
大数据及其体系架构与关键技术综述
2017-03-25 03:20:34吕登龙朱诗兵
装备学院学报 2017年1期
关键词:架构
吕登龙, 朱诗兵
(1. 装备学院 研究生管理大队, 北京 101416; 2. 装备学院 信息装备系, 北京 101416)
大数据及其体系架构与关键技术综述
吕登龙1, 朱诗兵2
(1. 装备学院 研究生管理大队, 北京 101416; 2. 装备学院 信息装备系, 北京 101416)
介绍了大数据的发展现状、研究动态和应用前景。针对大数据标准不统一、研究观点纷杂的问题,以比较辨析的方法从新的视角重新定义了大数据;注重安全性研究,分析总结了大数据的“6V”特征;从大数据标准化入手,深入分析现有研究成果,归纳总结了大数据的体系架构和目前大数据应用的共性技术,分析了各类技术的内涵,使大数据体系架构和关键技术有较为系统的展现。
大数据;体系架构;关键技术
近年来,随着移动互联网、物联网、云计算、社交网络、传感器、数据存储等技术和服务的迅猛发展,导致网络数据呈爆炸式增长。据统计[1],中国互联网的社交媒体用户达6.59亿,超过了美国和欧洲的总和,各种App的应用,使得网络数据急剧增长。同时,教育、医疗卫生、金融、科学研究等各行业也在源源不断地产生数据,世界已经进入大数据时代,并正受其影响和推动发展。根据国际数据公司(International Data Corporation,IDC)数字宇宙(Digital Universe)监测显示[2],全球数据量以大约每2年2倍的速度增长,预计到2020年,全球数据总量将达到44ZB。IDC报告显示[3],2014—2019年全球大数据技术和服务市场复合年增长率达23.1%,2019年大数据市场总规模将达486亿美元;2014年IDC对中国2013—2017年大数据与服务市场的预测[4]显示,中国将保持38.7%复合年增长率,到2017年大数据的市场规模将增长到8.501亿美元;未来几年,世界企业将进入规模化的数字化转型阶段,此过程将会产生更巨大规模的数据。
大数据已经引起了世界各国和地区的广泛关注。美国将大数据研究和应用提升到了国家战略层面,接连出台了《大数据研究和发展计划》《支持数据驱动型创新的技术与政策》《大数据:把握机遇,守护价值》等决策性和指导性文件,并在应用领域已经处在世界的领先地位。“棱镜门”事件曝光了美国对全球的监控计划,一方面凸显了美国在全球数据掌控的绝对优势,另一方面也为世界其他主要国家敲响了数据保卫战的警钟。欧盟成立了欧洲网络与信息安全局(European Network and Information Security Agency ,ENISA),并将数据应用提升到战略层面,出台了《数据价值链战略计划》,英国还专门制定了《英国数据能力发展战略规划》。日本、韩国也分别制定了《创建最尖端IT国家宣言》和《大数据中心战略》。我国也意识到了大数据及应用的重要性,实施了国家大数据战略,从2015年3月至9月,接连制定了《“互联网+”行动计划》《大数据产业“十三五”规划》,实施“加快推进云计算与大数据标准体系建设”计划,出台了《关于积极推进“互联网+”行动的指导意见》和《促进大数据发展行动纲要》等。随着信息技术在军事领域的应用发展,军事数据也呈现爆炸式增长趋势,军事大数据时代也已经到来。未来信息化战争更多的是数据驱动下的战争,谁掌握更多的数据,谁能在瞬息万变的战场态势下快速进行数据分析处理,谁就能掌握制数据权,就会获得战争的胜利。
研究结果表明:目前大数据的概念、体系架构、关键技术等方面还有待标准化,在安全和隐私保护方面还面临着严峻挑战,从概念提出到技术应用、再到科学研究的“第四范式”,大数据还有很大的研究和发展空间。本文分析了大数据的概念、特点及发展现状,重点分析、归纳、总结了大数据的体系架构和关键技术。
1 大数据基础研究
1.1 大数据定义及特征分析
对于大数据,目前在研究和应用领域还没有一个标准的定义,比较流行的定义主要有2类:(1)大数据是从规模巨大、形式多样的数据中,通过高效捕捉、发现和分析获取有价值信息的一种新的技术架构,是从“What is big data?”的角度定义,IDC、IBM以及百度百科等持这种观点[5-7],主要强调的是一种数据处理的技术架构;(2)大数据包括结构化和非结构化数据,它的规模相当庞大以至于用传统的数据库和软件技术很难对其进行处理,是从“How hard to deal with big data!”的角度定义, Mckinsey、Gartner以及维基百科等持这样的观点[8-10],主要强调的是处理大数据的困难所在。
2类定义都一定程度反映了大数据的最基本特点:大规模(Volume)、多样性(Variety)和高速性(Velocity),简称大数据的“3V”特性[11]。随着对大数据研究的深入,研究者对大数据的特点进行了深度挖掘和总结,将大数据的“3V”特性进行了丰富和扩展,又有了“4V”[12]、“5V”[13-14]、“6V”和“7V”[15-16]的特性概括,而比较公认的是“5V”特性。当然,对大数据关注的重点不同,研究者对大数据特性的理解和总结也会有所不同。
作者认为:大数据在推动经济社会创新发展及创造社会效益的同时,本身的安全问题也日益面临着严峻挑战,大数据及大数据设施极易成为被攻击的目标,大数据分析和服务也极易泄露个人隐私、企业等机构的敏感信息,甚至是国家机密。
就此来看,大数据还应包含另外一个重要特性:Vulnerable(易受攻击),构成“6V”特性(Volume, Velocity, Variety, Value, Veracity and Vulnerable)比较合理,这6个“V”共同作用,构成了大数据的特征体系,贯穿于从数据源到数据分析再到数据解释的整个大数据生命周期,表1对大数据的“6V”特性进行了具体描述。

表1 大数据“6V”特性的具体描述

续表
1.2 大数据与传统数据对比分析
为了更好地研究大数据,我们将前节所述2类定义进行了融合处理,这样来定义大数据:大数据规模巨大、形式多样(包括结构化和非结构化数据),通过传统的数据库技术和数据分析技术难以进行处理,只有采用新的技术架构才能高效捕捉、发现和分析,并从中获取有价值的信息。可以看到大数据在数据结构、体量、处理、存储等方面与传统数据有很大的区别,这些区别主要体现在数据分析模式的不同。图1显示了大数据分析模式的模型架构。从模型架构上来看,传统数据来源一般为各种业务系统,数据主要是结构化的,存储在关系型数据库中,需要将数据从这些关系数据库中通过抽取、转换和加载等一系列操作后,转移到数据仓库中再进行数据分析,分析过程主要是线下分析;大数据来源广泛,除了传统业务系统的关系型数据库外,还包括移动终端、传感器网及社交媒体等来源,数据类型既有结构化的也有非结构和半结构化的,分析过程既有线上分析也有线下分析,分析模式不仅包含了传统的数据分析,还解决了传统模式下无法很好对非结构化、半结构化及实时流数据进行分析的问题,同时大数据技术也一定程度缓解了传统数据处理软件和硬件无法对海量数据进行分析处理的压力。
大数据与传统数据的具体区别,如表2~表4所示。
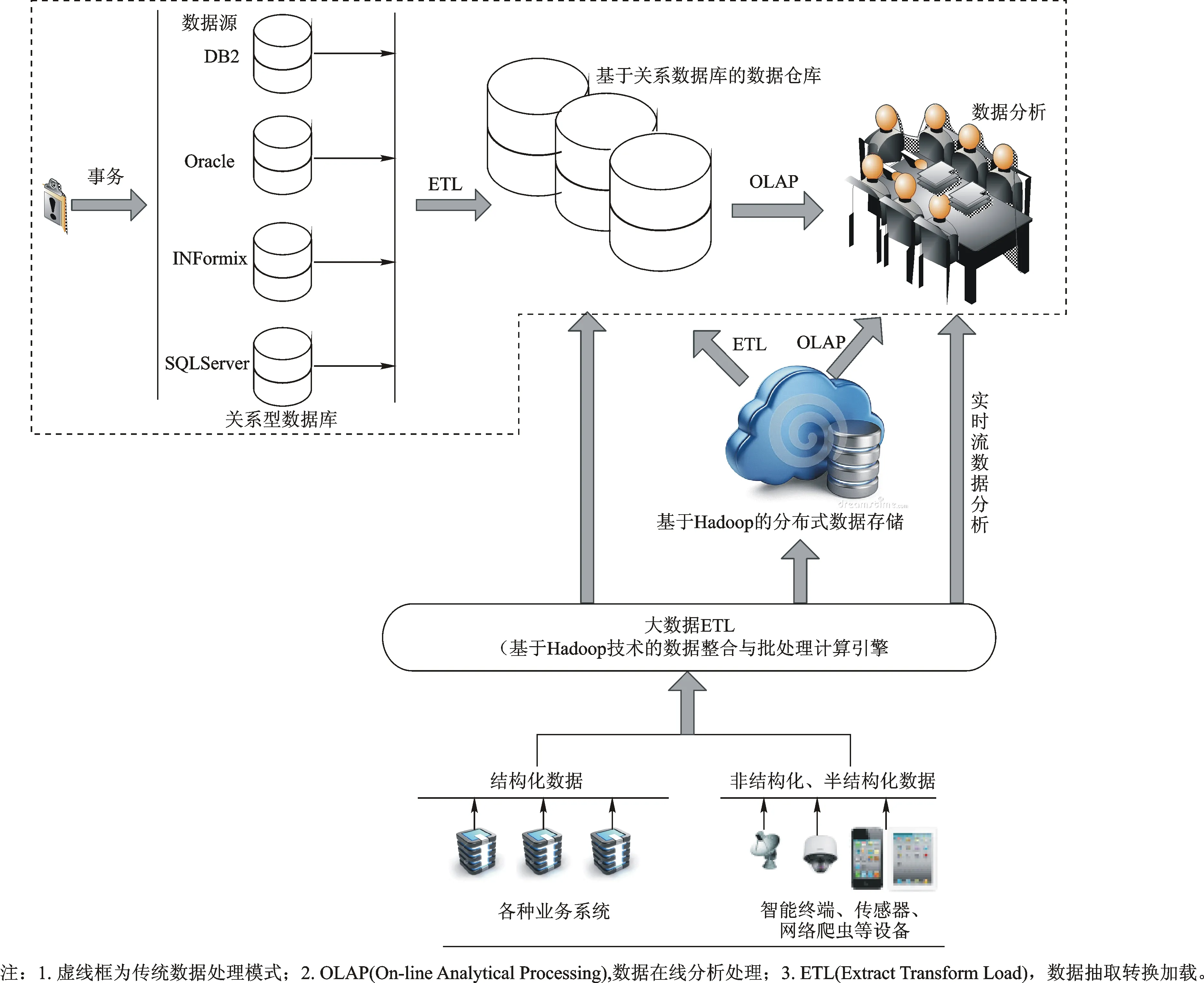
图1 大数据分析模式的模型架构

比较项目传统数据大数据数据来源数据来源单一,一般为各种业务系统的关系型数据库,约占数据总量的20%数据来源多,除了业务系统外,各种智能终端、传感器、网络爬虫、云服务、社交媒体等都是大数据来源,约占数据总量的80%数据类型类型单一,以结构化数据为主类型多样,既包括结构化数据,也包括半结构和非结构化数据数据规模一般是GB至TB规模TB、PB、EB甚至ZB规模,不同行业和领域的规模会有不同产生模式先有模式后有数据难以预先确定模式,数据出现后才能确定,数据模式会不断演化存储模式关系型数据库和数据仓库,可扩展性差既有关系型数据库和仓库,也有键值存储、列存储、文档存储、图形存储等非关系型数据库和仓库,分布式设计,易于扩展分析方法针对部分数据的采样分析、统计学针对所有数据的全数据分析、统计学精准度需要精确数据不需要精确数据,允许冗余分析目标分析数据的因果关系,即知其然知其所以然除了分析因果关系外,更多的分析数据的相关关系或关联关系,即知其然不知其所以然硬件基础支持关系数据库的大型服务器,受关系数据库制约,硬件难以进行横向扩展,处理大数据受限。支持关系和非关系数据库的大型服务器集群,有很好的扩展性,能够很好地处理大数据

表3 不同数据类型特点对比
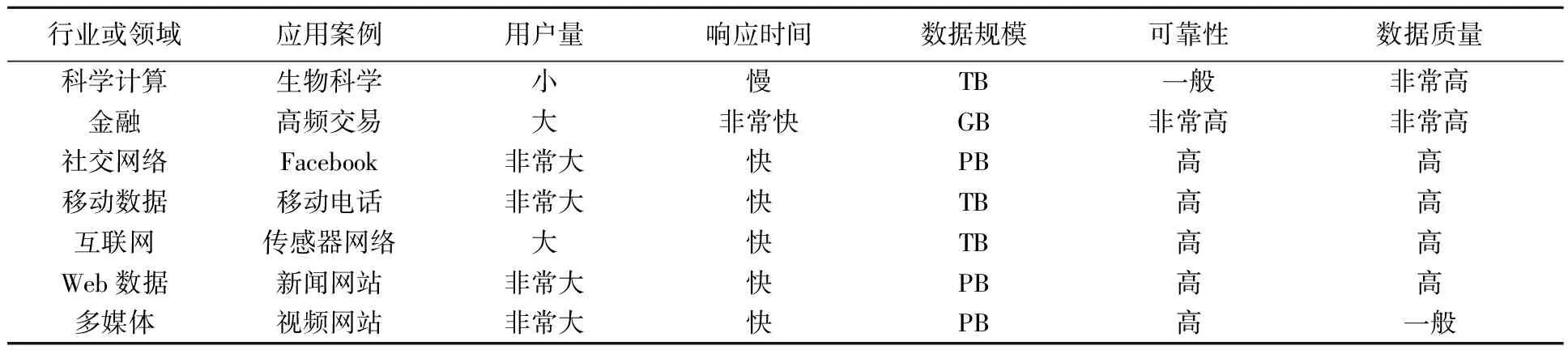
表4 不同行业或领域大数据规模对比[17]
综上所述,大数据是个系统的概念,是由大数据本身、大数据处理过程、大数据结果及运用组成的体系,缺一不可,如果不考虑大数据处理及结果运用,那么大数据仅仅是规模庞大的普通数据,也就无所谓“大数据”这一新生事物了。
2 大数据体系架构
2.1 大数据体系架构现状
对比分析Gartner公司公布的2013—2015年新兴技术炒作曲线图[18-20],可以看出大数据从2013年的火热到2014年开始走向低谷直到2015年在曲线图上消失,表明大数据技术已趋于成熟并被广泛应用。而对大数据标准化的研究始于2012年,目前从国内外研究现状来看尚处于起步阶段[21-25],大数据体系并没有统一标准的应用模型。大数据技术应用早于大数据标准化研究,从应用实际来看,大数据体系更偏向于软件系统。IEEE软件工程标准委员会对软件系统架构进行了定义[26]:软件系统架构包含各组成要素和各要素之间的相互关系、运行环境以及设计和运行原理描述。大多数研究机构和组织也主要基于软件系统来研究大数据体系架构。

图2 大数据参考架构
美国国家标准与技术研究院(National Institute of Standards and Technology,NIST)对9种大数据解决方案的体系架构进行了详细剖析和对比分析,确定了大数据体系架构的共性部分,在此基础上按照逻辑角色和商业应用的目的给出了大数据参考架构[27-28],中国电子技术标准化研究院对NIST研究成果进行了丰富和完善[29],在原有架构的基础上细化出活动和组件的概念,明确了角色的行为动作和行为的环境支撑以及相互之间的逻辑关系,使得整个架构更加具体形象,如图2所示。整个参考架构围绕2个价值链进行构建:横向为信息价值链,通过数据收集、集成、分析、分析结果应用创造价值;纵向为信息技术(IT)价值链,通过提供网络、基础设施、平台、应用工具及其他服务创造价值。架构定义了5个逻辑角色:数据提供者、大数据应用提供者、大数据框架提供者、系统协调者和数据消费者,整个架构以大数据应用提供者为中心提供了连通其他4个角色的接口。架构包含了2个服务和功能保障构件:安全隐私和管理,分别对各接口和大数据框架提供者内部进行安全与隐私监管以及对全系统各要素进行统一管理,从而构成大数据应用的完整体系。

图3 大数据技术参考架构
文献[22]借鉴了ISO/IECJTC1/SC32(数据管理和交换分技术委员会)对大数据标准概念模型的研究成果,提出了大数据技术参考架构,如图3所示。该架构综合考虑数据的生命周期,采取分层的模型结构,将大数据技术按照生命周期划分为4个层次、2个技术支撑体系。其中,4个层次包括数据采集层、数据支撑层、数据服务层和共性应用层;2个技术支撑体系包括数据传输技术体系和数据安全技术体系。层与层之间形成服务与依赖的关系,下层为上层提供服务,上层依赖于下层服务,2个技术支撑体系分别保证了层间及层内数据通信畅通和可靠的信息安全环境。
虽然不同机构或组织对大数据体系架构的设计有所不同,但从解决问题的实质上来看,不同的体系架构之间又有共性的方面:(1) 工作流程主要围绕大数据生命周期进行设计;(2) 工作方法主要依靠分布式存储和分布式并行处理来实现;(3) 基础设施具有良好的扩展性;(4) 大数据隐私和安全被广泛重视。
如同其他技术或事物一样,大数据体系会逐渐趋于一致并最终实现标准化,而具有普遍适用的标准又能更好地为大数据研究和应用提供理论指导和技术参考。
2.2 典型大数据开源架构
目前,比较流行的典型大数据处理开源架构主要有Hadoop、Storm和Spark 3种。
_2.2.1 Hadoop
Hadoop的核心思想是通过大量高效的硬件集群和标准接口构建大规模分布式计算系统,以软件处理的方式为海量数据提供存储和计算。Hadoop的核心组件是HDFS(Hadoop Distributed File System)和Hadoop MapReduce,其他组件为核心组件提供配套和补充性服务,其基本体系架构如图4所示[30-31]。

图5 HDFS基本体系架构

图4 Hadoop基本体系架构
1) HDFS。其思想来源于Google文件系统(Google File System,GFS),是GFS的开源实现。HDFS特点之一是以流式数据访问模式实现超大规模数据集存储。HDFS采取数据集一次写入、多次读取方式[32-34],实现了分布式环境下流式访问数据的能力,保证了数据的大吞吐量。HDFS的基本体系架构如图5所示,总体上采用了主从式执行模式,主要由Client、NameNode、SecondaryNameNode和DataNode几个组件构成。
Client是客户端,主要功能是为用户提供访问文件系统的接口,通过NameNode和DataNode交互访问HDFS中的文件;NameNode是HDFS的主节点,负责协调客户端对文件系统的访问,管理文件系统的命名空间、文件目录树和元数据信息,并且负责监控和调度DataNode;DataNode是NameNode的从节点,负责数据的实际存储,同时DataNode以Heartbeat的方式向NameNode报告节点的健康状况。SecondaryNameNode是监控HDFS运行状态的辅助节点,在NameNode出现问题时及时进行热备份来代替NameNode。
2) Hadoop MapReduce。其主要设计目标是为用户提供抽象的程序模块,简化分布式程序设计,将用户从繁琐的接口和通信等程序设计中解放出来,只专注应用程序的设计,从而提高程序开发和解决大数据问题的效率。MapReduce也采取master/slave结构模式,基本体系架构如图6所示,主要由Client、JobTraker、TaskTracker和Task几个组件构成[34-38]。
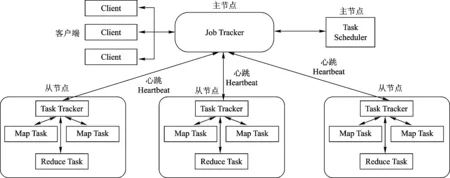
图6 Hadoop MapReduce基本体系架构
Client客户端,主要负责将用户编写的应用程序提交给JobTracker,并为用户提供查看作业(Job)运行状态的接口;JobTracker是MapReduce的主节点,主要负责监控子节点TaskTracker和作业的运行状况,一旦子节点出现问题,JobTracker会将任务转移到其他子节点执行,同时JobTracker还负责跟踪任务的执行进度和资源的使用情况,发挥任务调度的作用。TaskTracker是JobTracker的子节点,主要为任务(Task)分配资源和提供执行环境;Task是任务的具体执行单元,主要分Map任务和Reduce任务。Map任务以
_2.2.2 Storm
Storm是一款开源的分布式实时流处理系统,最早由BackType公司的Nathan Marz开发,之后BackType公司被Twitter收购,随之Storm也由Twitter开源发布,目前Storm已成为Apache软件基金会的孵化器项目之一。Storm同样也采取主从式架构,核心组件包括3个部分[39-42]: Nimbus、Supervisor node和ZooKeeper cluster,基本体系架构如图7所示。

图7 Storm基本体系架构
Nimbus是Storm集群的主节点,负责向工作节点分发应用代码和分配任务,同时监控任务的执行状态和工作节点的健康状况。Nimbus节点被设计成“快速失败(fail-fast)”的模式,所有的数据都存储在Zookeeper上,一旦节点死掉会快速重启而不会对工作节点造成任何影响[43-44]。Supervisor是Storm集群的从节点,每个节点上运行一个Supervisor,负责创建、启动、停止工作进程,控制工作进程执行分配的任务。与Nimbus相同,Supervisor也被设计成“快速失败”的模式,所有的状态信息也存储在Zookeeper上,节点一旦死掉会快速重启而不会丢失任何状态信息。Zookeeper是整个Storm集群的桥梁,在整个系统中发挥协调作用,存储着Nimbus的数据和Supervisor的状态信息,并负责Nimbus和Supervisor的通信。
_2.2.3 Spark
Spark是在MapReduce基础上实现的高效迭代计算框架,它的最大特点是支持基于内存的分布式数据集计算,从而大大提高了运算速度。Spark最早由美国加州大学伯克利分校于2009年开发,2010年实现开源发布,2013年由Apache软件基金会接管,并成为其顶级项目。Spark核心理念是通用和速度,集成了流计算框架、图计算框架、数据查询引擎、机器学习算法库、分布式文件系统等功能和组件,其基本体系架构[45-47]如图8所示。
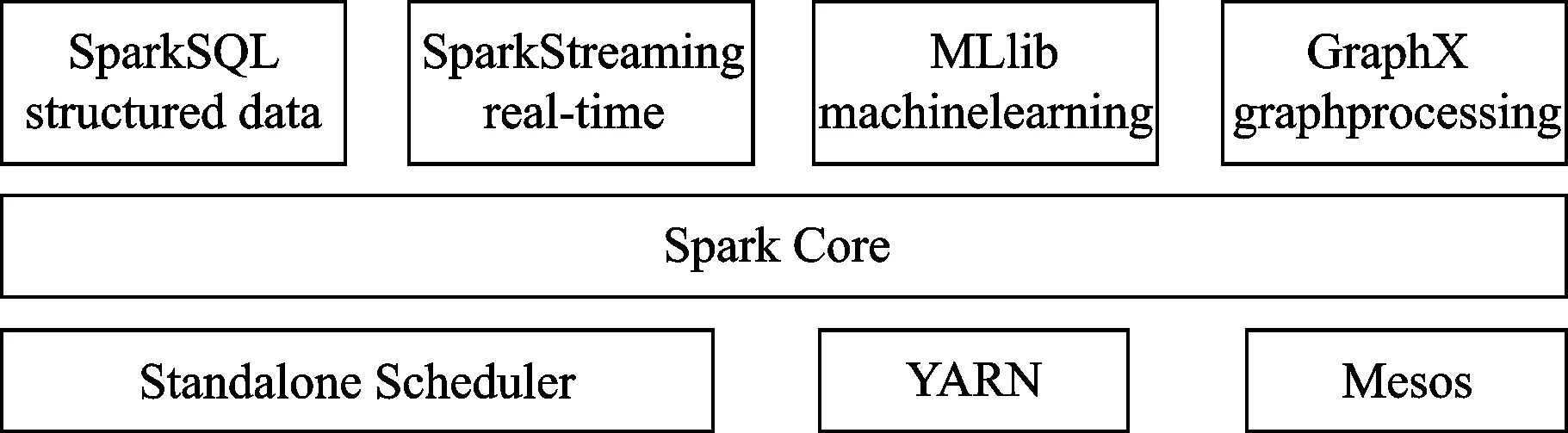
图8 Spark基本体系架构
Spark Core是Spark体系的核心,实现了Spark的基本功能,包括任务调度、内存管理、错误恢复以及和存储系统的交互,Spark Core定义了一个程序抽象模型——弹性分布式数据集(Resilient Distributed Datasets,RDD),所有的应用程序都被抽象成RDD来完成运算[45,48-49]。Spark SQL是处理结构化数据的工具,通过引入RDD数据抽象,能够通过SQL语言和集成其他SQL工具实现对结构化数据的高效查询。Spark Streaming是Spark的实时流数据处理组件,它以时间片对数据进行分割形成RDD,能够以相对小的时间间隔对流数据进行处理,同时提供良好的应用程序接口(Application Program Interface,API)和容错机制,能够与其他组件友好的合作从而高效完成对流数据的处理。MLlib是Spark的机器学习算法库,可以为处理大数据提供基本的机器学习算法,包括分类、回归、聚类等算法,同时还支持算法模型评估等。GraphX是Spark对图操作和处理大规模并行图计算的功能库,能够利用RDD API接口实现对图数据的统一高效处理。YARN、Mesos等运行于Spark体系的底层[50],负责对集群资源和数据的管理,保证Spark集群节点的扩展和统一高效运行。
_2.2.4 3种架构的比较分析
上述3种开源架构的技术特点各有不同。Hadoop采用一次写入多次读取的流式数据访问方式,更多的是以时间换空间,侧重的是数据吞吐量,不适合迭代式的数据处理,在数据处理的实时响应方面也不占优势,更适合在线下对静态大数据进行处理和分析。Storm设计理念是对大数据记录逐条持续进行处理,计算过程非主动结束,同时容错性较高,更适合对实时流数据的处理。由于集成度相对不高,Storm对其他类型的大数据处理性能还有待完善。Spark的集成程度较高,功能比较强大,能够对不同数据类型(一般结构化数据,图数据、流数据等非结构化数据)的大数据进行处理。由于Spark是基于内存计算框架,在数据量低于内存容量时计算性能突出,但当数据量远大于数据容量时存在稳定性问题[51],更适合进行规模适当迭代式数据处理。
3 大数据关键技术
在实际应用中,大数据是一项非常复杂的系统工程,既需要硬件基础也需要软件支撑,涉及的技术涵盖信息通信、计算机科学、信息网络、数据库等多个领域。单从大数据的处理流程和生命周期考虑,归纳起来,大数据的关键技术主要包括数据感知与获取技术、数据预处理技术、数据存储与管理技术、数据分析技术、数据可视化技术以及数据安全与隐私保护技术等6部分。
3.1 数据感知与获取技术
大数据应用的关键,就是从海量的看似无关的数据中,通过分析关联关系从而获取有价值的信息,有效获取目标数据成为大数据应用必须解决的首要问题。大数据类型多样,来源非常广泛,涉及人类社会活动的各个领域,其中最主要的来源有3个方面[52-53]:人们在互联网活动中产生的数据,各类计算机系统产生的数据,各类数字设备记录的数据。人在互联网活动中产生的数据为网络数据,常用到的数据感知与获取技术有网络爬虫或网络嗅探等;计算机系统产生的数据主要是日志和审计数据,常用日志搜集和监测系统来获取数据,如Scribe、Flume、Chukwa等;各类数字设备主要包括传感器、RFID、GPS等,这些设备记录的数据既有实时的流数据,也有像记录产品交易信息的非实时数据,常用数据流处理系统、模数转换器等来感知和获取数据。
3.2 数据预处理技术
大数据源中既有同构数据也含有大量的异构数据,目标数据常会受到噪声数据的干扰,影响到数据的准确性、完整性和一致性。为提升大数据质量,需要对原始数据进行数据清理、数据集成、数据规约与数据转换等预处理工作。
大数据清理是通过设置一些过滤器,对原始数据进行“去噪”和“去脏”处理。常用到的技术有数据一致性检测技术、脏数据识别技术、数据过滤技术、噪声识别与平滑处理技术等。
大数据集成是指把来自不同数据源、不同格式的数据通过技术处理,在逻辑上或物理上进行集中,形成统一的数据集或数据库。常用到的技术包括数据源识别技术、中间件技术、数据仓库技术等。
大数据规约是在不影响数据准确性的前提下,运用压缩和分类分层的策略对数据进行集约式处理。常用到的技术有维规约技术、数值规约技术、数据压缩技术、数据抽样技术等。
大数据转换是将数据从一种表示形式转换成另一种表示形式,目的是使数据形式趋于一致。常用到的技术有基于规则或元数据的转换技术、基于模型和学习的转换技术等。
3.3 数据存储与管理技术
目前,除了传统关系型数据库外,大数据存储和管理形式主要有3类:分布式文件系统、非关系型数据库和数据仓库。
分布式文件系统是由物理上不同分布的网络节点,通过网络通信和数据传输统一提供文件服务与管理的文件系统,它的文件物理上被分散存储在不同的节点上,逻辑上任然是一个完整的文件。常用的分布式文件系统有Hadoop的HDFS、Google的GFS等。
非关系型数据库(Not Only SQL,NoSQL)是为解决大规模数据集合多重数据种类存储难题应运而生的,它的最大特点就是不需要预先定义数据结构,而是在有了数据后根据需要灵活定义。非关系型数据库一般分为4类:键值(Key-Value)存储数据库,主要利用哈希表中的特定键值对来实现数据存储,常见的有Redis、Apache Cassandra等;列存储数据库,是按行排序以数据列为单位进行存储,有利于对数据库进行压缩,减少数据规模,提高存储和数据查询性能,常见的有Sybase IQ、InfiniDB等;文档型数据库,是按封包键值对的方式进行存储,每个“文档”(如XML、HTML、JSON文档等)代表一个数据记录,记录着数据的具体类型和内容,常见的有MongoDB、CouchDB等;图形数据库,是利用图形模型实现数据的存储,主要存储事物与事物之间的相关关系,将这些相关关系所呈现负责的网络关系简单地称为图形数据,常见的有Google Pregel、Neo4J等。
数据仓库建立在已有大量操作型数据库的基础上,通过ETL等技术从已有数据库中抽取转换导出目标数据并进行存储。与操作型数据库不同,数据仓库不参与具体业务数据操作,主要目的是对从操作型数据库中抽取集成的海量数据进行分析处理,并提供高速查询服务。
3.4 数据分析技术
数据分析是大数据处理流程中最为关键的步骤,也是大数据价值生成的核心部分。从对数据信息的获知度上来看,大数据分析可以分为对已知数据信息的分析和对未知数据信息的分析。对已知数据信息的分析一般运用分布式统计分析技术来实现,对未知数据信息的分析一般通过数据挖掘等技术来实现。
大数据统计分析主要利用分布式计算集群和分布式数据库,运用统计学相关知识和算法(如聚类分析、判别分析、差异分析等),对获取的海量已知数据信息进行分析和解释。目前,比较流行的大数据统计分析工具是基于R语言的分布式计算环境(如RHIPE)。
数据挖掘是从海量的数据中通过算法计算,提取隐藏在其中的有用信息的数据分析过程,是统计分析、情报检索、模式识别、机器学习等数据分析方法的综合运用。在大数据领域中,常见数据挖掘方法主要包括聚类分析、分类分析、预测估计、相关分析等。
3.5 数据可视化技术
大数据可视化技术的工作原理,是运用计算机图形学和图像处理技术将数据以图形或图像的方式展示出来,实现对大数据分析结果的形象解释,并能够实现对数据的人机交互处理。大数据可视化关键技术包括:符号表达技术、数据渲染技术、数据交互技术、数据表达模型技术等。
大数据可视化技术与传统数据可视化技术不同。传统数据可视化技术通常是从关系数据库或数据仓库中提取数据(数据类型较为单一)并进行可视化处理,一般不支持实时数据的可视化和交互式的可视化分析。而大数据可视化技术则是从多个数据源提取多种类型数据进行可视化处理,并且支持实时数据的可视化和交互式的可视化分析。常见的可视化处理和管理工具有Tableau Desktop、QlikView、Datawatch、Platfora等。
3.6 数据安全与隐私保护技术
大数据应用在商业、政府决策、军事等领域创造了巨大价值,同时也正是受利益驱使,大数据的安全和隐私保护也正面临着愈来愈严重的威胁。从大数据的关键技术来看,大数据处理的每个阶段几乎都面临着各种各样的安全威胁[29,54],传统的信息安全技术措施很难对大数据进行有效的安全防护[55]。越来越多的人开始重视大数据的安全和隐私保护,并开始着重研究应对安全隐患和保护隐私的技术措施。
保护大数据安全,主要是保证大数据的可用性、完整性、机密性[56]。大数据来源广泛、模态复杂,大量数据来自于不可信的数据源,同时收集到的大数据常常会有字段缺失或数据错误的情况,导致大数据不可用或弱可用以及完整性缺失。解决大数据可用性问题一般通过数据冗余设置,而大数据的完整性问题一般通过数据校验技术和审计策略来解决。对于大数据的机密性,由于数据规模大,传统的数据加密技术会极大地增加开销,因此一般利用访问控制和安全审计技术来保证大数据的安全。
由于监管和法律条款的缺失,大数据在收集和发布等过程中常常会涉及个人或数据拥有者的隐私,导致隐私信息被泄露。目前,除了加强监管和完善立法外,在技术层面研究人员也在不断地探索和突破。文献[57]从密码学的角度综述了大数据隐私保护技术,包括安全审计技术、大数据加密搜索技术、完全同态加密技术。针对大数据背景下个人隐私数据的保护,文献[58]设计了一套个人数据溯源机制,一定程度起到了对个人隐私的保护。文献[59]以云计算为背景,深入研究了基于不经意随机访问存储器的隐私保护、基于对称加密的隐私保护、基于公钥体制的隐私保护、可搜索加密等技术和方法,一定程度反映了大数据的隐私保护研究现状。
4 结 束 语
大数据很“热”,其在当下的价值贡献和未来的应用前景已经引起了各个领域的高度重视并开始付诸实践,但其中也不乏炒作的因素。大数据需要变“冷”,需要人们用平常心冷静地看待、研究和应用;大数据还没有统一的标准,在体系架构和核心技术上需要进一步完善和创新,特别是大数据的安全和隐私保护机制更需要在立法、监管、安全保护、响应处理等方面进行系统化、标准化。大数据被称为科学研究的“第四范式”,是一场新的技术革命。大数据催生了智能时代,促进了机器智能的发展;大数据也势必催生新的战争模式,加速推进武器装备的信息化、智能化。未来战争将是数据驱动型的战争,谁掌握制数据权谁将取得战争的胜利。扎实推进我军的大数据应用与创新,将会使我国的国防实力产生质的飞跃。
References)
[1]2015中国互联网、社交和移动数据报告[EB/OL].(2015-09-21)[2016-04-05].http://tech.163.com/15/0921/10/B41EHHAG00094P40.html.
[2]EMC Digital Universe.The digital universe of opportunities:rich data and the increasing value of the internet of things(executive summary)[EB/OL].(2014-04-05)[2016-04-05].http://www.emc.com/ leadership/digital-universe/ 2014iview/executive-summary.htm.
[3]IDC.New IDC forecast sees worldwide big data technology and services market growing to MYM48.6 billion in 2019,driven by wide adoption across industries[EB/OL].(2015-11-09)[2016-04-05].http://www.idc.com/getdoc.jsp?containerId=prUS40560115.
[4]IDC.中国大数据技术与服务市场2013—2017年预测与分析[EB/OL].(2014-03-05)[2016-04-05].http://www.idc.com.cn/prodserv/detail.jsp?id=NTc3.
[5]LUDLOFF M.IDG IDC’s latest digital data study:a deep dive[EB/OL].(2011-07-08)[2016-04-05].http://blog.Patternbuilders.com/2011/07/08/idcs-latest-digital-data-study-deep-dive.
[6]TechAmerica Foundation’s Federal Big Data Commission.Demystifying big data[R/OL].(2012-10-10)[2016-04-06].http://www.kdnuggets.com/2012/10/techamerica-demystifying-big-data-report.html.
[7]Big data[EB/OL].[2016-04-06].http://baike.baidu.com/link?url=b5lUEoIdzxfvAAzFnhZcO8jFkUyUIIycCg SS1KFH5dsJ vemrma75706H5i3kgUbqhY_uXLxO1Wbh DITM9AKzLEWzhhrt9FEfeHDN0W4qVSm.
[8]ADRIAN M.It’s going mainstream, and it’s your next opportunity [EB/OL].(2011-11-01)[2016-04-06].http://www.teradatamagazine.com/v11n01/Features/Big-Data/.
[9]Big data[EB/OL].[2016-04-06].http://www.gartner.com/it-glossary/big-data.
[10]Big data[EB/OL].[2016-04-06].http://en.wikipedia.org/wiki/Big_data.
[11]VENNILA.S, PRIYADARSHINI J.Scalable privacy preservation in big data a survey[J].Procedia Computer Science,2015,50:369-373.
[12]KSHETRI N.Big data's impact on privacy,security and consumer welfare[J].Telecommunications Policy,2014,38:1134-1145.
[13]DEMCHENKO Y,NGO C, DE LAAT C,et al.Big security for big data:addressing security challenges for the big data infrastructure[C]//Secure Data Management.10thVLDB Workshop,SDM .Cham, Switzerland:Springer International Publishing,2013:76-91.
[14]JIN X L, WAHA B W,CHENG X Q, et al.Significance and challenges of big data research[J].Big Data Research,2015,2(2):59-64.
[15]BEDI P, JINDAL V, GAUTAM A.Beginning with big data simplified[C]//2014 International Conference on Data Mining and Intelligent Computing(ICDMIC).New Jersey:Institute of Electrical and Electronics Engineers Inc,2014:1-7.
[16]ALI-UD-DIN KHAN M, UDDIN M F, GUPTA N.Seven V’s of big data understanding big data to extract value[C]//2014 Zone 1 Conference of the American Society for Engineering Education(ASEE Zone 1).New Jersey:Institute of Electrical and Electronics Engineers Inc,2014:1-4.
[17]孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展, 2013, 50(1):146-169.
[18]Gartner.Gartner’s 2013 hype cycle for emerging technologies maps out evolving relationship between humans and machines[EB/OL].(2013-08-19)[2016-04-10].http://www.gartner.com/newsroom/id/2575515.
[19]Gartner.Gartner’s 2014 hype cycle for emerging technologies maps the journey to digital business[EB/OL].(2014-08-11)[2016-04-10].http://www.gartner.com/newsroom/id/2819918.
[20]Gartner.Gartner’s 2015 hype cycle for emerging technologies identifies the computing innovations that organizations should monitor[EB/OL].(2015-08-18)[2016-04-10].http://www.gartner.com/newsroom/id/3114217.
[21]《大数据发展研究报告》编写组.综合分析 冷静看待 大数据标准化渐行渐近(上)[J].信息技术与标准化,2013(9):12-14.
[22]《大数据发展研究报告》编写组.综合分析 冷静看待 大数据标准化渐行渐近(下)[J].信息技术与标准化,2013(10):17-20.
[23]张群.大数据标准化现状及标准研制[J].信息技术与标准化,2015(7):23-26.
[24]韩晶,王健全.大数据标准化现状及展望[J].信息通信技术,2014(6):38-42.
[25]NIST Big Data Public Working Group (NBD-PWG).NIST big data interoperability framework V1.0[EB/OL].(2015-08-25)[2016-04-10].http://www.nist.gov/itl/bigdata/bigdatainfo.cfm.
[26]ISO/IEC .Systems and software engineering-recommended practice for architectural description of software-intensive systems:IEEE Std 1471-2000 [S].New York:Institute of Electrical and Electronics Engineers, Inc ,2000:1-11.
[27]NIST Big Data Public Working Group (NBD-PWG).NIST big data interoperability framework:volume 5,architectures white paper survey[R/OL].(2015-08-25)[2016-04-10].http://dx.doi.org/10.6028/NIST.SP.1500-5.
[28]NIST Big Data Public Working Group (NBD-PWG).NIST big data interoperability framework:volume 6,reference architecture[R/OL].(2015-08-25)[2016-04-10].http://dx.doi.org/10.6028/NIST.SP.1500-6.
[29]全国信息技术标准化技术委员会大数据标准工作组.大数据标准化白皮书(2016版)[R].北京:中国电子技术标准化研究院,2016:1-97.
[30]WHITE T.Hadoop权威指南 [M].曾大聃,周傲英,译.北京:清华大学出版社,2010:13-14.
[31]董西成.Hadoop技术内幕:深入解析MapReduce架构设计与实现原理[M].北京:机械工业出版社,2013:33-37.
[32]费仕忆.Hadoop大数据平台与传统数据仓库的协作研究[D].上海:东华大学,2014:4-8.
[33]高蓟超.Hadoop平台存储策略的研究与优化[D].北京:北京交通大学,2012:2-13.
[34]曹风兵.基于Hadoop的云计算模型研究与应用[D].重庆:重庆大学,2011:15-28.
[35]李韧.基于Hadoop的大规模语义Web本体数据查询与推理关键技术研究[D].重庆:重庆大学,2013:14-17.
[36]杨宸铸.基于HADOOP的数据挖掘研究[D].重庆:重庆大学,2010:5-19.
[37]潘阳.基于Hadoop技术在分布式数据存储中的应用研究[D].大连:大连海事大学,2014:8-27.
[38]李娇龙.基于Hadoop 的云计算应用研究[D].成都:电子科技大学,2014:13-26.
[39]JAIN A,NALYA A.Learning storm[M].Birmingham:Packt Publishing,2014:19-24.
[40]ESKANDARI L, HUANG Z Y, EYERS D.P-scheduler:adaptive hierarchical scheduling in apache storm [C]//Australasian Computer Science Week(ACSW) ’16 Multiconference.Canberra,Australia:ACM,2016:1-3.
[41]陈敏敏,王新春,黄奉线.Storm技术内幕与大数据实践[M].北京:人民邮电出版社,2015:2-95.
[42]龙少杭.基于Storm的实时大数据分析系统的研究与实现[D].上海:上海交通大学,2015:18-22.
[43]邓立龙,徐海水.Storm 实现的应用模型研究[J].广东工业大学学报,2014,31(3):114-115.
[44]李川,鄂海红,宋美娜.基于Storm 的实时计算框架的研究与应用[J].软件,2014,35(10):17-18.
[45]KARAU H, KONWINSKI A, WENDELL P, et al.Learning spark[M].Sebastopol:O’Reilly Media,2015:1-7.
[46]李文栋.基于Spark的大数据挖掘技术的研究与实现[D].济南:山东大学,2015:8-12.
[47]孙科.基于Spark的机器学习应用框架研究与实现[D].上海:上海交通大学,2015:20-22.
[48]胡俊,胡贤德,程家兴.基于Spark 的大数据混合计算模型[J].计算机系统应用,2015,24(4):214-217.
[49]胡于响.基于Spark的推荐系统的设计与实现[D].杭州:浙江大学,2015:6-9.
[50]邱荣财.基于Spark平台的CURE算法并行化设计与应用[D].广州:华南理工大学,2014:7-14.
[51]方艾,徐雄,梁冰,等.主流大数据处理开源架构的分析及对比评测[J].电信科学,2015,(7):2-5.
[52]LI G J,CHENG X Q.Research status and scientific thinking of big data[J].Bulletin of Chinese Academy of Sciences,2012,27(6):647-657.
[53]MAYER-SCHONBERGER V, CUKIER K.大数据时代[M].盛扬燕,周涛,译.杭州:浙江人民出版社,2013:193-232.
[54]TeraData.The threat beneath the surface:big data ana-lytics,big security and real-time cyber threat response for federal agencies[R].California:TeraData,2012:1-35.
[55]孟小峰,张啸剑.大数据隐私管理[J].计算机研究与发展,2015,52(2):265-281.
[56]何小东,陈伟宏,彭智朝.网络安全概论[M].北京:清华大学出版社,2014:272-278.
[57]黄刘生,田苗苗,黄河.大数据隐私保护密码技术研究综述[J].软件学报,2015, 26(4):945-953.
[58]王忠,殷建立.大数据环境下个人数据隐私泄露溯源机制设计[J].中国流通经济,2014(8):117-120.
[59]肖人毅.云计算中数据隐私保护研究进展[J].通信学报,2014,35(12):168-174.
(编辑:李江涛)
Big Data and Its Architecture and Key Technologies
LYU Denglong1, ZHU Shibing2
(1. Department of Graduate Management, Equipment Academy, Beijing 101416, China;2. Department of Information Equipment, Equipment Academy, Beijing 101416, China)
This paper introduces the status, research activities and application perspectives of big data. In order to solve the problems like inconsistent standards for big data and different views among researchers, the paper redefines the big data in a new aspect by comparative analysis; especially in the respect of security, the paper analyzes and summarizes the "6V" feature of the big data; starting from the standardization of big data, this paper further analyzes existing research results, concludes the architecture of big data and generic technology in application, analyzes the connotation of various technologies and presents the architecture and key technologies of big data systematically.
big data; architecture; key technologies
2016-09-20
吕登龙(1983—),男,讲师,博士研究生,主要研究方向为信息网络与安全。 朱诗兵,男,教授,博士生导师。
TP311
2095-3828(2017)01-0086-11
A DOI 10.3783/j.issn.2095-3828.2017.01.017
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18 07:31:10
汽车工程(2021年12期)2021-03-08 02:34:30
时代人物(2019年27期)2019-10-23 06:12:20
计算机测量与控制(2017年6期)2017-07-01 16:24:11
电信科学(2017年6期)2017-07-01 15:45:17
油画艺术(2017年1期)2017-05-20 09:09:42
电信科学(2016年11期)2016-11-23 05:07:58
电测与仪表(2015年22期)2015-04-09 11:42:18
现代教育技术(2015年1期)2015-02-26 08:47:40
电测与仪表(2014年1期)2014-04-04 12:00:32
