
基于Logistic时间函数和用户特征的协同过滤算法
2017-02-27 11:10:41赵文涛成亚飞王春春
计算机应用与软件 2017年2期
赵文涛 成亚飞 王春春
(河南理工大学计算机科学与技术学院 河南 焦作 454000)
基于Logistic时间函数和用户特征的协同过滤算法
赵文涛 成亚飞 王春春
(河南理工大学计算机科学与技术学院 河南 焦作 454000)
目前推荐系统中协同过滤算法是应用最成熟的推荐算法之一,然而传统算法没有考虑随着时间的迁移,用户的兴趣也可能发生相应变化以及特征属性在推荐过程中对推荐结果的影响,致使预测结果不准确。为此,提出一种新的相似性改进算法对传统算法进行改进。改进后的协同过滤算法对基于时间的Logistic权重函数与用户特征属性进行加权计算,形成一种新的相似性度量模型。实验结果表明该算法推荐平均绝对误差(MAE)比传统算法降低了12%,较传统算法推荐质量有明显提高。
协同过滤 兴趣变化 时间权重 用户特征
0 引 言
在现实生活和工作中,网络上的信息量越来越大,为了从大量的信息中搜索到我们所需要的信息,就必须花费更多的时间,这就是所谓的“信息过载”问题。面对与日俱增的信息量,我们再想找到自己所需的信息变得越来越难。针对这个问题,广大的研究学者和科研人员为了更大程度地挖掘潜在的有用信息,对推荐系统[1]的推荐准确性和效率等方面进行了更深层次的研究,提出了多种改进推荐算法,其中协同过滤算法[2]就是最为典型的推荐算法。
在推荐系统中推荐算法是关键要素。迄今为止,多种推荐算法被提出,其中,冷亚军等人[3]介绍了相对完整的协同过滤知识架构,对认清协同过滤的发展前景,促进个性化信息服务的发展具有参考意义。王道平等人[4]在综合考虑用户兴趣和项目特征的基础上,提出基于内容相似度的知识协同过滤推送算法,一定程度上提高了信息推送的精确度。王卫平等人[5]提出基于标签(Tag)和协同过滤的混合推荐方法TAG-CF,能够有效降低推荐系统的平均绝对误差,提高推荐质量。以上文献中所提到的算法虽然在一定程度上缓解了数据稀疏性和冷启动问题,但没有考虑用户兴趣变化和用户特征属性对推荐结果的影响,这是本文改进算法的研究重点。
研究者更青睐于最常见的基于用户的协同过滤算法(UBCF)和基于产品的协同过滤算法(IBCF)。如果仅采用传统的协同过滤算法进行推荐会存在很多问题,主要问题有:数据的稀疏性问题[6],冷启动问题,算法的扩展性问题和同一性问题。由于用户年龄大小,所处生活环境,受教育程度,兴趣爱好各不相同,思维方式的差异性和产品个体的差异性,都是导致推荐结果不准确的原因。用户相互之间的独立性和预测环境的不同以及产品之间相互联系的不确定性,是基于用户或产品的协同过滤算法存在一定局限性的主要原因。在本文中,对传统的推荐算法进行改进,提出了基于用户访问时间和相关特征属性[7]相似度的数据权重[8],将其引入到协同过滤算法的生成推荐过程当中,能够更好地体现用户兴趣的变化规律,从而改善推荐效率。
1 相关工作及研究
随着网络上的信息呈几何倍数增长,普通人再想轻松获取自己所需信息变得越来越困难,这就为研究人员提出了更高的要求。构建一套完整的推荐系统是相当复杂的,分清楚推荐系统与推荐算法、推荐模型的区别至关重要。推荐系统的核心在于推荐算法,众多的科研人员可能会将大部分精力投入到推荐算法的优化上。然而事实并非如此,数据的搜集、整理、筛选等准备工作在推荐系统中同样重要,例如当淘宝网推荐顾客可能喜欢的商品时,不能只依靠简单的推荐算法,顾客的个人信息,浏览记录,过去一段时间的购物信息,购物车里面的商品清单等都会影响顾客的购物选择。
推荐系统的原理:首先,收集数据库中客户或产品的数据信息。其次,选取合适的推荐模型,查找相似用户集。最后,采用KNN算法为目标用户选择推荐对象。
1.1 基于时间的数据权重
作为推荐系统的重要准备工作,数据信息采集主要是收集用户对产品的评分记录,构建一个用户产品评分矩阵UIM(User Item Matrix),用R_(m×n)=(R_(a,j))_(m×n)表示。其中,m表示用户行数,n表示产品列数,R_(a,j)表示第a个用户对第j个产品的评价分数。
1.2 查找相似用户集
推荐系统最为核心一步就是推荐算法的选取,采用合适的推荐算法计算用户(或项目)相互之间的相似度[9],然后删选出与目标用户相似度[10]最高的K个用户(或项目)作为备选邻居集。相似度的计算方法种类繁多,但最常用的主要有下面三种方法:如式(1)-式(3)所示。
1) 余弦相似性
(1)
2)Pearson相关相似性
(2)
3) 修正的余弦相似性
(3)
1.3KNN算法推荐
通过前面相似度算法得到用户相互之间的相似度,采用KNN算法为目标用户选取与其最相近的前N个作为邻居集[11],传统预测评分方法如下:
(4)
选取其中排在前面的而且未出现过的前N个选项组成Top-N推荐集。
2 改进算法描述
从上述对传统推荐算法的介绍过程中可以看出,个性化推荐系统[12]主要是根据用户对产品的打分操作,得到用户产品评分矩阵,来表达用户对某件产品的喜爱程度。然而在现实情况下,用户随着阅历的增加和年龄的增长,兴趣爱好[13]同过去一段时间相比会有所变化。例如某用户A在结婚之前,可能更喜欢衬衣领带等都是自己生活所需的物品,在结婚之后精力更多地投入到家庭,所购买的用品大多由自己转向了妻子或孩子,这个例子很好地说明了一个人在一段时间内的兴趣转移,在前一段时间特别关注的物品在当前可能就没有那么重要了。所以传统的个性化推荐系统仅仅采用用户评分矩阵对目标用户进行推荐可能感兴趣的产品存在一定的局限性,虽然算法UBCF和IBCF在一定程度上能够进行推荐,但考虑现实情况的复杂性和多样性导致推荐结果差强人意。
2.1 基于Logistic函数的数据权重
推荐系统中一般把时间标签作为一个重要的标签信息,能够体现用户的兴趣迁移。用户在不同时间区间内的兴趣和行为可能会有很大反差,例如在一天的行为变化中,白天用户更倾向于将精力投入到工作中,而晚上就可能放松一下,到公园散散步,看看电影或者电视剧等娱乐节目。
为了解决传统算法不能充分体现用户兴趣爱好随时间变化的问题,本文在计算用户相似度时提出基于时间的logistic权重函数[14],运用logistic函数对产品评分进行时间加权计算,对不同时间区间的评分数据加以区分,增加近期数据的信任度[15]权重,减弱过去喜好的权重比例,logistic函数为:
(5)
式中,ta,j表示用户a对项目j产生兴趣的时刻与该用户所有评分项目中最早评价时刻之间的时间差。函数f(ta,j)随ta,j的增加而单调递增。
本文提出的logistic时间函数比文献[16]中用到的线性时间函数更能反映人类的遗忘规律,相较于文献[17]中提出的基于Ebbinghaus遗忘曲线作为时间函数推荐结果更为准确,故采用logistic函数。从该函数中可以看出函数取值范围是(0,1),函数值随时间标签的变化呈非线性曲线增长,强调近期活动对目标用户行为的影响程度,改善传统算法仅利用用户评分进行推荐的不足,最大化地为目标用户推荐有相似兴趣爱好的邻居用户。
2.2 基于非线性遗忘函数的改进CF算法
改进算法采用时间窗口技术将用户过去行为的时间标签运用离散化方法进行分段,分别将时间标签映射到这些时间窗口上,遵循客户兴趣的变化规律,提出基于时间权重的非线性遗忘函数的改进CF算法,实现个性化的推荐,将式(5)引入到Pearson相关相似性系数中,得到改进相似度计算方法如式(6):
simT(i,j)=
(6)
上述改进算法在计算过程中有效地为目标用户挑选可能兴趣度相近的邻居用户。
2.3 用户特征的挖掘
在平时的生活中,相同类别的人可能在兴趣取向上比较类似,而不同特征属性的人兴趣取向可能差别比较大,正所谓人上一百,形形色色,难免良莠不一,何况是上千上万。比如教师和农民工这两类在生活中最经常接触的两类人群,教师一般都受过高等教育,文化素质较高,工作上教书育人从事脑力劳动且工作环境干净整洁,而农民工普遍文化素质不是很高,工作环境差大多以体力劳动为主。这两类人群由于工作环境,社会经历的不同而兴趣爱好千差万别。
传统的协同过滤算法在对用户相似度的计算过程中,没有结合用户属性信息,致使推荐结果具有一定的局限性。为了使推荐结果是用户想要得到的结果,达到用户的满意,在对用户详细信息的深入挖掘过程中,特征数据与评分数据对用户兴趣取向的影响没有任何交集,分析不同特征数据,尽最大可能挖掘与目标用户具有相似特征信息的用户作为推荐邻居。
本文对Movielens电影评分数据集中用户信息进行挖掘,得到用户的年龄、性别、职业、邮编等个人基本信息,不同属性标签代表不同的用户群体,例如性别特征,在天猫网进行网购过程中,男女购物类别相差就比较大。不同职业的用户,由于工作环境不尽相同,对事物的感兴趣程度也不相同,例如工作在发达城市的高薪阶层与二三线城市的低薪阶层,这两类人群不管在穿着打扮、言行举止等方面均存在明显不同。所以本文对用户的特征属性标签进行离散化取值,针对年龄标签将其大致分类为少年、青年、成年人和老年人阶段。将邮编信息表示为用户地域特征。文中将各类特征标签进行离散化后得到如下简化的用户特征信息表如表1所示。

表1 用户特征属性表
根据上述得到的特征属性表计算用户相似性sim1,具体步骤如下:设特征矩阵表示形式为Attri={Aa1,Aa2,…,Aai},其中Aai分别对应用户a的属性标签中的性别、年龄、职业、地域特征。如果Aai=Abi=1,表示a和b的第i个特征属性相同或在同一个特征区间内,如果Aai=Abi=0,表示a和b的第i个特征属性没有交集,不是属于同一类别的人群,所有就不能将其作为邻居用户推荐给目标用户,实验中计算特征相似性的计算公式如下:
(7)
得到用户的特征相似性后将式(7)引入到修正的余弦相似性系数中,进一步计算得到基于用户特征的改进相似性公式,得到等式如下:
simR(i,j)=
(8)
上述改进算法利用对具有相似特征的用户进行聚类分析给目标用户推荐最相近特征邻居集。
2.4 改进相似度计算模型
前面介绍了两种数据加权度量,它们各有优势:为了适应用户兴趣频繁变化的情况,强调近期数据在权重上的比例,从而能更快地捕捉到用户的近期爱好,而基于用户特征相似度中,具有相似特征的人的兴趣爱好会很相近,并且不同类别的人的偏好特征是非常不同的。于是考虑到双权函数与一定比例因子组合,基于时间的权重函数,同时对用户特征进行定义:
sim(u,v)=(1-W)simT(u,v)+WsimR(u,v)
(9)
式中比例因子W∈[0,1],W和(1-W)分别代表两种权重值所占的比例。通过选择适当的权值,将两者的优点结合起来,从而进一步提高推荐算法的精度。
2.5 组合KNN推荐算法
本文提出的改进协同过滤算法模型引入非线性logistic时间函数和用户特征属性,有效克服了传统算法实时性差的缺点,利用KNN算法得到目标用户的最近邻居集后,采用式(10)计算得出每一个项目的预测值。
(10)
选取其中排在前面的而且未出现过的前N个选项组成Top-N推荐集。
2.6 算法描述
改进的算法在加入时间因子后能较好地捕获用户的兴趣取向,对推荐的精度进行优化,更能反映在现实生活的推荐实例中,算法1给出了详细的算法描述。
算法1:
输入:用户i,所有被用户i访问过的项目Ii,用户近邻模型M。
输出:用户i所对应的Top-N推荐集。
Step1 运用本文中改进协同过滤算法对所有用户计算其近邻模型M,使用KNN算法得到它的k个最近邻居集NEIi={I1,I2,…,Ik},将所有NEIi进行合并得到集合Y;
Step2 将Y中每个用户评价的所有项目合并得到集合X;
Step3 将X中与Ii相同的项目剔除,剩下的项目即是候选集Cand;
Step4 对所有项目计算得到预估分值,选择Cand中分值高的N个项目作为推荐集。
3 实验结果及分析
3.1 数据集及评判标准
文中的实验部分用到的数据取自于MovieLens数据集,其中的实验数据主要源于设计者们调查不同的用户群体对电影的看法评分,在子文件u.data中包含了100 000条评分数据,这些数据是选自943个用户对1 682部电影项目的打分数据。而文件u.user中包含用户的gender、age、occupation、zipcode等个人基本信息。为了有效缓解数据稀疏性,这些用户都至少评价过二十部以上的电影,评分分值从1到5不等,分值越高代表用户对电影印象度越深。
在推荐系统中用来衡量算法推荐质量好坏的评判标准有很多,在业界用到最多的衡量准则是平均绝对误差MAE(MeanAbsoluteError),其原理是将实验得到的结论与实际的结论两者偏差的比较作为衡量标准,推荐准确度的好坏与MAE值的大小成反比关系,计算得到MAE值越小的算法表示更高质量的推荐算法。在实验中假设用户u对所有项目的预测分值为Pu,1,Pu,2,…,Pu,n。与其相对应真实分值为Qu,1,Qu,2,…,Qu,n。则MAE的定义为:
(11)
3.2 仿真分析
实验中首先对改进相似性计算模型中权值W进行计算,在式(9)中W的值为可变的实验权重,由前文可知比例因子W的大小范围是[0,1]。当W=0时,表示改进算法模型只考虑用户兴趣对推荐结果的影响;当W=1时,表示用户特征属性对推荐结果的影响。
实验如图1所示,取W值从0到1每隔0.1逐渐递增,从中可以看出权重系数W在取值不同时对推荐效果的影响程度。由图1所得,在W=0.1时MAE值最小,表示推荐效果更好。
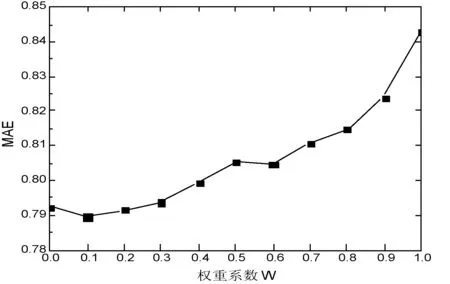
图1 权值W对推荐精度的影响
实验过程中将非线性logistic遗忘函数的改进CF算法同文献[17]中基于Ebbinghaus遗忘曲线的CF算法的推荐结果进行比较,比较结果如图2所示。在邻居数很小的情况下,得到的MAE值都比较高,推荐准确度不高;在邻居数大于10的情况下,本文提出的logistic权重函数在推荐过程中比基于Ebbinghaus权重函数所得到的MAE值都小,MAE值越小表示推荐准确度越高。故本文采用基于时间的非线性logistic权重函数来表示用户兴趣的变化趋势。

图2 两种函数推荐结果的平均绝对误差MAE比较
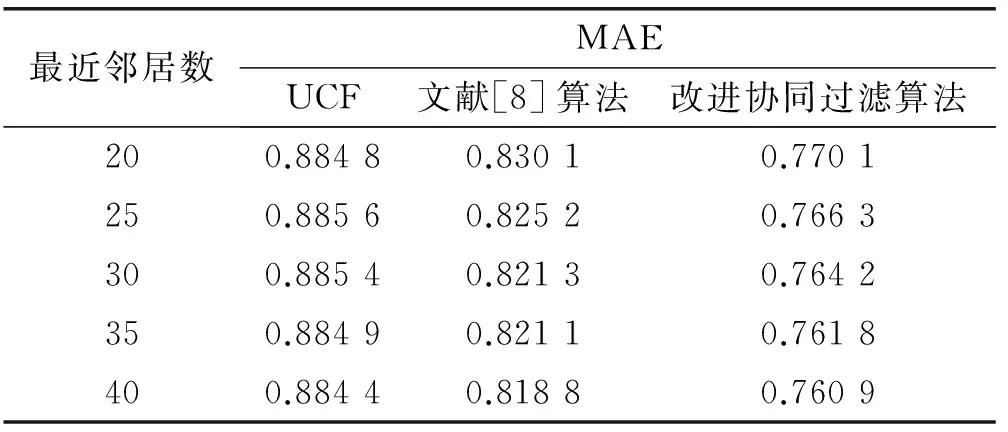
下面将以传统算法UCF和文献[8]中算法作为对照来验证本文中所提出的改进算法推荐效果。实验过程中分别计算在不同邻居数目下,各种推荐算法所得MAE值大小的不同,结果见表2所示,然后与本文提出的改进算法做对比,对比情况如图3所示。

表2 改进协同过滤算法与传统算法的MAE
续表2
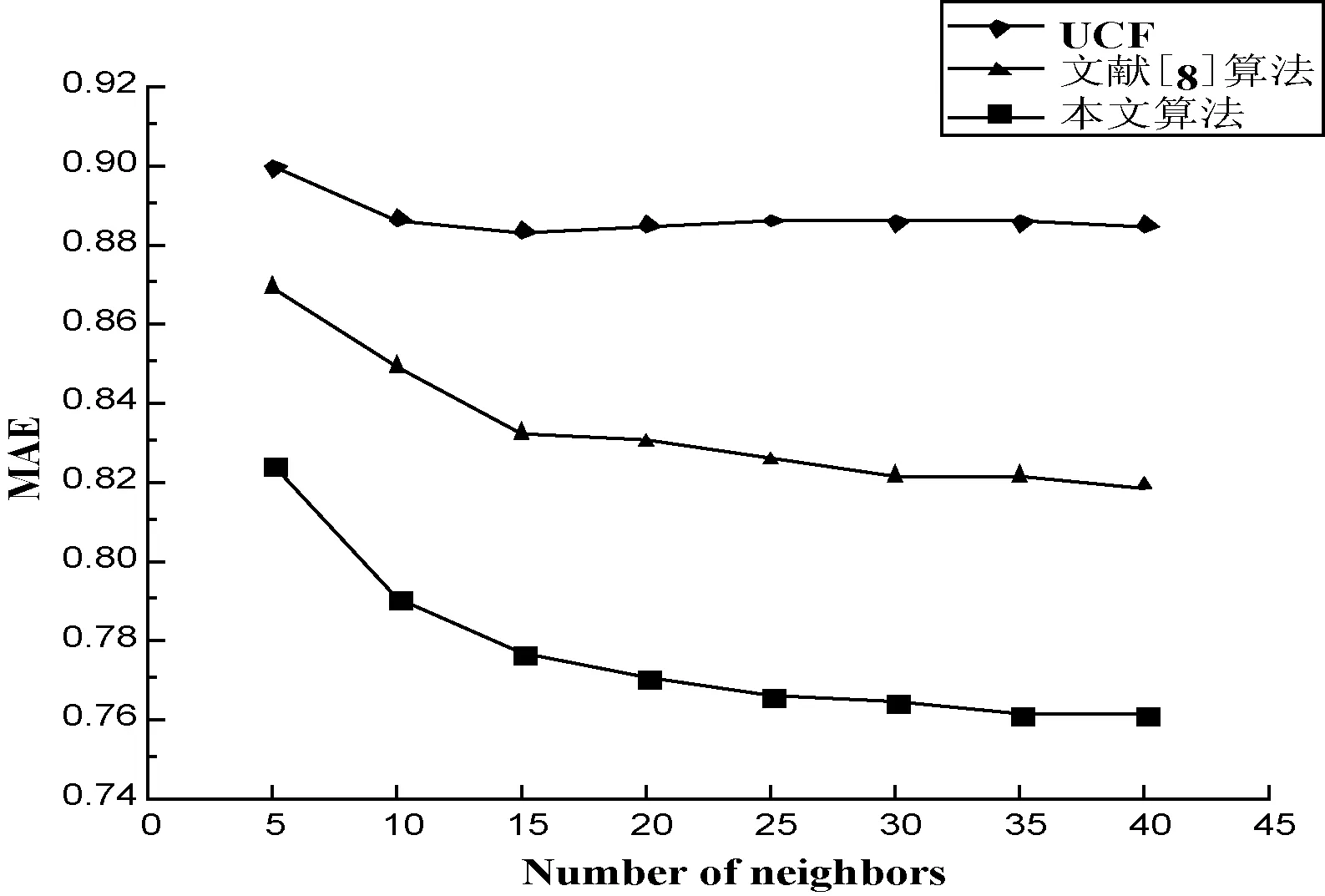
图3 推荐算法的平均绝对误差MAE比较
在表2和图3中可知,文中提出的融合用户兴趣变化和特征属性的新的度量方法在不同情况下得到的MAE值在很大程度上都低于传统方法。可见本文提出的改进算法在推荐过程中更加高效实用。
4 结 语
本文在计算用户相似度的过程中仍存在很多缺点和不足需要研究并改进。例如,因为每个人的遗忘规律会随着年龄、经历的不同而有所不同,你也需要为每个用户提出适合自己的遗忘函数,这样就能提高预测评分从而提高推荐的质量。其次实验部分只选取了常用的相似度计算方法进行了简单的对比试验,需要进一步改进,这也是本算法的遗憾之处。在未来的推荐系统的研究领域中,希望能够将更多的各个方面的知识应用到推荐系统中来,从而使推荐准确性有进一步提高。
[1] 孟祥武,胡勋,王立才,等.移动推荐系统及其应用[J].软件学报,2013,24(1):91-108.
[2] 刘青文.基于协同过滤的推荐算法研究[D].合肥:中国科学技术大学,2013.
[3] 冷亚军,陆青,梁昌勇.协同过滤推荐技术综述[J].模式识别与人工智能,2014(8):720-734.
[4] 王道平,李秀雅,杨岑.基于内容相似度的知识协同过滤推送算法研究[J].情报理论与实践,2013,36(10):86-90.
[5] 王卫平,王金辉.基于Tag和协同过滤的混合推荐方法[J].计算机工程,2011,37(14):34-35.
[6]XuJ,ZhengX,DingW.Personalizedrecommendationbasedonreviewsandratingsalleviatingthesparsityproblemofcollaborativefiltering[C]//e-BusinessEngineering(ICEBE),2012IEEENinthInternationalConferenceon,2012:9-16.
[7]YangXG.Collaborativefilteringalgorithmbasedonpreferenceofitemproperties[M].FoundationsofIntelligentSystems.SpringerBerlinHeidelberg,2014:1143-1149.
[8] 邢春晓,高凤荣,战思南,等.适应用户兴趣变化的协同过滤推荐算法[J].计算机研究与发展,2007,44(2):296-301.
[9] 邱璐.协同过滤算法中的相似度计算与用户兴趣变化问题研究及应用[D].北京:北京邮电大学,2015.
[10] 荣辉桂,火生旭,胡春华,等.基于用户相似度的协同过滤推荐算法[J].通信学报,2014,35(2):16-24.
[11] 贾冬艳,张付志.基于双重邻居选取策略的协同过滤推荐算法[J].计算机研究与发展,2013,50(5):1076-1084.
[12] 邓晓懿.移动电子商务个性化服务推荐方法研究[D].大连:大连理工大学,2012.
[13] 韦素云,业宁,吉根林,等.基于项目类别和兴趣度的协同过滤推荐算法[J].南京大学学报(自然科学版),2013,49(2):142-149.
[14]SuH,LinX,YanB,etal.ThecollaborativefilteringalgorithmwithtimeweightbasedonmapReduce[M].BigDataComputingandCommunications.SpringerInternationalPublishing,2015.
[15]YangL,HuY.Animprovedcollaborativefilteringalgorithmbasedontheconstraintmodelofconfidence[J].JournalofComputationalInformationSystems,2015,11(8):3001-3009.
[16] 嵇晓声,刘宴兵,罗来明.协同过滤中基于用户兴趣度的相似性度量方法[J].计算机应用,2010,30(10):2618-2620.
[17] 于洪,李转运.基于遗忘曲线的协同过滤推荐算法[J].南京大学学报(自然科学版),2010,46(5):520-527.
COLLABORATIVE FILTERING ALGORITHM BASED ON LOGISTIC TIME FUNCTION AND USER FEATURES
Zhao Wentao Cheng Yafei Wang Chunchun
(CollegeofComputerScienceandTechnology,HenanPolytechnicUniversity,Jiaozuo454000,Henan,China)
At present, collaborative filtering algorithm is one of the most mature recommendation algorithms applied in recommendation systems. However, traditional collaborative filtering algorithms do not take into account the problem of users’ interests drifting over time as well as the effects of feature attributes, which may decrease the accuracy of recommendation results. Hence, in order to enhance the traditional algorithms, a novel similarity measurement algorithm is put forward. In this paper, an innovative similarity measurement model is constructed by combining time-based Logistic weight function and user feature similarity-based data weight. Experimental results show that compared with traditional algorithms, the mean absolute error (MAE) of recommendation using the proposed algorithm is reduced by an average of 12% and the quality of recommendation is improved significantly.
Collaborative filtering Interest change Time weight User feature
2016-04-02。河南省科技攻关项目(142402210435)。赵文涛,教授,主研领域:计算机专业教学和数据库技术,信息系统,大数据。成亚飞,硕士生。王春春,硕士生。
TP393
A
10.3969/j.issn.1000-386x.2017.02.051
猜你喜欢
数学物理学报(2022年5期)2022-10-09 08:56:44
科学大众(2020年23期)2021-01-18 03:09:08
当代陕西(2020年17期)2020-10-28 08:18:18
河北画报(2020年8期)2020-10-27 02:54:20
汽车观察(2019年2期)2019-03-15 06:00:50
人大建设(2018年5期)2018-08-16 07:09:00
电信科学(2017年6期)2017-07-01 15:44:57
中国卫生(2016年5期)2016-11-12 13:25:26
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
生物进化(2014年2期)2014-04-16 04:36:26
