
基于Lucene的异构数据库全文检索技术
2017-05-11 01:34王亮,苏云
指挥控制与仿真 2017年2期
王 亮,苏 云
(1. 海军指挥所,北京 100841;2. 江苏自动化研究所,江苏 连云港 222061)
基于Lucene的异构数据库全文检索技术
王 亮1,苏 云2
(1. 海军指挥所,北京 100841;2. 江苏自动化研究所,江苏 连云港 222061)
当前,我军积累了部队情况、装备性能、海战场环境等海量的作战数据。这些数据数量巨大、格式多样,且存储在不同类型的数据库中。如何快速准确地从这些数据中检索出目标信息,成为一项非常重要的工作。Lucene是一个基于Java的开源的全文检索库,利用它可以方便地定制出符合用户特定需求的搜索引擎。使用Lucene可研制出一种可配置的、支持不同类型数据库的全文搜索引擎。
Lucene;异构数据库;全文检索;搜索引擎;索引
随着现代互联网的快速发展,网络上存储的信息量越来越大且呈指数增长。随着计算机计算能力的日益增强、存储设备存储密度的日益提高、大规模集群日益普遍,人们处理大量数据的能力越来越强,“大数据”成为当前炙手可热的话题。网络成为现代人生活中不可或缺的一部分,在给人带来便利的同时,也不可避免地造成了用户难以快速获取有效信息的问题[1]。如何使用搜索引擎快速地从浩瀚的网络中获取用户需要的信息,成为一个重要研究课题。
当前,我军积累了部队情况、装备性能、战备工程、海战场环境资料、水文气象资料、情报资料等海量的作战数据,并且数据种类和数量还在逐年增加。这些数据具有以下几个特点:
1)数量较大。尤其是包括高清图片、视频等大容量数据,以及各种实时数据。单个数据库的大小可达几GB、几十GB甚至更多;
2)格式多样。既有通常的结构化数据,也有文档、图片、视频等非结构化数据;
3)存储在不同类型的数据库中。包括Oracle、SQL Server、Access等不同类型的数据库。
如何快速准确地从这些数据中检索出目标信息,成为一项非常重要的工作。Lucene是一个开源的全文检索库,利用它可以方便地定制符合自身需求的搜索引擎。本文使用Lucene,研制出了一种可配置的、同时支持多种类型数据库的全文搜索引擎,并成功应用于作战数据搜索。
1 开源库Lucene简介
1.1 原理
Lucene的两个核心能力是建立索引和搜索索引,分别通过索引器(Index Writer)和搜索器(Index Searcher)完成。具体的工作原理和过程见图1。
1)建立索引过程:待处理的数据可能来源于各种不同的途径,具有各种不同的形式,如文件系统、数据库、互联网、手工录入的数据等。应用程序首先按需要把待处理数据划分成一条条的数据记录,此处的数据记录类似于数据库中表的记录,即一条不可分割的信息单元。例如,对于来自文件系统的文本文档,可以将每个文档的内容作为一条数据记录;对于来自数据库的数据,可以将每个数据行作为一条数据记录;对于来自互联网的站点数据,可以将每个网页的内容作为一条数据记录。接下来通过Lucene提供的方法,将每条数据记录转换成一个文档(Document),并写入索引文件中。文档是Lucene中的基本概念,是索引文件中的一个最小单元,同时对应着搜索过程中的一条搜索结果。
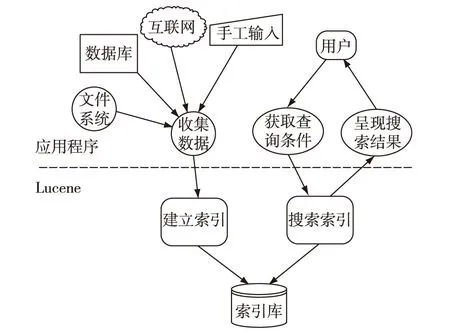
图1 Lucene的工作原理和过程
2)搜索索引过程:应用程序将搜索关键字(通常来源于用户输入)提交给Lucene的搜索器,后者依次完成词汇分析、停止词去除、词干提取、名词及名词性短语识别等过程[2],然后将处理后的搜索关键词与索引库中的索引内容对比,找到匹配的项,进行排序,将结果返回给应用程序,最终展示给用户。在搜索过程中,排序是一个不可或缺的重要步骤,排序算法的好坏直接影响搜索结果的质量。
1.2 特点
Lucene主要有以下特点:
1)索引文件的格式独立于应用平台,它是一种以8字节为基础的文件格式,使得兼容系统或者不同平台的应用能够共享建立的索引文件;
2)在传统的全文搜索引擎的倒排索引的基础上,实现了分块索引,能够针对新的文件建立小文件索引,提升索引速度。然后通过与原有索引的合并,达到优化的目的;
3)优秀的面向对象的系统架构,使得对其扩展的学习难度降低,方便扩充新功能;
4)设计了独立于语言和文件格式的文本分析接口,索引器通过接受Token流完成索引文件的建立。用户扩展新的语言和文件格式,只需要实现文本分析接口;
5)面向全文检索的优化,首次索引后并不把所有文档的具体内容读取出来,而只将所有结果中匹配度最高的前100个文档的编号放到结果缓存中并返回,可以满足90%以上的检索需求;
6)已默认实现了一套强大的搜索引擎,用户无需自己编写代码即可使系统获得强大的检索能力,默认实现了布尔检索、模糊查询和分组查询等操作。
2 作战数据库全文搜索引擎设计
本文在Lucene的基础上,实现了一个支持异构数据库的、按分类搜索的、灵活可配的作战数据库全文搜索引擎(以下简称搜索引擎)。下面按照整个过程中数据流动的顺序,详细介绍搜索引擎的特点、设计过程中遇到的问题及解决措施。
2.1 对异构数据库的支持
作战数据存储在各种不同类型的数据库中,如Oracle数据库、Access数据库、SQL Server数据库等。为了能够统一处理存储在不同数据库中的数据,必须使用一种屏蔽数据库类型差异的方法。Java平台提供的JDBC,即Java数据库连接,正是一种以相同的方式访问不同类型数据库的方法。它在语言层提供了统一的数据库访问接口,而在底层则由各种类型的数据库驱动实现这些接口。因此通过使用JDBC,在建立索引过程中获取各数据库存储的作战数据时,就不需要针对具体的数据库类型专门进行实现。存在某些特殊的情况,例如在对Access数据库进行查询时,返回的结果集中的数据不符合标准,因此需要对其单独处理。
为了能够同时对多个不同类型数据库提供支持,搜索引擎提供了专门的配置文件,用来配置搜索引擎使用的数据源,包括名称、地址、数据库名称、数据库类型等信息。搜索引擎会根据数据库类型自动选择相应的驱动程序对数据库进行访问,如表1所示。另外还可以灵活地配置数据库中的哪些表被纳入索引,哪些表被排除。

表1 数据源配置信息示例
2.2 建立索引
搜索引擎建立索引的过程[3-4]如图2所示。
建立索引的过程中,最重要的步骤就是生成索引文档。索引文档类似于数据库中的一条记录,它包括多个字段,这些字段是将来进行搜索时用来匹配的关键信息。
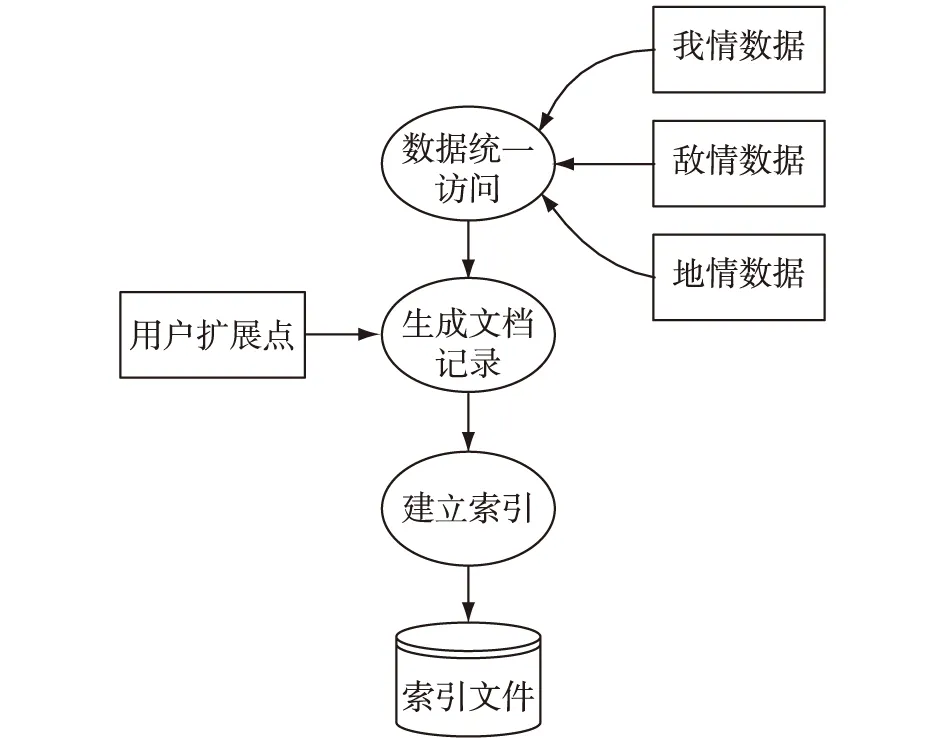
图2 搜索引擎建立索引的过程
在作战数据库搜索引擎设计过程中,在索引文档中添加了如表2所示的字段。

表2 索引文档中的字段及含义
其中,只有“内容”字段才是原始数据的信息,理论上只需要此字段就可以了。但是,为了实现更多功能而额外增加了一些字段[5]。例如,假设“内容”字段只保存了原始数据行中的部分数据,那么通过“数据源的名称”字段、“表名”字段和“主键信息”字段就可以反查出此数据行中的其他数据。为了简单起见,将数据行中的所有字段的数据拼接起来,生成“内容”字段。
另外,数据库中的数据可能并非全部需要被索引,因此在建立索引时,需要有对数据进行过滤的功能。前文提到的在配置文件中对排除范围的配置,只能精确到数据表的级别。为了更精确地进行控制,搜索引擎提供了一个扩展点,可以通过编写代码将过滤数据的能力提升到数据行级别。搜索引擎提供的全部扩展点如表3所示。

表3 搜索引擎提供的扩展点
2.3 更新索引
通常,数据库中的数据不是一成不变的,数据常常会更新,包括增加、删除和修改。在数据更新时,搜索引擎的索引文件也必须相应地进行更新。针对不同特点的数据库,本文中的搜索引擎提供了两种可选的方式来更新索引。
1)全量更新方式。此更新方式针对数据可能会被增加、删除和修改的数据库。当数据有更新时,搜索引擎会重建索引文件,然后删除之前的旧索引文件。在重建索引文件期间,仍然使用旧索引文件进行搜索,因此搜索服务不会中断。
2)增量更新方式。此更新方式主要针对数据只会被增加、修改的数据库。对于新增的数据,只需要重复上述的建立索引过程,并将索引文件合并到已有的索引目录即可。对于更新的数据,可以使用Lucene提供的更新索引的方法,通过索引文档的ID字段找到对应的索引,进行更新操作即可。
另外,搜索引擎还提供了一个后台定时任务,以固定的时间间隔执行更新索引的操作。同时也支持手动触发的方式来更新索引。
2.4 对中文的支持
在建立索引和处理搜索关键词时,需要对数据文本进行分词处理。Lucene本身不支持中文分词,数据中含有中文时,使用Lucene建立索引和搜索时将不会得到预期的结果。但是作为一个高度模块化的库,Lucene的分词过程由分词器完成,同时又支持第三方分词器的接入,从而替代原生的分词器。针对中文分词,最出名、使用最广泛的是IKAnalyzer分词器,本文中正是用它完成中文分词。
2.5 实现分类搜索
建立索引阶段生成的索引文件都存在一个目录下,在搜索阶段将会对此索引目录下的所有索引文件进行检索。但是某些情况下,搜索引擎没有必要检索所有数据范围,而是只检索某个数据库中的数据,或者只检索属于某个或某几个分类的数据。例如,假设作战数据库中存储了我情数据、敌情数据和地情数据,用户可能只希望搜查我情数据分类中的结果。此时如果不加区分地对整个索引目录进行检索,将会在搜索结果中出现用户不需要的无用数据,并且会消耗更多的查询时间。
为了能够更好地支持分类搜索,需要在建立索引阶段将数据按照需要分成几个类别,可以在配置文件中配置某个数据源属于哪个类别,或者某个表属于哪个类别。在建立索引时,以类别为名称建立多个文件夹,将不同类别的数据产生的索引文件保存到对应的目录下。同时也可以通过树状的目录结构实现多级分类。在搜索阶段,根据用户指定的类别,只需要到对应的索引目录下去检索数据即可,如图3所示。如果用户希望搜索某几个分类或全部分类的数据,可以通过Lucene合并索引目录的能力实现,即将多个索引目录映射成一个虚拟的索引目录。在此基础上,也可以实现对某个指定的数据源进行搜索的功能。
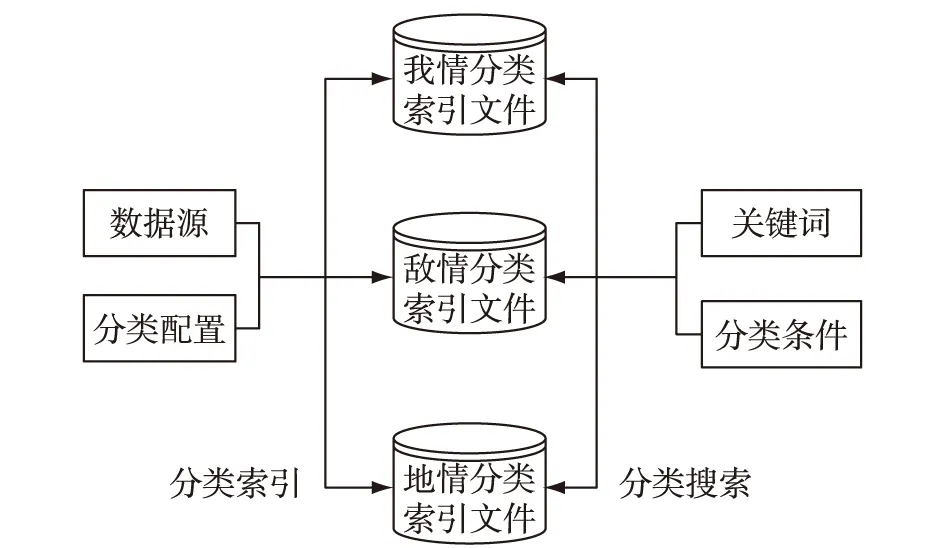
图3 搜索引擎分类搜索的原理
2.6 实现多种排序方式
排序是搜索引擎非常重要的一个环节,排序的质量会影响整个搜索过程的质量。Lucene默认按照结果的相关度进行排序。所谓相关度,通常是指在某个索引文档中“内容”字段匹配到的关键词的数量与“内容”字段的长度的比值。
为了实现更丰富的排序功能,Lucene支持自定义排序方式,即按照索引文档中的其他字段进行排序,并且可以指定排序字段的优先级。本文的搜索引擎实现了按照数据源名称和按照类别进行排序。例如,优先按照类别排序,然后在同一个分类中按照相关度进行排序。以作战数据库为例,搜索结果可以按照我情、敌情和地情的分类顺序排列,而在三种分类内部,按照结果的相关度排序。这样一来,用户就可以更加方便快速地定位结果。
2.7 摘要和高亮
摘要和高亮功能也是搜索引擎通常会具备的重要功能,通过这两个功能可以很好地提升搜索引擎用户的使用体验。
Lucene本身提供了对摘要功能和高亮功能的支持。其中,摘要功能是从匹配结果附近抽取出一段文字返回给用户,方便用户了解搜索结果所处的上下文,以确定搜索结果是否符合自己的预期。而高亮功能通常是对摘要内容中的关键字进行特殊处理,以突出展示给用户。例如对于在浏览器中以网页形式展示的搜索结果,可以通过HTML页面突出显示关键字。本文中的搜索引擎,采用了将搜索关键字变成红色的方式,同时支持自定义。如图4所示。

图4 搜索引擎的摘要和高亮功能示例
最终实现的作战数据库搜索引擎软件的模块组成和调用关系如图5所示。其中,init模块:启动和初始化整个搜索引擎服务;collect模块:周期性运行采集任务,完成索引的创建和更新;config模块:用于用户对数据采集过程进行配置;index模块:将作战数据库中的数据转化为索引文档,存入索引库;db模块:实现对多源异构的作战数据的透明访问;web模块:为用户提供一个基于浏览器的可视化搜索界面;search模块:根据用户输入的查询条件,完成搜索、排序、高亮和摘要等功能,返回最终结果;util模块:为其他模块提供公共工具。
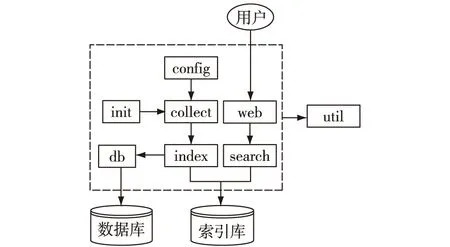
图5 搜索引擎的模块组成和调用关系
3 实验结果与分析
数据量为1GB的情况下,对若干关键词进行搜索的结果如表4所示。

表4 对不同关键词搜索的结果
数据量不同的情况下,对关键词“海军”进行搜索的结果如表5所示。

表5 不同数据量下搜索的结果
由上述的结果可以得出:1)对于不同的关键词,搜索耗时基本在几百毫秒的数量级,通常不超过200ms。这个速度完全可以满足对作战数据进行快速搜索的需求。
2)搜索耗时与搜索的结果数没有明显的关联,推测可能与倒排索引和搜索算法的内部实现有关。同时在增大数据量的情况下,对相同关键词进行搜索的耗时增加缓慢。这表明,在作战数据库的数据不断增大的情况下,仍能保证用户的搜索请求能得到及时响应。
4 结束语
在传统的作战数据软件中,对作战数据的搜索采用了SQL查询的方式。每次搜索请求,都需要遍历大量数据表,进行多次数据库查询,完成一次搜索通常需要几秒甚至十几秒,用户体验较差。
本文根据海军数据的特点,基于开源全文检索库Lucene,开发出一种可配置的、支持多种类型数据库的全文搜索引擎,并成功运用到了作战数据搜索的项目实践当中。完成一次搜索仅需要几百毫秒,同时能够保证在数据量持续增大时搜索耗时不会发生明显变化,因此用户体验得到很大的提升。
作战数据库搜索引擎的建立具有重要意义:一方面,可以将各单位建设的不同类型的作战数据库进行统一管理;另一方面,可以满足我军在执行任务时快速获取作战数据的需求。
[1] 李树青, 韩忠愿. 个性化搜索引擎原理与技术[M].北京:科学出版社,2008: 1-2.
[2] 岳昆. 数据工程: 处理、分析与服务[M].北京:清华大学出版社,2013: 88-89.
[3] 罗刚. 解密搜索引擎技术实战: Lucene & Java精华版[M].北京:电子工业出版社,2011: 6-7.
[4] 崔诗程,李千目,戈峰. 基于Lucene的全文检索架构设计[J].南京理工大学学报(自然科学版), 2015,39(6):692-697.
[5] 秦杰,宋金玉,张广星. 基于Lucene的本地搜索引擎研究与实现[J].计算机科学, 2014,41(22):368-370.
Full-text Search of Heterogeneous Database Based on Lucene
WANG Liang1, SU Yun2
(1.Navy Command Center, Beijing 100841;2.Jiangsu Automation Research Institute, Lianyungang 222061, China)
Recently the army has accumulated massive operational data, equipment performance, naval battlefield environment etc. These huge data is with various formats, and stored in different types of database. How to retrieve the target information from these data rapidly and exactly is a very important work. Lucene is a Java-based open source library of full text search, and can be easily used to customize a search engine which can meet the specific needs of users. In this paper, we develop a configurable full-text search engine which can support different types of database.
lucene; heterogeneous database; full-text search; search engine; indexing
2016-11-30
2017-02-28
王 亮(1980-),男,辽宁铁岭人,硕士研究生,工程师,研究方向为数据工程建设。 苏 云(1986-),男,工程师。
1673-3819(2017)02-0141-04
TP391.3;E917
A
10.3969/j.issn.1673-3819.2017.02.026
猜你喜欢
计算机与网络(2022年2期)2022-03-17
电脑爱好者(2021年23期)2021-12-08
名家名作(2021年4期)2021-05-12
疯狂英语·新阅版(2020年11期)2020-12-21
科普童话·学霸日记(2020年1期)2020-05-08
办公室业务(2019年13期)2019-08-01
小天使·一年级语数英综合(2019年2期)2019-01-10
新世纪图书馆(2014年7期)2014-09-19
新世纪图书馆(2014年7期)2014-09-19
科学导报·学术论坛(2013年5期)2013-06-26
