
基于支持向量机的消极性文本识别研究
2017-04-26 22:10李军高立群蔡翔
电脑知识与技术 2017年6期
李军+高立群+蔡翔


摘要:随着移动互联网技术地不断发展,网民针对各种话题发出的博文、评论呈爆炸式增长。该文针对各大网站产生的海量新闻、微博文及其评论信息,将网络中海量的新闻、微博文及其评论转变为文本信息进行分析,识别出其中的消极性信息,对于现代商业企业、政府舆情监控具有较高应用价值。
关键词:支持向量机;消极性短文本;识别
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2017)06-0209-03
随着互联网技术、特别是移动互联网的迅速发展,网络已经成为了人们获取信息,发表意见的新媒介。各类网络论坛、新闻点评、微博等渐渐成为了网络舆论重要力量,无处不在的网络,让网民们可以极为容易地通过网络发表自己的意见和观点,各种博文、评论呈爆炸式增长。而在当前的社会意识形态下,因不少网民热衷于对消极性的,甚至带有攻击性、贬低性色彩的帖子进行围观、转发和评论,导致类似负面情绪主导舆论走势,产生了消极甚至恶劣的影响,所以对负面评论较正面或客观性评论的识别在舆情导向中就显得更为重要。
在以往的研究中,人们主要针对网民的情感倾向进行分类研究,也就是褒贬性进行了计算和分析。而在实际的生活、工作、学习中,网民对某一事物进行围观、转发、探讨以及寻求建议,往往更加注意到的是对该事物的消极性评价上,这种特点更加体现在购物和突发舆情事件上面。本文在不同的语言模型下提取文本特征,利用支持向量机分类方式,对消极性文本情感识别进行了研究和对比,取得了一定的效果。
1 相关工作研究
情感分析,也称为意见挖掘,是指通过计算技术对文本的主客观性、观点、情绪、极性的挖掘和分析,对说话者的情感倾向做出分类判断。随着移动互联网的发展,人们越来越容易,也越来越趋于在网络上发表自己的观点和意见,同时,也越来越受到网络上他人的观点和意见的影响,这就决定了情感分析研究的重要现实意义。当前,情感分析在网络舆情监测、企业营销策略、突发事件检测、经济分析预测等方面均有着较好应用。在中文情感分析领域,涉及文本预处理、语言模型、文本分类等方面工作。
1.1 文本预处理
文本预处理是为了提取文本中对于情感文本分类有价值的信息因素。首先,中文不像英文,词与词之间有用空格符号进行分隔,而是一个句子与另一个的句子之间才有标点符号进行间隔。这样就需要将本是一个个句子的文本处理成为一个个词或者词组,因此,在各项处理前,首先要对文本进行分词。其次,文本中经常性地含有大量人名、地名、时间、助动词等词语,这些词语不仅与情感分析无关,还会提高情感分析的维度,致使分类的复杂度提高,而且还会严重影响分类的效果。文献[1] 专门对适应不同领域的中文分词方法进行了研究,对不同专业领域分词起了较好领路作用。
目前,分词技术有基于词典匹配、统计分析和语义分析三类。基于词典匹配是使用已有或者自建的情感词典,采取正/逆向最大匹配方式与词典中的词条进行逐条匹配,匹配成功就认为是一个词,但是,当文本中有新的情感词语出现时不能很好识别。统计分析的方法是基于统计相邻汉字出现的次数,次数越多,说明它们是词的可能性就更大,这就有效地避免了基于词典匹配带来的弊端。常用的分词系统中科院的ICTCLAS分词系统,清华大 学的SEGATG中文分词系统,复旦大学的中文分词系统,哈尔滨工业大学的 统计分词系统,微软公司汉语句法分析器中的自动分词系统等。
1.2 语言模型
词袋模型(Bag of Words)和词向量模型(Word Embedding)是自然语言和文本分析中最为常见的两种模型。词袋模型是假定一个文本,不顾词的顺序和语法结构,仅仅将其视为是词的集合,将每一个词都看成是独立的出现,而不是依赖于其他词是否出现。这种假设将文本有效地进行了简化,便于模型化处理。词向量模型则是文本中的词语处理為向量,然后将所有向量置于一起形成一个向量空间,每一个向量视为空间中的一个点,这时,在空间中加上“距离”这个概念,这样就可以计算向量间的相似度来衡量文本之间的相似度。下面,对本文使用到的词袋模型中的词频TF(Term Frequency)、词频—逆向文档频率TF—IDF(Inverse Document Frequency)和词向量模型中的doc2vec特征提取办法进行阐述。
1.2.1 词频TF
词频TF是一种常见的、但比较简单的权重计算方法,其思想是统计词语在文本中出现的频数,如果某个词或短语在一篇文章中出现的频数高,TF越大,而在其他文章中却出现不多,则认为该词语具有很好的类别区分能力。
对于某一文档dj来说,假设文档中某一特定词语wi共出现了n次,则该词语对于文档区分的重要性为:
ni,j指wi在文档dj出现的次数,则表示文档中所有词出现次数之和。
逆向文档频率(IDF) 的思想是统计出现词语出现在文本中的频率,如果包含某词语的文档越少, IDF越大,则说明该词语具有很好的类别区分能力。
假定整个文本库的文本总数为N,出现了某一词语的文档数目为nk,则该词的IDF值计算如下:
为了避免nk为零时,导致以上式子分母为零,所以引入一个常数λ。
以上面文档d1,d2为例,此时文档仅为2,为了避免出现负数,在分子中加入一个常数,得到每个词的idf值为:A:0.4,B:0.4,C:0.4,D:1.1,E:0.4,F:0.4,G:0.4。
结合前面的TF和IDF,TF-IDF公式为:
以上d1,d2tfidf值如下:
d1 [0.032,0.032,0.032,0.044,0.64,0.032,0.032],
d2 [0.016,0.032,0.016,0,0.048,0.016,0.032]。
由此可以看出,在某一文档中的高词语频率,如果该词语又在整个文档库中的低文档频率,则该词语可以产生高权重的TF-IDF。
1.2.3 doc2vec的词向量
doc2vec实际是基于Word2vec思想的算法,Word2Vec使用了两种方法,连续词袋CBOW (Continuous Bag of Words)和Skip-gram。在CBOW方法中,通过某个词的上下文经过模型预测该词,而在Skip-gram方法则是用给定的词来预测其周边的词。在训练前,每一个词都会首先初始化为一个N维的向量,训练过程中,会对输入的向量进行反馈更新,在进行大量语料训练之后,便可得到每一个词相对应的训练向量。doc2vec与其类似,它分为DM (Distributed Memory)和DBOW (Distributed Bag of Words),它在此基础上将文本作为一个特殊的token id引入训练语料中,也就是对文本也配置了向量,并在训练中进行更新。
1.3 分类器选择
对于文本情感分析的研究,主要思路有基于语义的情感词典方法和基于机器的学习的方法。基于语义的情感词典方法较为简单,主要通过情感知识来对微博文本进行情感分析。文献[1]根据语义分析的方法,构建语境歧义词搭配词典,进而利用该词典对句子进行情感倾向性分析。基于机器学习的方法较为常见的有基于朴素贝叶斯、基于最大熵值、基于支持向量机、K最近邻分类和条件随机场等方法。Pang[2]在2002年就使用支持向量机、最大熵和朴素贝叶斯3种分类器对篇章级别电影评论文本进行分类对比,发现机器学习方法比基于人工标注特征的方法更有效,并且SVM在3种分类器中平均表现最好。文献[3]使用了多种特征提取、量化方法,用不同机器学习模型对微博进行分析,实验表明采用SVM分类模型、信息增益特征提取以及TF-IDF量化权重的方式对微博的情感分类效果最好。本文以朴素贝叶斯作为baseline,使用支持向量机(SVM)的分类方法进行实验。
支持向量机(SVM)是Vapnik[3]等在多年研究统计学习理论基础上于1995年对线性分类器提出的一种设计最佳准则,是一种能够解决小样本模式识别的十分有效的方法,其基本思想是寻找一个超平面作为两类训练样本点的分割,以保证最小的分类错误率。在线性可分的情况下,存在一个或多个超平面使得训练样本完全分开,SVM的目标是找到其中的最优超平面。
假设有训练样本集合{ x[i] , y[i]} , i = 1 ,2,3 , …, n ,{ x[i]} ∈ Rn 由两类点组成, 如果x[i]属于第1类, 则y[i] = 1 , 如果x[i]属于第2类, 则y[i] = -1。所要求的用来分割的超平面方程w便可以表示成:
与以上1/-1分类相对应的,Logistic回归的目的是从特征中学习到一个0/1,只是因为其将特性的组合作为自变量,取值范围是从负无穷到正无穷。此时,使用Logistic函数将自变量映射到(0,1)上,由此得到的值就是属于y=1的概率,设x为n维特征向量,函数g为Logistic函数,表示如下:
当g函数为一元变量时,它就将(-∞,+∞)映射到了(0,1),则有:
此时,需要对一个新来的数据进入分类判定时,只要求hθ是否是大于0.5即可。
在前面的超平面构建中,需要将-1/1替换Logistic中的0/1,并将θ换成w和b。这样,,更进一步,则得到:
2 实验结果及分析
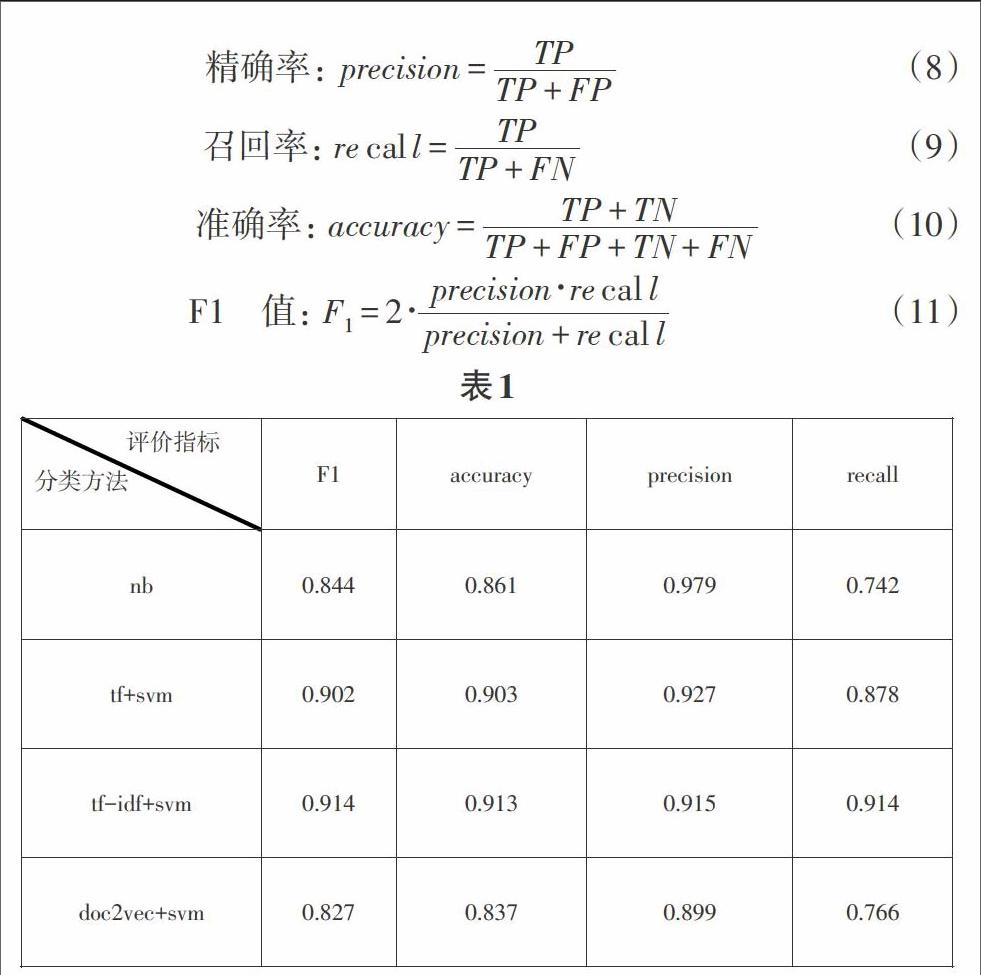
本文实验环境为:python3+sklearn+gensim+nltk,语料来源为5001条宾馆住宿评论语料,其中正面语料2774条,负面语料2227条,测试样本与训练样本比例为7/22。用当前流行的jieba分词系统对语料进行分词和去停用词,以贝叶斯分类器为baseline,分别使用TF、TF—IDF和doc2vec特征选择加支持向量机分类器的方法进行实验,设置以下评价指标如下:
TP:正確识别消极性文本数;FP:错误识别消极性文本数;
TN:正确识别正面/客观性文本数;FN:错误识别正面/客观性文本数;
从实验结果来看,tf-idf+svm的效果最好。首先,相对于tf+svm方法,它多引进行了逆向文档频率作为特征,使得召回率增大,虽然对精确率有一点点影响,但很明显,影响极小。其次,单独的朴素贝叶斯分类器在分类中的精确率最高,但召回率明显偏低,这很大程度上因为其条件独立假设,丢弃了词与词之间的相互信息,还有就是训练样本的偏少,导致测试样本中的部分特征词语在训练样本中没有出现。第三,同样存在召回率低的还有doc2vec+svm方法,主要是doc2vec为了降低复杂度,对原有特征空间进行了压缩,在此过程就很有可能出现特征信息的损失,加上线性不可分和样本量不足,导致了召回率以及F1值和准确率均不高。
参考文献:
[1] 修驰.适用于不同领域的中文分词方法研究与实现[D].北京:北京工业大学,2013.
[2] 宋艳雪,张绍武,林鸿飞.基丁.语境歧义词的句子情感倾向性分[J].中文信息学报,2012,26(3): 38-43.
[3] 刘志明,刘鲁.基于机器学习的中文微博情感分类实证研究[J].计算机工程与应用,2012, 48 (1) : 1-4.
[4] Pang Bo, Lee L.Shivakumar Vaithyanathan. Sentiment Classification using Machine Learning Techniques[C]. the 2002 Conference on Empirical Methods in Natural Language Processing,2002:79-86.
[5] Corte C, Vapnik V. Suport Vector Netwoks [M] . Machine Learning, 1995(20):273-297.
猜你喜欢
中国水运(2016年11期)2017-01-04
东方法学(2016年6期)2016-11-28
现代园艺(2016年17期)2016-10-17
科学与财富(2016年28期)2016-10-14
