
基于层次拓扑树的虚拟机节能分配算法
2017-03-17 19:15蔡立军何庭钦孟涛陈磊
湖南大学学报·自然科学版 2017年2期
关键词:数据中心
蔡立军+何庭钦+孟涛+陈磊

摘 要:为了均衡分布式数据中心物理主机多维资源的利用率,减少物理主机使用数量,节约能耗,提出了一种基于层次拓扑树的虚拟机节能分配算法HTES(hierarchical topology energy saving),此算法可以有效提升虚拟机分配效率.利用Laplacian矩阵,对大规模网络拓扑分割,建立了层次拓扑树模型.基于层次拓扑模型,根据虚拟机请求中IP地址与数据中心的距离,将虚拟机请求分组,从层次拓扑树模型中查詢合适的物理主机区域,按虚拟机请求与物理主机的资源匹配度进行虚拟机的分配.将HTES与其他3种算法进行模拟仿真实验,从虚拟机分配时间、资源均衡率、能耗和物理主机使用情况等方面验证了HTES算法能够有效加快物理主机搜索速度,增加底层占用物理主机的集中度,降低底层物理主机的使用数量,达到节约能耗的目的.
关键词:数据中心;虚拟机分配;层次拓扑树;能源利用率
中图分类号:TP391 文献标志码:A
Energy Saving Allocation Algorithm
of a Virtual Machine Based on Hierarchical Topology Tree
CAI Lijun1,HE Tingqin1,MENG Tao1,CHEN Lei2
( 1. College of Information Science and Engineering,Hunan University,Changsha 410082,China;
2. College of Electrical and Information Engineering, Hunan University,Changsha 410082,China)
Abstract:In order to balance the utilization of multi-dimensional physical host resources and reduce usage number, a virtual machine allocation energy saving algorithm was proposed based on hierarchical topology tree (HTES) in the environments of distributed data center, which enhances allocation efficiency of the virtual machines. Laplacian matrix was then used to split large-scale network topology and to build hierarchical topology tree model. Furthermore, according to the distance between request IP address and the data center, HTES divided the virtual machines into groups, and searched the appropriate physical host region from hierarchical topology tree for allocation, which is based on the match degree between virtual machine requests and physical hosts. Simulation experiments were performed on HTES algorithms and other three algorithms, considering the virtual machine allocation time, resource balancing rate, energy consumption and physical host usage, and other aspects. The results shows that the HTES is able to balance multi-dimensional resources physical hosts, reduce physical host usage, and save energy consumption.
Key words:data centers;virtual machine allocation;hierarchical topology tree;energy utilization
随着信息科技的不断发展,数据中心作为一种基础设施,已经被各行各业普遍使用.然而当前数据中心的发展也面临新的问题,数据中心的规模不断扩张,地理位置愈趋分散.多个分散的数据中心通过高速网络互联,共同组成了大型的分布式数据中心.在分布式数据中心内,用户通过按需付费的模式,向数据中心提交需求.数据中心根据用户地理位置,从较近的基础设施库分配资源并构建虚拟机为用户服务.然而,大规模分布式数据中心环境的虚拟机的分配问题面临新的挑战,主要表现为主机地理位置更为分散、底层资源规模更为庞大、多维异构资源、较高的能源消耗等.因此,合理的虚拟机(资源)分配策略是数据中心收益的保障,研究虚拟机分配算法具有重要意义.
目前已有很多学者对数据中心虚拟机的分配进行研究,取得了较多的优秀成果.一些研究成果集中在优化分布式数据中心的资源分配上[1-6].文献[1]从服务供应商的角度,研究了分布式数据中心的收益最大化问题,提出了一种结合虚拟机分配的动态调价算法.文献[2-3]同样着眼于分布式数据中心的成本优化问题,从数据传输和资源分配两个角度设计了相应的数据管理系统和资源调度算法,最小化数据、成本低的同时,优化了数据的传输时间、提升了底层物理资源的利用率.文献[4]提出了一种基于温度感知的资源管理系统,通过动态调整服务器的功率,实现虚拟机分配和服务器负载间的优化.文献[5]在分布式数据中心内,对虚拟机的分配请求建立G/G/1/PS队列,通过优化队列处理实现服务器负载和虚拟机分配的均衡,节约了数据中心能耗.文献[6]为提升高性能数据中心资源使用率,设计了CAE集成平台架构,实现了一种基于Web方式的高性能计算中心资源的解决方案.有些研究工作使用数据中心网络拓扑来优化虚拟机的分配,提升底层物理资源的利用率[7-10].在portland网络拓扑上,文献[7]提出了2种启发式算法,通过分配虚拟机到最大链路能力和邻近的物理主机上,降低了网络开销,增加了底层资源利用率.文献[8]根据网络拓扑建立了MNT指标,优化资源分配.文献[9]在网络拓扑的基础上,通过虚拟机和链路的合并,增加了拓扑中空闲网络设备数量,节约了能源.同样,在实际数据中心拓扑上,文献[10]通过对带宽过载的虚拟机进行合并,优化了网络传输消耗.此外,还有较多学者研究数据中心的能耗问题[11-14],通过各种模型和方法减少数据中心的能源消耗.文献[11]同时考虑了虚拟机的分配和网络流的传输,通过建立线性规划模型,并行处理虚拟机的分配,节约能源消耗.文献[12]中将虚拟机的分配问题看做多商品流的成本最小化问题,通过Benders分解算法进行求解,减少了底层物理主机的使用数量,节约了能源消耗.文献[15]分析了云数据中心下资源分配和能源消耗问题,设计了一种节能框架,在减少成本的同时节约能耗.文献[16]研究了分布式数据中心内的能源节约问题,建立了最大化整数规划模型,通过虚拟机的合并,减少了物理主机的使用,从而实现能耗的节约.
以上的研究工作在处理大规模非树型随机网络拓扑[17]的虚拟机分配问题上,无法有效减少数据中心物理主机的使用数量,仍面临能耗较高的缺陷.网络拓扑的大规模性和随机性导致虚拟机分配时扫描的物理主机范围更为庞大,使用传统的算法效率较低,一方面表现在底层物理主机的搜索时间过长,降低了虚拟机的分配效率;另一方面底层物理主机分配后集中度较低,过高的分散性不利于物理主机的管理和维护.如DCEERS算法[18]通过Benders分解进行虚拟机分配,利用最小数量的物理主机承载虚拟机请求,虽然减少了物理主机的数量,在一定程度上降低了能耗,但并未考虑资源的均衡率,可能引起局部负载及单位时间功耗过大;ANT算法[19]利用蚁群策略求解多目标虚拟机的分配问题,但却需要大量的迭代寻找最优,分配时间上较差.
因此,本文提出了一种基于层次拓撲树的虚拟机节能分配算法.首先,将分布式数据中心的大规模网络随机拓扑进行拓扑分割,建立层次拓扑树.其次,在考虑底层物理主机多维资源均衡的前提下,扫描层次拓扑树,将虚拟机集中分配网络拓扑中的集中区域,降低底层物理主机的使用.通过关闭空闲物理主机达到节约能源的目的.最后,通过大量实验验证了算法的性能.基于层次拓扑树的虚拟机节能分配算法优化了虚拟机的分配,提高了底层资源利用率,降低了能源消耗.
1 模型建立
1.1 预备知识
1.1.1 分布式数据中心网络拓扑
网络拓扑是数据中心整体结构的一种表示和体现.数据中心所有物理主机、存储设备、网络设备通过网络链路彼此互连,共同组成网络拓扑.通常情况下,网络拓扑用图G=V,E表示.其中,V为节点集合,表示数据中心内所有的物理设备;E为边的集合,表示两两物理设备间的网络链路能力,即网络带宽.
在虚拟机的分配过程中,网络拓扑起着重要的作用.所有的虚拟机必须映射到网络拓扑中的物理主机上,占用物理主机的CPU,MEM资源,占用网络拓扑中多个物理主机间的链路带宽资源,甚至占用拓扑中存储节点的部分存储资源.一个虚拟机在分配过程中,需要扫描网络拓扑中的空闲物理主机,进行最终的资源分配.网络拓扑可以轻松反映虚拟机的分配情况和运行情况,能够方便监控物理主机的负载和运行,便于物理主机的资源调优和能源节约.当网络拓扑发生变化时,说明底层物理设备出现了故障,需要进行虚拟机的迁移和重新分配.
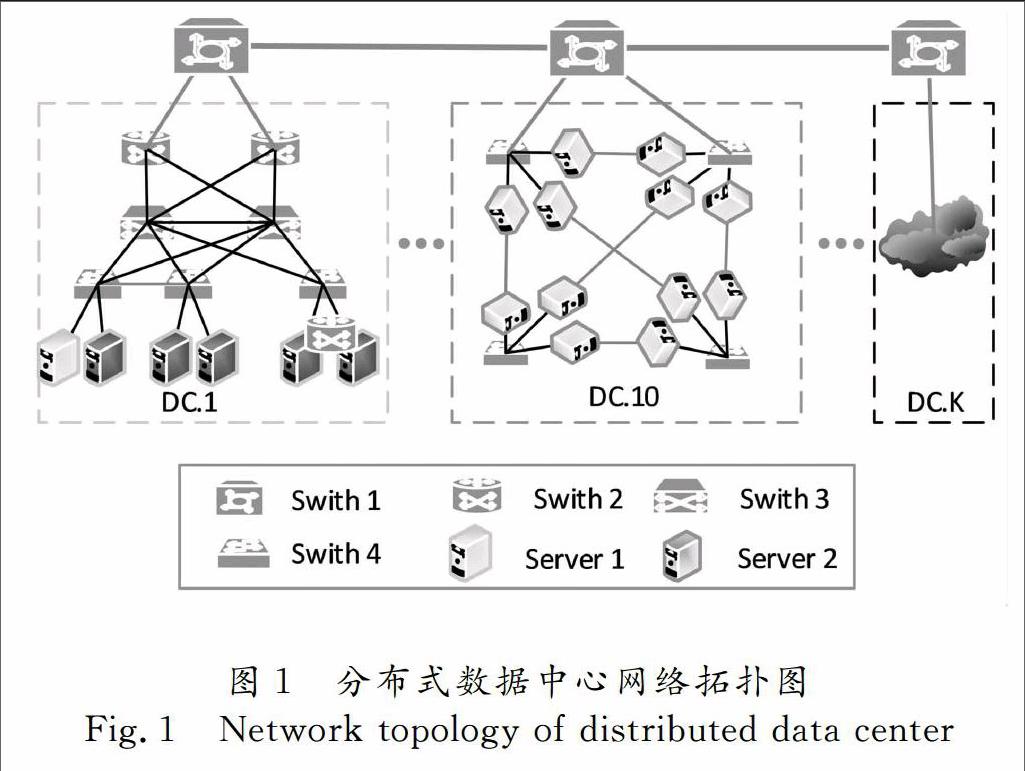
分布式数据中心由多个地理位置分散的小型数据中心组成.小型数据中心之间通过高速网络进行互连.每个小型数据中心彼此独立,可以拥有不同类型的网络拓扑和物理主机.通常,分布式数据中心的整体网络拓扑是随机的,底层物理主机资源是异构的.图1为分布式数据中心网络拓扑图.
在图1中,分布式数据中心由K个小型数据中心组成.每个数据中心拥有不同的网络拓扑和物理主机类型.分布式数据中心的网络拓扑呈现随机性和大规模性,物理主机拥有异构特性.网络拓扑的大规模性和随机性导致虚拟机分配时扫描的物理主机范围庞大,增加了虚拟机的搜索时间,降低了虚拟机的分配效率.此外,网络拓扑的大规模性必然存在大量物理主机和网络设备空闲的情况,带来庞大的能源开销,增加数据中心的成本;物理主机的异构性增加了虚拟机分配后物理主机多维资源间的不均衡分配,造成资源浪费;数据中心的分散性增加了额外的网络开销,浪费了网络带宽资源.
1.1.2 单机多维资源的不均衡分配
在数据中心网络拓扑中,物理主机本身由多种资源组成(CPU,MEM和存储),可看作多维资源向量.如果某维资源(CPU)过度分配,必然造成其他维资源(MEM和存储)的浪费.只有均衡利用各维资源,才能更充分地发挥资源效率,提升底层资源的利用率,减少数据中心物理主机的使用数量,降低能源开销.在传统虚拟机分配过程中,虚拟机的随机分配往往导致单机多维资源的不均衡分配.
图2(a)为单机多维物理资源的不合理分配情况.由图2(a)可知,仅考虑了CPU和MEM两维资源,3个虚拟机分配到了物理主机上,造成了物理主机CPU资源的利用率达到了90%(40%+20%+30%).然而,物理主机的内存资源才使用25%(15%+8%+2%).当新的虚拟机访问物理主机时,虽然剩余较多的内存资源,但是由于CPU资源的高利用率,导致物理主机无法承载新的虚拟机,从而造成了内存资源的大量浪费,出现单机多维资源的不均衡分配.图2(b)中,描述了物理主机的均衡分配情况.同样是3个虚拟机,但是物理主机的CPU和MEM资源利用率相对均衡,都达到了90%,不会出现单维资源的空闲浪费,能够更加充分地利用底层资源.
单机多维资源的均衡分配能够提升底层物理资源的利用率,降低数据中心成本.此外,多维资源的均衡分配,可以在一定程度上减少底层物理主机的使用数量,达到降低数据中心能耗的目的.
1.2 问题描述
分布式数据中心内虚拟机的调度过程可描述为:位置各异的多个用户向数据中心提交一批虚拟机请求Vms={vm1,vm2,…}.每个虚拟机拥有4种属性,用vmi={req_cpui,req_memi,req_bwi,ipi,lifetimei}表示,其中req_cpui,req_memi,req_bwi分别表示CPU,MEM和带宽请求大小,ipi表示用户的地理位置信息,lifetimei表示当前虚拟机的生命周期.分布式数据中心由网络拓扑图G=V,E表示.其中,V为物理资源的集合,E为物理资源间网络链路带宽的集合.在分布式数据中心内,用户提交的虚拟机请求将根据用户位置分配到较近的物理主机上,占用物理主机资源和网络带宽.每个物理主机hostj={cab_cpuj,cab_memj,cab_bwj,DC}拥有3种资源CPU,MEM和带宽.DC(Data Center)是物理主机所属子数据中心的标识,代表物理主机的位置信息.
在虚拟机的分配过程中,每个虚拟机vmi只能分配到一台物理主机上hostj.物理主机hostj的剩余资源能力必须满足虚拟机的请求.一个用户可以提交多个虚拟机请求,同一用户的多个虚拟机应该分配在同一地理位置的物理主机上.此外,分布式数据中心内,多个数据中心的物理主机通常为异构主机,拥有不同的CPU,MEM大小.在分布式数据中心网络拓扑中,所有网络设备和存储设备不能独立承载虚拟机,不具备相应的计算和处理能力.
1.3 分配模型
根据分布式数据中心的虚拟机分配过程描述,本文的虚拟机分配目标是:均衡物理主机多维资源的分配,减少底层物理主机的使用数量,提升底层资源的利用率,节约数据中心的能源消耗.
分布式数据中心内,虚拟机的分配过程是连续的,分配过程不断循环,一次分配过程完成后另一次分配过程准备开始.在多次虚拟机分配过程中,物理主机负载状态前后一致.单个物理主机可以在不同轮次的分配过程中承载多个虚拟机请求.为了均衡单个物理主机多维资源的均衡分配,必须在物理主机历史负载状态下考虑本轮分配,实现虚拟机分配后物理主机各维资源的剩余率均衡.
为了更好地描述物理主机多维资源的均衡情况,文中定义了请求匹配度HMatch的概念,描述当前虚拟机分配到物理主机后各维资源的使用情况.
1, (sur_cpu 公式(1)描述了虚拟机vmi分配到物理主机hostj后,物理主机剩余资源的均衡程度.其中,req_cpui,req_memi表示虚拟机vmi对CPU和MEM资源的请求大小.sur_cpuj,sur_memj表示物理主机hostj经过多轮虚拟机分配后剩余的CPU和MEM资源大小.cab_cpuj,cab_memj表示物理主机hostj的原始CPU和MEM资源大小.本文仅考虑物理主机的CPU和MEM资源的分配均衡程度,暂未考虑存储和I/O等资源. 此外,从式(1)可知,请求匹配度0≤HMatchij<2.当虚拟机vmi分配到物理主机hostj后,CPU和MEM的剩余资源占总资源的比值相同,则匹配度为0.否则,匹配度值大于0.剩余资源间越均衡,则匹配度值越小.通过匹配度的计算,可以快速获取虚拟机分配对物理主机资源使用的影响,越小的资源匹配度,则说明物理主机资源的利用率越高,越能减少底层物理主机的数量,实现节约能耗的目的. 在式(2)中,Is_Newj描述了物理主机是否在历史分配过程中承载了虚拟机.若当前物理主机是空闲物理主机,为承载任何虚拟机,则主机的剩余CPU和MEM能力与总资源能力相同.否则,剩余能力小于总资源能力.为了限制虚拟机随意分配到新的空闲虚拟机,本文用整数1和2来分别描述当前物理主机的状态. 在虚拟机分配过程中,虚拟机请求数量与底层物理主机数量不同,本文定义0-1变量xij表示虚拟机vmi与物理主机hostj间的映射关系,见式(3). xij=1 , vmi is maped to hostj 0 ,vmi is not maped to hostj(3) 在式(3)中,虚拟机vmi分配到物理主机hostj上,则xij为1;否则,xij为0.因此,分布式数据中心虚拟机分配的目标函数可以表示如下: min ∑j∈Hosts∑i∈Vmsxij×HMatchij (4) st. for each vmi: ∑j∈Hostsxij≤1 for each hostj: ∑i∈Vmsxij×req_cpui≤cab_cpuj ∑i∈Vmsxij×req_memi≤cab_memj∑i∈Vmsxij×req_bwi≤cab_bwj for each vmi , hostj: 0≤HMatchij<2 在式(4)中,最小的物理主机匹配度表示所有虚拟机分配到物理主机后,物理主机剩余资源的均衡性最好,则其可以承载的虚拟机数量就越多,分配过程中使用的物理主机数量将减少,此外,当已使用的物理主机分配完之后,再将虚拟机分配到其他的空闲物理主机上,从而节约了数据中心能耗.表1为分布式数据中心虚拟机分配过程中的符号及相关术语. 2 基于层次拓扑树的节能分配算法 针对分布式数据中心的网络拓扑特点,结合分配模型,本节提出了一种基于层次拓扑树的虚拟机节能分配算法,简称HTES.首先,HTES将分布式数据中心的大规模网络拓扑进行分配,建立了层次拓扑树,详细描述见2.1节;其次,在层次拓扑树的基础上,根据用户的地理位置,将虚拟机分配到网络拓扑中的某个区域,保证占用的物理主机相对集中,均衡物理主机多维资源分配,减少物理主机使用数量,节约能耗,详细的分配算法见2.2节. 2.1 拓扑分割建立层次拓扑树 分布式数据中心由多个地理位置分散的小型数据中心组成,整个网络拓扑具有明显的大规模性和随机性.在虚拟机的分配过程中,需要为每个虚拟机寻找合适的物理主机,从而必须搜索网络拓扑的所有物理主机.网络拓扑的大规模给虚拟机的分配过程带来了两个难点:①增加了底层物理主机的搜索时间,降低了虚拟机的分配效率.②扩散了底层物理主机的占用分布.例如,同一用户的多个虚拟机请求可能分配到不同地理位置的物理主机上,也可能分配到同一地理位置内的距离位置较远的多台物理主机上.这种分散性给底层物理主机的管理和维护带来了巨大困难,增加了节能策略的监控难度. 针对以上两个难点,本文对分布式数据中心的网络拓扑进行逐级分割,建立层次拓撲树.将整个拓扑转化为层次结构,保证每一层的节点数目逐层递减.当进行虚拟机分配时,根据虚拟机的分配数量,找到相应层级的拓扑子树寻找物理主机,不用再扫描整个网络拓扑,减少了物理主机的扫描时间,增加了虚拟机占用物理主机的集中度,便于虚拟机的快速分配和能耗节约. 为了进行网络拓扑的分割,本文引入了规范割Normalized-cut(Ncut)和Laplacian矩阵,证明了Laplacian矩阵的第二特征值是2分Ncut的最优解. 定义1 规范割Normalized-cut(Ncut)是衡量网络拓扑中两个节点子集间相似度的标准,公式如下:
NcutA,=cut(A,)vol(A,V)+cut(A,)vol(,V)
A∈V and ∈V(5)
cut(A,)=∑i∈A,j∈wij (6)
vol(A,V)=∑i∈A,j∈Vwij (7)
式中:V为网络拓扑G中的节点集合;wij为网络拓扑的邻接矩阵W中的值,表示節点i与节点j间的权值.邻接矩阵W为对称矩阵,其中wij=wji0.使用规范割Ncut进行拓扑分割度量,能够较好地避免小区域的产生.
定义2 Laplacian 矩阵是网络拓扑图的一种有效表示方式,一个Laplacian矩阵对应一个非负权重的无向有权图.Laplacian矩阵的常用表示如下:
Lsym=D-1/2LD-1/2=I-D-1/2WD-1/2(8)
式中:I为单位矩阵;D为网络拓扑中节点的度矩阵;W为邻接矩阵.每个节点的度di=∑njwij,表示与该节点相连的所有边的权值和.
Laplacian矩阵具有如下特性:
1)任意n维向量f∈R,有:fΤLf=12∑ni,j=1wij×(fi-fj)2.
2)L为半正定矩阵.
3)L的最小特征值为0,对应的最小特征向量为值1的常向量A.
4)L有n个非负实特征值0=λ1≤λ2≤…≤λn.
5)如果网络拓扑G是C的连通部件,那么L有C个等于0的特征值.
根据Ncut和Laplacian矩阵的定义和性质,可得Laplacian矩阵的第二特征值是2分Ncut的最优解,证明过程如下:
证明 设划分向量f如下:
f(vi)=vol(,V)vol(A,V) , if vi∈A -vol(A,V)vol(,V) , if vi∈
根据L的性质1 ,得
fTLf=12∑ni,j=1wij(fi-fj)2=
12∑i∈A,j∈wij(fi-fj)2+12∑i∈A,j∈Awij(fi-fj)2+
12∑i∈,j∈Awij(fi-fj)2+12∑i∈,j∈wij(fi-fj)2=
12∑i∈A,j∈wij(fi-fj)2+12∑i∈,j∈Awij(fi-fj)2=
12cut(A,)vol(,V)vol(A,V) +vol(A,V)vol(,V) 2+
12cut(A,)-vol(,V)vol(A,V) -vol(A,V)vol(,V) 2=
cut(A,)vol(V,V)vol(A,V)+vol(V,V)vol(,V)=
vol(V,V)Ncut(A,)
此外:
fTDf=∑i∈Avol(,V)vol(A,V)divol(,V)vol(A,V)+
∑i∈-vol(A,V)vol(,V)di-vol(A,V)vol(,V)=
vol(,V)vol(A,V)∑i∈Adi+vol(A,V)vol(,V)∑i∈di=
vol(,V)vol(A,V)vol(A,V)+vol(A,V)vol(,V)vol(,V)=
vol(V,V)
将上述两式结合,可得:NcutA,=fTLffTDf
根据L的性质3,可得:
DfTA=∑ni=1difi=∑i∈Adivol(,V)vol(A,V)-
∑i∈divol(A,V)vol(,V)=
vol(A,V)vol(,V)vol(A,V)-
vol(,V)vol(A,V)vol(,V)=
vol(A,V)vol(,v)-
vol(,v)vol(A,V)=0
因此,Ncut的最小化:min f fTLffTDf
st.
fi∈vol(,V)vol(A,V),-vol(A,V)vol(,V)
DfTA=0
由于最小化的Ncut是一个广义Rayleigh商,根据性质可得λ1=0,D1/2A为其最小特征值,可得fTLf/fTDf的第二小特征值是Ncut的最优解.
根据Laplacian矩阵与Ncut间的特性,本文将分布式数据中心的网络拓扑转化为Laplacian矩阵,然后对其求第二特征值,从而将网络拓扑分割成耦合度最小的两个子集.再依次对两个子集进行拓扑分割,最终形成层次拓扑树.图3为网络拓扑分割的过程.
从图中可以看出,网络拓扑的分割过程为2分迭代分割,通过多次迭代将网络拓扑分割成2个子拓扑.在整个分割过程中,必须保持多个数据中心间地位位置的分散特性.因此,分布式数据中心的层次拓扑树的第一层拓扑树就是多个地理位置分散数据中心拓扑,不进行过细的划分.此外,拓扑分割的目标是加快物理主机的搜索速度,减少分配时间,2分迭代分割必然出现最下层子拓扑中节点数量较少的情况.为此,本文设定了拓扑分割门限SplT和拓扑合并门限MerT.根据拓扑分割门限SplT判断是否继续进行网络拓扑的分割.根据拓扑合并门限进行节点数小于MerT的子拓扑的合并.因此,拓扑分割门限SplT必须大于拓扑合并门限MerT.
因此,分布式数据中心网络拓扑分割的具体过程如下:①根据分布式数据中心内小型数据中心的网络拓扑,建立第1层子拓扑集,保持分布式数据中心网络拓扑间地理位置的分散特性;②逐个遍历第1层子拓扑集,形成L矩阵,根据公式(8)进行第二特征值求解.根据求解结果计算相应的特征向量.按照特征向量中得到的节点列表,将网络拓扑分割成两个子拓扑;③逐层遍历所有子拓扑,生成下一层子拓扑集.当某个子拓扑中的节点数量少于最低分割门限SplT,不再进行下一层拓扑分割;④当所有拓扑分割完成后,遍历最后一层的子拓扑集,将节点数少于MerT的子拓扑与其兄弟节点进行合并;⑤遍历所有层的子拓扑,统计每层子拓扑中节点数量的范围,结合层次号和地理位置(IP),建立索引方便查询.算法1详细描述了网络拓扑分割建立拓扑树的详细过程.
算法1 网络拓扑分割过程
输入:网络拓扑G,拓扑分割门限值SplT,拓扑合并门限值MerT.
输出:层次拓扑树TT.
Step1 初始化.
1)根据网络拓扑G,生成相应的邻接矩阵W和度矩阵D.
2)初始化待分割的网络拓扑集TS和子拓扑集STS為空.
3)初始化层次拓扑树TT为空,层次序号IN为0.
4)根据网络拓扑G和多个数据中心的地理位置分散关系,生成第1层子拓扑集,填充到STS,计算总节点数量VN.更新层次拓扑树的顶层索引,包括层次序号、节点总数、子拓扑集合链接等,如下所示.更新完成后进入Step2,开始拓扑分割.insert 〈IN,VN,TS〉 to TTIN.
Step2 更新待分割拓扑集,将STS覆盖TS,清空STS.更新当前层次拓扑树的层号IN=IN+1.进入Step3开始拓扑分割.
Step3 判断TS是否为空.TS为空,则进入Step5合并节点数目过小的子拓扑.否则,进入Step4,分割拓扑.
Step4 遍历待分割拓扑集TS,生成子拓扑集STS.
1)计算子拓扑中节点数量VN.比较VN与分割门限SplT的大小.若大于,进入2)进行拓扑分割.若小于,则不进行拓扑分割.进行下一个子拓扑的计算.如果TS遍历完成,进入Step2更新待分割拓扑集.
2)根据子拓扑G、邻接矩阵W和度矩阵D,按照公式(8)生成L矩阵Lsym=I-D-1/2WD-1/2,其中I是单位矩阵.进入3)计算第二特征值.
3)根据L矩阵特性,计算(D-W)x=λDx的第二小特征值.根据特征值求得想要的特征向量f.按照特性向量中的节点,将子拓扑分割成两个子集,加入STS中.进入4)更新层次拓扑树.
4)计算中STS总节点数量VN,更新层次拓扑树,如下所示.更新完成后重新进行1),分割下一个子拓扑.
insert 〈IN,VN,TS〉 to TTIN.
Step5 遍历IN层子拓扑,判断每个子拓扑中节点数量.若节点数量小于MerT,删除当前子拓扑集和同一父节点的兄弟拓扑集.
2.2 区域性节能分配算法
根据分布式数据中心的网络拓扑特性,在构建层次拓扑树的基础上,本节提出了一种区域性虚拟机节能分配算法HTES.HTES的核心节能策略是减少底层物理主机的使用,通过关闭空闲物理主机实现节能.较传统的相同策略节能算法[12]而言,HTES关注于分布式数据中心环境;根据用户IP分组虚拟机请求,就近提供物理主机资源;分割网络拓扑建立层次拓扑树,快速寻找合适的物理主机;区域性分配虚拟机到底层集中的物理主机上,缓解了传统零散分配带来的难管理、难节能、难纠错等缺点;考虑物理主机多维资源的均衡分配,提高底层物理主机的资源利用率.
本文采用区域性分配,将虚拟机分配到底层集中的物理主机上,缓解了物理主机分散带来的节能和管理困难.区域性虚拟机节能算法的主要流程分为:虚拟机请求分组,物理主机搜索和区域性虚拟机均衡分配3个步骤.
虚拟机请求分组:①请求分组,根据虚拟机请求中IP地址属性,按照层次拓扑中顶层节点的地理位置(IP),将虚拟机请求进行分组.分组完成后,所有虚拟机请求都在距离自己最近的数据中心队列中.②并发分配,并发对多个虚拟机请求分组进行相应的物理资源分配.
区域性物理主机搜索:①锁定搜索层次.根据分组完成后的虚拟机请求个数V_size,查询拓扑层次树中空闲节点数量(物理主机)充足的子拓扑,保证子拓扑的空闲数量大于虚拟机请求数量α倍,更加均衡地分配虚拟机,均衡物理主机的多维资源.②比较资源能力.比较虚拟机请求大小与空闲物理主机的剩余能力,选择剩余能力大于请求大小的物理主机.若物理主机搜索成功,数量等于α×V_size,则进行虚拟机分配.否则,遍历当前子拓扑的父亲拓扑,再次搜索合适数量的主机,直到找到α×V_size个物理主机为止.③请求迁移.如果当前顶层拓扑内所有空闲物理主机数量小于V_size,则分配相应数量的虚拟机请求,并将多余的虚拟机请求移动到邻近的数据中心队列中,等待分配.如果邻近数据中心内资源同样不足,则继续迁移到其他数据中心.如果整个网络拓扑资源不足,则返回最近数据中心等待其他虚拟机释放资源.
均衡分配:根据虚拟机请求队列和相应的物理主机队列,进行虚拟机的最终分配.按照公式(1)的定义,将虚拟机分配到请求匹配度最好的物理主机上,完成分配过程.
图4展示了基于层次拓扑树的虚拟机节能分配算法过程.从图中可以看出,虚拟机的分配过程主要分为虚拟机请求分组、根据层次拓扑树搜索物理主机和虚拟机分配3个步骤.分布式数据中心由2个地理位置分散的小型数据中心A和B组成.4个用户在不同的位置向数据中心提交了7个虚拟机请求.根据用户IP和物理中心的位置,V1-V4虚拟机请求分配到了A,V5-V7分配到了B.根据虚拟机请求的数量,并发从A和B中寻找合适数量的子拓扑,进行虚拟机的分配,正如V1,V3-V7所示.然而,当子拓扑的可用物理主机数量小于虚拟机请求数量时,从其父节点的拓扑中寻找其他物理主机进行分配,如V2所示.在整个虚拟机的分配过程中,根据虚拟机请求与物理主机的匹配度公式(1),进行物理主机的分配.如图中V1,V3,V4分配到了原拓扑的物理主机,V2因其匹配度较差从而分配到了原拓扑的父节点.整个节能分配算法HTES的分配过程如算法2所示.
算法2 基于层次拓扑树的虚拟机节能分配算法
输入:网络拓扑G,虚拟机请求列表Vms
输出:虚拟机分配结果.
Step1 初始化.根据网络拓扑G,利用算法1生成层次拓扑树TT,监控数据中心所有物理主机的使用情况.
Step2 虚拟机请求分组.
1)根据虚拟机的IP和数据中心位置,将虚拟机分配到位置最近的数据中心排队队列中.
2)分配完成后,并发对多个数据中心进行虚拟机的分配.
Step3 区域性搜索物理主机.
1)根据分组完成后的虚拟机请求个数V_size,查询拓扑层次树中空闲节点数量(物理主机)充足的子拓扑,保证子拓扑的空闲数量大于虚拟机请求数量α倍.
2)比较虚拟机请求大小与空闲物理主机的剩余能力,选择剩余能力大于请求大小的物理主机.
3)若物理主机搜素成功,数量等于α×V_size,进入Step5进行虚拟机分配.否则,遍历当前子拓扑的父亲拓扑,再次搜索合适的数量主机,直到找到α×V_size个物理主机为止.
4)当遍历到顶层拓扑,搜索完整个小数据中心的所有物理主机,物理主机数量不满足V_size时,进入Step4进行虚拟机请求的迁移.
Step4 虚拟机请求的迁移.
1)当顶层拓扑内所有空闲物理主机数量小于V_size,则分配空闲主机数量的虚拟机请求,并将多余的虚拟机请求迁移到邻近的数据中心队列中,等待分配.
2)如果整个网络拓扑资源不足,则返回最近数据中心等待其他虛拟机释放资源.
Step5 均衡分配虚拟机.按照公式(1)的定义,根据请求匹配度的大小,将虚拟机分配到最好的物理主机上,均衡物理主机的多维资源,完成分配过程.
3 实验结果分析
为了验证HTES算法的性能,本文使用CloudSim3.5[17]作为仿真平台,将HTES算法与贪婪算法GRD[18],蚁群算法ANT[19]和DCEERS[12]算法进行比较,从分配时间、物理主机数量、物理主机异构使用情况等方面进行了性能验证.
3.1 实验环境
在CloudSim平台上,利用brite网络拓扑图生成工具,随机生成10个地理位置分散的数据中心网络拓扑,拓扑中包括1 000个物理主机和200个网络设备.表2为物理主机参数表.
此外,利用Cloudsim平台中的DataCenter,Host,Vm,DataCenteBoker等多个类,构建相应的1 000个物理主机属性信息和模拟对应的虚拟机请求信息.仿真了4种类型的物理主机模拟数据中心的异构特性:[〈4core-8g〉,〈8core-8g〉,〈8core-16g〉,〈16core-24g〉].同样利用随机的方式,模拟不同用户在不同IP下的虚拟机请求,虚拟机请求数量从10~500随机波动.每个虚拟机的资源请求大小为CPU[1~4],内存为[1~10]×512 M.
3.2 参数设置
本节对实验中的参数值拓扑分割门限值SplT,拓扑合并门限值MerT和虚拟机分配算法中的α参数进行讨论及测试.在网络拓扑分割的过程中,本文通过设定拓扑分割门限SplT和拓扑合并门限MerT来处理2分迭代分割出现的最下层子拓扑中节点数量较少的情况.本文通过固定合并门限,变动分割门限,或者固定分割门限,变动合并门限,通过不同的门限取值,观察不同设置下平均虚拟机分配时间.在网络拓扑中,对物理主机的搜寻速度越快,则相应的虚拟机分配时速会更快.因此实验测试中,测试100个虚拟机请求的分配,设置拓扑分割门限值SplT(10~20),合并门限值MerT(0~5)时,从表3中可以看出,拓扑分割门限值SplT(15~16),拓扑合并门限值MerT(2~3)时,此时拓扑结构下物理主机的搜寻速度最快,虚拟机平均分配时间最少,显示出良好的分配性能.
参数α是从子拓扑空闲物理主机数与虚拟机请求数量的比值.如果从子拓扑空闲物理主机中等同于虚拟机请求数量,则虚拟机的分配情况唯一,这种分配并非最优.因此从子拓扑空间选择空闲物理主机数量是要大于虚拟机的请求数量.本文在仿真实验中,设置固定虚拟机数为100,变动α取值为1.0~2.0,从网络拓扑中,搜寻虚拟机请求数量α倍的物理主机,表4给出了部分实验数据,可以看出,α取值为1.2~1.5时,物理主机的平均利用率较高,浪费率较低.
通过对表3和表4的分析可知,当拓扑分割门限值SplT(15~16)且拓扑合并门限值MerT(2~3)时,算法拥有较快的物理主机搜寻速度;当α取值为1.2~1.5时,物理主机的平均利用率较高,浪费率较低.
3.3 实验结果
本次实验从虚拟机分配时间、资源均衡度、资源浪费度、能耗和物理主机数量等5个方面对HTES算法进行验证.
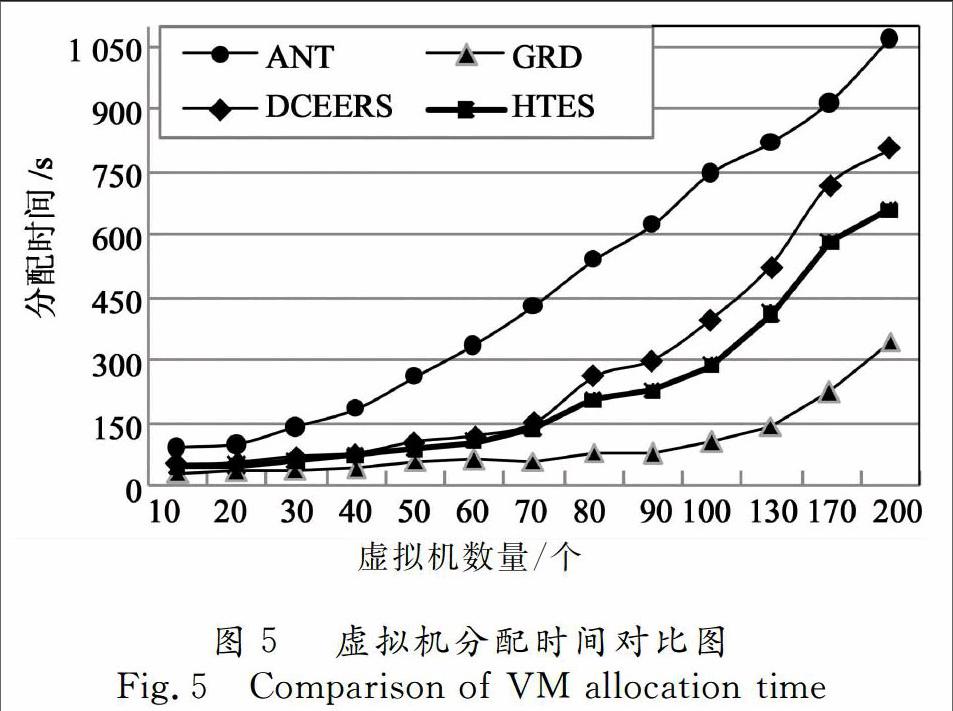
图5为4种算法在不同虚拟机数量下的分配时间对比.从图4可以看出,随着虚拟机数量的不断增加(10~200),分配时间快速增大.在4种算法中,GRD算法的分配时间最少,其次是HTES算法,ANT算法时间最多.在4种算法中,GRD算法随机分配虚拟机,将虚拟机分配到空闲资源最大的物理主机上,不考虑其他目标,其分配速度最快.HTES、DCEERS和ANT以节能和提升底层资源利用率为虚拟机分配的目标,通过不同的分配策略实现节能,分配时间较GRD算法而言有所增加.HTES算法在3种算法中分配时间最快.因为,HTES算法将分布式数据中心网络拓扑进行分割,建立层次拓扑树,生成索引.根据用户IP将虚拟机请求分组,快速扫描层次拓扑,查询物理主机,将虚拟机请求集中的分配到底层物理主机,加快了分配效率,减少了物理主机的使用数量,节约了能耗;DCEERS算法将虚拟机分配问题看做最小商品流问题,通过Benders分解进行虚拟机分配,利用最小数量的物理主机承载虚拟机请求,同样减少了物理主机的数量,节约了能耗;ANT算法利用蚁群策略求解多目标虚拟机的分配问题,同时优化底层资源的利用和能耗.然而ANT算法需要大量的迭代寻找最优,分配时间上较差.
物理主機内CPU和内存资源的均衡率对比如图6所示.从图6可以看出,随着虚拟机请求数量的不断增加(10~200),4种算法的资源均衡程度不断变化.其中,HTES算法均衡率最好,ANT和DCEERS较差,GRD最差.当虚拟机请求数为10~50时,GRD和ANT的资源均衡逐级下降,HTES和DCEERS两种算法围绕0.65和0.6两条水平线上下波动.当虚拟机请求数超过50时,ANT和GRD的均衡率稍微回升,DCEERS则开始下降,HTES相对平稳且有所提升.在各种虚拟机请求数量下,HTES都拥有较好的资源均衡率.因为,HTES在进行虚拟机分配时,需要根据公式(1)计算虚拟机与物理主机间的匹配度,将虚拟机分配到合适的物理主机上,均衡物理主机多维资源的利用率;DCEERS和ANT算法在尝试用最小的物理主机分配最多的虚拟机,随着虚拟机数量的增加,造成物理主机间资源的不均衡;GRD算法随机分配虚拟机,当虚拟机数量较小时,占用底层高性能的物理主机,造成物理主机内的资源分配不均衡.随着虚拟机数量增加,高性能物理主机的资源利用率提升,各维资源的均衡度相应增加.
图7展示了4种算法的资源浪费情况.图中资源的浪费率是指CPU和内存浪费率的均值,从图7可以看出,在不同虚拟机请求数量下(10~200),4种算法的资源浪费率不断变化,HTES算法浪费率最小,其次是DCEERS和ANT,GRD算法最大.在虚拟机数量较小时(10~30),HTES,DCEERS和ANT 3种算法的资源浪费率相近,HTES略差于DCEERS和ANT算法.随着虚拟机数量的不断增加,HTES算法的浪费率明显优于其他3种算法.因为,GRD算法的随机分配策略,并未考虑任何资源均衡目标,其分配时间快,资源浪费率高.DCEERS和ANT通过蚁群和Benders分解,在优化虚拟机分配的同时,提高了资源利用率,节约了能耗;但是两者并未考虑物理主机多维资源的均衡分配问题.HTES算法利用公式(1),在区域性分配虚拟机的同时,均衡地分配物理主机的多维资源(CPU和MEM),在提升底层资源利用率的同时,降低了各维资源的浪费率.
图8为4种算法在不同数量虚拟机下占用物理主机的单位时间能耗情况,物理主机单位时间能耗是指虚拟机占用的所有物理主机功耗之和.从图8可以看出,随着虚拟机数据的不断增加(10~350),单位时间的功耗快速加大.4种算法中GRD算法功耗增加最快,ANT和DCEERS的功耗比较接近,HTES算法的功耗最小.当虚拟机的数量为10~150时,其功耗增加速率相对较慢,4条趋势线的坡度比较缓,HTES算法功耗增加速度最慢.然而,随着虚拟机数量的不断增加,4种算法的功耗急速增加,坡度加大,HTES算法的功耗逐渐接近ANT和DCEERS算法.因为HTES算法、ANT和DCEERS算法都是通过提供资源利用率,减少底层物理主机使用数量来节约能耗.HTES算法额外考虑了物理主机多维资源均衡分配问题,进一步提升了物理主机的资源利用率.然而,随着虚拟机数量的不断增加,底层物理主机的空闲数量不断减少,单位时间产生的功效必然增加,最终变为一致(所有物理主机都在使用).
图9为4种算法对底层异构物理主机的使用情况.从图9可以看出,4种算法在相同虚拟机数量下占用的物理主机类型和数量各不相同.在4种算法中,GRD算法偏向于占用高性能物理主机.在虚拟机数量较小(80~150)时,G4[16c,24g]类型的物理主机被全部占用.随着虚拟机数量的增加(150~300),G3[8c,16g]类型的物理主机被快速占用;相反,HTES算法偏向于使用低性能的物理主机.在虚拟机数量较小(80~150)时,G1[4c,8g]和G2[8c,8g]类型的物理主机被占用.随着虚拟机数量的增加(150~300),G3[8c,16g]和G4[16c,24g]类型的物理主机少量被占用;ANT和DCEERS算法则相对比较均衡,在各种虚拟机数量下,均衡占用G1[4c,8g],G2[8c,8g],G3[8c,16g]和G4[16c,24g]类型的物理主机.HTES算法喜好占用低性能物理主机特性更方便进行分布式数据中心的节能.
4 结 论
针对虚拟机分配中物理主机多维资源的浪费问题,结合分布式数据中心网络拓扑的大规模性和地理位置的不同,本文提出了一种基于层次拓扑树的虚拟机节能分配算法.首先,将大规模网络拓扑按照地理位置的不同,划分成多个顶层子拓扑.其次,利用Laplacian矩阵和Ncut的特性,进行迭代二分切割,建立层次拓扑树.然后,根据虚拟机请求IP地址与数据中心位置的远近,将虚拟机请求分组,根据分组中虚拟机数量检索层次拓扑树,快速查询合适的区域性物理主机集合.最后,根据虚拟机请求与物理主机间的匹配度均衡分配物理主机的多维资源,提高了资源利用率,减少底层物理主机使用数量,通过关闭空闲物理主机实现了数据中心的节能.文中将HTES算法与GRD算法、DCEERS算法和ANT算法进行比较,从虚拟机分配时间、资源均衡率、能耗和物理主机使用情况等方面验证了HTES算法的性能,表明HTES算法适合于分布式数据中心.
参考文献
[1] ZHAO J, LI H, WU C, et al. Dynamic pricing and profit maximization for the cloud with geo-distributed data centers[C]//Conference on Computer Communications.Toronto: IEEE, 2014: 118-126.
[2] TUDORAN R, COSTAN A, WANG R, et al. Bridging data in the clouds: an environment-aware system for geographically distributed data transfers[C]//Cluster, Cloud and Grid Computing (CCGrid), 2014 14th IEEE/ACM International Symposium on. Chicago:IEEE,2014: 92-101.
[3] ALICHERRY M, LAKSHMAN T V. Network aware resource allocation in distributed clouds[C]//INFOCOM.Orlando: IEEE,2012: 963-971.
[4] ISLAM M A, REN S, PISSINOU N, et al. Distributed temperature-aware resource management in virtualized data center[J].Sustainable Computing: Informatics and Systems, 2015(6): 3-16.
[5] KO Y M, CHO Y. A distributed speed scaling and load balancing algorithm for energy efficient data centers[J]. Performance Evaluation, 2014, 79: 120-133.
[6] 鄧子云,章兢,白树仁,等.基于超级计算的 CAE 集成平台架构设计[J].湖南大学学报:自然科学版,2013,40(7): 80-85.
DENG Ziyun, ZHANG Jing, BAI Shuren,et al.Architectural design of CAE integration platform based on super computation[J]. Journal of Hunan University: Natural Sciences,2013, 40(7): 80-85.(In Chinese)
[7] GEORGIOU S, TSAKALOZOS K, DELIS A. Exploiting network-topology awareness for VM placement in IAAS clouds[C]//Cloud and Green Computing (CGC), 2013 Third International Conference on. Karlsruhe: IEEE, 2013: 151-158.
[8] PENG Y, YUAN Y, HUANG X, et al. Research on maintainability of network topology for data centers[C]//2014 Sixth International Conference on Ubiquitous and Future Networks (ICUFN). Shanghai: IEEE, 2014: 317-321.
[9] SHIRAYANAGI H, YAMADA H, KENJI K. Honeyguide: a VM migration-aware network topology for saving energy consumption in data center networks[J]. IEICE Transactions on Information and Systems, 2013, 96(9): 2055-2064.
[10]JAIN N, MENACHE I, NAOR J S,et al. Topology-aware VM migration in bandwidth oversubscribed datacenter networks[M].Berlin Heidelberg: Springer Berlin Heidelberg,2012:586-597.
[11]JIN H, CHEOCHERNAGNGARN T,LEVY D,et al.Joint host-network optimization for energy-efficient data center networking[C]// Parallel & Distributed Processing (IPDPS), 2013 IEEE 27th International Symposium on. Boston : IEEE, 2013: 623-634.
[12]SHUJA J, BILAL K, MADANI S A, et al. Data center energy efficient resource scheduling[J]. Cluster Computing, 2014, 17(4): 1265-1277.
[13]HAMMADI A, MHAMDI L. A survey on architectures and energy efficiency in data center networks[J]. Computer Communications, 2014, 40: 1-21.
[14]MOGHADDAM F A, LAGO P, GROSSO P. Energy-efficient networking solutions in cloud-based environments: a systematic literature review[J]. ACM Computing Surveys (CSUR), 2015, 47(4):1-32.
[15]BELOGLAZOV A, ABAWAJY J, BUYYA R. Energy-aware resource allocation heuristics for efficient management of data centers for cloud computing[J]. Future Generation Computer Systems, 2012, 28(5): 755-768.
[16]GU L, ZENG D, GUO S,et al.Joint optimization of VM placement and request distribution for electricity cost cut in geo-distributed data centers[C]//Computing, Networking and Communications (ICNC), 2015 International Conference on. Garden Grove: IEEE, 2015: 717-721.
[17]BUYYA R, RANJAN R, CALHEIROS R N. Modeling and simulation of scalable Cloud computing environments and the CloudSim toolkit: challenges and opportunities[C]// High Performance Computing & Simulation,HPCS'09,International Conference on. Leipzig: IEEE, 2009: 1-11.
[18]MILLS K, FILLIBEN J, DABROWSKI C. Comparing VM-placement algorithms for on-demand clouds[C]// Cloud Computing Technology and Science (CloudCom), IEEE Third International Conference on. Athens : IEEE, 2011: 91-98.
[19]GAO Y, GUAN H, QI Z, et al. A multi-objective ant colony system algorithm for virtual machine placement in cloud computing[J]. Journal of Computer and System Sciences, 2013, 79(8): 1230-1242.
猜你喜欢
电子乐园·下旬刊(2022年5期)2022-05-13
通信产业报(2020年11期)2020-04-20
中国计算机报(2018年12期)2018-10-08
中国计算机报(2018年24期)2018-09-21
通信产业报(2017年27期)2017-08-01
中国计算机报(2017年25期)2017-07-15
中国计算机报(2017年23期)2017-07-06
中国计算机报(2014年12期)2014-05-29
中国计算机报(2009年41期)2009-11-12
