
基于增量学习算法的校园网垃圾邮件检测模型
2017-04-17 05:13东一舟毛明荣
计算机应用 2017年1期
陈 斌,东一舟,毛明荣
(南京师范大学 信息化建设管理处,南京 210023)
(*通信作者电子邮箱njnuchenbin@njnu.edu.cn)
基于增量学习算法的校园网垃圾邮件检测模型
陈 斌*,东一舟,毛明荣
(南京师范大学 信息化建设管理处,南京 210023)
(*通信作者电子邮箱njnuchenbin@njnu.edu.cn)
针对大量垃圾邮件对用户带来困扰的问题,提出了一种增量被动攻击学习算法。该方法基于半年时间的对本校校园网内邮件宿主机上所发起的简单邮件传输协议(SMTP)会话日志的采集,针对会话中记录的投递率状态及多种类型的失败消息进行了宿主机行为分析,最终达到有效地适应被检测垃圾邮件源宿主机对最近邮件分类行为的目的。实验结果表明,在执行了若干回合分类策略的调整后,该检测的准确度可以达到94.7%。该设计可以有效地检测内部垃圾邮件宿主机行为,继而从根源上抑制了垃圾邮件的产生。
垃圾邮件宿主机;简单邮件传输协议会话;增量学习;分类器;失败信息
0 引言
如今,垃圾邮件越来越日常性地充斥着使用者的邮箱,这主要是由于电子邮件传递的零成本所致。按照Anti-Abuse消息工作组2011年度发布的调查报告显示,互联网电子邮件总量中超过90%的都是垃圾邮件[1],这不仅浪费了互联网带宽及邮件服务提供商的存储空间,同时干扰甚至伤害了部分用户的正当权益。虽然大多数用户都会忽视垃圾邮件,但由于它的体量巨大,故其带来的综合利润还是足以使得该不端行为存在。更有甚者,垃圾邮件的发送者通过发送嵌入了恶意软件的垃圾邮件,或含有驱动下载攻击类型的有害链接,使得缺乏免疫能力的宿主机成为被其控制的僵尸网络中的一台僵尸机[2],从而迫使它作为其有效垃圾邮件的分发者。有研究报告显示,僵尸网络产生了全球超过82%的垃圾邮件[3]。
解决该问题最通常的策略是,最大限度地为终端用户过滤来自于外部的垃圾邮件,它的实际效果取决于邮件服务商、邮件客户端或邮件代理所提供的过滤器能力[4]。即便终端过滤器可以精准隔离垃圾邮件,但其仍无法从源头上遏制垃圾邮件的发出,故而大量网络带宽还是会被无端消耗,这无疑让本已吃紧的校园网带宽雪上加霜。因此,如何从源头上制止垃圾邮件的产生,成为该领域紧急而重要的问题。如果垃圾邮件宿主机的行为可以尽早被抑制,其所造成的垃圾邮件隐患即可随之被排除。对于如何有效检测及认定垃圾邮件宿主机存在两个主要问题:1)对于企图避开检测的垃圾邮件宿主机而言,其有什么确定的特征可以作为鉴别的依据;2)针对可能存在的海量数据集所产生的简单邮件传输协议(Simple Mail Transfer Protocol, SMTP)日志,检测模型如何建立,其又如何与最新垃圾邮件的行为相适应?
本文从外部邮件服务器和消息分类器运作细节的角度,描述了多种失败消息相应情况下垃圾邮件的行为特征,每一个垃圾邮件宿主机检测的重要特征都是经过了深度学习的,同时使用了一种增量被动攻击学习算法来从大量的SMTP日志中适应性地检测垃圾邮件宿主机。该设计可以帮助校园网络的管理者检测垃圾邮件宿主机,从而抑制这些宿主机的行为,当然该方法在其他机构和场景下也是适用的。
1 相关工作
之所以将垃圾邮件宿主机检测作为研究焦点,是因为僵尸网络类检测与其相关性较低,下面介绍近些年对其的相关研究。垃圾邮件追踪器是一款开发于2007年的基于行为黑名单算法的垃圾邮件宿主机识别系统,它通过具有相似模式的目标域宿主机聚类的收发邮件消息进行分析,垃圾邮件可以较容易地分发至邮件地址的接收者,这些接收者在不同的垃圾邮件宿主机消息域中,这可能使得检测结果变得混乱难以理解[5]。自2011年起,有学者开始研究采集的垃圾邮件消息与具有相似内容的宿主机的识别工作。作者提取了业务日志对垃圾邮件宿主机进行了分组,它们作为既定相似目标的传播源,并主动发现其他的垃圾邮件宿主机的传播行为[6]。相比较而言,该工作并不依赖于任何必须优先建立的垃圾邮件内容或行为观测器,检测可以通过增量学习方式,自动适应于最近的垃圾邮件的行为。2012年有研究人员专门针对大学校园垃圾邮件过滤器接收的输出消息进行尝试性研究,实验使用了时序化测试来检测内部宿主机持续发送垃圾邮件的概率[7]。该工作不依赖于外部的垃圾邮件过滤器,这主要取决于以下两点因素:1)一个SMTP会话可以因为协商过程存在问题而失败,而若一个会话在交互阶段持续保持失败状态,服务器将会发送一封垃圾邮件消息,在该情况下不会针对内容进行过滤。2)一个用户可以向邮件服务器自动转发配置,这也将导致转发器收到包括垃圾邮件在内的邮件,对于一个用户的特定外部账户来说,垃圾邮件过滤器将察觉到来自于邮件服务器的垃圾邮件消息,继而这种检测可以得到更明确的判断结果[8]。
对于增量学习和在线学习,周期性数据分析请求出现于部分应用,其中包括了网络交易分析、匿名检测以及干扰检测等,应用需要周期性地适配近期数据的分类[9]。同样地,垃圾邮件宿主机分类检测,对于从SMTP日志中识别最近的垃圾邮件行为来说是必须的[10]。大多数针对该目标的增量学习方法是基于决策树、神经网络以及向量机的,与之相关的典型设计用例有,将它用于建立静态分类模式,该模式基于之前的实例,并可以从实例中纠错,从而形成新的实例标签。虚拟机已经被证实可以用来较好地分离不同标签的实例,它通过最大化标签实例边缘从而产生不同的超平面,这里的边缘是实例与分离超平面之间的距离,该方法可通过识别每一个新的实例的向量支持能力,进而调节虚拟机增量分类,它的优势是可以保持之前有用的实例作为支持向量,并同步获取有效的更新步骤信息作为知道依据[11]。然而,虚拟机超平面方法在分发出现错误的情况下,未必能进行有效的调节,换句话说,当监控实例的分发与固有的支撑向量存在明显的差异时,监控实例可能由于支撑向量概率的减小而导致分类错误。出于对更新步骤效率的考虑,同样可以用在线学习的方法来解决周期性调整分类的问题。在线学习过程中,每一个标签实例都会在被用于分类器更新处理后被丢弃。与增量学习的设置不同,其无需维护之前的标签实例,更新步骤只需要使用一个标签实例就可以完成基本的执行动作,更新分类器可以弹性地适配多种实例的分发。一些类似模拟人类视神经控制系统的图形识别感知器算法,以及基于边界的算法已经被证实在大范围的应用中都是非常有效的。分类器更新通常是基于各类特征表示的,相对支持向量机(Support Vector Machine, SVM)、提升方法(boosting)、最大熵方法等“浅层学习”方法而言,深度学习所学得的模型中,非线性操作的层级数更多。浅层学习依靠人工经验抽取样本特征,网络模型学习后获得的是没有层次结构的单层特征;而深度学习通过对原始信号进行逐层特征变换,将样本在原空间的特征表示变换到新的特征空间,自动地学习得到层次化的特征表示[12]。为了与分类器的垃圾邮件分类任务相对抗,攻击者通常都会尝试通过诱骗的方式使得分类器产生错误结果从而躲避检测。在对抗性研究领域,已经有一些专门针对精准化分类器而建立的伪装攻击研究,这些研究的贡献就在于,对恶意攻击及正常分类实例的最小代价可以作出合理化区分及评估[13]。对于攻击者而言,垃圾邮件制造者不能对外部服务器的回复消息进行修改,这也就限制了其对邮件的控制权,因此,使用攻击学习的作用是微乎其微的。本文的主要工作将集中在对持续改变其行为的垃圾邮件的适应性检测上。
2 垃圾邮件行为特征分析及检测模型
垃圾邮件行为失败消息特征分析及检测分为五个阶段,即:1)通过干扰检测系统对校园网络与互联网之间的SMTP交互日志进行捕获;2)从日志中提取出校园网内部宿主机与外部宿主机初始会话中的SMTP报文;3)计算来自于每台内部宿主机个体的多种类型SMTP会话投递成功及失败消息的数量及类型;4)按照宿主机状态,通过行为检测的方式,针对训练集中的内部宿主机打上垃圾邮件源标签或正常宿主机标签;5)在此基础上,可以通过增量学习算法持续检测校园中的垃圾邮件宿主机。特征分析和检测常用的两种分类方法分别为基于规则的方法和基于机器学习的方法[14]。针对分类后的特征结果集合,淘汰历史样本集中的非支持向量,将支持向量同新增样本一起训练,以达到增量学习的目的[15]。一旦通过检测确认当前存在垃圾邮件行为,则会将发现的垃圾邮件宿主机列表发送给管理者从而对其加以限制。
图1描述了部署于计算中心的专门用于监控SMTP会话的宿主机。该宿主机内嵌了网络监控卡以进行网络交互的检测,其检测对象是一台位于校园网关的思科路由器。由于本文只关注于校园内的垃圾邮件宿主机,所以对来自于外部的SMTP会话进行了忽略处理。值得注意的是,垃圾邮件僵尸网络可能会通过基于网页的邮件服务发送垃圾邮件,同样也可能通过SMTP服务来发送,故而很难在没有对SMTP会话进行检测的前提下来定义可靠的垃圾邮件特征。一种可行的解决方案是按照短会话模式来查找SMTP会话日志,该方法背后的基本原理是一个失败会话的终结必然在失败当下立即发生,所以该会话将比正常情况下要短。换句话说,如果一个宿主机经常在SMTP会话时发生短会话,则可以认为该会话是容易失败的,并且其容易被外部干扰所控制,从而成为一台垃圾邮件宿主机。真正难于被可靠检测到的垃圾邮件发送者,是基于安全超文本传输协议(Hyper Text Transfer Protocol over Secure socket layer, HTTPS)的页面邮件会话,对于该种情况,干扰检测系统可以检测到垃圾邮件宿主机,但发送者可以通过行为随机化处理轻易地躲避检测,所以其需要检测垃圾邮件的加密通道,这不在本文的研究范围之内。
网络干扰检测系统通过宿主机监控及关键日志信息进行总结,以此来进行对SMTP会话的分析,这其中包括了邮件接收地址和回复码。以下是采集自192.168.92.154设备的日志消息示例,由于其主机网络互连协议(Internet Protocol, IP)地址被垃圾邮件检测扫描并被列入黑名单后,接收到了一条来自于SMTP服务器223.1.106.1的拒绝消息,头两行是消息的时间戳以及会话标识码,对其解析后可知消息出现的时间,以及区分SMTP会话消息对[DENY,605]的意思,是SMTP响应码605与邮件命令在请求响应中虽被拒绝但状态是保持接续的。该日志不包含邮件体,否则日志内容的体积将会非常庞大,并且这会导致严重的隐私泄露,日志中的消息包括了多种类型的成功分发和失败情况,同时还有一些关键域信息。通过这些检测细节信息,已经足够对一个宿主机是否进行了垃圾邮件的分发行为作出判断。
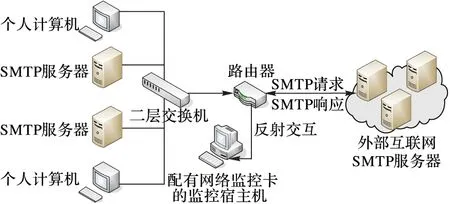
图1 计算中心宿主机SMTP会话监控架构
一个来自于服务器的SMTP响应消息,标志着一个SMTP邮件分发会话的成功与失败状态,如果失败总是发生,意味着其异常等级较高。起初试图通过SMTP响应码对日志中的失败消息进行分类,但事实上响应码和真正的失败原因是多元的关系,无法做到一一对应。表1中列出了一些实验过程中的实例,从中可以看出有很多比响应码更合理的键值选项,这些键值选项都是从多种失败消息中提取的。

表1 相同SMTP响应码情况下不同响应消息示例
另外,邮件服务器可以针对同样的失败原因给出不同的响应消息。例如由于黑名单而造成的邮件阻塞在表1中就给出了多种列举,所以在实验过程中通过人工识别键值的方式,根据语义分析对垃圾邮件进行了标注,并基于失败原因的键值域组织了响应消息。作为一个检测系统,在默认SMTP策略脚本中并没有列出所谓的期望回复结果,只是在默认脚本中添加了附加键值信息,以帮助其进行垃圾邮件会话的识别。附加信息包括了日志是否成功转发、邮件头的格式、邮件回复路径、发送者以及接收者的地址和主题等。
在记录了SMTP会话日志后,就可以开始针对SMTP会话进行成功投递及失败消息的统计。按照SMTP的转发实现规则,失败消息存在多种不同的语义,按照实际情况可以进行分类,主要分为6大类,实验步骤中的键值是通过人工设定的。表2中列出了典型的键值子集,这些键值在实验过程中的分类处理中都有用到,并且在失败消息中以模糊匹配加正则表达式的方式进行键值的查找,需要说明的是,在实验中的键值是不完备的,因为针对数百GB的日志中的潜在键值是无法穷举的。

表2 针对各种失败原因的语义键值归类
类似拉丁语义检索的自然语言处理技术,可以对相似语义的上下文语句的检索匹配有所帮助。针对邮件的不同区域,包括邮件标题和正文,可以进行概念分析、分类、标引、描述和处理,形成具有语义关联的资源元数据集合,并使用RDF(Resource Description Framework)和OWL(Web Ontology Language)语言进行语义层面的表述和描述,通过适应于邮件类型的自然语言关系模型学习处理,结合针对邮件上下文的语义分析,形成用以与分类器预定义分拣数据集较为匹配的语义关键词或语句。回复消息通常只包含一两个短句,示意失败的键值通常只在消息中出现一次。回复消息中隐含的失败原因可以对垃圾邮件宿主机的行为产生影响,在这些原因中,由于发送域可能被篡改,所以必须针对失败域进行核查,因为这往往是垃圾邮件的征兆所在。在接收到的失败消息中,标识为邮件接收者未找到的类别通常有以下三种情况:目标邮件地址已经过期停用,但垃圾邮件制造源依然在持续向其发送邮件;目标邮件地址由于解析错误而造成拼写问题,这种解析错误是由于垃圾邮件制造源的恶意探测器在网络上扫描目标源后,对其地址试探性轮询分析产生的过程结果;另外,垃圾邮件制造源也会随机产生邮件地址作为目标邮件地址,对于之前已经发送过垃圾邮件的宿主机而言,对端服务器可能会将其列入IP黑名单,每次接收到邮件的检索过程中,可能会对这些宿主机的邮件进行退信处理。
对于外部邮件服务器,由于其响应消息中的一些情况及其状态并不确定,所以实验中将其归入单独的类别。还有一类特别的不常用命令对,例如SMTP会话数据无响应,这类错误通常与响应码702相关联,所以将该响应码作为该分类的键值。对于校园里的每一个IP地址,均可按照相应键值计算其回复消息数量,该统计结果对识别疑似垃圾邮件宿主机是有帮助的。实验中使用了8维特征向量对内部宿主机的每一个实例的SMTP会话进行了描绘,该特征向量中的八元组其中第1元记录的是成功投递情况,第2至第7元记录的是失败消息的6种分类(如表2),第8元标识了宿主机是否是邮件服务器。需要说明的是,如表2所列举的,域名系统(Domain Name System, DNS)过滤器或者IP黑名单的方法都只是导致失败的一部分原因,也就是说,垃圾邮件会话的动机检测机制对象是多样的,并且是随着实际情况的演变而变化的,特别在针对外部邮件服务器的情况下,更是如此。
实验通过使用内部宿主机行为结果作为训练集,并且手工检测以下邮件头区域,以建立基本的垃圾邮件宿主机判断机制。主要邮件头区域为:主题,通过检查邮件消息的主题,判断其是否疑似为垃圾邮件,例如其是否包含了攻击性关键词,该区域通常是非常有代表性的垃圾邮件识别信息源;发送者,垃圾邮件发送者通常都会对自己进行伪装,例如使用随机产生的邮件地址或者域名,故对此域进行检查也是非常有必要的;接收者,该域可以在垃圾邮件中被随机产生,所以一旦检测到有序列化的随机目标的行为产生,则可以断定其来源为垃圾邮件宿主机。通过扫描传输控制协议(Transmission Control Protocol, TCP)绑定的25号端口,并检查宿主机域名称,进而判断宿主机是否为SMTP服务器。
当一系列打着不同标签的报文到来时,分类器需要不断更新以保持与最新的垃圾邮件行为相适配,在此使用了被动攻击增量学习算法,用以对当前分类器的邮件样本分类工作进行调整。对于每一个潜在的样本实例,都需要做如下两步更新操作,即纠正当前分类器的预测错误,并且通过主动调整来更新当前分类器。最终,当前已经被最小化错误处理后的分类器将作为下一次数据集采集选择的分类器而使用,进而实现优化分类的精确度提升。前述方法的具体标记需要在对其建模进行公式化之前进行定义,打上了标签的周期化数据集Pt在周期t时被采集,|Pt|的实验标签都是成对的,在{(u1,v1),(u2,v2),…,(u|Pt|,v|Pt|)}实例数组中的un是宿主机在八元组周期观测值条件下的SMTP行为,相应的类标签vn是垃圾邮件或非垃圾邮件标识符。设置kt为周期t下分类器组成向量的权重,当每一个实例un∈Pt到达时,被更新的分类器kt+1都会修正之前kt分类器的错误,所以kt也只是进行最小化的修正。如果un从kt获得了不正确的预测值,则kt的调节将被un的自身边界值所取代。设置Q为kt的基于(un,vn)键值对的更新模型,分类器优化调整可以公式化描述如下:
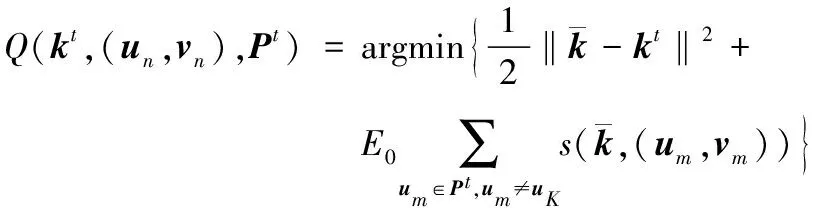
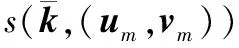
在按照上述公式对kt对应的分类器进行更新时,{Q(kt,(uK,vK),Pt):1≤n≤|Pt|}是新分类器的备选键值组对。为防止新的分类器过多地被当前分类器影响,选择策略会按照最准确的分类性能在Pt中挑选最合适的分类器,当超过一个已经更新过的分类器具有非常高的分类准确性时,则可以选择该分类器中与kt差别最小的,因此新的分类器kt+1可以按照该策略从备选分类器中进行选择。按照上述对基础过程的描述,垃圾邮件过滤器的更新所使用的增量学习算法流程如下所述。
步骤1 初始化数据集Pt、分类器kt以及分类优化调整内核函数Q。
步骤2 在每一个周期t,按照所采集数据的具体不同情况对数据集Pt进行更新,以用于增量学习。

算法1 增量学习算法形式语义建模。
1)
Initialize:k1=(0,0,…,0);
2)
fort=1,2,…do
3)
Recpt_Collect_data(Pt);
4)
5)
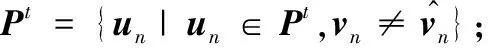
6)
foreachun∈Ptdo
7)
8)
9)
end
10)
choose
11)
12)
end
3 实验及分析
通过实验证实增量学习算法对垃圾邮件分类检测的准确性及其性能优劣的影响。实验在核心机房搭建的信息系统平台上实施。实验环境基础配置为:八核4.8GHz×4CPU、64GB内存、16TB硬盘,双200GB/s网卡的机架型服务器。虚拟机操作系统选择了64位的Linux,虚拟机最大并发数为256台。实验采用基于径向基内核(RadialBasisFunction,RBF)的支持向量机(SupportVectorMachine,SVM)以实现分类器的设计,同时使用Matlab算法分析包对读取参数与内核参数进行有效开采和识别。在实验中,分类器是定期增量更新的,这里更新周期为6h,更新对象是打了标签的数据集,分类器kt在周期t中由实例标签键值对Pt进行更新。增量学习算法的性能在不同设置条件下,对分类器错误修正的实际效果是不同的,同时在分类器更新后这种差别又可以被最大限度地减小,在选择潜在分类器时起到了最小化评估错误的作用。按照分类器性能进行评估时,需要同时强调垃圾邮件和非垃圾邮件宿主机的分类效果,所以测量平均分类准确率也是由这两大类别共同计算得出的。表3中列出了周期为月计的实验数据集,每行中的数字是具有邮件行为的宿主机数量,垃圾邮件宿主机数量以及非垃圾邮件宿主机数量。对于每一个实例来说,数据集中的un包含了第2章特征分析模型中介绍的八元组向量中的SMTP行为,每一个un的标签都被打上了垃圾邮件(vn=+1)或非垃圾邮件(vn=-1)。
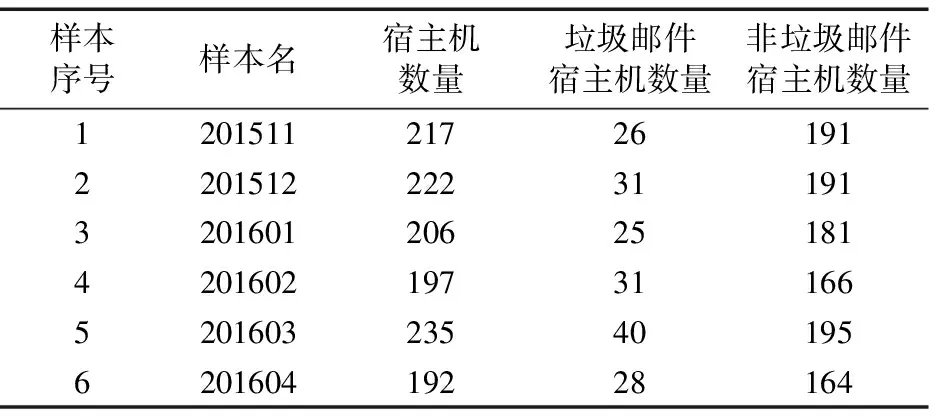
表3 2015-11至2016-04校园网内垃圾邮件宿主机统计
在不同E0和E(E代表E0的权衡结果,1代表校正,0表示不校正)调节系数背景下,针对混合邮件集的增量学习算法检测结果如表4所示,实验中尝试了多种E0和E值情况下的调节效果,在表4中只列出了部分有代表性结果。根据调节效果显示,大多数分类精确度都是通过t=2或t=3情况下的增量学习分类调节后提升的,增量学习算法当E=1时有着最优的检测能力,根据结果显示,从第2个周期开始平均分拣准确度在80%以上,并保持在稳定水平。另外,当E0=0,E=1以及E0=0.25,E=1时,较E0=0.5,E=1时准确性更稳定。对于分类器产出者来说,当一个新的分类器衍生出之后,产出者错误检测修正权重将会变小以避免过拟合问题的出现,增量学习算法在本实验中保守地采取了最小化调节效果。
表4 增量学习算法在不同参数情况下的检测结果 %
Tab.4Detectionresultofincrementallearningalgorithmwithdifferentparameters%
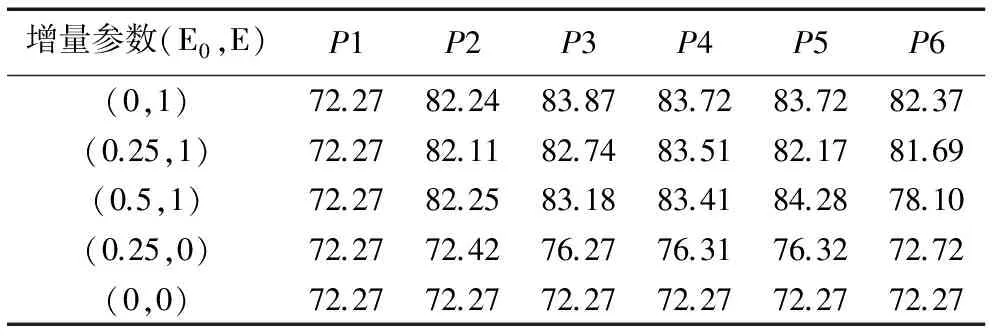
增量参数(E0,E)P1P2P3P4P5P6(0,1)72.2782.2483.8783.7283.7282.37(0.25,1)72.2782.1182.7483.5182.1781.69(0.5,1)72.2782.2583.1883.4184.2878.10(0.25,0)72.2772.4276.2776.3176.3272.72(0,0)72.2772.2772.2772.2772.2772.27
表5中显示了在不同增量学习配置类条件下的分析细节,主要为E0=0.25,E=1以及E0=0,E=1两种情况。从表5中可以看到非垃圾邮件宿主机(NoneSpamHost,NSPH)的识别准确度普遍低于80%,一些不确定的宿主机也由于其接收到了失败响应而被认定为垃圾邮件宿主机。非垃圾邮件宿主机可以误导预测结果并降低综合检测准确度。在实践中,类似错误识别的情况已经通过白名单的方式给予了纠正,所以综合准确度显著提高,对垃圾邮件宿主机(SpamHost,SPH)的3到4个周期的平均检测识别准确度达到了90%以上。垃圾邮件宿主机与非垃圾邮件宿主机基于不同增量学习配置条件下的调节预测准确度结果如图2所示。

表5 垃圾邮件宿主机与非垃圾邮件宿主机的检测结果
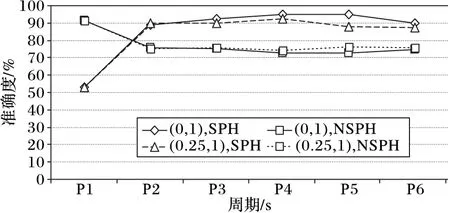
图2 SPH与NSPH基于不同增量学习配置调节的预测准确度
除了讨论特征权重的重要性,实验通过手工检测SMTP日志的研究方法,对可能误导检测结果的因素进行了分析,主要有以下几类情况:1)“接收者未响应”应答,通常是由于接收者Email地址错误或邮件格式出现了问题,特别是当已经超期停用的邮件地址添加在了接收列表中的情况下,很容易出现这种问题。出现类似错误通常的主要原因是宿主机向邮件列表进行了宣告,称其可以持续接收响应,这种情况一般可以通过邮件列表或白名单列表更新并修正。在该情况中,还发现部分邮件地址为假造的情形,由于连续出现了多次雷同的邮件地址,其均投递失败,故确定归类为该情况。2)邮件服务器“黑名单”应答,该应答意味着某些用户账号可能曾经被盗取后用来发送垃圾邮件,这种情况下邮件服务器管理员可以通过解析邮件日志的方式对该账号进行确认分析。3)垃圾邮件宿主机接收到新的失败响应,通常这种情况并不多见,但在实验中仍然对其原因进行了分析。当一个实例看起来和过去的邮件账户中的命令相类似的话,其成功率相对较高。另外,一个新的宿主机在观测周期内,只会初始化少量的SMTP会话,其观测行为的缺乏可能是错分类中偶然的结果。
垃圾邮件发送者往往都会企图躲避检测,但躲避毕竟不可能总是成功的,因为其无法控制外部邮件服务器,根据表2中的失败原因键值归类情况,垃圾邮件发送者需要通过域认证,在垃圾邮件会话中避开非正常的命令,并且频繁地拒绝传递垃圾邮件。邮件接收者地址列表需要很仔细地采集以确保列表中的每一项都是有效的,因为邮件地址可能是非正确的,或者已经过期。然而在网页或磁盘组中检索邮件地址往往是不精确的,垃圾邮件发送者也不可能在海量数据中手工认证邮件地址的有效性,但任何非正确的转发或向过期地址的转发都将导致失败的结果。另外,邮件服务器列出了一个黑名单以阻止垃圾邮件的进入企图,宿主机在控制了垃圾邮件转发的同时,也会不断补充更新其黑名单内容。
本实验与同类垃圾邮件分拣实验相比,最本质的不同是,本实验使用的是增量学习算法为基础的分类器,而其他实验主要以堆叠器编码机为主。相比较而言,使用堆叠器编码机的分类器其优点是分拣稳定速度快,准确度在有条件背景下能快速达到较高值;但其缺点在于通常与分拣对象数据集属性强关联,针对著名的Enron数据集则效率很高(主要体现在1,2,3,5版本,4版本并不稳定),但关联其他类型数据集则效果并不明显。而使用增量学习算法为基础的分类器,则与数据集属性没有强关联关系,对各种数据集效果差异并不明显,但分拣准确度提升和稳定需要一定周期,且准确度最高值低于堆叠编码机方式。
本实验的检测工作依赖于对独立宿主机的统计,这些独立宿主机以IP地址为识别符号,所以对主机地址做过网络地址转换(NetworkAddressTranslation,NAT)映射的内网地址,或者对使用了动态主机配置协议(DynamicHostConfigurationProtocol,DHCP)获取的地址而言,可能会存在不确定性。对于前者来说,网络管理员仍可以识别近似源地址继而分析其垃圾邮件行为,但需要对NAT所对应的真实设备进行处理;对于后者而言,垃圾邮件宿主机可能被认为来自于多个源,同样地,网络管理员可以对实际分配IP地址的DHCP服务器进行分析,以查找到真实的地址源。最难处理的情况是由移动终端获取到一个动态IP地址,并且该地址又是做过NAT映射的。当一个移动终端在某一个点稍作停留,其垃圾邮件发送行为可能就会演变得非常严重,除非当前垃圾邮件已经造成了拥堵。因此,一个可能的解决方案是,通过灰名单的方式仅仅阻塞该IP地址接收拥堵失败消息,如果该源是一个正常的邮件服务器,一段时间后它将会再次发起请求。该途径至少阻止了垃圾邮件移动终端对其停留区域其他终端的垃圾邮件的转发。
4 结语
本文使用了增量学习算法用于垃圾邮件宿主机的检测工作,该工作基于大量的SMTP会话中嵌套的成功及失败转发消息,以及其中嵌入的邮件服务器信息。增量学习算法可以有效地根据待检测者情况调节分类器,以适配垃圾邮件宿主机的多变行为,故而垃圾邮件发送行为可以被识别甚至被弱化。实验结果显示,增量学习算法可以对检测者在很短的周期内进行调节,并且检测成功率可以大幅度提升。特征分析结果说明对于垃圾邮件宿主机检测来说,IP黑名单是其中最重要的特征。对垃圾邮件行为的观测是通过SMTP绑定的,然而研究中也发现有些宿主机可能通过基于SSL(SecureSocketLayer)安全协议之上的简单邮件传输协议(SimpleMailTransferProtocolOverSSL,SMTPS)或者纯网页邮件服务发送垃圾邮件,由于从加密会话中观测纯文本信息是不可能的,宿主机可以通过模仿正常邮件网络行为,从而轻易躲避检测,所以找到一种健壮而彻底的解决方法是接下来的研究方向。
)
[1] 杨峰,曹麒麟,段海新,等.基于DNSBlocklist的反垃圾邮件系统的设计与实现[J].计算机工程与应用,2003,39(7):11-12.(YANGF,CAOQL,DUANHX,etal.Designandimplementationofananti-spamsystembasedonDNSBlocklist[J].ComputerEngineeringandApplications, 2003, 39(7): 11-12.)
[2]LIUWY,WANGT.Onlineactivemulti-fieldlearningforefficientemailspamfiltering[J].KnowledgeandInformationSystems, 2012, 33(1): 117-136.
[3]BERTINIJR,ZHAOL,LOPESAA.AnincrementallearningalgorithmbasedontheK-associated graph for non-stationary data classification [J].Information Sciences, 2013, 246: 52-68.
[4] COSTA J, SILVA C, ANTUNES M, et al.Customized crowds and active learning to improve classification [J].Expert System with Application, 2013, 40(18): 7212-7219.
[5] HU L S, LU S X, WANG X Z.A new and informative active learning approach for support vector machine [J].Information Sciences, 2013, 244: 142-160.
[6] 王学军,赵琳琳,王爽.基于主动学习的视频对象提取方法[J].吉林大学学报:工学版,2013,43(S1):51-54.(WANG X J, ZHAO L L, WANG S.Video object extraction method based on active learning SVM [J].Journal of Jilin University (Engineering and Technology Edition), 2013, 43(S1): 51-54.)
[7] 丁文军,薛安荣.基于SVM的Web文本快速增量分类算法[J].计算机应用研究,2012,29(4):1275-1278.(DING W J, XUE A R.Fast incremental learning SVM for Web text classification[J].Application Research of Computers, 2012, 29(4): 1275-1278.)
[8] LENG Y, XU X Y, QI G H.Combining active learning and semi-supervised learning to construct SVM classifier [J].Knowledge Based Systems, 2013, 44(5): 121-131.
[9] 刘伍颖,王挺.集成学习和主动学习相结合的个性化垃圾邮件过滤[J].计算机工程与科学,2011,33(9):34-41.(LIU W Y, WANG T.Ensemble Learning and active learning based personal spam email filtering [J].Computer Engineering & Science, 2011, 33(9): 34-41.)
[10] ALI HAJI N, IBRAHIM N S.Porter stemming algorithm for semantic checking [EB/OL].[2016-07-16].https://www.researchgate.net/profile/Noraida_Haji_Ali/publication/260385215_Porter_Stemming_Algorithm_for_Semantic_Checking/links/5584e9d708ae7bc2f448474f.pdf.
[11] 吴伟宁,刘扬,郭茂祖.基于采样策略的主动学习算法研究进展[J].计算机研究与发展,2012,49(6):1162-1173.(WU W N, LIU Y, GUO M Z.Advances in active learning algorithms based on sampling strategy [J].Journal of Computer Research and Development, 2012,49(6): 1162-1173.)
[12] 李艳涛,冯伟森.堆叠去噪自编码器在垃圾邮件过滤中的应用[J].计算机应用,2015,35(11):3256-3260.(LI Y T, FENG W S.Application of stacked denoising autoencoder in spamming filtering [J].Journal of Computer Applications, 2015, 35(11): 3256-3260.)
[13] YANG J M, LIU Y N, ZHU X D, et al.A new feature selection based on comprehensive measurement both in inter-category and intra-category for text categorization [J].Information Processing & Management, 2012, 48(4): 741-754.
[14] 沈承恩,何军,邓扬.基于改进堆叠自动编码机的垃圾邮件分类[J].计算机应用,2016,36(1):159-162.(SHEN C E, HE J, DENG Y.Spam filtering based on modified stack auto-encoder [J].Journal of Computer Applications, 2016, 36(1): 158-162.)[15] 张文兴,樊捷杰.基于KKT和超球结构的增量SVM算法的云架构入侵检测系统[J].计算机应用,2015,35(10):2886-2890.(ZHANG W X, FAN J J.Cloud architecture intrusion detection system based on KKT condition and hyper-sphere incremental SVM algorithm [J].Journal of Computer Applications, 2015, 35(10): 2886-2890.)
This work is supported by the Digital Campus Construction Project of Nanjing Normal University (2013JSJG069).
CHEN Bin, born in 1978, Ph.D., engineer.His research interests include distributed computing, cloud computing.
DONG Yizhou, born in 1978, experimentalist.His research interests include Internet of things application.
MAO Mingrong, born in 1958, senior experimentalist.His research interests include network application.
Spam detection model of campus network based on incremental learning algorithm
CHEN Bin*, DONG Yizhou, MAO Mingrong
(InformatizationOffice,NanjingNormalUniversity,NanjingJiangsu210023,China)
Concerning the problem brought by a large number of spam, an incremental passive attack learning algorithm was proposed.The passive attack learning method was based on the Simple Mail Transfer Protocol (SMTP) session log initiated by the email host in the campus during half a year.Analysis on the status of delivery rate and many types of failure message of the host behavior in the session record was conducted, and the effective adaptation was ultimately achieved by detecting spam source host behavior on the recent email classification.The experimental results show that after implementing several rounds of classification strategy adjustment, the detection accuracy of the proposed model can reach 94.7%.The design is very useful to effectively detect internal spam host and control the spam from the source.
spam host; Simple Mail Transfer Protocol (SMTP) session; incremental learning; classifier; failure information
2016-08-04;
2016-09-13。 基金项目:南京师范大学数字校园建设研究项目(2013JSJG069)。
陈斌(1978—),男,江苏南京人,工程师,博士,CCF会员,主要研究方向:分布式计算、云计算; 东一舟(1978—),男,江苏海门人,实验师,主要研究方向:物联网应用; 毛明荣(1958—),男,江苏靖江人,高级实验师,主要研究方向:网络应用。
1001-9081(2017)01-0206-06
10.11772/j.issn.1001-9081.2017.01.0206
TP393.08
A
猜你喜欢
北京航空航天大学学报(2022年5期)2022-06-06
当代陕西(2022年6期)2022-04-19
英语文摘(2021年10期)2021-11-22
当代水产(2021年8期)2021-11-04
电脑爱好者(2020年18期)2020-09-26
计算机与网络(2020年4期)2020-04-20
妇女生活(2019年1期)2019-01-17
电脑爱好者(2017年9期)2017-06-01
计算机世界(2009年35期)2009-11-17
网络与信息(2009年9期)2009-10-30
