
基于冗余数据压缩算法的经济信用风险研究
2017-05-09 05:41季姝俞静河海大学商学院江苏南京211100
电子设计工程 2017年7期
季姝,俞静(河海大学 商学院,江苏 南京 211100)
基于冗余数据压缩算法的经济信用风险研究
季姝,俞静
(河海大学 商学院,江苏 南京 211100)
针对信贷市场中的大数据难以有效分析经济信用风险的问题,本研究以终端云计算存储网络平台的金融数据包为基础,通过筛选过滤和降维处理的操作,在静态的分块模块中将上传的数据包文件进行分割得到不同容量的数据包从而实现对冗余数据的高纬度的立体空间映射;动态的分块模块中时间序列数据副本边缘特征空间向量的迭代操作步骤数对冗余数据包进行模式的转换。选取国民经济中划分的18个行业81个月实验结果表明:时间滑动窗口为5 s,对象个数为40个时,经济信用风险的误差在1%左右,数据误差和标准差分别在3%和4%以内,数据集检出准确率超过95%;冗余数据的压缩率为5.93%以内。
压缩算法;冗余数据;云存储;信用风险
随着当代信息科技的发展,人们进入大数据时代,信贷市场的大量数据犹是如此[1]。云端为信贷市场数据存储提供了平台[2],它不仅提供了存储的空间,还提供了计算和管理的功能。在云计算系统背景之下大数据的处理问题也日益呈现[3]。在电子计算机云系统中,云端作为一个可变的规模,其能够任意的伸缩[4],但是由于在计算过程中储存子节点同构互换,使得在数据传输的次通道中产生了大量的冗余数据,通过对冗余数据的筛选和压缩能够减少云计算的成本[5]。因此,对数据库数据进行降维处理并实现对冗余数据的压缩筛选[6]和滤除滤波并删除[7],能够提高云端计算的速度和效率,降低信贷双方的计算开销。目前对于云端次通道中产生的冗余数据处理方法主要有分数阶傅里叶变换的处理方法[8]、神经网络控制的处理方法[9]和支持向量机特征分类的处理方法[10],然而以上冗余数据的处理方法存在信息成本高,计算开销大以及次通道中冗余数据特征维数较高等问题[11]。针对上述问题,文中提出一种基于特征压缩的云计算冗余数据降维算法对经济信用风险进行研究,以期减少经济风险成本。
1 冗余数据压缩算法
1.1 冗余数据生成机制与体系构架
一般情况下,基于电子计算机系统之下的外环境通过将用户群使用的终端软件、网络处理器以及经过虚拟处理的核心云计算电子平台相结合[12]。但是很多情况下,随着电子计算机云端存储的中枢系统与电子设备结构的发展相适应,其中的技术和结构的变化容易对数据产生传输的次通道[13],在数据传输的次通道中会出现动态的衍生和节点转换的现象,由此在数据处理和传输的过程中就会产生相当数量的冗余数据,对于产生的冗余数据需要进行筛选滤除以及降维处理[14],同时要兼顾开发处理使用的软件以及电子计算机云端存储平台的特征相适应。电子计算机的云端存储平台遵循的存储机制如下:数据输入输出端口、存储设备层,节点管理器和组件层调用管理云存储外部环境下的大数据。基于电子计算机系统之下的外环境进行存储数据和管理数据的具体过程流程图如图1所示。
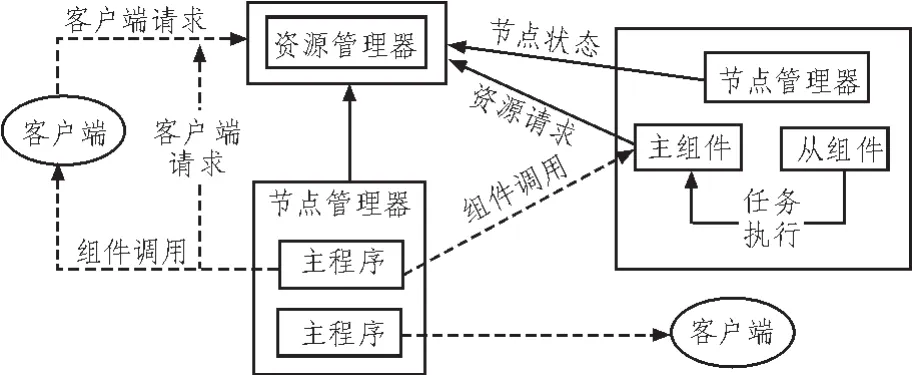
图1 数据存储与管理流程
为了使数据的处理更有针对性,面向不同的用户群和受众,在数据传输的次通道中分布有不同的资源节点,利用四元组G来表示在数据处理过程中冗余数据的存储结构,即G=(V,E,W,C),同时对移动终端的云计算存储网络平台的数据包进行定义,将传输的第i个数据包定义为ith,其主要的运行机制是首先在静态的分块模块中将上传的数据包文件进行分割得到不同容量的数据包,故存在不同大小的冗余数据模块,从而实现了对冗余数据的高纬度的立体空间映射。在电子计算机云端存储系统中数据变化导致的次通道中存在的分隔分片函数可以如下表示:
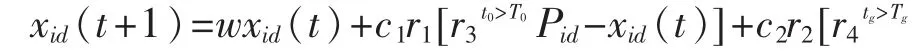

其中,g表示在高纬度的立体空间中进行迭代操作的步骤数,t表示在动态的时间序列数据副本中的一些存在边缘特征的空间向量的迭代操作步骤数。在资源节点的分布管理中,利用设置的组件进行调用和降维处理和筛选,并对冗余数据包进行模式的转换,最终得到电子计算机云端存储系统下次通道中冗余数据包的采样时间向量,以及得到冗余数据包在云存储系统中的处理顺序序列,其规模如下:
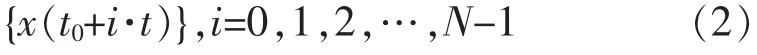
在进行冗余数据压缩的同时可能会存在云端存储的资源节点分布对冗余数据堆产生降维干扰的影响,为了尽可能的减少这样的影响提升数据压缩的效率,需要对分布节点进行干扰滤波,并通过空间降维的方法最终实现对冗余数据的过滤和筛选达到冗余数据压缩的目的。
1.2 冗余数据的空间降维与特征值提取
在进行云存储系统中系统结构的冗余数据包进行分析和空间重组降维处理[15],同时需要以互联网为媒介进行信号的算法处理并且实现对冗余数据的提取和读取处理。在电子计算机云端存储系统中利用资源节点分布来调用中间组件进行调试,一般情况下会产生冗余数据包的漂移情况,设冗余数据包的时间区间长度为N,将收集录入的数据进行分类汇总,得到C个分类,根据其空间特征获得电子计算机云端存储系统中次通道冗余数据的空间重组表达公式:
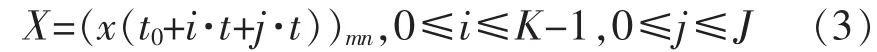
其中,x(t)用以表明时间序列,j为对空间进行重构的分割尺度,m是冗余数据包中的维数。一般在上述构建的多维空间内对次通道中的冗余数据特征值进行提取,设在向量特征值提取的过程中的降维矢量集合表示如下:
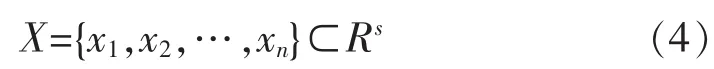
在电子计算机的云端存储系统中,将次通道中的冗余数据集合形成向量进行历遍运算流程之后得到了含有n个样本特征值的有限元,采集的样本共有n个,冗余数据包的空间多维向量为:xi=(xi1,xi2,…,xis)T。对冗余数据的不同量化模式进行不同步长的熵编码[16],将编码的矢量设为c类 ,其范围为1<c<n,利用高阶高维的特征向量压缩处理方法处理冗余数据的聚类中心,表达如下:

其中,Vi表示第i个对冗余数据产生干扰的向量,通过SVD分解法得到冗余数据分解结果:
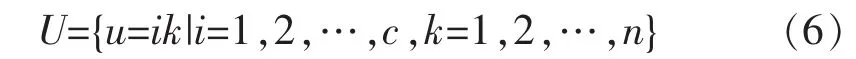
将冗余数据的降维目标函数定义如下:

其中欧式距离dik公示表达如下:

结合上述所有的约束条件并联系中心极限定理的原理得到如下的冗余数据特征空间压缩的目标函数的极值[17]:
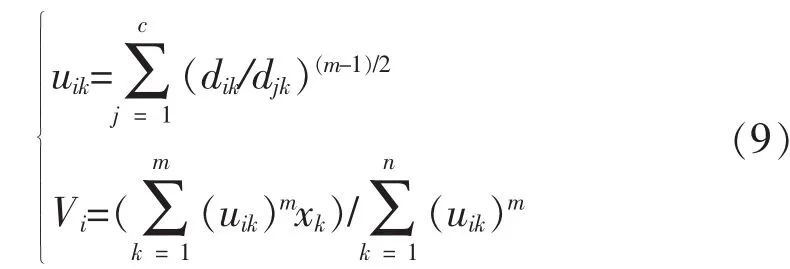
通过设定能够干扰向量,并输入初值结合模糊度指标m,最终实现高维冗余数据的降维处理和特征值提取。
2 经济信用风险分析
2.1 信用风险度量
对于信用风险的度量目前主要是CCA方法[18],其理论根源为期权定价理论,对于信贷市场的信用风险度量有着非常重要的经济意义。CCA方法主要特点在于其将企业的公开财务数据和市场的数据相结合,对于信用风险的度量更为准确也更为及时,能够表现企业和银行在信贷市场信用风险变动的动态趋势,从而在业界得到了广泛的应用。在CCA方法中利用违约距离DD来衡量信用风险。当假设企业资产价值At服从几何布朗运动时,根据Black-Scholes公式及伊藤引理得[19]:
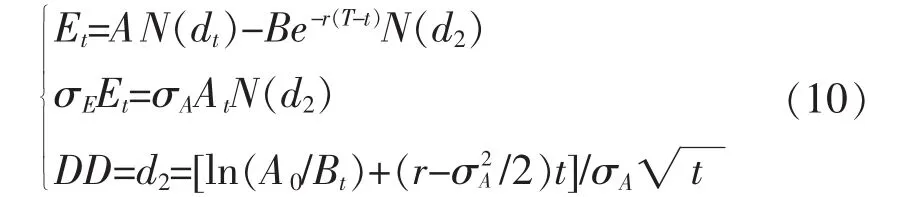
其中,B为违约障碍,E为债务低级索取权,σA、σE分别表示企业资产波动率及企业低级索取权波动率,r为无风险利率,T-t为期限d2=d1-σ,满足P{At≤Bt}=N-d2通过利用牛顿迭代法即可计算出违约距离DD。
2.2 信用风险冗余数据压缩算法步骤
根据经济中信用风险数据的特性,将本算法具体划分为3个步骤:1)时间序列的归类:运行数据库数据,将经济市场数据按照特征根据元组标码,对于属于同一个簇的元组分标,此处簇可为不动点也可为噪声点的集合;2)对簇的类型进行判别:对已标号分类的聚类进行判断,并从中汇聚出不动的噪声点和不动点和数据波动轨迹;3)压缩数据:根据特征提取和降维处理对数据进行压缩处理。从第一个未被标记的子算法开始运行整个数据库,按时间先后进行处理,整个子算法的运行直到所有的数据遍历为止,最终所有数据都会被标注相应的记号,最后再根据特征提取和降维处理实现冗余数据的压缩。子算法的具体流程如图2所示。
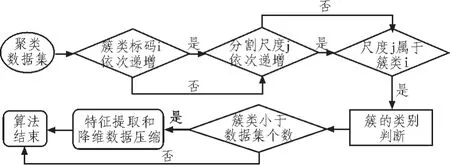
图2 簇类别判断与冗余压缩合成算法
3 实验结果分析
实验中的算法运行CPU硬件选取双核AMD FX-8350 4GHz,内存DDR3 1866 8GB,并采用CSR-6930Z超高频固定式读写器,在操作系统为Windows 7的PC机上完成。文中用于实验的数据为国民经济中划分的18个行业,取其行业市值在全行业市值中所占比重为前九的行业作为样本,样本区间为2008 年1月至2014年9月,共81个月。为了验证冗余数据压缩算法对经济信用风险分析的有效性,本研究选取数据压缩率和准确率作为标准,同时实验所用的时间滑动窗口大小和对象个数作为参数,独立重复实验30次获取对信贷市场所选取的9个行业作为样本的月度数据的数据库进行降维处理和特征值提取进行数据压缩和冗余数据的筛选,如表1所示。

表1 时间滑动窗口大小与对象个数的压缩率和准确率
由表1可知,经济信用风险的冗余数据的时间滑动窗口大小和对象个数对原始数据集有重要的影响。压缩率愈小说明冗余数据在降维处理后的数据量占比愈小,并且准确率愈大说明算法对经济信用风险的冗余数据识别所占比愈大。其中,随着时间滑动窗口用时递增,压缩率逐渐降低,而准确率逐渐提高,且当时间窗口为6 s时,压缩率仅为9.54%,准确率为99.89%;随着对象个数的增加,压缩率逐渐降低,准确率逐提升,且当对象个数为60时,压缩率为24.54%,准确率仅为99.91%。为了进一步研究经济信用风险的波动情况,本研究选用时间滑动窗口为5 s,对象个数为40个,标记出经济信用风险的违约距离的动态波动轨迹,其动态趋势如图3所示。
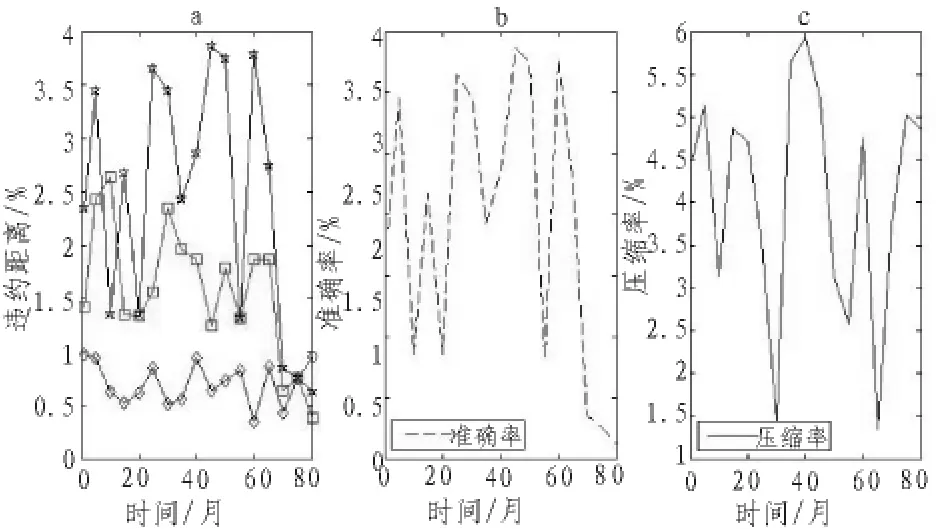
图3 经济信用风险的冗余数据动态趋势检验
由图3可知,经济信用风险的误差在1%左右,在本实验中数据误差和标准差分别在3%和4%以内,此时数据集中不动点的检出准确率最高,超过95%;冗余数据的压缩率为5.93%以内。
4 结 论
由于信贷市场由于贷款双方信息不对称所导致的信用风险,为了解决在银行在决定放贷之前对企业的财务数据进行评级所遇到的数据冗余问题,本文根据数据特征进行按簇分类提出了一种基于冗余数据压缩压缩算法的经济信用风险研究方法。本文算法首先根据修正的CCA方法并结合冗余数据的压缩算法,以经济运行中的九大行业为样本采集到企业的财务状况数据,参照基于时序的聚类算法将每个行业的财务数据按照特征归类并分成若干簇,形成的每个簇都是按照其属性进行归类运动的运动轨迹或静止点形成的噪声数据;根据之前设定的参数对所划分归类的簇进行判断并按照元组为单位对冗余数据进行压缩。通过进行本实验表明,本文提出的冗余数据压缩算法能够对各种类型的数据进行压缩聚类,实现对冗余数据的筛选压缩和处理。对于经济信用风险数据的压缩准确性和算法运行效率的提高将是研究的下一个方向。
[1]张杰,刘凤,贺立龙.基于企业规模的中小企业信贷融资特征分析[J].统计与决策,2012(15):92-95.
[2]秦秀磊,张文博,王伟,等.面向云端Key/Value存储系统的开销敏感的数据迁移方法 [J].软件学报,2013(6):1403-1417.
[3]刘正伟,文中领,张海涛.云计算和云数据管理技术[J].计算机研究与发展,2012,49(1):26-31.
[4]张友鹏,权海宁.新型分布式全电子计算机联锁系统研究[J].计算机工程与应用,2012,21(6):164-166.
[5]聂军.基于K-L特征压缩的云计算冗余数据降维算法[J].微电子学与计算机,2016(2):125-129.
[6]王汝言,吴晴,熊余,等.压缩感知的多参数链路故障定位算法 [J].电子与信息学报,2013(11): 2596-2601.
[7]郭凤鸣,李兵,何怡刚.密集环境下RFID系统滤波方法研究[J].计算机工程与应用,2014,50(13): 210-213.
[8]谭鸽伟,潘光武,林薇.基于分数阶傅里叶变换的两步运动补偿CS算法[J].计算机应用研究,2015,32 (1):89-92.
[9]朱金华.组合模型在商业银行信用风险评估中的研究[J].计算机仿真,2011,28(9):361-364.
[10]焦卫东,林树森.整体改进的基于支持向量机的故障诊断方法[J].仪器仪表学报,2015,36(8): 1861-1870.
[11]刁爱军.基于压缩特征编码的混合云冗余数据删除算法[J].科技通报,2015,31(8):42-44.
[12]张伟娜.以云计算为导向的计算机操作系统教学研究[J].软件,2014(7):85-88.
[13]唐懿芳,钟达夫.基于数据冗余的BDS长报文传输机制改进算法[J].指挥控制与仿真,2016(1): 152-157.
[14]李蓉,周维柏.基于多特征选取和类完全加权的入侵检测[J].计算机技术与发展,2014(7):145-148.
[15]付仲良,赵星源,王楠,等.一种基于流形学习的空间数据划分方法[J].武汉大学学报:信息科学版,2014(7):145-148.
[16]黄庆卿,汤宝平,邓蕾,等.无线传感器网络子带能量自适应数据压缩方法 [J].仪器仪表学报,2014,35(9):1998-2003.
[17]叶清,吴晓平,叶晓慧,等.基于PCA与FCM的入侵检测样本数据压缩方法[J].海军工程大学学报,2012,24(5):25-30.
[18]管薇薇,周凯.信用风险数据集市的构建探讨[J].电脑知识与技术,2014(8):5155-5158.
[19]王飞,孙维尧.基于Black-Scholes方程的股指期货期现套利模型及交易算法[J].计算机应用,2013,33 (1):326-328.
Research on economic credit risk of based on redundant data compression algorithm
JI Shu,YU Jing
(Business School,Hohai University,Nanjing 211100,China)
For the credit markets effectively analyze large data difficult economic problems of credit risk,this study terminal cloud storage network platform of financial data packet basis,by operating the screening and filtration reducing the dimension of the block in the module,in a static Upload file packets obtained by dividing the capacity of different packets of three-dimensional space in order to achieve high latitudes redundant data mapping;Iterative procedure number of copies of the data dynamic partitioning module for the time series feature space vector edge of redundant data packet conversion mode.Select the national economy division 18 industry 81 months results show that:the sliding window of time 5 s,the number of objects is 40,the credit risk in the economy error of about 1%,the data error and standard deviation,respectively,and 3%less than 4%,the detection accuracy of the data set more than 95%;redundant data compression rate of less than 5.93%.
compression algorithm;redundant data;cloud storage;credit risk
TN<919.6 文献标识码:A class="emphasis_bold">919.6 文献标识码:A 文章编号:1674-6236(2017)07-0015-04919.6 文献标识码:A
1674-6236(2017)07-0015-04
A 文章编号:1674-6236(2017)07-0015-04
2016-06-22稿件编号:201606173
国家自然科学基金面上项目(71171207);河海大学中央高校基本科研业务费项目(2013B33114)
季 姝(1992—),女,江苏南通人,硕士研究生。研究方向:信用风险。
猜你喜欢
车主之友(2022年4期)2022-08-27
海峡姐妹(2019年12期)2020-01-14
铁道通信信号(2019年9期)2019-11-25
辽宁经济(2017年6期)2017-07-12
电讯技术(2017年4期)2017-04-16
当代经济(2016年26期)2016-06-15
新疆财经大学学报(2015年3期)2015-12-10
电测与仪表(2015年14期)2015-04-09
特区实践与理论(2014年5期)2014-07-24
计算物理(2014年1期)2014-03-11
