
基于CNN网络的汉字图像字体识别
2017-03-29 06:56:58刘志伟
现代计算机 2017年5期
刘志伟
(四川大学计算机学院,成都 400000)
基于CNN网络的汉字图像字体识别
刘志伟
(四川大学计算机学院,成都 400000)
在传统的OCR文字识别系统中,研究者主要关注的主要问题是文字的识别。但是由于现代印刷技术的发展与应用,对于印刷体文字版面的恢复成为当前一种重要应用需求。不仅需要识别出文字,还应该识别出文字的字体格式。目前针对汉字字体识别的研究较少,而且大部分基于特征提取方法,主要以局部特征,和全局特征为主。提出一种基于CNN的深度学习方法,来处理汉字字体识别。和以往的方法相比较,该方法识别率高,速度快,适用于复杂的应用环境,具有良好的实际使用价值。
OCR;CNN;识别;字体识别;特征提取
1 研究背景
现代办公要将纸质文档转换为电子文档的需求越来越多,目前针对这种应用场景的系统为OCR系统,也就是光学字符识别系统,例如对于古老出版物的数字化。但是目前OCR系统[1]主要针对文字的识别上,对于出版物的版面以及版面文字的格式的恢复,并没有给出相应的解决方案。对于版面恢复中主要遇到的困难是文字字体的恢复。对于汉字字体识别问题,目前主要有几种方法,但是都是基于人工特征提取的方法。以往的方法主要分为两大类,第一种为整体分析法,将一整片数据看做采用小波纹理分析抽取字体特征用于分类[2];使用滤波器提取文字的全局文字特征作为分类特征;使用小波包做多级分解,提取字体纹理特征的方法了[3];使用人工经验方式提取特征。可以看到这些方法都有一个重要的缺陷,如果一个文字整个版面含有不同的字体信息,这种场景就不能采用整体分析法。第二种为个体分析法,个体分析法对象为单个字符图像,依然采用小波分解提取特征。这种方法需要知道单个汉字的图像,对于现代出版物的识别系统中,可以很容易得到单个汉字的图像。很显然这种方法可以解决整体法不能解决文字中夹杂其他字符比如英文的情况。另外有人提出特征点[4]的方法来处理汉字字体识别,但是特征点的提取也是有问题。因为定义提取的特征需要人为干预,
由此可见,在考察完整体法和个体法来看,个体法明显更灵活并适用于多种情况。本文将采用个体法来实现汉字字体识别。但是应该看到传统方法基本上都是采用图像处理的方法,计算复杂度都很高。另外不同汉字的外形差异是不一样的,而采用图像处理的方法往往不能有效解决这个问题。
综上所述,我们可以看到传统汉字字体识别方法的不足,因为汉字字符的复杂性,特征提取方法不能处理多变的汉字外形,特征点提取方法需要人工专家定义重要的特征点位置。而且,对于哪些特征点重要也不能给出统一的标准。故而本文提出一种基于CNN[5]的字体识别方法。CNN网络可以靠卷积核以及池化层,自动生成特征,这就避免人为特征提取上的不稳定性以及盲点。我们通过计算机内嵌的字体生成实验数据,然后训练CNN深度学习网络。最终实现结果显示出了良好的稳定性,较高的正确率,一次训练多次使用等通用性好的优点。
2 CNN字体识别原理
与传统特征提取方法不同,卷积神经网络通过卷积核提取特征,每一个神经元和前一层的局部感受区域相连,通过卷积核计算局部特征。以卷积窗口的移动生成特征平面,每一个特征平面共享一个卷积核,做到权值共享,降低了权值的数量的优点。CNN网络主要用于识别二维图像,由于共享权值采用监督学习的方式得到。所以避免了人为提取特征,故而CNN具备从训练数据中学习共享权值的优点。通常CNN网络分为多层,其中一种叫卷基层,一种叫池化层,卷基层和池化层可以有多个。分别用于特征的提取和特征参数的处理。
如图1所示,输入数据为一张32x32的像素图片。先看第一层卷基层,如果采用5x5的卷积核也就是25个权值。然后通过平移卷积窗口得到一个28x28的特征图。上图中我们采用6张特征图,也就是提取了6种不同的特征。然后进入第二层池化层,我们以第一层卷基层的输出数据,作为池化层的输入数据。采用2x2的均值化方法,得到6张14×14的池化层数据。接下来反复的采用这种方法,可以设置多层网络来生成复杂的预测模型。CNN网络最后一部分为直接相连部分,和传统神经网络一样,最后采用损失函数来计算误差值。通过误差值采用向后传导的方式修正权值,达到训练网络的目的。
3 生成训练数据
在现代计算机中有各种truetype字体。所以我们通过获取计算机内部的字体生成图像数据。使用.NET编程生成数据,我们采用.NET提供的图像绘制功能生成汉字图片,核心代码如下。输入参数为需要生成图像的汉字字符,输出为一个bmp位图。

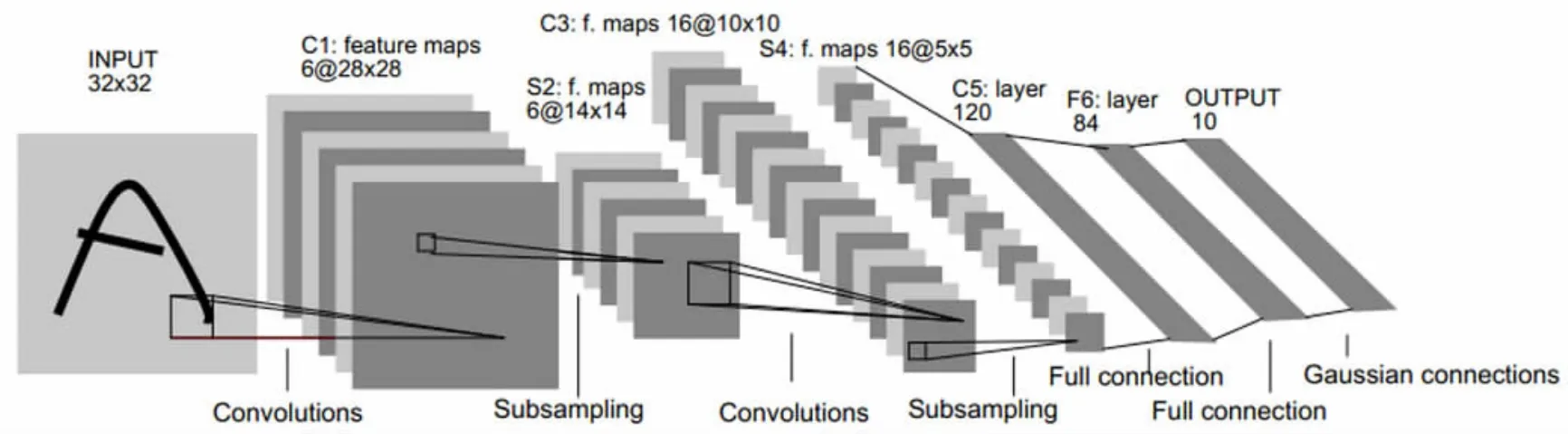
图1

图2
我们把在实际生活中常用的8种字体,宋体、楷体、隶书、黑体、幼圆、华文行楷、华文新魏、华文舒体,作为我们研究的重点。我们使用7800多个汉字字库中的数据,对每一个汉字生成一个64×64的图片数据,对于这八种字体我们总共可以得到62400多个图像数据,并对这些图像数据根据字体的不同分别进行类标,宋体1、楷体2、隶书3、黑体4、幼圆5、华文行楷6、华文新魏7、华文舒体8。然后,随机抽取10000个数据集作为验证数据,剩下50000个数据作为训练数据。实验数据生成如图2,分别是幼圆、隶书、黑体、宋体、华文行楷、华文舒体、华文新魏、楷体。
由于在实际的应用中,光学扫描件受到噪声的干扰,图像中会出现噪点扭曲以及旋转的状况。所以我们另外编制程序对计算机原始生成的图像数据,进行随机的噪点生成,旋转,以及扭曲操作,这样就可以生成更多的数据。我们对于每一个图像采用这种方法生成新数据,数据量至少提高三倍。也就是187200个数据。对于采用不同的旋转角度,不同的噪声点生成方法以及扭曲算法的随机生成。我们可以获得更多的数据量。
4 CNN网络设计
我们选用流行的CNN网络框架Caffe,深度学习Caffe框架是一个C++/CUDA架构,支持命令行以及Python和MATLAB接口,CPU和GPU可以切换的易用性框架。Caffe框架的优点有,易用性,模型和优化都是靠文本的方式。另外速度快,可以结合cuDNN运行海量数据,模块化程度高,开放性好等点。
由于我们的输入数据是64x64的位图信息,第一层卷基层我们目前采用10x10的卷积核来提取特征。定义32张特征平面输出,窗口滑动步长为2。第一层代码简要示例如下所示。池化层的定义也采用类似的结构定义。而我们采用的CNN网络定义,结构流程图见图3。
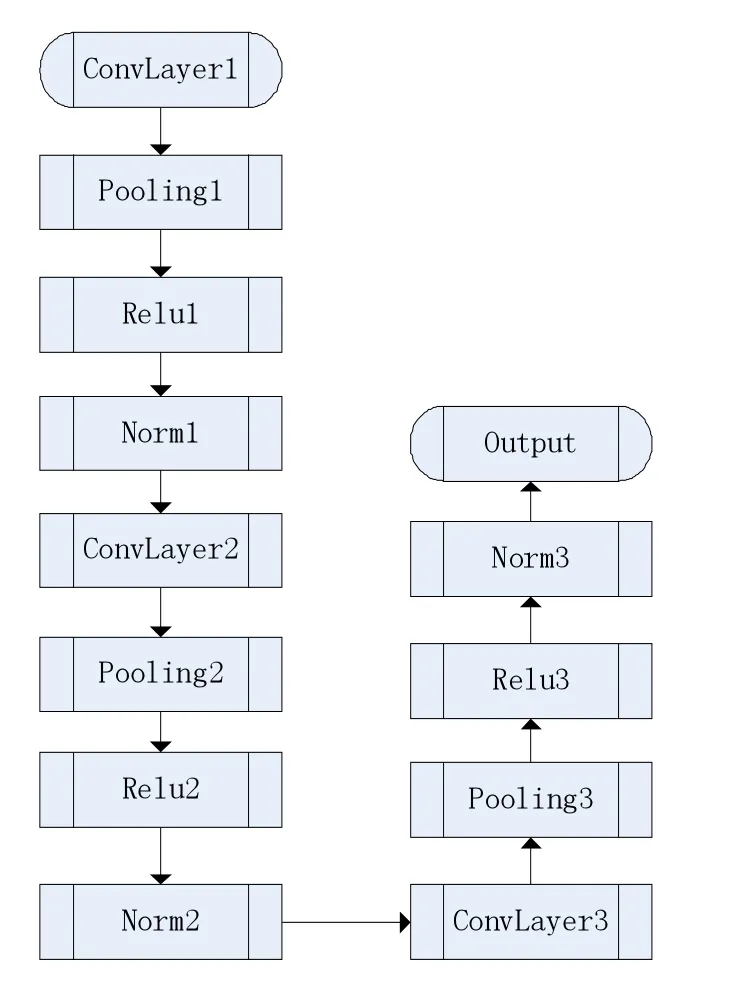
图3

5 试验数据与分析
本文试验环境搭配为,英特尔i5-4210处理器,英伟达GTX850M核心,内存12GB,在CUDA7.5下运行Caffe。实验数据由180000个字符组成,其中150000作为训练数据,30000作为验证数据。Caffe网络迭代60000次训练,每1000此生成一次错误率与正确率的验证结果,在Windows操作系统下运行10多个小时。得到错误率和正确率的结果如图4。横坐标代表,每1000此迭代纵坐标代表准确率以及错误率。由图4可以清晰的看到CNN方法对于汉字字体识别的准确率非常高,而错误率很低。这是一种在实际应用中非常好的方法。
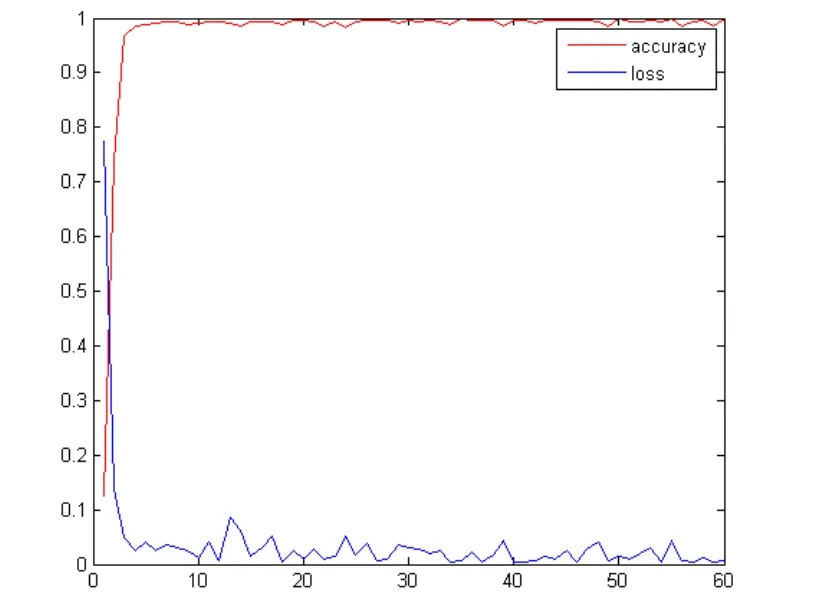
图4
6 结语
本文给出了基于CNN网络的汉字字体识别方法。详细说明CNN网络的设置方法以及训练数据的生成方法。该方法解决了以往字体识别体统的存在人为提取特征的不足,对于印刷体汉字的字体识别做到了很高的字体识别率,对于解决实际应用中的排版修复有一定的实际意义。
参考文献:
[1]Xing Xiang-hua,Gu Guo-hua.Method of Quickly Recognizing Vehicle Plate Based on Pattern Matching and Characteristic Dot Matching.Optoelectronic Technology,2003,23(4):268-270.
[2]Zhu Yong,Tan Tie-niu,Wang Yun-hong.Font Recognition Based on Global Texture Analysis.IEEE Transactions on Pattern Analysis and Machine Intelligence,2001,23(10):1192-1200.
[3]王洪,汪同庆,刘建胜,朱永权,黄甫征声.基于小波包纹理分析的字体识别方法.光电工程,2002,29(S1):62-65.
[4]王恺,靳简明,史广顺,王庆人.基于特征点的汉字字体识别研究.天津:南开大学机器智能研究所.北京:NEC中国研究院,2008.2
[5]Jurgen Schmidhuber.Deep Learning in Neural Networks:An Overview,The Swiss AI Lab IDSIA Istituto Dalle Molle di Studi Sull'Intelligenza Artificiale University of Lugano&SUPSI Galleria 2,6928 Manno-Lugano Switzerland 2 July 2014.
Chinese Text Font Recognition Based on CNN
LIU Zhi-wei
(College of Computer Science,Sichuan University,Chengdu 610044)
In the traditional OCR character recognition system,the main problem is the recognition of characters.However,due to the development and application of modern printing technology,the restoration of printed text layout became an important application requirement.It is not only to recognize the text,but also recognize the text font style.At present,there are few studies on the character recognition of Chinese characters,and most of them are based on the feature extraction methods,especially on local features and global features.Proposes a CNN based depth learning method to deal with Chinese character font recognition.Compared with the previous methods,this method has high recognition rate and high speed,which is suitable for complex application environment,and has good practical application.
OCR;CNN;Recognition;Font Recognition;Feature Extraction
1007-1423(2017)05-0067-04
10.3969/j.issn.1007-1423.2017.05.016
刘志伟(1987-),男,重庆人,本科,研究方向为人机交互、模式挖掘
2016-12-06
2017-02-10
猜你喜欢
华人时刊(2022年11期)2022-09-15 00:54:28
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
娃娃乐园·综合智能(2020年2期)2020-03-12 10:30:28
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
海外华文教育(2017年6期)2017-08-07 03:10:51
国际汉语学报(2016年2期)2016-05-17 04:04:01
小雪花·成长指南(2014年10期)2014-10-31 18:10:08
电视技术(2014年19期)2014-03-11 15:38:20
海外英语(2013年9期)2013-12-11 09:03:36
