
基于FPGA的低秩矩阵恢复算法研究与应用
2017-04-19 10:17沈镇柴志雷
单片机与嵌入式系统应用 2017年2期
沈镇,柴志雷
(江南大学 物联网工程学院,无锡214122)
基于FPGA的低秩矩阵恢复算法研究与应用
沈镇,柴志雷
(江南大学 物联网工程学院,无锡214122)
低秩矩阵恢复算法主要包括鲁棒主成分分析、矩阵补全、低秩表示,由于矩阵补全是一个NP难的问题,低秩表示涉及到字典矩阵,复杂度高,因此本文主要针对鲁棒主成分分析在FPGA上的研究与应用进行了描述,并且在CPU以及FPGA上实现了图像恢复。实验结果表明,基于FPGA的HLS设计相对于传统CPU在速度上得到了数十倍的提高。
低秩矩阵恢复;鲁棒主成分分析;FPGA;HLS
引 言
低秩矩阵恢复算法[1]在信号处理、图像修复、计算机视觉、机器学习、人工智能等方面有着极其广泛的应用。通常把鲁棒主成分分析[2]、低秩表示和矩阵补全统称为低秩矩阵恢复算法,然而由于矩阵补全是一个NP难的问题以及低秩表示涉及到字典矩阵,其复杂度高,因此鲁棒主成分分析得到广泛使用。
FPGA(Field-Programmable Gate Array,现场可编程门阵列)是在PAL、GAL、CPLD等可编器件的基础上进一步发展的产物。由于支持细粒度并行及硬件重构,是一种常用的硬件加速平台,系统设计师可以根据需要,通过可编辑的连接把FPGA内部的逻辑块连接起来。
本文使用的是Xilinx开发的Vivado HLS[4]工具,Vivado HLS工具的出现和发展突破了以往在使用FPGA进行设计时使用HDL语言进行设计实现的瓶颈。在Xilinx FPGA[5]上构建数字系统时,首先使用C/C++/System C语言进行建模,然后通过Vivado HLS工具将C/C++/System C模型直接转换为RTL级的HDL描述,因此,大大提高了FPGA设计的效率。
1 HLS介绍
1.1 Vivado HLS设计流程及其功能
高级综合(High Level Synthesis,HLS)是Xilinx公司推出的新一代FPGA设计工具。利用System C语言进行数字系统的描述,并可以将其自动转换成RTL级代码,其处理流程如图1所示。
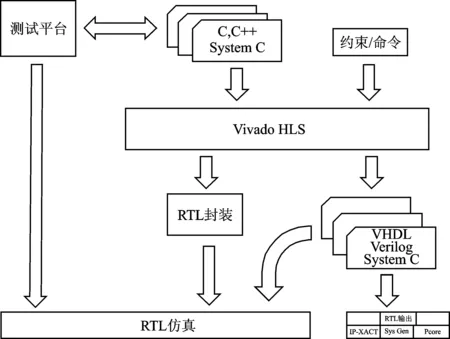
图1 HLS的处理流程图
该综合工具主要有以下4个功能:
① 从C语言描述级别的源代码创建一个RTL级实现。
② 从C源代码提取出控制和数据流。
③ 基于默认和用户定义的命令实现设计。
④ 从相同的源代码描述中,可以实现很多的设计,即开发者使用C/C++高级语言在源文件以及测试文件中进行编程。源文件用来实现IP核的功能,可以采用工具优化或手动优化从而满足性能指标,之后通过测试文件在源代码级进行仿真验证保证IP功能正确,功能仿真后再通过高层综合工具综合生成RTL级代码同时运行RTL级仿真,在满足功能时序要求之后可以导出RTL级的IP核。
1.2 Vivado HLS优点
HLS可以用于将C语言函数转换成硬件模块。它能够基于现有的 C/C++的代码编写的算法,按照Vivado HLS编译工具的规范进行简单修改后,就可以快速、直接地生成IP核或者综合后的结果(.dcp文件)。对于嵌入式系统的开发者来说,这样就可以快速地完成现有算法到 FPGA 中的移植,既能显著缩短开发时间,又能利用FPGA的性能几十倍上百倍地提高算法性能。
2 低秩矩阵恢复算法
2.1 算法流程
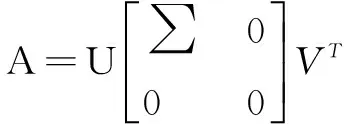
奇异值分解[3]步骤分为两大步:首先利用Householder变换把矩阵A约化成双对角线矩阵,即
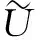
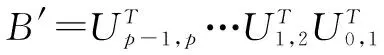
每次迭代的时候,经过初始变换V0,1,将在第0列的主对角线下方出现一个非零元素。在变换V0,1时,选择位移值u的计算公式如下:
最后再对奇异值按非递增次序排序。
2.2 算法并行性分析
首先,定义一个深度为256的双口RAM来保存每个灰度值的像素点个数,具体操作是将每个像素点的灰度值作为其中一个端口的读地址,读取RAM单元中的计数,将其值增加1,接着将更新后的计数从另一个端口写入同一单元。
其次,由于在统计处理每个像素点时,都要执行3个步骤:读取计数、更新计数、写回计数。只有完成当前像素点的3个步骤之后,才能进行下一个像素点的处理。而FPGA的并行性能够解决此类处理延时导致的低效率,即在模块内部构建3个功能相同的统计模块,每个模块各自负责相邻的3个像素点,从而构成一条流水线,使得每个子模块都有3个时钟周期来统计1个像素点。读取计数、更新计数、写回计数3个步骤的逻辑被划分到各自的时钟周期来完成,从而提高了处理效率。
3 算法硬件加速单元的HLS设计与实现
3.1 硬件加速单元设计
考虑到算法使用流水结构,用一个32位宽度的行缓冲来存储前一行所产生的图像灰度值,从而能够在硬件当中实现流水计算,硬件计算模块如图2所示。

图2 硬件计算模块图
3.2 硬件加速单元的HLS实现
Vivado HLS中的基本系统构建块是C/C++函数,构建一个由模块和子模块组成的系统,意味着需要用一个顶层函数来调用底层函数,因此要先准备好用来生成硬件模块的函数,它需要保存在一个单独的文件里。在创建工程时,指定它为顶层函数,同时也要准备一个实现相同功能的函数,它不会被生成硬件模块,只用于验证硬件模块的功能是否正确。最后还要准备一个测试的main( )函数,它分别调用前面所述的两个软件函数,并比较它们输出的结果是否一致。在C语言验证和RTL验证时,HLS工具都会调用它。
3.2.1 主函数定义
由于Vivado HLS中仿真与综合的区别,仿真与综合时输入口数目不同,因此主函数定义略有不同。
#ifdefine DEBUG_MODE
voidsvd_filter(hls_int32 *in_pix, hls_int32 *out_pix, unsigned int byte_rdoffset, unsigned int byte_wroffset, int rows, int cols, int stride)
#elsevoidsvd_filter(volatile hls_int32 *inout_pix, unsigned int byte_rdoffset,unsigned int byte_wroffset,int rows,int cols,int stride)
#endif
上面定义函数中,hls_int32为输入输出像素值的数据类型,即32位整型输入输出,inout_pix用于存储输入/输出数据。执行这个函数时,CPU指令会读写其中的数据。
3.2.2 生成AXI4硬件接口
C语言函数转换成硬件模块,由于Vivado HLS工具支持3类通用类型的信号:流接口、BRAM接口、标量I/O。在这三类中,只有标量I/O 能够被处理器通过AXI4-Lite接口进行访问,生成AXI4[7]接口,由硬件模块自动读取数据,相当于集成了一个DMA控制器;也可以生成AXI Stream接口,AXI Stream Slave接口接收其他数据源生成的数,AXI Stream Master 接口可以作为数据源。接下来主要介绍AXI4硬件接口。
① 为指针inout_pix生成AXI4接口的约束:
#pragma HLS INTERFACE m_axi depth=2048 port=inout_pix offset=off bundle=Data_Bus
byte_rdoffset是一个输入参数,指定 buffer 的长度,转换成硬件模块后,会生成一个可写的寄存器,可以由AXI Lite总线访问,由CPU写入长度。
② 为输入、输出参数byte_rdoffset、byte_wroffset、rows、cols创建AXI Lite寄存器约束:
#pragma HLS INTERFACE s_axilite register port=return offset=0x00 bundle=Ctrl_Bus
#pragma HLS INTERFACE s_axilite register port=byte_rdoffset offset=0x14 bundle=Ctrl_Bus
#pragma HLS INTERFACE s_axilite register port=byte_wroffset offset=0x1c bundle=Ctrl_Bus
#pragma HLS INTERFACE s_axilite register port=rows offset=0x24 bundle=Ctrl_Bus
#pragma HLS INTERFACE s_axilite register port=cols offset=0x2c bundle=Ctrl_Bus
#pragma HLS INTERFACE s_axilite register port=stride offset=0x34 bundle=Ctrl_Bus
如果是用户自己的函数,虽然参数个数和类型可能都不一样,都可以参照上述类型做约束。HLS生成的硬件模块的寄存器都是无符号32位数据。必要的时候,可以使用C语言的 union来做类型转换。
3.2.3 memory copy
memory copy创建一个突发访问内存,memory copy的多次调用不能流水线执行,将顺序执行,memory copy需要一个本地缓存burst_buff_in来存储输入数据。
memcpy(burst_buff_in,(hls_uint32*)(inout_pix+byte_rdoffset/4+row*cols),BURST_NUM*sizeof(hls_uint32));
最后的输出结果返回给输出接口。
memcpy((hls_uint32 *)(inout_pix+byte_wroffset/4+(row-1)*cols), burst_buff_out,BURST_NUM*sizeof(hls_uint32));
3.2.4 性能优化
约束好与CPU的接口后,需要考虑性能优化,HLS有很多性能优化的技巧。
① “#pragma HLS DATAFLOW”,数据流编译指令指示Vivado HLS尽量以并行方式安排执行该函数的所有子函数。“internal”参数用于设置该模块的初始化间隔(II),初始化间隔(II)告知 Vivado HLS该模块必须具备的处理新输入数据字的频次,故决定了设计的吞吐量。
② “#pragma HLS PIPELINE”,流水线编译指令指示Vivado HLS将该函数流水线化,让初始化间隔为x(II=x),即x个时钟周期处理一个新的输入数据字。
3.2.5 buffer的使用
模块与模块之间需要buffer进行缓存,这样有利于模块之间的同步,提高计算效率。如输入数据存储在 buffer 中:
buff_A.insert_bottom(rgb2y(tempx),col);
最后再由 buffer 读出:
buff_C.insert(buff_A.getval(2,col),0,2);
4 实验结果与分析
本文采用基于高级综合工具HLS的C语言进行编写,采用的器件是Zynq7030系列芯片。以256×256大小图像为例,SVD算法在CPU上的执行结果如图3所示;在FPGA上的执行结果如图4所示。
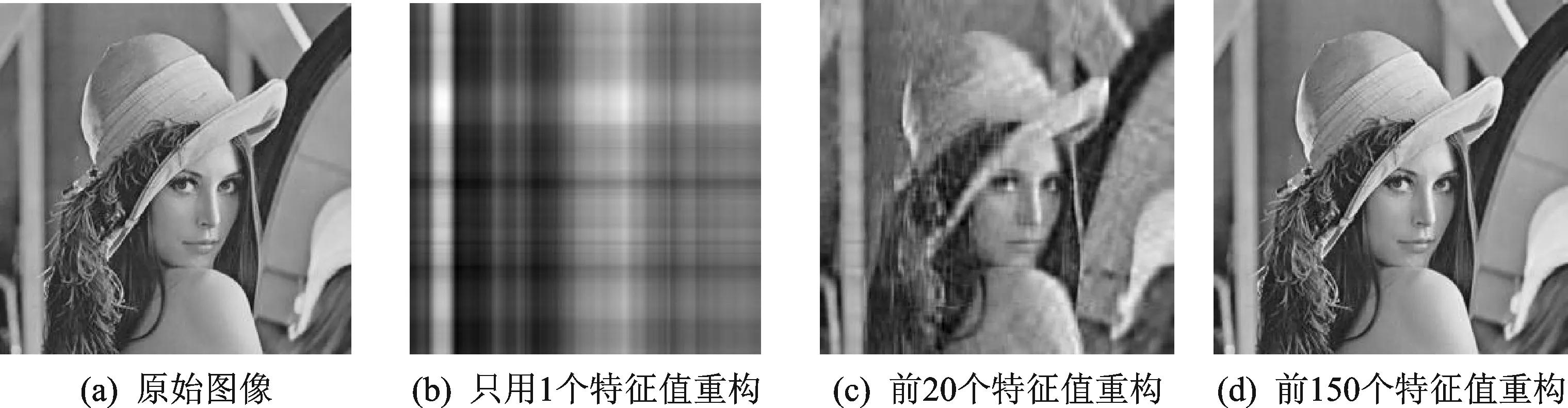
图3 CPU实验结果图

图4 FPGA实验结果图
由此可知,同一幅图片在FPGA上执行的效果与在传统的CPU上基本一致,然而FPGA执行时间比传统CPU提高了数10倍,表1列出了不同大小图片在CPU与在FPGA上执行的时间对比。
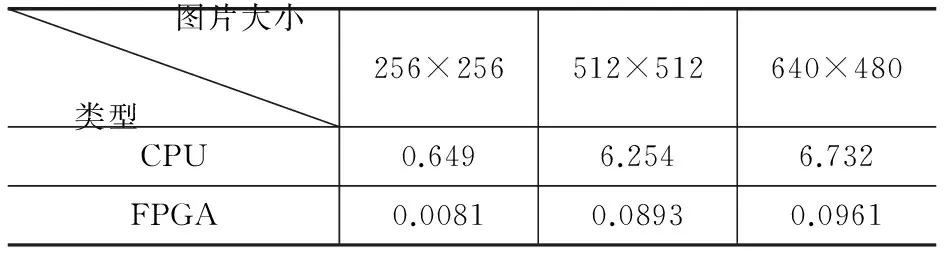
表1 不同图片在CPU和FPGA上的执行时间(单位:s)
通过Vivado HLS综合分析可知,SVD在FPGA上实现的部分逻辑资源所占比例分别是:DSP为4%,FIFO为3%,LUT为11%,这大大节约了芯片的硬件资源,节省了硬件成本,使得更多的资源可用于其他硬件算法。
结 语

[1] 史加荣,郑秀云,魏宗田,等.低秩矩阵恢复算法综述[J].计算机应用研究,2013(6).
[2] JinXing Liu,Yong Xu,ChunHou Zheng,et al.RPCA-based tumor classification using gene expression data[J].IEEE/ACM Transactions on Computational Biology and Bioinformatics (TCBB),2015,12(4):964.
[3] Menghan Yan,Wenqian Shang,Zhenzhong Li.Application of SVD technology in video recommendation system[C]//2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS),2016.
[4] 何宾.Xilinx FPGA设计权威指南[M].北京:清华大学出版社,2014.
[5] Xilinx.Zynq-7000SoC[EB/OL].[2016-08].http://www.xilinx.com/products/silicondevices/soc/zynq-7000/index.htm.
[6] R Dorado,E Torres-Jiménez,C Rus-Casas,et al.Mobile learning:Using QR codes to develop teaching material[C]//2016 Technologies Applied to Electronics Teaching (TAEE),2016.
[7] Ckristian Duran,D Luis Rueda,Giovanny Castillo,et al.A 32-bit RISC-V AXI4-lite bus-based microcontroller with 10-bit SAR ADC[C]//2016 IEEE 7th Latin American Symposium on Circuits & Systems (LASCAS),2016.
沈镇(硕士研究生),主要研究方向为嵌入式系统、图像处理;柴志雷(副教授),主要研究方向为嵌入式系统设计技术、机器视觉、FPGA操作系统等。
Research and Application of Low Rank Matrix Recovery Algorithm Based on FPGA
Shen Zhen,Chai Zhilei
(School of Internet of Things,Jiangnan University,Wuxi 214122,China)
The low rank matrix recovery algorithm mainly includes the robust principal component analysis,the matrix completion,the low rank representation.Because the matrix completion is a NP hard problem,the low rank said relates to the dictionary matrix,high complexity.Therefore,this paper mainly described the research and application of the robust principal component analysis in FPGA,and the CPU and FPGA image restoration is realized.The experimental results show that the speed of the design based on the FPGA HLS has been increased by tens of times compared to the traditional CPU.
low-rank matrix recovery;robust principal component analysis;FPGA;HLS
TP368
A
�士然
2016-08-26)
猜你喜欢
数学小灵通(1-2年级)(2021年11期)2021-12-02
现代电子技术(2021年1期)2021-01-17
中等数学(2020年8期)2020-11-26
计算机教育(2020年5期)2020-07-24
小学生学习指导(低年级)(2020年4期)2020-06-02
上海大学学报(自然科学版)(2018年5期)2018-11-02
电子制作(2018年16期)2018-09-26
电脑知识与技术(2018年35期)2018-02-27
数学小灵通·3-4年级(2017年11期)2017-11-29
自动化学报(2017年11期)2017-04-04
