
基于MapReduce编程模型的改进KNN分类算法研究
2017-03-30 08:11:34邱宁佳郭畅杨华民王鹏温暖
长春理工大学学报(自然科学版) 2017年1期
邱宁佳,郭畅,杨华民,王鹏,温暖
(长春理工大学计算机科学技术学院,长春 130022)
基于MapReduce编程模型的改进KNN分类算法研究
邱宁佳,郭畅,杨华民,王鹏,温暖
(长春理工大学计算机科学技术学院,长春 130022)
采用一种属性约简算法,将待分类的数据样本进行两次约简处理--初次决策表属性约简和基于核属性值的二次约简。通过属性约简方法来删除数据集中的冗余数据,进而提高KNN算法的分类精度。在此基础上应用MapReduce并行编程模型,在Hadoop集群环境上实现并行化分类计算实验。实验结果表明,改进后的算法在集群环境下执行的效率得到很大提升,能够高效处理实验数据。实验执行的加速比也有明显提高。
KNN;属性约简;MapReduce编程模型;Hadoop
随着信息技术以及“互联网+”的快速发展,数据在大容量、多样性和高增速方面爆炸式增长,给数据的处理和分析带来了巨大挑战[1]。数据的分类处理就变得尤为重要,在经典分类算法中KNN分类算法操作比较简单,在诸多领域都有很广泛的应用。不过KNN作为一种惰性算法在处理大容量数据集时,由于数据的属性较多,会影响KNN算法的分类效率和分类精度,因此对KNN分类算法进行改进是很有必要的。
国内外的学者们对KNN算法已经有了一些研究,闫永刚等人提出了将KNN分类算法通过MapReduce编程模型实现并行化[2];Papadimitriou等人提出了一重新的聚类分析算法DisCo[3],且这种新算法应用在分布式平台上进行并行化实验研究;鲍新中等人应用了粗糙集权重确定方法来解决粗糙集信息上的权重确定问题[4];汪凌等人应用了一种基于相对可辨识矩阵的决策表属性约简算法[5]来解决KNN算法中的数据冗余问题;张著英等人在研究KNN分类算法时将粗糙集理论应用到KNN算法中从而实现属性约简[6];樊存佳等人提出了一种基于文本分类的新型改进KNN分类算法[7],同时采用聚类算法裁剪对KNN分类贡献小的训练样本,从而减少数据冗余;Zhu等人提出了一种基于哈希表的高效分类算法H-c2KNN[8],应用在高维数据下的KNN分类算法中;Wang等人提出了一种基于内核改进的属性约简KNN分类算法[9];吴强提出了一种基于概念格的属性约简方法[10],将粗糙集理论的可辨识矩阵方法应用于概念格的约简,从而提高效率简化;鲁伟明等人提出了一种基于近邻传播的改进聚类算法-DisAP[11],并将其应用在MapReduce编程框架中;王煜将KNN文本分类算法进行了基于决策树算法的改进并进行并行化研究[12];梁鲜等人提出了一种全局K-均值算法[13],解决了全局K-均值算法时间复杂度大的问题;王鹏等人提出了在MapReduce模型基础上的K-均值聚类算法的实现问题[14]。本文在上述研究的基础上,对实验数据进行基于决策表和核属性值的两次属性约简改造并结合MapReduce编程框架进行KNN分类算法的并行化实现。
1 相关知识
1.1 KNN分类算法的基本原理
K最近邻(K Nearest Neighbors,KNN)算法是一种基于实例的学习方法。其基本原理如下:通过将给定的检验样本与和它相似的训练样本进行比较来分析结果,此为学习。训练样本通常用属性来描述,一个训练样本包含多个属性,每个属性则代表n维空间的一个点。当输入新的训练样本时,KNN算法即开始进行遍历搜索,得到与新样本最近邻的k个训练样本,其示例如图1所示。
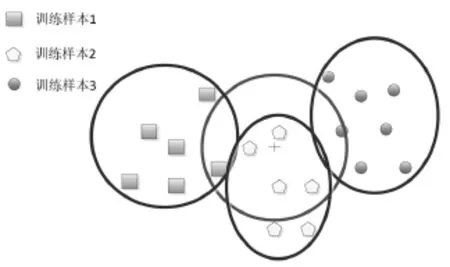
图1 KNN分类示例
可以看出,给定的训练样本共有三种:正方形、圆形和五边形。每给定一个新的检验样本,就需要计算与其最近的K个训练样本,计算的方法通常采用欧式距离计算,再由计算出的K个训练样本的分类情况来确定新样本的分类情况。由上图中心圆所选出的即为离待分类样本最近的六个训练样本,这六个样本中有四个为五边形,按照分类号进行“投票”,则可以将该训练样本分类为五边形。
1.2 MapReduce框架
MapReduce是一种面向大数据并行处理的计算模式,它是基于集群的高性能并行计算平台,也是并行计算与运行软件的框架,同时也是一个并行程序设计的模型。MapReduce框架程序主要由Map函数和Reduce函数组成,首先由Map函数负责对数据进行分布计算,即将输入的数据集切分为若干独立的数据块,各个Mapper节点在工作时不能够实时的交互,框架会将Map输出的数据块进行排序;然后将输入结果发送给Reduce函数,Reduce函数负责对中间结果进行处理,以得到最终结果并进行结果输出,图2为MapReduce程序执行示意图。
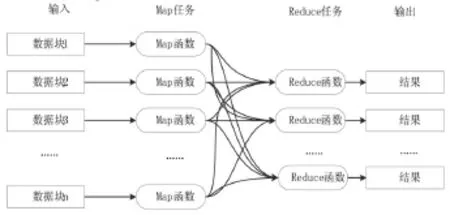
图2 MapReduce程序执行示意图
1.3 属性约简方法
属性约简即通过删除不相关属性或者降低属性维度从而减少数据冗余,提高数据处理的效率,节约数据计算成本。属性约简是计算最小属性子集的过程,在此过程中还要保证其数据的分布概率基本保持不变或有较少改动。常见的属性约简方法有逐步向前选择法、合并属性法、决策树归纳和主成分分析等方法。主成分分析是一种用于连续属性的数据降维方法,构造了原始数据的一个正交变换,新空间的基底去除了原始空间基底下数据的相关性,这样较少的新变量能够刻画出原始数据的绝大部分变异情况。在应用中,通常是选出比原始变量个数少,能解释大部分数据中的几个新变量,即主成分来代替原始变量进行建模。
其计算步骤如下:
设原始变量X1,X2,…,XP的n次观测数据矩阵为:
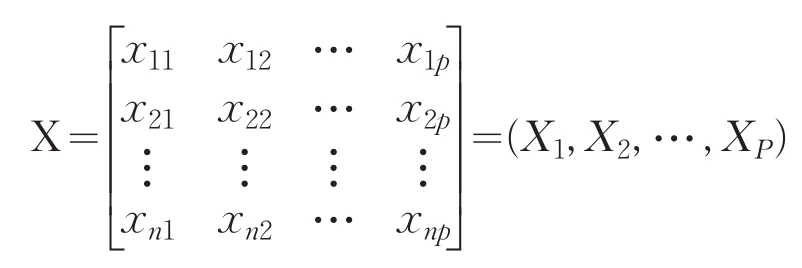
对观测的数据矩阵进行中心标准化,并将标准化后的数据矩阵仍然记为X。
求相关系数矩阵R,R=(rij)p×p,rij的定义为:

求R的特征方程det(R-λE)=0的特征根λ1≥λ2≥λp>0;
计算m个相应的单位特征向量:
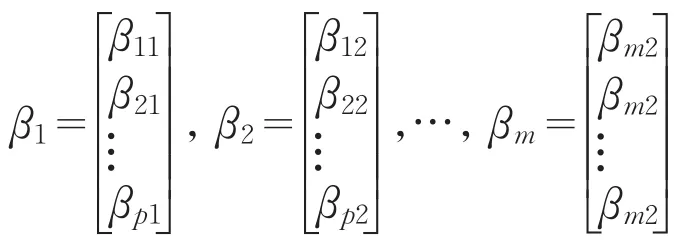
计算主成分:
Zi=β1iX1+β2iX2+…+βpiXp,i=1,2,…,m
再使用主成分分析降维的方法,可以得到特征方程的特征根,对应的特征向量以及各个成分各自的方差百分比(即贡献率),贡献率百分比越大,向量权重越大。通过此种方法可以在完成属性归约的同时保存与原始数据相配的数据信息。
2 改进KNN算法
2.1 基于属性约简的KNN分类算法
改进后的KNN分类算法即在进行KNN分类算法的基础上利用属性约简的相关知识,将算法进行先基于决策表再基于核属性值的两次属性约简,将冗余的数据进行约简,在不影响结果的情况下,提高分类的效率,下面给出改进后算法的形式化描述:
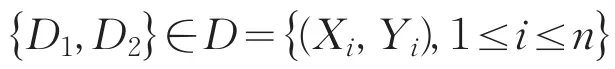
输出:样本数据的类别。
算法步骤:
(1)对输入的训练数据进行初次属性约简,并计算出核属性值;
(2)根据样本属性进行基于核属性的二次属性约简,通过信息熵理论,计算核属性的重要度w(p),若w(p)=0,则认为该属性为冗余属性,从核属性中移除该属性,得到二次约简属性集[4];
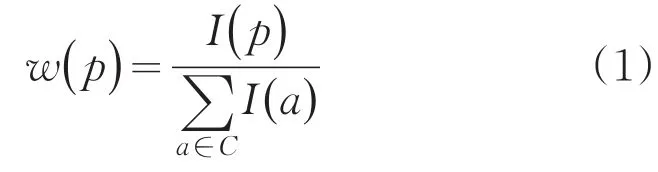
(3)利用分布式处理平台对样本数据进行分块处理,对每一块样本数据分别计算其与训练数据属性之间的距离d(X,Xi),此处的距离采用欧式距离进行计算;
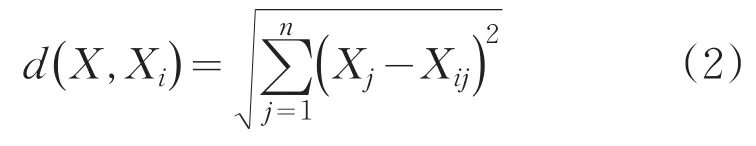
(4)对计算出的距离d(X,Xi)进行从小到大的排序,选取排在前K个训练数据;
(5)统计前K个训练数据的类别,将个数最多的类别预测为当前样本的类别,进行结果分析。
2.2 改进后的KNN算法的MapReduce并行化
将改进后的KNN算法进行MapReduce并行化,主要分为三个阶段来实现。
(1)下载文件系统中的训练数据集和测试数据集到本地存储节点。
(2)Map函数将测试样本数据分块,计算出测试数据到训练数据的欧式距离,进行排序。
(3)将排序结果传送给Reduce函数,Reduce函数将执行KNN分类算法进行规约操作并计算出分类结果。因为Map阶段的关键为对应待分类样本在文件中的偏移值,其在Map阶段完成时会被MapReduce框架自动排序,所以Reduce阶段输出的分类号就对应了待分类样本在原文件中的顺序。本文中的Map函数和Reduce函数的算法步骤如下所示:

表1 Map函数的算法步骤

表2 Reduce函数的算法步骤
经过上述改进后,得出了一个基于属性约简的改进KNN算法,并对其进行MapReduce编程模型的搭建。
3 实验分析
3.1 实验环境及数据
实验运行所需的云平台由实验室4台电脑组成,每台电脑装有3台虚拟机,共12个节点。Hadoop分布式云计算集群采用Centos6.0操作系统、hadoop-1.1.2版本的Hadoop。其中一个作为Master节点,其余作为Slave节点。本次实验采用7个数据节点来进行实验。
实验数据采用标准数据集CoverType DataS-et,该数据具有54个属性变量,58万个样本,7个类别。本文将数据分为测试数据(data1)和训练数据(data2)两部分,其中测试数据共20万个样本,大小约为500MB,训练数据共38万个样本,大小约为1000MB。
3.2 实验过程及分析
本实验的主要内容分为两部分:
(1)分析KNN算法在数据规模相同而在数据节点数目不同的情况下,数据执行时间的对比情况。首先对给定的训练样本进行初次属性约简和二次基于核属性值的约简,以达到删除冗余数据的效果,然后在Hadoop分布式平台上进行基于MapReduce的并行化实验,依次导入训练样本和测试样本,实验数据节点数目依次从1个添加到7个,通过增加节点数目来对实验执行时间进行比较,得出相应结论;
(2)研究数据在执行分类算法的过程中,不同数据节点数目所对应的加速比情况。此部分实验是由实验(1)的实验结果分析而得出的,不用数据节点数目条件下对应的实验结果加速比理论上应该是不同的,所以通过实验来做真实的数据分析,得出具体的变化曲线。
实验结果分别如图3、4所示:
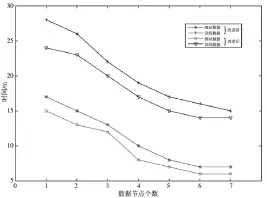
图3 数据集的时间对比图
图3可以看出,两组数据集分别为改进前和改进后的测试数据和训练数据,由实验可以验证每组数据在进行属性约简改进后都其运行的时间都比没有改进前有明显减少,训练数据约简后执行时间平均缩短了2.28min,测试数据的执行时间平均缩减了1.71min,且数据量大的训练数据时间减少的更为明显,通过对数据进行属性约简后其运行的效率明显提高,改进的KNN算法在分布式平台上能够高效运行,对于单个数据集而言随着节点数增加数据在平台上运行的时间相应减少,训练数据在7个数据节点条件下执行的时间是单机条件的58.3%,测试数据仅仅为40%。测试结果说明改进后的KNN算法能满足实际并行分布式环境下大数据处理的需求。由此可以看出将算法改造后,能够很好的提高处理数据效率,进而降低对大数据的分类工作复杂度。
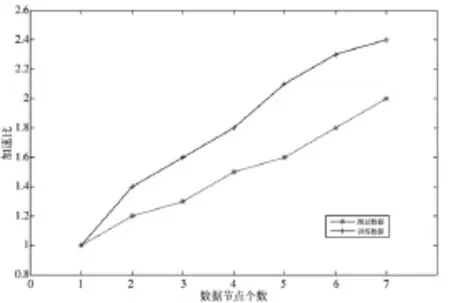
图4 加速比对比图
图4看出,两组数据的实验运行加速比曲线都是成正相关的,即随着数据节点个数的增加实验运行加速比有明显提高,可以看出分布式平台在处理KNN分类算法上有很好的计算能力,可以看出,当数据量不够大时,使用分布式平台执行任务没有单机环境下执行效率高,当数据规模足够大时,并且每一个数据分片都在进行处理工作时,集群的效率最高,训练数据和测试数据这两组数据的加速比分别提高了140%和100%。实验通过对两组数据的运行加速比进行研究分析,表明分布式计算在集群环境下运行效率最高。
4 结论
本文在研究过程中主要实现了如下内容:对KNN分类算法的研究与分析,提出了基于决策表和核属性值的两次属性约简的改造,对改造后的KNN算法进行MapReduce并行化研究实验。通过研究过程及实验分析得出了如下结论:
(1)实验通过对数据进行两次属性约简,大大减少了数据冗余,提高了实验的运行效率;
(2)对改造后的算法使用MapReduce编程模型进行实验设计,并在Hadoop平台上进行并行化实验分析;
(3)实验表明在大数据环境下,属性约简后的数据在集群环境下执行算法提高了KNN算法的加速比和可扩展性,算法效率也随着集群规模的扩大而变高。
实验证实了通过对现有经典KNN算法的改进可以大大提高其执行效率,减少工作量,在下一步的研究过程中还将对数据量进行扩大,研究对比数据量变大时算法的执行效率是否会有所影响,以及再次改良后算法的执行情况。
[1]王元卓,靳小龙,程学旗.网络大数据:现状与展望[J].计算机学报,2013,36(6):1125-1138.
[2]闫永刚,马廷淮,王建.KNN分类算法的MapReduce并行化实现[J].南京航空航天大学学报,2013,45(4):
[3]Papadimitriou S,Sun J.DisCo:Distributed Co-clustering with Map-Reduce[C].Data Mining,IEEE International Conference on.IEEE,2015:512-521.
[4]鲍新中,张建斌,刘澄.基于粗糙集条件信息熵的权重确定方法[J].中国管理科学,2009,17(3):131-135.
[5]汪凌,吴洁,黄丹.基于相对可辨识矩阵的决策表属性约简算法[J].计算机工程与设计,2010,31(11):2536-2538.
[6]张著英,黄玉龙,王翰虎.一个高效的KNN分类算法[J].计算机科学,2008,35(3):170-172.
[7]樊存佳,汪友生,边航.一种改进的KNN文本分类算法[J].国外电子测量技术,2015(12):39-43.
[8]Zhu P,Zhan X,Qiu W.Efficient k-Nearest neighborssearchinhighdimensionsusingMapReduce[C].Fifth International Conference on Big Data and Cloud Computing.IEEE,2015:23-30.
[9]Xueli W,Zhiyong J,Dahai Y.An improved KNN algorithm based on kernel methods and attribute reduction[C].Fifth International Conference on Instrumentation and Measurement,Computer,Communication and Control.IEEE,2015.
[10]吴强.采用粗糙集中可辨识矩阵方法的概念格属性约简[J].计算机工程,2004,30(20):141-142.
[11]鲁伟明,杜晨阳,魏宝刚,等.基于MapReduce的分布式近邻传播聚类算法[J].计算机研究与发展,2012,49(8):1762-1772.
[12]王煜.基于决策树和K最近邻算法的文本分类研究[D].天津:天津大学,2006.
[13]梁鲜,曲福恒,杨勇,等.一种高效的全局K-均值算法[J].长春理工大学学报:自然科学版,2015,38(3):112-115.
[14]王鹏,王睿婕.K-均值聚类算法的MapReduce模型实现[J].长春理工大学学报:自然科学版,2015,38(3):120-123. wirless channels[C].Rhodes:Vrhicular Technology Conference,2001:680-692.
The Research of Modified KNN Classification Algorithm Based on MapReduce Model
QIU Ningjia,GUO Chang,YANG Huamin,WANG Peng,WEN Nuan
(School of Computer Science and Technology,Changchun University of Science and Technology,Changchun 130022)
An attribute reduction algorithm is proposed.The algorithm will be classified data samples for the two reduction processing--attribute reduction of the initial decision table and second reduction based on kernel attribute value. The method of attribute reduction is to delete the redundant data,and then to improve the classification accuracy of KNN algorithm.On the basis of the application of the MapReduce parallel programming model,the parallel computing experiments are implemented in the Hadoop cluster environment.The experimental results show that the efficiency of the improved algorithm in the cluster environment has been greatly improved,which can effectively deal with the experimental data.Experimental implementation of the speedup is also significantly improved.
KNN;attribute reduction;MapReduce programming model;hadoop
TP391
A
1672-9870(2017)01-0110-05
2016-08-01
吉林省科技发展计划重点科技攻关项目(20150204036GX)
邱宁佳(1984-),男,博士后,讲师,E-mail:269212811@qq.com
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
科技创新与应用(2020年6期)2020-02-29 10:39:27
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
自动化学报(2018年2期)2018-04-12 05:46:01
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
成都信息工程大学学报(2017年1期)2017-07-21 14:14:11
北京理工大学学报(2016年6期)2016-11-22 11:17:22
电视技术(2016年9期)2016-10-17 09:13:41
