
基于 Nagios 的监控数据分析展示平台
2017-04-28 00:58:21
数据与计算发展前沿 2017年5期
中国科学院计算机网络信息中心,北京 100190
引言
中国科学院超级计算环境是由总中心、9 家分中心、19 家所级中心组成的三层架构网格计算环境,同时还连接了院内 11 家单位的 GPU 计算集群,聚合通用计算能力近 1300 万亿次,GPU 计算能力近 3000万亿次。中国科学院超级计算环境主要为用户提供计算服务,同时对用户提出的问题及时响应并提供技术支持。衡量一个超级计算环境主要关注环境的资源信息、使用情况和用户数目等。管理员及时有效地获取环境的运行情况,了解环境的资源使用信息可更好地调度用户作业,为用户提供更好的服务。
基于 Nagios 搭建的中国科学院超级计算环境监控平台[1]中,针对集群主要考虑系统利用率 (CPU 占用率) 和节点占用率两个指标。为获取这两项数据按照 Nagios 已有插件的实现方式,编写了获取集群CPU 和节点占用率的插件。在获取这两项数据的同时一并抓取了集群的其它运行数据,包括集群计算节点数、CPU 核数、账号数、作业数等。在之前的监控平台中处于当时的需求只考虑了系统利用率这一指标,集群的其它运行数据并没有展示。为了更加详细准确地反映集群的运行,优化改进已有的监控平台,根据实际的运行需求对获取的运行数据加工处理,设计成更准确直观反映集群的数据结构。有了这些数据后,为使外部能方便快捷地获取利用这些监控数据,把数据设计成通用接口的形式对外提供。外部人员可直接调用接口快捷地获取数据并根据自己的需求从各种维度对数据进行展示。本文中用于展示中科院超级计算环境的 Show 平台即基于监控数据接口开发并实现的。Show 平台主要展示超级计算环境的运维数据、集群的使用信息以及集群利用率等。普通用户或系统管理员登录后可根据自己不同的权限查看相应内容。
1 整体结构
中科院超级计算环境监控整体结构如图 1 所示,底层是已搭建好的环境监控平台,其中涉及获取集群和服务器信息的插件。在监控平台中主要获取服务器的磁盘、进程、负载、用户、数据库,通过这几项来保证服务器能与集群正常连接并存储数据。针对集群主要获取集群的磁盘和运行信息,包括集群当前的利用率、作业数等;中间层是监控数据接口,利用底层环境监控获取的监控数据以接口的形式对外提供数据。设计的接口包括获取实时数据 (利用率、计算节点、账号、CPU 核、作业) 和统计数据 (系统利用率) 两类;上层是应用层,开发人员利用监控数据接口开发的应用程序。本文设计的展示超级计算环境的 Show平台即其中的一个应用,利用监控数据接口提供的接口对数据组合并展示。
2 环境监控
2.1 部署结构
超级计算环境以三层架构超级计算网格中间件SCE[2]作为核心支撑软件,根据部署和管理的要求,设计有登录客户端 Client、中央服务器 CS (center server) 以及前端服务器 FS (front server) 三大模块。其中 FS 负责中央服务器 CS 与超级计算机 HPC 之间的连接,对到 HPC 的连接进行访问控制,以保证访问的安全性和合法性。考虑到中国科学院超级计算环境的三层架构特点,FS 分布在各个分中心或所级中心,采用 Nagios 的分布式监控方式部署监控平台。FS 收集网格服务器和相连接的集群的信息,通过NSCA 将数据发送给部署在总中心的监控主服务,具体部署结构图如图 2 所示。
服务器的具体含义如表 1 所示。监控主服务是部署在中国科学院计算机网络信息中心的一台服务器,收集所有信息并集中显示;监控中转服务器是指与HPC 相连的前端 FS 服务器。由于安全等因素,主服务无法直接获取 HPC 的相应信息,只能通过 FS 中转服务器获取。FS 以及相连的 HPC 的监控信息通过汇报的形式发送给主服务,这样可做到只要 FS 是正常工作的即可把监控信息发送给主服务。主服务主动连接 FS 获取监控信息会造成主服务自身负载过高或因连接问题获取不到数据,采用分布式的监控方式部署可避免以上问题。

图1 监控整体结构图Fig. 1 Monitor structure
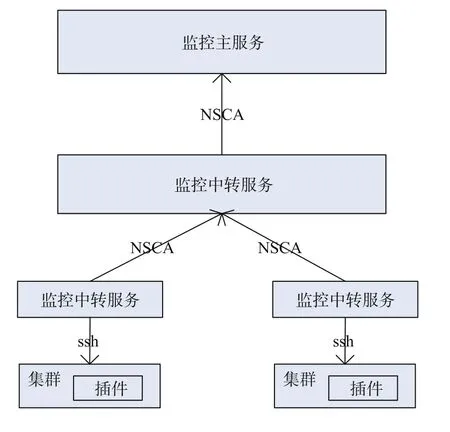
图2 监控平台部署结构图Fig. 2 Monitor platform structure

表1 服务器描述Table 1 Description of servers
2.2 集群监控
中国科学院超级计算环境现有 HPC 的作业系统主要包括 LSF、Torque、Pbspro 和 Slurm 四种,所以需要根据各自的使用方式编写插件获取集群信息。获取的集群信息包括利用率、计算节点、账号、作业以及 CPU 核。其中利用率的定义如下:
系统利用率 (CPU 占有率) = (运行作业占用的CPU 核数/开机总 CPU 核数)
节点占有率= (运行作业占用的节点数/开机总节点数)
开机率= (开机总节点数/总节点数)
计算节点数据包括总节点数、离线节点数、管理员关闭的节点数、运行作业占用的节点数、预留节点数、空闲节点数;账号数据包括总数、有作业运行的账号、有作业排队的账号;作业数据包括总作业数、运行作业数;CPU 核数包括可用总核数、运行作业占用的核数、排队作业核数。
集群实现这些插件后,在监控中转服务中定义对集群以及自身服务器的监控内容,验证配置后启动 Nagios 进程,监控中转服务即可获取集群的监控信息。另外,监控中转服务需要设置 NSCA 的一项配置,通过该命令将监控内容发送给监控主服务。在监控主服务中同样需要定义监控中转服务和集群的监控内容,与监控中转服务定义的内容不同的是不需要定义获取监控内容的命令。中转服务将监控信息发送到主服务后,主服务能自动匹配获取相应内容。在中国科学院超级计算环境监控平台中,前端服务器 (监控平台中的监控中转服务) 以五分钟一次的频率采集集群数据并汇报给监控主服务的服务器。部署监控主服务的服务器存放有所有集群的信息,可对这些信息进行分析处理或配置一个 Web 服务器展示监控信息。在监控平台中,服务器或集群出现故障时,平台可根据定义的故障处理方式通知管理员,包括邮件、短信等。一旦出现问题管理员会收到邮件通知,有利于及时解决出现的故障问题,为用户提供更好的服务。
2.3 监控数据
在监控平台中,总中心部署监控主服务的服务器收集到的监控数据借助 RRDTool(Round Robin Database tool)[3]将数据存储在对应的 RRD 文件中。“Round Robin”指使用固定大小的空间来存储数据,并有一个指针指向最新的数据的位置。一段时间后,当所有的空间都存满了数据,又从头开始存放。整个存储空间的大小是一个固定的数值,RRDTool 就是使用类似的方式来存放数据的工具,该工具存储数据的一个缺点是存储空间大小固定,当所有空间都存满时会覆盖原有的数据。
在保存的数据中,如集群的利用率信息,很多情况下希望可以保留几个周期,以便于进行对比分析。借助 RRDTool 存储数据只能保留一段时间,所以在监控平台中引入 NDOUTILES[4]将 Nagios 监控数据存入 MySQL 数据库。利用 MySQL 数据库中集群的原始数据,根据需求设计不同的表存储不同时间间隔的数据以便统计数据时使用。表 2 是针对中科院超级计算环境设计的数据表,其中 scgrid 表存储每个集群的原始数据,每五分钟增加一个数据项;scgridhalf、scgridtwo 是通过 scgrid 数据表生成,主要用于提供集群最近半月或一月的数据。scgridhalf 中集群的每个数据项间隔为 30 分钟,scgridtwo 每 2 小时增加一个数据项;Dayinfo 存储集群每天的系统利用率数据,通过 scgrid 数据累计求和取均值获得,用于计算每月的系统利用率数据。
3 监控数据接口
为保证数据访问的方便快捷,利用 Flask[5]框架 python 语言开发了一个 Web 服务来获取监控数据。考虑到监控数据存储在 MySQL 数据库中,外部直接访问数据库获取数据会造成数据的不安全性。SCEAPI-REST[6]是访问 SCE 环境的跨平台和语言的通用接口。在 SCEAPI-REST 中,通过调用获取监控信息的 Web 服务实现获取监控数据的接口。
3.1 数据接口定义
获取的监控数据主要包括集群利用率、计算节点数、账号数、作业数和 CPU 核数等信息。针对这些数据主要从计算节点、账户、作业、CPU 核不同维度设计接口;除了考虑实时数据外,还设计了系统利用率的统计数据接口。针对一个超级计算环境,一般用户会想要了解环境的整体信息,包括总计算能力、用户数、作业数等,系统管理者除关注环境整体信息外,对其中各个集群的信息也需要清楚。针对前面的实时数据,分别针对环境整体和集群设置了两个接口(当前实时数据和指定时间段内数据)。对系统利用率的统计数据同样设置了两个接口 (指定时间段内单个集群的系统利用率和指定月份所有集群的系统利用率)。具体接口定义如表 3 所示:
其中,表 3 给出了定义的接口相对路径,调用API 时 URI 路径还需要拼接 HTTP 协议、域名和版本信息,如 http://域名/版本//show/scgrid/tdata 表示获取环境整体实时数据全路径。表 3 中定义的各个接口都设计有自己的参数,如 /show/scgrid/envInfo 参数包括 type、start、end 三个,其中 type 表示需要获取的数据类型 (计算节点、账号、作业、CPU 核);start 和end 分别用于指定获取数据的开始时间和结束时间。
3.2 数据接口实现
如图 3 部署图所示:SCEAPI-REST 以 web 形式访问监控的 Web 服务;Web 服务接受请求后查询存储 Nagios 信息的 MySQL 数据库并进行计算,以JSON 格式返回数据。SCEAPI-REST 相当于对 Web服务各个接口进行封装处理,只要保证 Web 服务提供的接口不变,即使 Web 服务内部的实现根据实际运行做出调整并不影响 API 端接口的使用。Web 服务采用 Flask 框架 python 语言开发实现。Flask 是一轻量级的 web 应用框架,具有一个包含基本服务的强健核心,其他功能可通过扩展实现。Flask 主要依赖于两个外部库 Jinja2 模板引擎和 Werkzeug WSGI 工具集,开发简单方便。在 Web 服务中,为获取所需的环境整体数据和集群数据,从数据库获取数据后需要进一步对数据简单计算处理。比如环境整体数据需累加各个集群的对应数据,每个集群虽然都五分钟一条数据,但由于获取时间并不完全相同,对时间进行取整操作保证每个时间都存有各个集群的一条数据。获取到数据结果后,为方便外部使用将数据结果统一为现在比较流行的 JSON 格式输出。

表2 数据表描述Table 2 Description of data tables
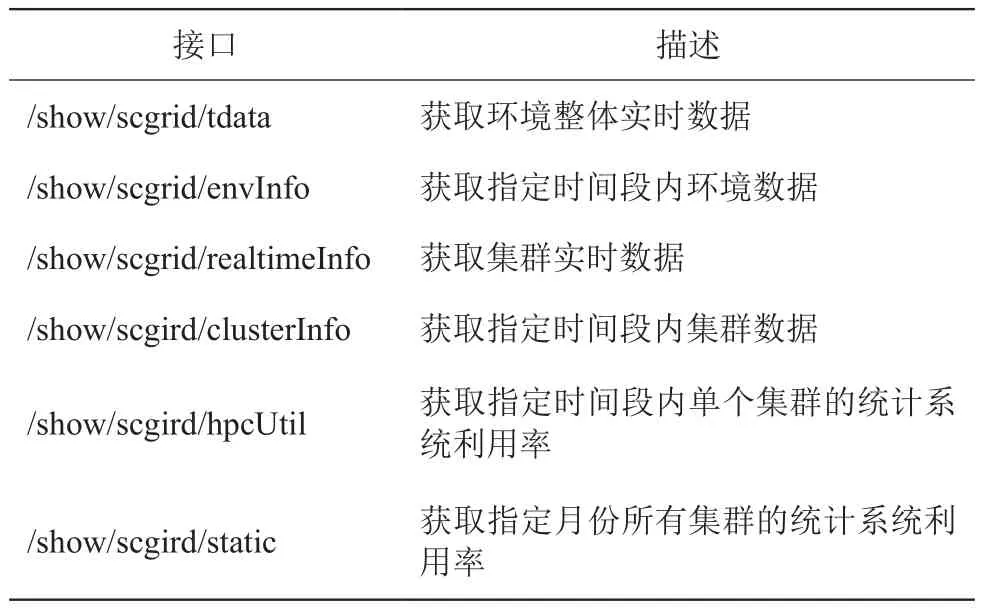
表3 接口定义描述Table 3 Description of interfaces
开发者可通过 Web 社区、移动应用、桌面程序、脚本等不同形式的终端访问 SCEAPI-REST,获取相应数据。SCEAPI-REST 提供相应的使用手册,开发者只要根据手册可方便地利用提供的各个接口获取 SCE 环境的各项数据,从而根据自己的需求开发设计相应的应用。
中科院超级计算环境中用户和集群管理员大都使用科技网通行证,为了方便浏览器端的开发,支持科技网通行证,SCEAPI-REST 针对获取监控数据设计和实现了 javascipt 开发接口。开发人员可以直接在浏览器端使用,不再需要处理同源和跨域问题,该接口支持请求的并发访问。具体流程如图 4 所示,通过科技网通行证的脚本验证用户是否已经登录通行证,若已经成功登录,“通行证登录”模块负责根据 code从科技网通行证服务器获取用户信息,并提供公开查询的权限,然后使用 js 脚本连接访问公开数据,若未登录给出出错信息并提示需要登录。如果设计的WEB 应用是采用科技网通行证验证登录,可直接采用加载浏览器的 javascript 脚本方式获取 JSON 格式数据,进而对数据进行展示处理。
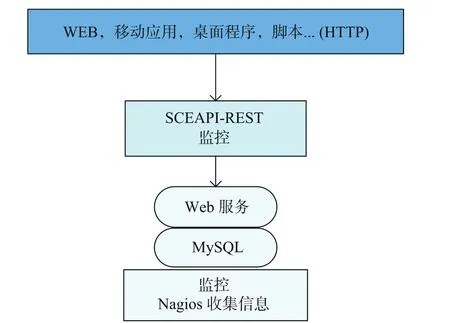
图3 监控数据部署图Fig. 3 Monitor data structure
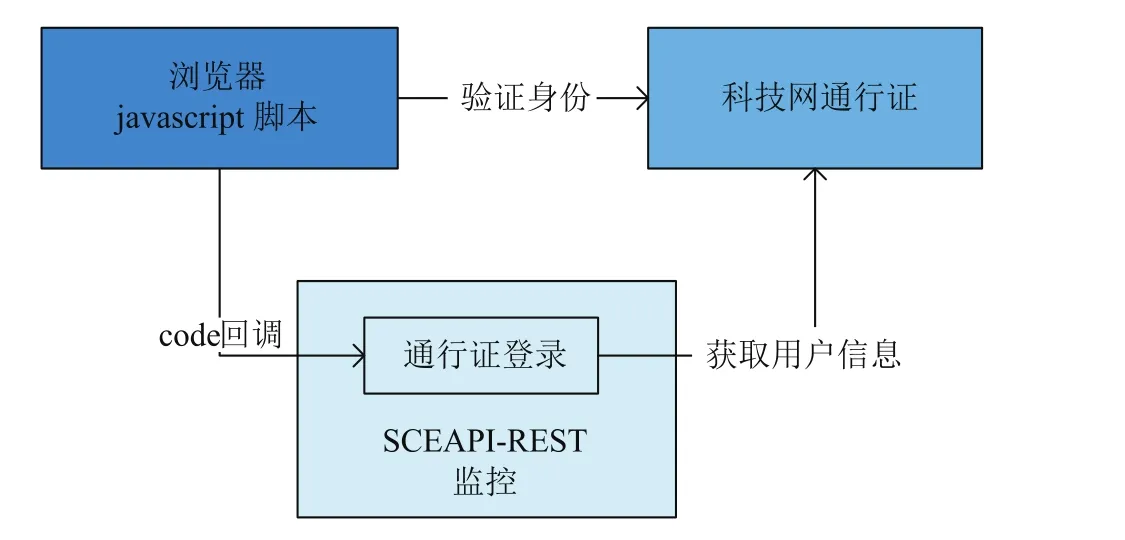
图4 监控数据登录流程示意图Fig. 4 Login process of monitoring data
4 Show 平台
基于 SCEAPI-REST,结合运维的实际需求,我们设计开发了 Show 平台对其中的监控数据从不同维度进行展示。平台接入了中国科技网通行证平台,采用科技网通行证统一登录,直接调用 SCEAPIREST 提供的 javascipt 开发接口获取监控数据。调用javascript 开发接口的好处是简单方便,只需要加载相应的 js 代码,但必须使用科技网通行证先登录,否则无法获取接口返回数据,提示错误信息。
关注超级计算环境的一般为使用资源的用户或者集群管理员,针对不同的用户设置了三类角色,包括超级管理员、集群管理员和普通用户。在平台中赋予每一类角色不同的权限用于查看不同的页面内容。图5是权限控制的流程图,当用户发出访问请求时,根据用户提供的凭证 (用户名、密码) 验证用户的合法性,若凭证无误,平台通过角色检查得到用户的权限,根据权限显示对应的网站内容。通过权限控制可实现系统的分级,提高系统安全性,同时更加方便用户查看自己关注的内容。
针对前面设置的三类角色,平台分别设计了首页、集群展示和集群月报利用率三个页面。首页展示环境的整体信息,所有用户只要登录该平台即可查看。集群展示和集群月报利用率页面展示集群的相应数据,其中集群管理员可查看自己集群的利用信息和利用率数据;超级管理员可查看所有集群的信息。

图5 权限控制图Fig. 5 Access Control

图6 首页示意图Fig. 6 Home page
图6 是首页展示信息,左侧为中科院超级计算环境的整体运维数据,包括总节点数、开机节点数和可用核数;累计开通账号数;作业运行和排队信息。右侧为环境整体计算节点、核数、作业数和账号信息展示图,通过点击右侧的最近一天、最近一周和最近一月按钮可分别查看对应时间段的数据。右侧显示的每个图都是采用 Highcharts[7]所画的时间轴函数图,可通过拖拽横轴查看不同时间段的数据,点击下侧的各个数据项,可控制对应的数据显示与否。每个图都可通过一个单独的链接来访问,如果特别关注某一信息可通过链接来访问并查看相关数据。
集群展示页面与首页相比可直接查看集群利用率和节点开机率两个维度数据。图 7 为截取的集群利用信息,包括集群利用率和节点开机率,这两项数据是集群管理员最为关注的数据。在计算集群利用率时时只考虑了可用的 CPU 核和节点,结合节点开机率信息可反映集群运行的是否比较慢,空闲资源是否很多。与前面的图类似,也是时间轴函数图,通过拖拽横轴可查看不同时间段的数据。集群每月的系统率可通过集群月报利用率页面查看,这里显示集群最近半年的数据。
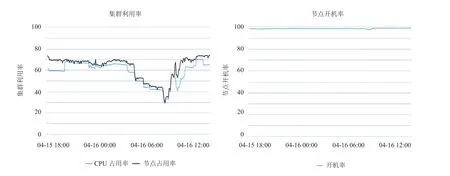
图7 集群利用信息示意图Fig. 7 Cluster Utilization
5 小结
基于 Nagios 开发了中国科学院超级计算环境监控平台,通过监控平台可获取集群的运维数据。为方便外部使用,对其中的运维数据加工处理并设计成接口的形式对外提供。开发者可利用提供接口获取运维数据并设计自己的应用展示相关数据。本文利用监控数据接口搭建了中科院超级计算环境展示平台用于展示整个超级计算环境以及集群的运行情况。各集群管理员可通过此平台查看自己集群的运行情况 (计算节点、作业、账号、CPU 核、利用率);普通用户可通过平台了解超级计算环境的整体资源信息;超级管理员可查看整个环境以及集群的数据,清楚地了解环境运行信息。平台提供了时间轴函数图来展示各项数据,用户也可通过调用监控数据接口获取监控数据,以更方便自己查看使用的形式来展示这些数据。
[1] 和荣,肖海力. 基于Nagios的监控平台的设计与实现[J].科研信息化技术与应用,2014,5(5): 77-85.
[2] 戴志辉. 三层架构超级计算环境优化设计与实现研究[D].北京,中国科学院研究生院,2011.
[3] RRDTool [S]. http://oss.oetiker.ch/rrdtool/,2014.
[4] Nagios项目组. Nagios-3应用指南[S]. http://www.nagios.org,2008.
[5] Flask[S]. http:// flask.pocoo.org/,2010.
[6] 曹荣强,肖海力,卢莎莎. 基于REST风格的科学计算环境信息Web服务[J].科研信息化技术与应用,2012,3(5):76-82.
[7] Highcharts[S]. http://www.highcharts.com/products/highcharts/,2016.
猜你喜欢
消费电子(2022年7期)2022-10-31 06:17:34
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
中国化肥信息(2019年6期)2019-01-19 13:10:42
经济技术协作信息(2018年5期)2019-01-19 08:39:16
电子制作(2018年11期)2018-08-04 03:25:40
消费导刊(2017年24期)2018-01-31 01:29:29
中国交通信息化(2017年3期)2017-06-08 06:09:28
电子制作(2017年20期)2017-04-26 06:57:48
知识就是力量(2017年2期)2017-01-21 18:29:36
印制电路信息(2015年6期)2015-12-30 12:57:48
