
Hadoop集群效能建模与评价
2017-04-05 01:09:47冯东煜朱立谷张雷
中国传媒大学学报(自然科学版) 2017年1期
冯东煜,朱立谷,张雷
(中国传媒大学 计算机学院,北京 100024)
Hadoop集群效能建模与评价
冯东煜,朱立谷,张雷
(中国传媒大学 计算机学院,北京 100024)
随着大数据技术的研究深入,Hadoop集群效能问题越来越引起业界的关注。如何有效地利用计算资源,使有限的资源发挥出最大的效能,成为大数据应用中一个迫切需要解决的问题。本文对Hadoop集群效能进行建模研究,建立以Hadoop集群单位时间完成的任务量与消耗能耗的比值来定义的Hadoop集群效能度量模型,并且基于该模型给出测量Hadoop集群效能所需的参数和度量方法。对不同硬件配置的Hadoop集群,选取CPU密集型和I/O密集型任务进行效能测试与评价。由测试结果可以得出机架服务器组成的Hadoop集群适合处理TB级的大规模数据,而PC组成的Hadoop集群更适合在要求不十分苛刻的场景处理10GB级及以下的中小规模数据,对生产环境中的Hadoop集群选型具有一定指导意义。
Hadoop;集群;效能;MapReduce
1 引言
随着大数据技术不断发展和大数据应用的不断膨胀,Hadoop作为目前最广泛使用的大数据平台,Hadoop集群能耗问题成为业界的关注重点如何有效地利用计算资源,使有限的资源发挥出最大的效能,提高Hadoop集群的效能以降低运行成本成为大数据应用中一个迫切需要解决的问题[1]。
但是现有的Hadoop集群设计选型都缺乏对系统构建最根本的因素——集群效能进行考虑,并与集群处理的负载建立关联。为此,本文对Hadoop集群效能进行建模研究,提出Hadoop集群效能度量模型。在Hadoop集群效能度量模型的基础上,对Hadoop集群进行效能测试,分析效能规律,进而对不同硬件架构的Hadoop集群效能进行评价。
2 Hadoop集群效能建模
根据效能的通用定义[2-4]形式,计算系统的效能是单位成本完成的任务量,本文仅考虑集群能耗作为成本,分别定义集群消耗的能量和完成的任务,称为“能耗”和“任务量”。因此针对Hadoop集群,我们定义效能为Hadoop集群单位时间内完成的任务量与所消耗能耗的比值,即

(1)
然后分别从能耗和任务量分别进行建模。
2.1Hadoop集群能耗模型建模
首先考察“能耗”因素。本文的研究仅考虑计算机和交换机等网络交换设备的能耗。定义Hadoop集群的能耗为:
E(T)=Ec(T)+En(T)
(2)
式中:Ec(T)为计算机的能耗,En(T)为各种网络设备的能耗,能耗单位均为焦耳。
2.2Hadoop集群任务量模型建模
考察“任务量”因素。任意一个计算本质上包含2个部分的任务[5]:1.执行算法的运算任务;2.I/O任务。对于前者,均由CPU完成(不考虑GPU对媒体数据的处理),因此可以采用CPU的工作状态来度量;对于后者,可以分为2种I/O操作:本地磁盘I/O和网络I/O。
设W(T)是T时间内的任务量:
W(T)=Wc(T)⊕1[Wd(T)⊕2Wn(T)]
(3)
式中:Wc(T)为CPU的运算量,Wd(T)为磁盘读写运算量,Wn(T)为网络收发运算量,符号⊕1和⊕2表示聚集函数。下面研究的量纲统一方法。Wc(T)可以用“执行的浮点运算量”来度量。对于任意时刻t,可得Wc(T)的计算公式:
Wc(T)=Cf(t)×Cu(t)×Cc×Cfn
(4)
式中:Cf(t)为t时刻的CPU的频率,Cu(t)为t时刻的CPU使用率,Cc为CPU核心数,Cfn(t)为每周期浮点运算次数。CPU每次进行浮点运算的对象都是2个长度为机器字长的值。式(4)可以写成:
Wc(T)=Cf(t)×Cu(t)×Cc×Cfn×2Cmw
(5)
式中:Cmw为机器字长。Wc(T)的单位为:
1024M×cycles/sec×1/cycles×bit
=1024MB/8=27MB
于是,将CPU运算量的量纲统一到了MB,与网络I/O和磁盘I/O相同。
2.3Hadoop集群效能模型
定义 效能在T时间内Hadoop集群的效能η(T)定义为完成的任务量W(T)与消耗的能量E(T)的比值:
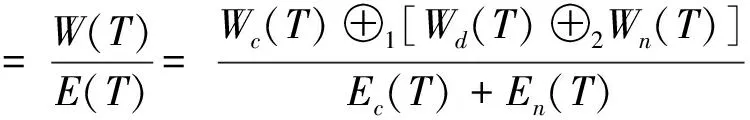
E(T)≠0
(6)
3 Hadoop集群效能度量方法
对于Hadoop集群,设存在N个节点,记为ci(1≤i≤N),存在M个网络设备,记为nj(1≤j≤M)。
3.1Hadoop集群能耗
由2.1的讨论,Hadoop集群的能耗分为节点能耗和网络设备能耗两部分。
在Hadoop集群中 ,节点ci在t时刻的功率为pci(t),则
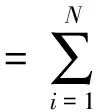
(7)
网络设备nj在t时刻的功率为pnj(t),则
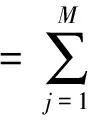
(8)
测量Ec(T)的方法有很多种。所有计算机都有额定功率,但实际功率是动态变化的,很难找到pci(t)和pnj(t)的数学表达式,并按照式(7)和(8)计算能耗Ec(T)和En(T)。因此我们采用电量计测量时间内Hadoop集群所有设备的能耗总和∑E(T),作为(2)式的E(T)。
3.2Hadoop集群任务量
下面介绍任务量Wc(T)、Wd(T)和Wn(T)的数量级统一和测量方法。Wd(T)和Wn(T)的数量级一致,可以令A⊕2B=A+B。当采用式(5)将CPU的频率单位GHz转换成存储大小单位MB时,转换算法使Wc(T)远大于Wd(T)+Wn(T)。 若⊕1为简单的相加,则会导致Wc(T)在W(T)的计算中起决定作用,Wd(T)和Wn(T)的影响被缩小。因此,式(3)中的聚集运算不能采用简单加法。为了使A与B保持在同一数量级,定义A⊕1B=ΦA+B,其中Φ为调整系数。式(4)可以改写为:
W(T)=ΦWc(T)+[Wd(T)+Wn(T)]
(9)
为确保Wc(T)与Wd(T)+Wn(T)在W(T)中所占的比重一致,引入Φ为计算机系统的调整系数,Φ=TIO/TCPU。其中,TIO表示I/O最大吞吐量,包括磁盘和网络2部分;TCPU表示CPU最大吞吐量。
表1定义了t时刻第i个节点(1≤i≤N)的若干特征属性来计算Hadoop集群效能。
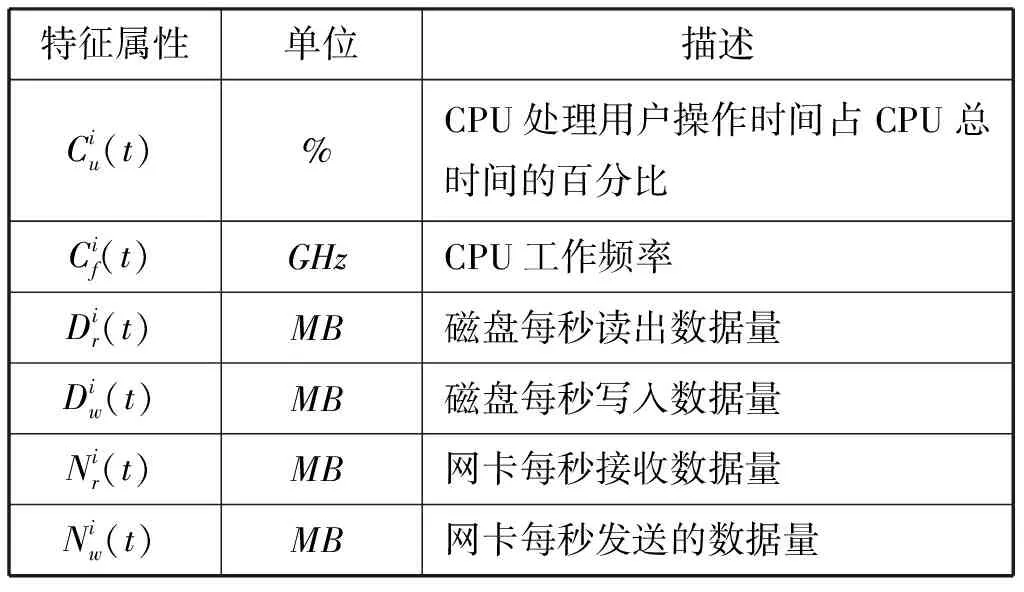
表1 效能计算特征属性
基于上述特征值,定义Wc(T)、Wd(T)和Wn(T)的计算方法如下:
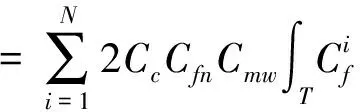
(10)
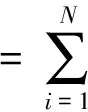
(11)
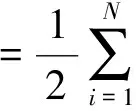
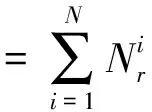
(12)
3.3Hadoop集群效能度量公式
综合(4)~(12)式,我们定义一个N个计算节点M个网络交换设备的Hadoop集群的效能:
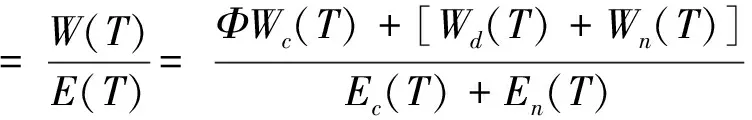
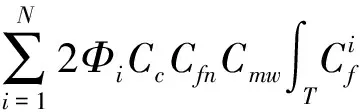
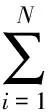
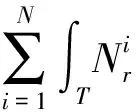
4 Hadoop集群效能测试与评价
为验证Hadoop集群度量模型,总结Hadoop集群效能规律,在相同规模的机架式服务器和PC机组成的Hadoop集群进行效能测试。
4.1 测试环境
机架式服务器采用HPDL380服务器,搭载IntelXeonE5645CPU,2.4GHz6核处理器。PC机采用联想R4900d主机,搭载Inteli3 3240处理器,3.4GHz双核处理器。两个集群均为8节点,通过H3C交换机互联,集群部署Ganglia监控系统,所有服务器和网络设备接入同一电源,使用电量计测量总能耗。具体测试环境的拓扑图如图1所示。
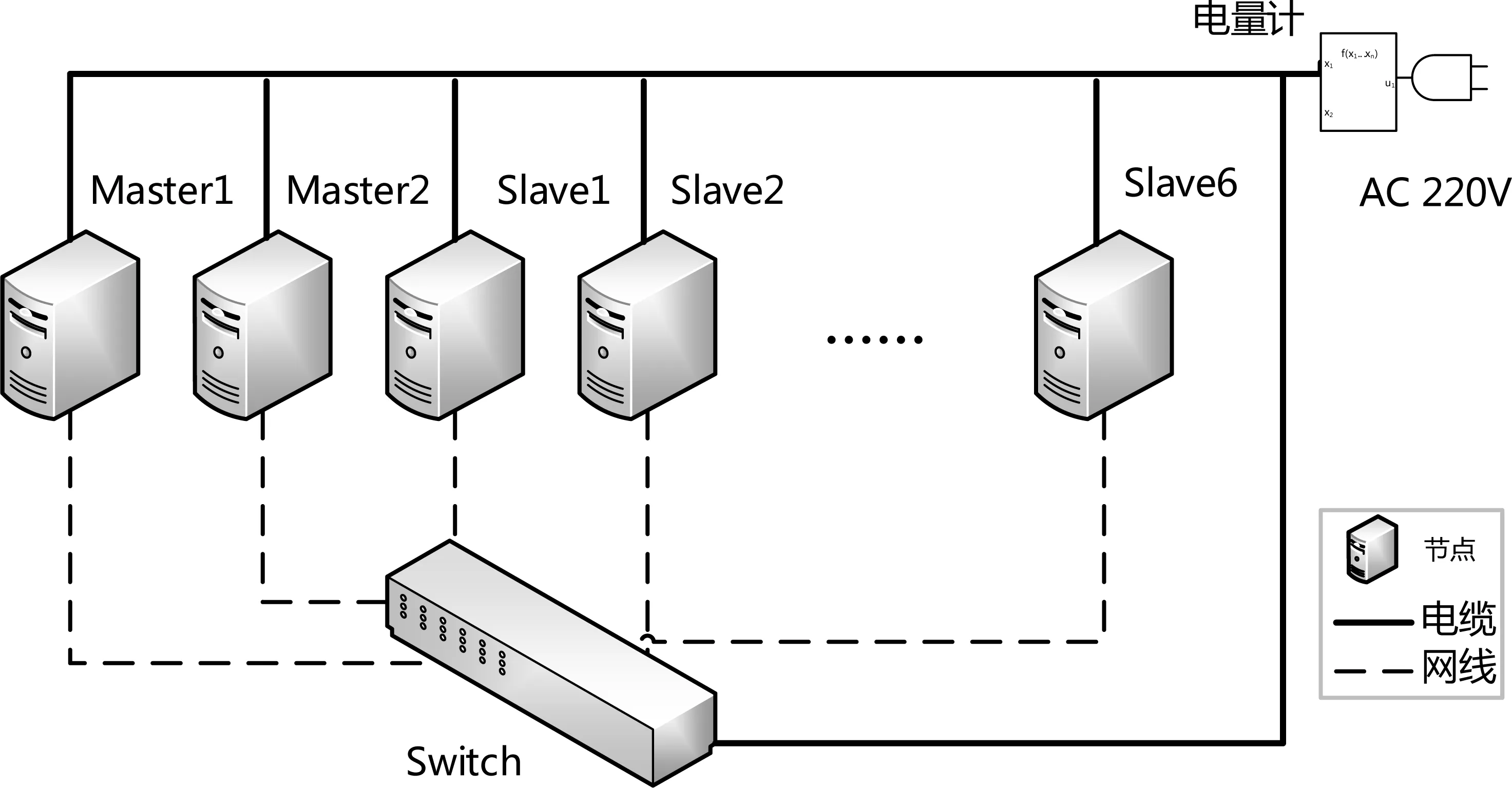
图1 Hadoop集群效能测试环境拓扑
4.2Hadoop集群效能指标测试与计算
本文采用CPU密集型和I/O密集型任务作为测试用例。CPU密集型主要体现在任务特点以大量计算作业为主,I/O密集型体现在任务需要大量的数据读写操作,两者是Hadoop集群应用领域中最常见的计算类型[6]。本文利用Wordcount和Sort用例分别代表两种类型的操作进行测试,根据上节给出的效能度量公式,记录集群的各项性能参数及能耗。测试样例全部采用MapReduce提供的Benchmark基准测试集,任务负载分别取100MB、1GB、10GB、100GB、1TB。利用Ganglia集群监控软件对CPU频率、使用率、磁盘和网络的吞吐率进行测量。
为了对Hadoop集群的效能进行度量,首先需要确定每个集群的对应的系数Φ。
由于集群是同构的,每个节点的Φ和特征属性相同。实验环境中所用的网络带宽为1000Mb/s,理论最大峰值传输速率为125MB/s。硬盘接口类型为SerialATA3.0,数据传输率理论可以达到600MB/s。因此,TIO=725MB/s。由式(4)计算可得,TServer-CPU=2.4×100%×6×2×64×27MB/s=235929.6MB/s(Cf=2.40GHz,Cu=100%,Cc=6,Cfn=2,Cmw=64bit)
TPC-CPU=1.8×100%×2×1×2×64×27MB/s=58982.4MB/s(Cf=1.80GHz,Cu=100%,Cc=2,Cfn=1,Cmw=64bit)
因此,ΦServer=1.55×10-3,ΦPC=1.22×10-2。
将测试指标带入Hadoop集群度量公式,得到机架服务器集群和PC集群的CPU密集型和I/O密集型任务效能如表2所示。

表2 服务器、PC Hadoop集群效能测试结果

续表
4.3 Hadoop集群效能测试结果评价
在对机架服务器和PC组成的Hadoop集群效能测试基础上,我们综合对比分析两种Hadoop集群在运行相同任务时的效能。同时考虑到任务执行时间和能耗是用户直接关心的两个度量,因此我们也引入相同条件下的执行时间和能耗,将两种架构Hadoop的效能、执行时间、能耗分别绘制在同一坐标系中,如图2、图3、图4所示。

图2 效能对比

图3 执行时间对比
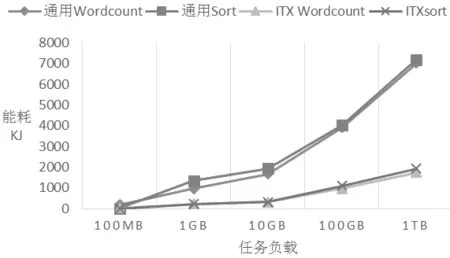
图4 能耗对比
如图3所示,机架服务器组成的Hadoop集群在TB级负载内效能指标平稳,并在数据量达到TB级以后效能呈上升趋势。PC组成的Hadoop集群在10GB左右负载时效能达到极值,负载继续增大时,效能呈下降趋势。如图4反观两种架构的能耗与执行时间关系,两种架构的能耗都和其任务执行时间呈正相关。PC集群的任务执行时间总大于同样负载的服务器集群,在负载小于10GB时,二者差距200s内,即不超过4分钟,但是两者时间差距的程度在负载大于10GB后,呈不断增大的趋势,且差距越来越明显,可达到1000s以上,即15分钟以上。显然PC组成的Hadoop集群执行大于10GB负载的任务执行时间相比通用架构Hadoop集群是用户不能忍受的。
综上,我们可以得出,机架服务器组成的Hadoop集群适合处理TB级的大规模数据。而PC组成的Hadoop集群更适合在响应时间要求不十分苛刻的应用环境中,处理10GB级及以下的中小规模数据。测试结论也体现出Hadoop采用廉价机器搭建服务器集群的思想。
5 结束语
随着大数据技术不断发展和大数据应用的不断膨胀,Hadoop集群能耗问题成了各大公司和研究机构重点关注的问题。因此,在当前和未来很长一段时间内,如何有效地利用计算资源,使有限的资源发挥出最大的效能,提高Hadoop集群的效能以降低运行成本成为大数据应用中一个迫切需要解决的问题[7]。
但是现有的Hadoop集群设计选型都缺乏对系统构建最根本的因素——集群效能进行考虑,并与集群处理的数据量建立关联。为此,本文对Hadoop集群效能进行建模研究,提出Hadoop集群效能度量模型,并对不同节点性能的集群效能进行对比测试,总结出其适合处理的数据量级,对生产环境中的Hadoop集群选型具有一定指导意义。
[1]程学旗,靳小龙,王元卓.大数据系统和分析技术综述[J].软件学报,2014(9):1889-1908.
[2]H W Meuer.The Mannheim Supercomputer Statisties 1986-1992[R].TOP500 Report 1993,University of Mannheim,1994,1-15.
[3]KUMAR K,LU Y H.Cloud computing for mobile users:can offloading computation save energy[J].IEEE Computer,2010,43(4):51-56.
[4]ABDELSALAM H S,MALY K,MUKKAMALA R.Analysis of energy efficien in clouds[J].Future Computing,Service Computation,Cognitive,Adaptive, Content,Patterns Computation World,Norfolk:IEEE,2009,416-421.
[5]宋杰,李甜甜,闫振兴.一种云计算环境下的能效模型和度量方法[J].软件学报,2012,23(2):200-214.
[6]D Jiang,B C Ooi,L Shi.The Performance of Mapreduce:An in-Depth Study[J].VLDB Endow,2010,1(3):472-483.
[7]The Apache Software Foundation.Welcome to Hadoop[OL].2013:http://hadoop.apache.org/.
(责任编辑:宋金宝,昝小娜)
Hadoop Cluster Productivity Modeling and Evaluation
FENG Dong-yu,ZHU Li-gu,ZHANG Lei
(Computer School,Communication University of China,Beijing 100024,China)
With the deep research on big data technology,the issue of Hadoop cluster productivity causes more and more concern in the industry.It is one of the most important issues of the big data application about how to effectively utilize the computing resource,making full use of the limited resource with the most efficiency.In this paper,the mathematical models have been established for Hadoop cluster productivity,defining the productivity of Hadoop cluster as the ratio of the task size and energy consumption per unit time,and proposed the measurement parameter and methods of Hadoop cluster productivity.For Hadoop clusters with different hardware configuration,experiments.The productivity of CPU intensive and I/O intensive computing was measured and evaluated based on the measurement model.It concluded from the measurement result that Hadoop cluster with IBM rack servers is suitable for processing terabytes of data,while Hadoop cluster of PCs is more suitable for processing 10 gibabytes of data and under in the condition that response time requirements is not harsh.This research in this paper is instructive for hardware selection of Hadoop cluster in production environment.
Hadoop;cluster;productivity;MapReduce
2016-09-11
国家自然科学基金项目(61730063)
冯东煜(1989-),男(汉族),辽宁锦州人,中国传媒大学计算机学院博士研究生,E-mail:fengdy1225@163.com.
TP
A
1673-4793(2017)01-0022-05
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
舰船电子工程(2023年8期)2023-12-20 15:33:55
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
软件(2020年3期)2020-04-20 01:45:06
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
大经贸(2017年6期)2017-07-29 09:42:12
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
