
基于改进依存句法的微博情感分析研究*
2017-03-31 05:10:38李雪红闫泓涛
计算机与数字工程 2017年3期
李雪红 郭 晖 闫泓涛
(1.海军大连舰艇学院训练部 大连 116000)(2.海军工程大学电子工程学院 武汉 430033)
基于改进依存句法的微博情感分析研究*
李雪红1郭 晖2闫泓涛2
(1.海军大连舰艇学院训练部 大连 116000)(2.海军工程大学电子工程学院 武汉 430033)
分析微博情感倾向分析重要意义,针对微博文本特点,提出一种改进依存句法分析算法进行情感倾向分析。改进算法通过引入表情、标点等符号词的感情极性分析,采用基于中心情感词的语法距离分析词语情感极性,通过实例研究发现改进算法在微博情感倾向分析中效果明显。
情感倾向分析; 依存句法分析; 中心情感词; 微博
Class Number TP309.7
1 引言
微博(Micro Blog)是一种通过Web、WAP及其他客户端,基于用户关系的信息分享、信息传播和信息获取的一种集成化、开放化社交服务平台[1]。用户通过简短的文字、图片、链接等发布发表自己的心情、状态以及各类话题,由于微博便利快捷的特点,微博用户及其发布量急速增长。微博国外最早代表是2006年开设的Twitter网站,全球已拥有5.17亿注册用户,其中1.4亿活跃用户。中国在2009年开设了新浪微博,目前用户达到5.03亿,活跃用户4600万。2010年中国互联网舆情报告指出,微博成为网络舆论主要载体[2]。
大量微博用户发布的文本信息包含了用户的情绪情感。研究微博中情感倾向分析在商业产品评论、垃圾邮件过滤等领域有着广泛应用,特别是有助于舆情监控、舆情发现、舆论引导等工作实现[3],从而有效进行社会情绪疏导,及时避免盲目群体事件发生和恶化,具有很强的社会意义。
情感倾向分析是按照文本表达的情感倾向性对文本进行分析[4]。本文在研究微博文本特点基础上,分析当前文本情感倾向分析基本方法,提出了一种改进的依存句法算法对微博进行情感分析,通过语句的依存句法结构确定中心情感词,再根据依存关系和语法结构距离研究微博中包括句子结构词、表情和标点符号在内情感特征词的情感倾向值,最后确定整个文本句子的情感倾向。
2 研究背景
2.1 微博文本特点
微博作为一种新兴的互联网信息交互平台,用户以140字左右的文字更新消息,并实现即时分享,同时与手机短信、社交网站和博客等多种互联网交互平台和方式互通联系。这里主要研究以文本为主体信息的微博,微博文本信息主要包括以下几个特点:
1) 文本长度短,结构不规范。微博文本长度一般限制在140字左右,且句子结构随意性大。
2) 表述方式内容不规范。微博大量采用网络语言,表情符号等,且对于标点符号、成语等没有规范使用。
3) 话题交互性强。微博很多都是针对某话题或主题的评论,要结合上下文进行系统分析。
2.2 文本情感分析基本方法
文本情感分析主要任务就是根据文本来判断作者的情感倾向,主要利用底层情感信息抽取的结果将情感文本单元分为若干类别,如分为褒贬,喜悲等对立两类或更为细致的感情类别(如喜怒哀乐等),并进行分析归纳。文献[5]最早给出了情感分析的概念,文献[6]针对中文的文本情感分析的任务、内容和主要技术进行描述。
文本情感分析可分为三个研究层次,即情感信息的抽取、情感信息的分类以及情感信息的检索与归纳。情感信息抽取是抽取情感文本中有价值的情感信息,是情感分析的基础任务,为后续文本情感分析提供数据基础;情感信息分类主要包括主客观信息的二元分类和主观信息的情感分类,同时还包括观点分类;情感信息的检索和归纳是用户交互任务,前者是为用户检索出主题相关且包含情感信息的文档,后者是针对大量主题相关的情感文档,自动分析和归纳整理出情感分析结果。
文本情感分析按照处理文本的粒度不同可以分为词语级,语句级和篇章级;按照不同分析目的,可以分为主客观分析和主观分析,前者主要研究作者对客观事物的褒贬评价,后者则主要研究作者自身的喜怒感受;按照分析内容的不同,可分为对新闻事件的情感分析和对商品评价的情感分析;按照技术处理手段可分为基于词典的情感分析和基于机器学习的情感分析,前者主要是利用基础情感词典对文本中词语进行情感分析,后者则是利用SVM方法、神经网络、朴素贝叶斯等分类器进行文本情感分析;按照有无人工参与可分为无监督分类方法和有监督分类方法,主要区别在于是否需要人工词语情感标注。
结合微博文本的长度较短,结构不规范,中文语法结构复杂等特点,针对现行文本情感分析方法在微博文本情感分析上的不足和欠缺,针对性提出了改进依存句法分析算法,采用语句级基于词典的改进依存句法分析(Improved Chinese Dependency Parsing,ICDP),算法主要改进在于围绕中心情感词分析进行依存句法分析情感倾向。
3 改进的依存句法分析算法
本文提出一种基于改进中文依存句法算法来进行微博文本情感分析,基于情感词典给出情感值,分析句法结构确定中心情感词,从句法结构和与中心词距离研究句中各类词、表情及标点符号的情感值,最后对微博文本进行情感倾向归一化求平均得到文本情感倾向。
3.1 依存句法分析算法
句法分析是根据给定的语法体系,自动推导出句子的句法结构,分析句子包含的句法单元及其之间关系,并转化为结构化的句法分析树[7]。中文文本的句法分析是基于汉语这一表意型语系的,其书写形式和句子结构相对英语更加复杂,要先进行句子分词和词性判定。文献[8~9]分别对中文自动分词技术和无监督词性标注技术进行了研究。
依存句法分析是一种基于规则的句法分析方法。基于规则句法分析是由人工组织语法规则,建立语法知识库,通过条件约束和检查来实现句法结构建立,完成分析树。分为三种基本类型:自顶向下,自底向上和两者结合的方法。文献[10]指出两者结合的算法在理论上最接近人实现句法分析的过程,最具有心理语言学的价值。
依存句法分析使用的语法体系包括短语结构语法和依存语法,其中依存语法是用词与词之间的依存关系来描述语言结构,也叫从属关系语法,该方法是法国语言学家Tesniere于1959年提出,认为结构语法可概括为关联、组合和转位三大核心,从而建立起支配词和从属词联结而成的从属关系。
采用哈尔滨工业大学研究的LTP平台依存句法分析器确立的24种依存关系[11],如表1所示。
在依存语法理论中,依存是指词与词之间的支配与被支配关系,这种关系是不对等,有方向的,处于支配地位的为支配词,被支配地位的为从属词,依存关系用有向弧表示为依存弧,方向由支配词指向从属词,依存弧上标记依存关系符号。例如对语句“武汉是座很美丽的城市!”的结构分类如图1所示。
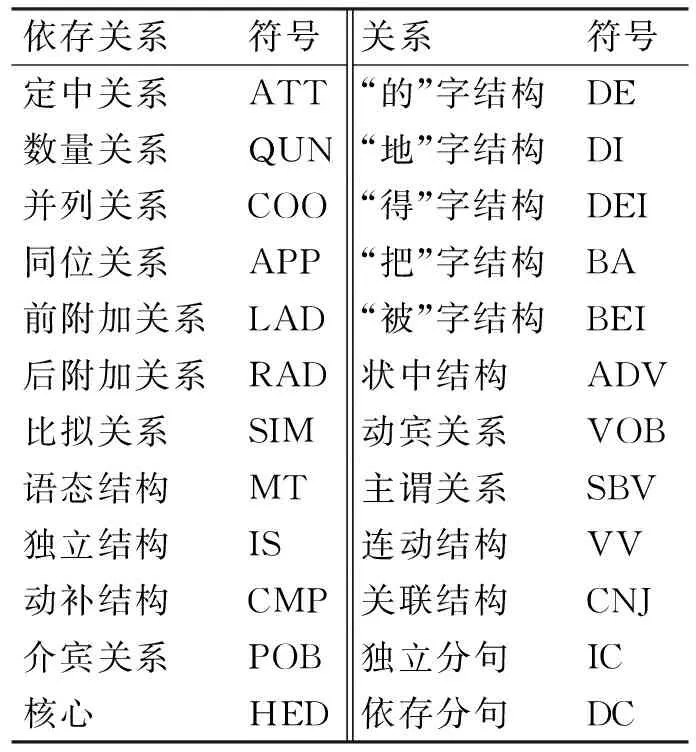
表1 依存关系符号表

图1 依存句法分析实例图
目前国内针对中文文本的依存句法分析算法一般采用两类方法,一是中心情感词分析,通过情感强度来确定中心情感词,分析该词情感极性得到句子情感倾向;二是句法分析,通过对句子中带情感的形容词、名词等进行情感分析,根据对其进行修饰词的文本距离等进行情感强化或弱化修饰。这些方法主要存在以下问题:一是中心情感词选择按照情感强度进行,没有对文中所有带情感词及句子的句法结构进行分析;二是简单的将修饰词对中心词的情感修饰强度用文本长度衡量,忽略了文本结构长度;三是对文本中新兴的带有网络特点的标点、符号等的情感研究重视不够。
3.2 改进的依存句法分析
由于微博文本的语言结构不规范和标点、表情等符号语言广泛使用,一般分析方法不能满足高标准情感倾向分析要求。针对微博文本特性和当前分析方法的不足,本文研究一种改进的依存句法分析,该算法步骤和采用的主要技术为
1) 句子分词和词性判定。将分析对象划分为若干词语并对词语性质如名词、动词、形容词等进行判定。
2) 词语极性计算。主要基于情感词典,如HowNet词典对词语进行情感极性判定,确定句中支配词的正负、褒贬信息。
3) 分析语句句法结构。采用依存句法分析得到语句的结构分析树。
4) 计算修饰词极性。对句中形容词、副词等从属词通过结构分析树计算其情感极性。
5) 计算语句情感倾向。对文本中各语句进行分析,按照句间关系词通过归一化平均处理等方法确定文本情感倾向。
改进算法针对现有依存句法分析算法在三个方面进行改进:
1) 增加了对标点、表情等符号词语的情感极性分析。
2) 由常规的对各词的情感极性计算改进为确定中心情感词,结合句法分析结构设计的所有情感词进行计算。
3) 增加结合情感修饰词与中心情感词的语法结构距离分析其情感极性。
3.2.1 符号词的极性分析
本文中提及的符号词主要包括表情符号和标点符号,表情符号大部分是由标点符号与字母组合而成的,如“:D”表示笑脸等。对于表情符号,通过分析不同微博应用平台中表情符号的含义,通过机器学习等方法得到表情符号感情极性值Ee,并将这些值记录在新建的情感词典中;对于标点符号,通过分析不同语态,如感叹句,疑问句,反问句等对感叹号,问号等分析其对语句情感的影响作用λi。
假设文本初始情感极性值或倾向值为Ei,表情符号感情极性值Ee,标点符号对语句情感的影响作用λi,那么考虑符号词后的句子情感倾向值Ef为
Ef=(Ei+Ee)·λi
3.2.2 分析结构确定中心情感词
在文本句子分析中通过分析句子结构,特别是对长句的句间结构分析,得到句子的中心情感词,即表达句子情感的核心词。核心词根据依存句法中依存弧确定,当一个词不是句子中任何词的从属词时,即该词的依存弧入度为零时,即认为该词为句子的核心词HED。
根据句子核心词HED确定中心情感词的一般步骤为
1) 根据句子核心词HED,寻找HED下一个依存关系词。
2) 判断依存关系词是否为形容词或名词,否则继续步骤1)。
3) 根据情感词典判定是否为情感词,否则继续步骤1),直到寻找到情感词Wm。
4) 当依存关系为独立分句IC或依存分句DC时,将依存关系IC、DC的从属词作为分句的核心词继续步骤1),确定分句的情感词Wh。
5) 根据分句间关系结构词确定主从句关系,根据主从句首连词确定主从句的从属关系,进而确定从句相对主句的情感相对倾向度比重λh。
那么考虑主从句关系,整个句子的情感极性值Eh为
Eh=E(W1)+E(W2)·λ2h+…+E(Wi)·λih
E(W1)、E(Wi)分别为以主句和第i个从句以W1和Wi为中心情感词计算的情感倾向值,λh为主从句情感倾向比重,中文语系中主从句的8种基本关系[12]的情感相对比重,按照平铺陈述句的情感比重为1,依据层次分析法按主从关系的相对情感比较,从而得到8种基本关系情感比重如表2所示。
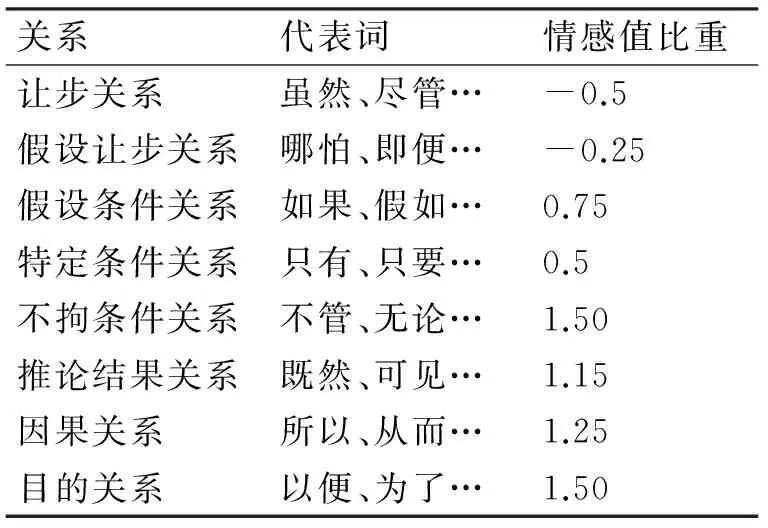
表2 主从句关系及其情感比重
3.2.3 词语语法距离的情感分析
词语的语法距离主要研究在依存句法分析背景下,这种距离是区别于常规的词语间字数长度距离的,主要考虑树中两个词先后检索到达的顺序差绝对值。这里重点研究副词针对中心情感词的语法距离,对于不同类型的依存结构关系赋予不同的语法距离,例如对于“的”字结构DE关系,由于“的”字在ADV结构中可忽略,其语法距离为0,独立分句IC关系其分句中词语情感主要基于分句中心情感词分析,其距离为无穷大。通过对不同依存关系分析,关系对应的语法距离如表3所示。

表3 依存关系的语法距离
根据依存关系分析树结构,句中两个词有且仅有一条可达路径,那么计算句子中某个词与中心情感词的语法距离方法为
其中,n为可达路径中依存弧(关系)的个数,di为第i个依存关系对应的语法距离。那么假设原句情感极性值为E0,考虑影响情感权重λi的程度副词的语法距离,否定副词在ADV关系对象前取负,语法距离越远对中心情感词的影响越小,可以分析得到句子情感极性值Ed为
按照上述方法对句子S1“他很不友好”和句子S2“他不很友好”两个句子进行分析对比如表4所示。
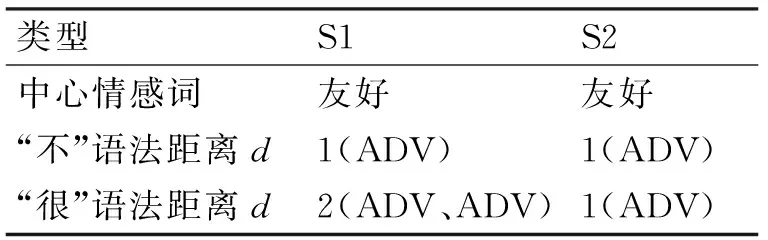
表4 分析对比表
假设否定词“不”为情感极性值取负,程度副词“很”为情感极性值乘1.25,中心情感词“友好”的情感极性值为1,那么得到两个句子的情感极性值为

可以看出:分析结果符合实际句意表达,S1较S2的负向情感更加重,可以发现考虑语法距离的句子情感极性值计算方法是科学有效的。
4 实例及分析
4.1 实验数据及指标
为了测试本文改进算法的情感分析效果及其改进程度,本文采用新浪微博中随机抽取的1000篇微博,大部分通过网络爬虫获取,部分通过手动获取。情感词典采用Hownet,并在结构分析中提取标点符号和结构连词,采用准确率(Precision)、召回率(Recall)和微F测度(F-Score)作为评价指标,准确率用于评价信息检索、分类算法等的效果,召回率反应算法的查全率,微F测度反应了算法的综合效果。
对于三个不同指标,还考虑对于正面和负面两种类型情感极性值文本及其平均值。如果微博文本的情感倾向性值大于0,则该短文本为正文本;如果短文本的情感倾向性值小于0,则该短文本为负文本;如果短文本的情感倾向性值等于0,则该短文本为中性文本。设数据集中的正文本个数为NP,负文本个数为NN,分类中的正文本正确个数为nP,负文本正确个数为nN则准确率计算如下:负文本准确率:PN=nN/NN,正文本准确率:PP=nP/NP,平均准确率:PA=nP+nN/(NP+NN)。同样可得到召回率的正负文本值和平均值。那么微F测度计算公式为:F=2*P*R/(P+R)。
4.2 实验结果
采用本文改进依存句法分析算法A2对1000篇微博进行情感分析,对比文献[13]的一般依存句法分析算法A1,针对不同篇幅微博采用两种方法进行情感分析对比,篇长70字以下的结果如表5所示。

表5 短篇微博情感分析试验对比
对于篇长70字到140字的中长篇幅微博文本进行情感分析结果如表6所示。
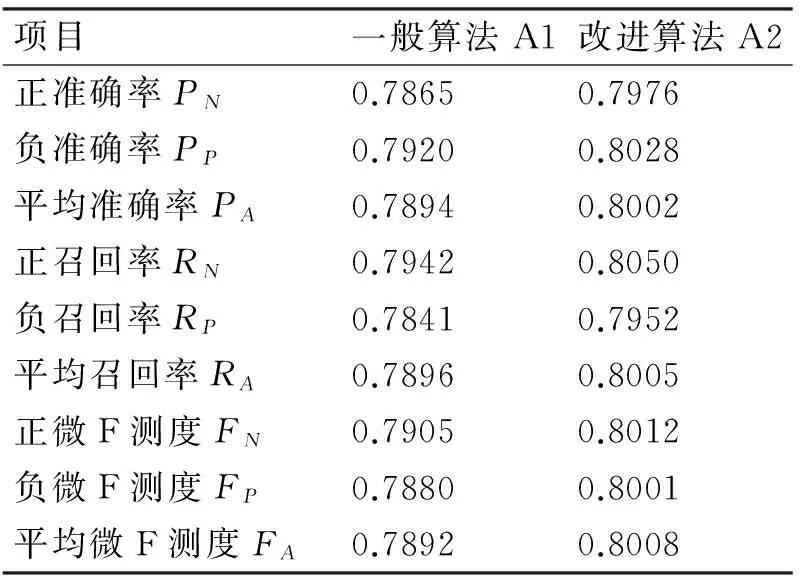
表6 长篇微博情感分析试验对比
通过不同篇幅文本微博的两种情感分析方法对比,可以得到以下结论: 1) 改进依存句法分析算法在准确率、召回率和微F测度上较一般算法均有所改进; 2) 对于字数少于70字的短篇微博,改进算法A2具有更好情感分析效果。
5 结语
微博已经逐渐成为社会舆情重要关注对象,研究微博情感倾向具有重要意义,但由于微博文本的语法结构不规范和表达方式多样化特点,全面有效的微博文本情感分析难度较大。本文为了分析微博情感,针对当前依存句法分析缺陷,对依存句法分析算法进行改进,引入表情标点等符号词的感情极性分析,采用基于中心情感词的语法距离分析词语情感极性方法,通过实例发现较一般依存句法分析效果提高,特别对短篇微博改进效果更加明显。
[1] 平亮,宗利永.基于社会网络中心性分析的微博信息传播研究[J].图书情报知识,2010(6):92-97. PING Liang, ZONG Liyong. Based on the analysis of the social network centricity weibo information dissemination study[J]. Journal of book intelligence knowledge,2010(6):92-97.
[2] 中国互联网信息中心.第二十五次中国互联网发展状况统计报告[R].中国互联网统计报告,2010(1):1-10. China Internet network information center. 25 times China Internet development statistics report[R]. China’s Internet statistics report,2010(1):1-10.
[3] 贾焰,刘江宁,周斌.微博的舆情特点及其谣言治理[J].行政管理改革,2012(6):37-41. JIA Yan, LIU Jiangning, ZHOU Bin. Microblogging public opinion characteristics and rumors governance[J]. Journal of administrative reform,2012(6):37-41.
[4] 赵妍妍,秦兵,刘挺.文本情感分析[J].软件学报,2010,21(8):1834-1848. ZHAO Yanyan, QIN Bing, LIU Ting. Text sentiment analysis[J]. Journal of software,2010,21(8):1834-1848.
[5] Bo Pang, Lillian lee. Thumbs up: Sentiment Classification Using Machine Learning Techniques. EMNLP’02, July 6-7, Philadelphia, USA,2002:22-240.
[6] 魏韡,向阳,陈千.中文文本情感分析综述[J].计算机应用,2011,31(12):3321-3323. WEI Wei, XIANG Yang, CHEN Qian. Chinese text sentiment analysis review[J]. Journal of computer applications,2011,31(12):3321-3323.
[7] 宗成庆.统计自然语言处理[M].北京:清华大学出版社,2008:125-126. ZONG Chengqing. Statistical natural language processing[M]. Beijing: Tsinghua university press,2008:125-126.
[8] 郑晓刚,韩立新,白书奎,等.一种组合型中文分词方法[J].计算机应用与软件,2012(7):26-29. ZHENG Xiaogang, HAN Lixin, BAI Shukui, et al. A combination of Chinese word segmentation method[J]. Journal of computer applications and software,2012(7):26-29.
[9] 孙静,李军辉,周国栋.基于条件随机场的无监督中文词性标注[J].计算机应用与软件,2011(4):21-24. SUN Jing, LI Junhui, ZHOU Guodong. Unsupervised Chinese part-of-speech tagging based on conditional random field[J]. Journal of computer applications and software,2011(4):21-24.
[10] 王文然.基于依存句法分析的互联网细粒度观点挖掘研究[D].大连:东北财经大学,2011:43-44. WANG Wenran. Based on dependent fine-grained syntactic analysis of Internet opinion mining research[D]. Dalian: Northeast university of finance and economics,2011:43-44.
[11] 马金山.基于统计方法的汉语依存句法分析研究[D].哈尔滨:哈尔滨工业大学,2007:52-55. MA Jinshan. Chinese dependency based on statistical method of syntax analysis[D]. Harbin: Harbin institute of technology library,2007:52-55.
[12] 宋京生.汉英从属连词比较[J].四川外语学院学报,2001(5):63-66. SONG Jingsheng. Chinese-english subordinate conjunction comparison[J]. Journal of sichuan foreign language institute,2001(5):63-66.
[13] 冯时,付永陈,阳锋,等.基于依存句法的博文情感倾向分析研究[J].计算机研究与发展,2012(11):2395-2406. FENG Shi, FU Yongchen, YANG Feng, et al. Based on the analysis of interdependence syntactic post emotional tendency study[J]. Journal of computer research and development,2012(11):2395-2406.
Micro-blog Sentiment Analysis Based on Improved Dependency Parsing
LI Xuehong1GUO Hui2YAN Hongtao2
(1. Military Training Division. Dalian Naval Academy, Dalian 116000) (2. College of Electronics Engineering, Naval University of Engineering, Wuhan 430033)
Micro-blog sentiment orientation analysis’s important signification is analyzed firstly. Then a new improved dependency parsing is proposed to analyze micro-blog sentiment orientation on the base of analyzing the peculiarity of micro-blog texts. This improved algorithm includes the sentiment orientation analysis of emoticons and punctuation, and analyze sentiment orientation based on the distance to the kernel emotional words in syntax structure. Experimentations show the algorithm has good applicability and robustness.
sentiment orientation analysis, dependency parsing, kernel emotional words, Micro-blog
2016年9月3日,
2016年10月28日
李雪红,女,硕士,副教授,研究方向:计算机应用技术。郭晖,女,硕士,讲师,研究方向:软件工程,计算机应用技术。闫泓涛,女,研究方向:计算机技术,通信技术。
TP309.7
10.3969/j.issn.1672-9722.2017.03.021
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19 18:09:52
时代英语·高一(2019年5期)2019-09-03 02:09:34
时代英语·高一(2019年1期)2019-03-13 10:29:48
时代英语·高三(2019年1期)2019-03-13 10:29:26
小学生作文·小学低年级适用(2018年12期)2018-04-11 03:10:42
时代英语·高三(2018年1期)2018-02-23 19:33:53
新高考(英语进阶)(2017年10期)2017-12-23 09:15:06
电测与仪表(2016年11期)2016-04-11 12:20:42
校园英语·下旬(2016年2期)2016-03-18 10:23:20
电源技术(2015年5期)2015-08-22 11:18:28
