
一种基于语音活动检测的声源定位方法
2017-04-10 08:09杨立春
电脑知识与技术 2017年4期

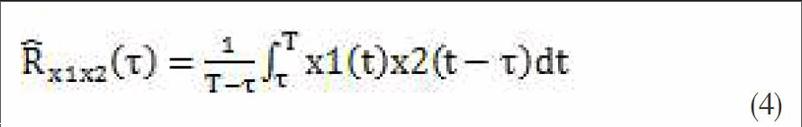

摘要:聲源定位的准确程度对语音增强的效果影响很大,因而成为语音增强领域的重要研究方向。本文提出一种基于语音活动检测的实时处理声源定位方法,仅在目标语音段进行判定。相对传统声源定位方法,可以明显提高判定的有效性. 仿真实验表明本文方法在实时处理系统中能更有效的实现声源定位。
关键词:声源定位;语音活动检测;语音增强
中图分类号:TP302 文献标识码:A 文章编号:1009-3044(2017)04-0251-02
A Sound Source Localization Method Based on Voice Activity Detection
YANG Li-chun
(Institute of Intelligent Control Technology, Zhejiang Wanli University, Ningbo 315101, China)
Abstract: The accuracy of sound source localization has a great influence on speech enhancement, which is an important study direction in the field of speech enhancement. This paper proposes a real-time processing of sound source localization method based on voice activity detection which decision lie only in target speech segments. Compared with the traditional sound source localization method, the proposed method can significantly improve the effectiveness of the determination. The simulation experiment shows that the proposed method is more effective in real-time system for realize sound source localization than that its counterpart.
Key words: Sound Source Localization;Voice Activity Detection;Speech Enhancement
麦克风阵列语音增强[1]是语音通讯和交互领域的关键技术,其效果直接影响目标语言质量的好坏,而声源定位则是麦克风阵列语音增强的重要支持。当前语音定位技术是利用时延估计实现的,时延估计技术主要包括广义互相关(Generalized Cross Correlation, GCC)[2]算法和最小均方自适应(Least Mean Square, LMS)[3]滤波两种方法,其思想都是寻找语音段内能量最强的方向。在实时处理系统中,由于各种环境干扰,如语音、音乐、机器以及汽车等,造成无法有效和正确估计目标信号的方向。
为了解决这个问题,本文提出一种基于语音活动检测(Voice Activity Detection, VAD)的目标语音定位方法,使得声源定位仅在语音段进行,可以规避在非语音段进行声源定位而导致的定位错误发生,进而可以提高声源定位的有效性。
1基于语音活动检测的广义互相关的声源定位
为了获得目标声源的位置,需要得到其在两个麦克风的时延,本文的方法是基于GCC的无偏互相关函数实现时延估计。假定目标声源与噪声独立不相关,则两个麦克风获得的信号分别可用式(1)和(2)表示:
其中:x1与x2分别表示两个麦克风获得的信号;t表示时刻;s表示目标语音信号;v1,v2表示两个麦克风接收到的噪声信号;τ表示两个麦克风接收到目标语音信号的时延。
则两个麦克风接收到信号的互相关函数可表示为式(3)形式:
其中
其中T为观测时间。由于实际采集的是离散信号,所以式(4)可改写成式(5)的形式:
其中n表示采样点。在式(5)中,我们可以近似认为
本文的语音活动检测方法是基于WebRtc[4]中的VAD算法,该方法首先在频域内把信号分成6个子带,并分别计算每个子带的能量;然后使用高斯混合模型 (Gaussian Mixture Model, GMM)分别计算语音和非语音存在的概率,并通过相应的概率来判断语音和噪声。GMM的噪声和语音模型如式(6)所示:
其中:xk是选取的特征量,在WebRtc的VAD中具体是指子带能量;rk是包括均值uz和方差sita的参数集合;z=0,代表噪声;z=1,代表语音。
2 仿真实验
实验中,不失一般性,我们采用2个麦克风组成一个小阵列进行声源定位,阵元间距为4cm,采样率为16KHz。分别利用传统的广义互相关算法和本文提出的基于VAD的算法进行验证。
实验环境在一个普通会议室内,测试10次,每次语速和目标语音间隔不同,信噪比均为10dB左右,干扰源为风扇、机器以及嘈杂说话声(babble),每次录音时,目标声源分别在位于阵列中心0°到180°每隔20°共10个位置分别说一句话,以模拟声源移动。每次实验录音长度均选取45秒,然后使用本文算法和GCC方法对这10个录音进行计算,对结果进行平均,其结果如图1所示:
从图1中可以看出,本文的算法在实时系统中无论目标声源位于哪个位置,估计的方向与实际方向误差很小,因而表明本文提出的方法具有较好的准确性和鲁棒性。
3 总结
实际应用中,由于目标信号位置可能会发生变化,因此实时处理系统需不断判定目标声源位置,本文提出的仅在语音段进行声源位置判定,可以有效避免在非语音段判定造成的定位错误,因而具有较好的理论意义和实际应用价值。
参考文献:
[1] 杨立春, 叶敏超, 钱沄涛. 基于多任务稀疏表达的二元麦克风小阵列语音增强算法[J]. 通信学报, 2014, 35(2):87-94.
[2] Knapp C H,Carter G C, The Generalized Correlation Method for Estimation of Time Delay[J]. IEEE Transactions on Acoustics, Speech and Signal Processing. 1976, 24(4):320-327.
[3] Widrow B, Hoff M E. Adaptive switching circuits[J]. WESCON Conv. Rec, 1960, 5(3): 96-104.
[4] https://webrtc.org
