
增强学习算法寻找最优策略分析
2017-03-27 20:44孙灿宇
电子技术与软件工程 2017年4期
摘 要 如今人工智能发展迅速,在日常生活中越来越普及,与人工智能接触的机会越来越多。本文介绍了增强学习中的Q学习中如何找到最优策略以达到最终状态的过程和总结,以及通过试验对影响Q值的几个因素的进行了分析。
【关键词】Q-learning 策略 探索 Q值 状态
1 实验背景
文章研究增强学习算法是如何找到最优策略以达到最终状态的。通过使用off-Policy TD Control即Q learning实现。
2 实现和实验
2.1 方法和影响因素
起初机器人对环境一无所知,能做的只是采取行动然后根据反馈的信息进行判断。每次行走之前机器人会根据当前的动作产生一个次优策略。随着机器人行走步数增多,逐渐会优化行走策略。对于增强学习(Q-learning)考虑以下影响因素:
S:一组状态
A:机器人能够采取的动作
T:转换函数T
α:学习率,可扩展的范围和方向(范围从0到1)
γ:折扣因子(范围从0到1)
Living reward:生存状态时的奖励
Epsilon:随机采取动作或者在当前的策略上采取动作(范围从0到1)
Noise:一个影响机器人是否能采取正确动作的因子(范围从0到1)
注:s是当前状态,s是由当前状态执行操作后的状态。
以上等式可以计算出Q值。最开始初始化Q值表中的每一个值为0。
每轮假设机器人从state 8开始采取动作到下一个状态。当机器人选择向上走(up)时,有(1-noise)的可能到达state 4,也有一定可能到达state 9或原地不动(除开边界和有障碍的情况)。从开始到结束机器人决定是否探索或者采用当前策略,显然不探索就无法确保得到了最优的策略,不采取當前策略这很有可能在无用的尝试上浪费大量的时间。
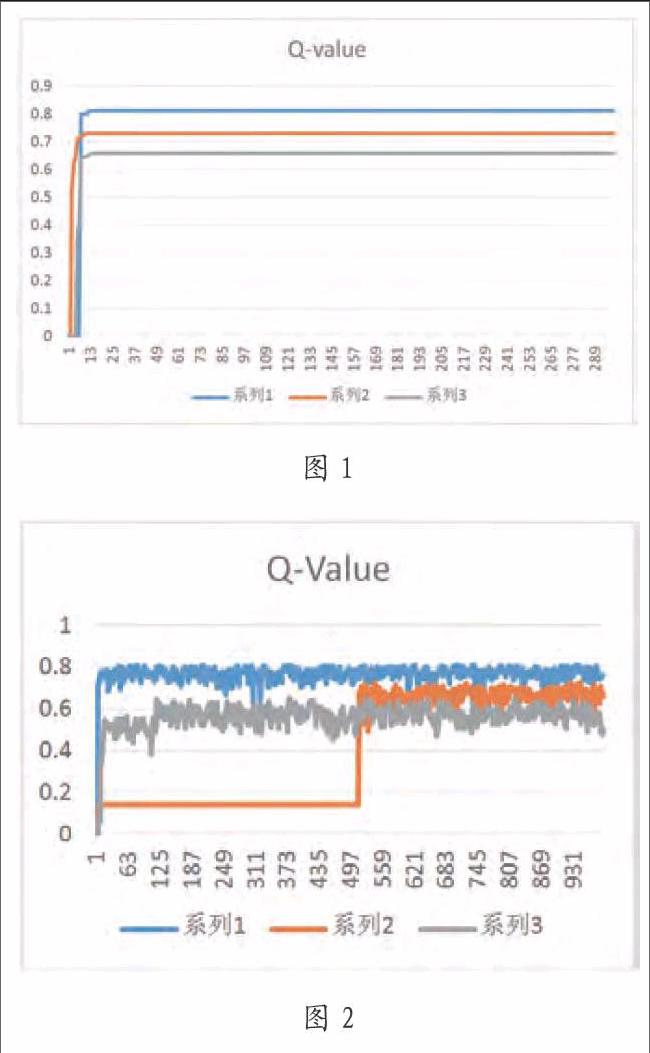
2.2 实验数据
2.2.1 将参数设置为
与epsilon=0相比这种情况更理想,因为这种情况保证至少每种state能够被探索一遍。所以这种情况的Q值更为合理有更快的收敛速度。但这不是最理想的情况,因为机器人有可能采取同样的动作会浪费大量时间去计算Q值。
3 总结
让探索更加有效率而非重复相同的动作,采用了一个探索函数提高效率。实现这个函数需建立一个数组记录到达每个状态的次数,当计算值时需要用有效状态的访问次数。访问的次数越少,探索的奖励就越高。
Noise因素,若程序中没有Noise因素(noise=0),Q值则会很快收敛,当noise的值增加,Q值则会不稳定。对于Alpha (α) 和折扣因子Gamma(γ),这两个参数的值不宜太小。因为Alpha的值越小,Q值收敛的速度越慢。一般来说,Alpha因素的值应该在整个过程中是改变的。对于折扣因子(γ),用来判断即刻反馈和未来反馈哪一个更重要。γ=1表示未来反馈和即刻反馈同样重要,γ=0表示只考虑即刻反馈的因素。因此,γ因子也需要根据不同的场景进行改变。
参考文献
[1]Richard S.Sutton & Andrew G.Barto.Reinforcement Learning:An introduction[M].Massachusetts:MIT Press,1998:12-16.
[2]Tom M.Mitchell. Machine Learning:A Guide to Current Research[M].Germany: Springer,1986:265-278.
作者简介
孙灿宇(1995-),男,重庆市人。现为四川大学软件学院软件工程系本科在读。主要研究方向为软件工程。
作者单位
四川大学软件学院软件工程系 四川省成都市 610207
猜你喜欢
中学生数理化(高中版.高考理化)(2020年2期)2020-04-21
小学生作文(低年级适用)(2019年9期)2019-10-08
小学生作文(低年级适用)(2019年5期)2019-07-26
数学大世界(2018年1期)2018-04-12
读友·少年文学(清雅版)(2018年12期)2018-04-04
大学教育(2016年9期)2016-10-09
时代英语·高三(2014年5期)2014-08-26
