
中文网络评论中的产品特征情感倾向提取算法研究
2017-02-24 10:10陶娅芝
重庆邮电大学学报(自然科学版) 2017年1期
王 永,陶娅芝 ,张 勤
(1.重庆邮电大学 电子商务与现代物流重点实验室,重庆 400065; 2.圣何塞州立大学 计算机工程系,美国 加利福尼亚州 95192)
中文网络评论中的产品特征情感倾向提取算法研究
王 永1,2,陶娅芝1,张 勤1
(1.重庆邮电大学 电子商务与现代物流重点实验室,重庆 400065; 2.圣何塞州立大学 计算机工程系,美国 加利福尼亚州 95192)
Web中的客户评论信息挖掘是大数据分析中的一项重要内容。分析客户评论中所包含的产品特征情感倾向,不仅可为消费者购买产品提供更具体的决策支持,还能有效帮助企业改进产品质量。针对商业应用的实际需要,提出了一种自动从中文客户评论中抽取产品特征并判断其情感倾向的方案。基于frequent pattern-tree(FP-tree)方法提取产品特征,结合基于语料库的方法和依存句法分析方法识别关于产品特征的主观评论语句、情感词及其情感词的依存关系,综合考虑情感词、否定词、程度词计算产品特征的情感倾向值。采用公开数据中的600篇手机评论作为实验数据,检验了算法的准确性。对比分析的结果说明,算法有很好的应用潜力,能够有效地从网络评论中获取有价值的商业信息。
情感倾向分析;产品特征;语义相似度;Web挖掘;知识发现
0 引 言
随着互联网飞速发展,电子商务应运而生且发展迅速。当前,在电子商务网站中存在着大量客户关于网络产品的评论。这些评论信息极具价值,是大数据分析中的一项重要内容。对客户评论信息进行深度地分析不仅可帮助消费者进行购买决策,也可为生产企业提供反馈信息以便于更好地改进产品。由于网络产品的客户评论信息具有及时性、数量巨大、非结构化和内容复杂等特点,仅依靠人工浏览全部的产品评论以获取有价值的信息是不现实的。因此,网络评论挖掘技术应运而生,并得到了广泛的应用。
当前,已有不少研究者提出了关于网络客户评论信息的挖掘方法。在网络评论的产品特征提取方面,Quan等[1]通过测量域向量的相似距离来实现无监督的产品特征提取。Wang等[2]提出了一种新型的混合关联规则挖掘方法来识别隐含特征,该方法的核心是使用多种互补的算法来挖掘出更多的关联规则。从中文语言特点出发,李实等[3]提出了基于关联规则Apriori的产品特征提取算法,但该方法运行效率不高。马柏樟等[4]采用潜在狄利特雷分布训练文本模型并结合同义词词林拓展和过滤规则得到产品特征。对于文本中的主观信息的识别,人们通常采用2种方法,一是将形容词作为判断语句主观性的依据,二是通过使用机器学习方法计算待识别语句与主观语句间的相似度来判断待识别语句是否是主观语句[5],第1种方法较第2种方法而言具有更好的鲁棒性。Pan等通过直推式支持向量机(transductive support vector machines,TSVM)来实现对中性语句和极性语句的区分[6]。在中文领域中,叶强等[7]提出根据连续双词词类组合模式(2-part-of-speech, 2-POS)来自动判断句子的主观性程度,该方法在查准率与查全率方面接近目前英文文本分析的研究结果。姚天昉等[8]针对微博汽车领域,提出了结合汽车评论语料与微博的基于支持向量机模型的主观句识别方法。关于句子情感分析的研究,Kim[9]在传统的 N-gram 模型基础上,将句子位置和情感词作为分类特征完成句子级的情感分类。Hu和Liu[10]提出将至少包含了一个特征词和情感词的语句定义为“意见语句”,然后根据句子中情感词汇的总体情感来判断句子的情感倾向,但是此方法只能对句子的情感倾向进行粗略地判断。唐晓波等[11]提出一种基于句法分析的极性传递法和共词分析相结合的方法对句子级文本进行情感分析。王晓东等[12]提出基于规则集和情感词汇本体的连续3词词类组合(3-POS)模型,并以此来识别和计算主观句子的倾向值。
与单纯研究文本挖掘方法不同的是,本文从数据的商业应用出发,关注如何从网络客户评论自动获取对产品特征的情感倾向。即首先确定评论中涉及的产品特征或者属性,然后逐句分析该评论中客户对这些产品特征的情感倾向。在产品特征的提取方面,采用以frequent pattern-tree(FP-tree)为基础的特征提取算法,其运行速度远高于基于Aprior的特征提取算法。在产品特征的情感分析方面,考虑了包含产品特征词和特征词附近至少有一个形容词的句子,句子的筛选对提高算法的准确性有积极的意义。与已有的研究相比,本文并非从整体上确定某条评论是好评还是差评,而是从语句级别给出客户喜好或厌恶的是产品的哪些具体特征或属性。因此,本文在应用方面关注的粒度更细,即,首先在语句级别对客户评论中的某项或多项产品特征的情感极性进行提取,以此为基础进行汇总,获得产品各项特征或属性的客户情感极性。此项研究的结果,更利于生产企业掌握客户对产品具体特征或属性的喜恶,以便改进产品设计和提升产品质量。同时,还能为消费者选购网络商品提供更具体的参考意见,利于促进网络消费市场的健康发展。
1 算法描述
本文以多种文本挖掘的方法为基础,提出如图1所示的评论信息处理的整体框架方案。首先,提出基于FP增长算法获取网络评论中的产品特征集;然后,结合依存句法分析方法和基于语料库的方法,从评论中识别出有关产品特征的主观信息元素,并根据情感词和情感词的修饰成分计算句子的情感倾向;最后,根据各句子的情感倾向结果,从整体上确定客户对产品各项特征的情感倾向值。对本算法的详细陈述如下。
1.1 提取产品特征
为了提高算法从评论中获取产品特性的效率,本文提出了一种新的方法。首先,采用FP-tree算法获取产品特征的候选集合;然后,利用产品与其属性间的语义关联关系,对获取的产品候选特征做进一步筛选,弥补了关联规则算法只考虑词频的不足,提高了产品特征集合的准确性。具体的产品特征提取步骤如下。
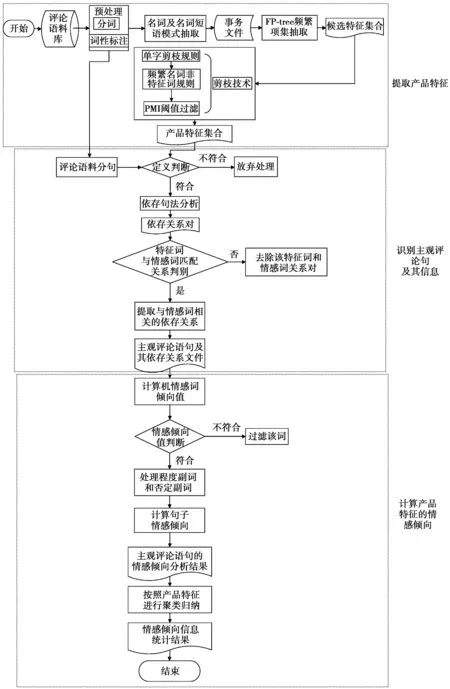
图1 评论信息处理整体框架Fig.1 Integrated framework of processing information
步骤1 采用中科院的汉语词法分析系统 (institute of computing technology chinese lexical analysis system,ICTCLAS)对评论语料进行分词和标注。由于产品特征往往与名词相关,因此,从标注后的评论语料中抽取名词和名词短语,将其存储到一个事务文件中。
步骤2 采用FP-tree算法对事务文件进行扫描,获得产品特征的候选集合I0。具体过程为:统计名词或名词短语出现的频率,删除出现频率小于最小支持度(本文以1%作为标准)的词语,得到频繁项集F1;将F1生成一棵频繁模式树(FP-tree),并保留其中的关联关系;将 FP-tree分解为若干个与频繁项集相关的条件库,再根据每一个条件库做频繁模式挖掘,得到频繁项集F2,即产品特征的候选集合I0。
步骤3 根据单字剪枝规则,去除I0中由单个字构成的特征,得到候选特征集I1。
步骤4 根据中文语义及语法知识,确定中文频繁项且非特征的名词规则。以此规则来过滤I1,得到候选特征集I2。本文制定的中文频繁项且非特征的名词规则为:
1)表示人的称呼类名词,如“同事”、“网友”、“老板”等;
2)口语化的评论名词,如“机子”、“本子”等;
3)表示评价产品本身的名词,如“手机”、“酒店”、“宾馆”等;
4)常见的抽象名词,如“原因”、“情况”、“事情”等;
5)常见的集合名词,如“大家”、“人员”等。
步骤5 2个词之间的点互信息值(pointwise mutual information, PMI)越大,表示二者之间的关联程度越高,反之则相反。计算产品和I2中各个候选特征之间的PMI值,筛选出大于阈值的候选特征,将其构成最终的产品特征集合I3。本文设定的产品与特征之间的PMI计算公式为
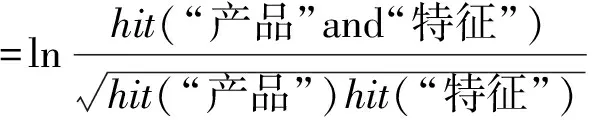
(1)
(1)式中:hit(x)是以词x为关键词时得到的搜索引擎所返回的页面数;hit(xandy)表示以x和y同时作为关键词时得到的返回页面数。此处选取百度搜索引擎返回的页面数作为PMI计算的依据,阈值通过实验样本数据综合考虑查准率和查全率来确定,本文选择的阈值为-3.77。
1.2 识别包含产品特征的主观评论语句及其评论信息
在网络客户的产品评论文本中,并非所有的句子都表达了评论者的观点、态度或情感。评论中,未包含情感信息的客观陈述句对情感倾向分析的意义不大,甚至会影响挖掘结果的准确率。因此,识别主观评论语句是进行产品特征情感倾向分析的前提。本文首先将包含产品特征的主观评论语句定义为至少包含一个特征词且特征词附近至少有一个形容词的句子;然后,结合依存句法分析方法和基于语料库的方法,从评论中识别出有关产品特征的主观评论句和评论句中包含的主观评论信息,即情感词、特征词和情感词关系对,以及情感词修饰成分等主观信息元素。具体步骤如下。
步骤1 中文网络产品评论文本具有篇幅不长,短句分隔随意,语义丰富等特点。根据这些特点,本文把以逗号、分号、句号等标点结束的短句作为一个逻辑上的语义单位,将这些短句作为一个整句单位进行处理。即根据分词中的标点符号标注{/w},将评论语料进行分句,得到一个句子片段集合。
步骤2 根据已获得的产品特征集合,从句子片段集合中获取包含产品特征的主观评论语句。使用计算机语言遍历句子中的所有词。若句子中存在产品特征集合中的词,就以该产品特征词为中心在检测窗口范围内提取形容词,将其作为情感词,得到特征词和情感词关系对。本文根据实验结果,将窗口大小设置为6。若句子中不包含特征词或者包含特征词但没有情感词,则认为该句子不是主观评论语句,忽略而不予处理。
步骤3 获取特征词与情感词之间的匹配关系,具体过程如下。
1)采用句法分析工具Parser对步骤2中得到的主观评论语句进行依存句法分析,获得句子中全部的依存关系对;
2)若特征词和情感词之间存在nsubj型的依存关系,就认为它们存在匹配关系;
3)对于不存在nsubj型依存关系的特征词和情感词,若存在一个词使得特征词和情感词之间构成间接依赖关系,也认为该特征词和情感词之间存在匹配关系;
4)保留存在匹配关系的特征词和情感词关系对,去除没有匹配关系的特征词和情感词关系对。
步骤4 从具有匹配关系的特征词和情感词关系对中提取出与情感词相关的依存关系。本文主要提取与情感词相关的advmod型和neg型依存关系对,即考虑修饰情感词的否定词和程度副词成分。
1.3 计算产品特征的情感倾向
根据主观评论语句中特征词和主观评论信息计算语句中产品特征的情感倾向。然后,对每一个产品特征的情感倾向进行统计,得到最终的情感倾向分析结果,具体步骤如下。
步骤1 计算情感词的情感倾向值。采用基于How Net的词汇语义相似度方法计算情感词的情感倾向值,其公式为
(2)
(2)式中:P代表褒义种子词;N代表贬义种子词;函数Sim(x,y)返回词语与y之间的语义相似度;Orientation(X)为词语X的情感倾向值。本文从How Net词典提供的情感分析用词语集中选取如表1所示的24组词语作为种子词。

表1 褒贬义种子词
步骤2 若词x的情感倾向值为0,且Sim(Pj/Nj,X)各项之和同时为0,则认为该词不具有情感色彩,将其过滤掉。
步骤3 考虑情感修饰词的情况下,计算主观评论句的情感倾向。
1)处理否定副词。若句子中存在与情感词相关的neg型依存关系对,则将情感词的倾向值取反,并强度减半。否定副词对情感词X的影响因子定义为
(3)
2)处理程度副词。若句子中存在与情感词相关的advmod型依存关系对,则对情感词的程度进行修饰。程度副词对情感词X的影响因子定义为
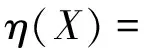
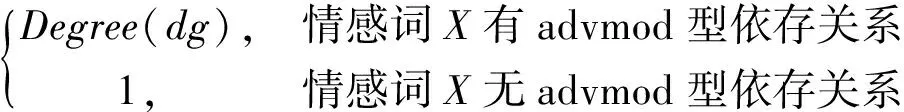
(4)
(4)式中,Degree(dg)代表程度副词dg的强度值。本文根据How Net提供的程度级别词库构建程度副词表,并按照《知网》和《近代汉语:程度副词研究》对程度副词的强烈程度进行修正[13],结果如表2所示。
3)计算句子的情感倾向。本文在综合考虑情感词、否定副词、程度副词的基础上,提出句子情感倾向的计算公式为
Orientation(S)=
(5)
(5)式中,Orientation(S)为句子的S的情感倾向值,符号正负代表句子的褒贬义。
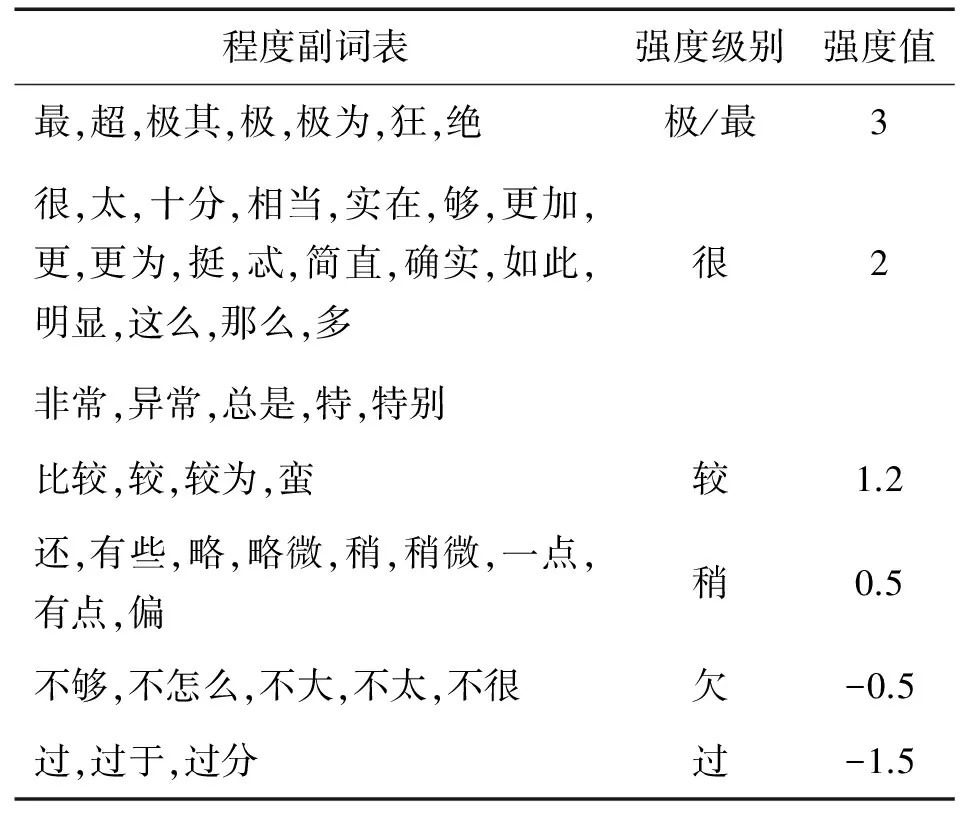
表2 程度副词及其强度
步骤4 以产品特征为分类标准,将其在各主观评论句中的情感倾向统计在一起,即为该产品特征的情感倾向值。
2 性能评价指标
在信息检索领域,常采用的性能评价指标有查准率P、查全率R、准确率Accuracy和综合值F-score。在产品特征提取的性能分析中,采用查准率、查全率和综合值作为评价指标,在句子情感倾向的性能分析中,采用查准率、查全率和准确率作为评价指标。
2.1 产品特征提取的性能评价指标
产品特征提取的各性能评价指标的计算方法为
(6)
(7)
(8)
(6)-(8)式中,A,B,C的含义如表3所示。
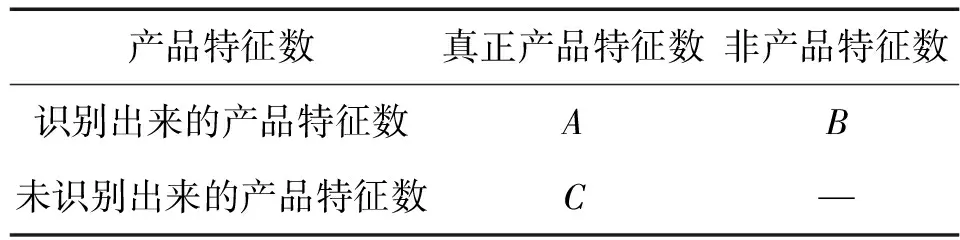
表3 产品特征提取性能评价的列联表
2.2 句子情感倾向的性能评价指标
与产品特征提取的评价指标类似,对句子情感倾向的性能评价指标的计算方法如式(9)-(13)所示。
(9)
(10)
(11)
(12)
(13)
(9)-(13)式中:p和n分别代表褒义句子和贬义句子;P(p)表示褒义句子的查准率;P(n)表示贬义句子的查准率;R(p)表示褒义句子的查全率;R(n)表示贬义句子的查全率;A,B,C,D的含义如表4所示。
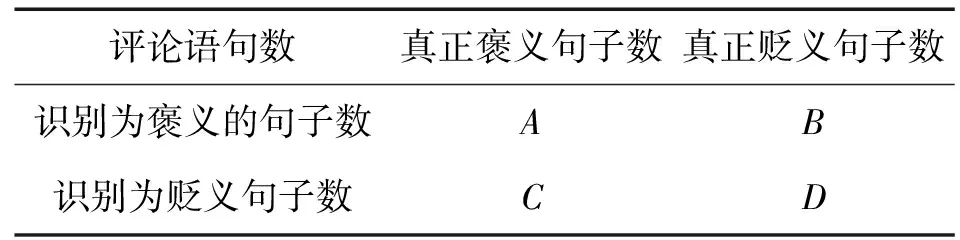
表4 句子情感倾向分析性能评估列联表
3 实验结果及性能评估
3.1 实验数据
以数据堂提供的600篇手机评论语料作为实验数据,对语料进行人工标注,得到手机的产品特征86个,如表5所示;得到主观评论语句949个,其中褒义548个,贬义401个。
3.2 实验结果
利用1.1节中提出的方法对语料进行处理,抽取出89个产品特征。因篇幅所限,仅列出客户关注度居于前20位的手机特征,如表6所示。通过该算法得到的产品特征的查准率,查全率和综合值分别为70.8%,73.3%和72%。此外,文献[14]中的结果为62.8%,81.8%和71.05%,文献[15]中的结果为70.72%,68.35%和69.51%。指标对比的结果表明,本文的特征提取方法具有更好的整体性能。

表5 人工标注的手机产品特征集合
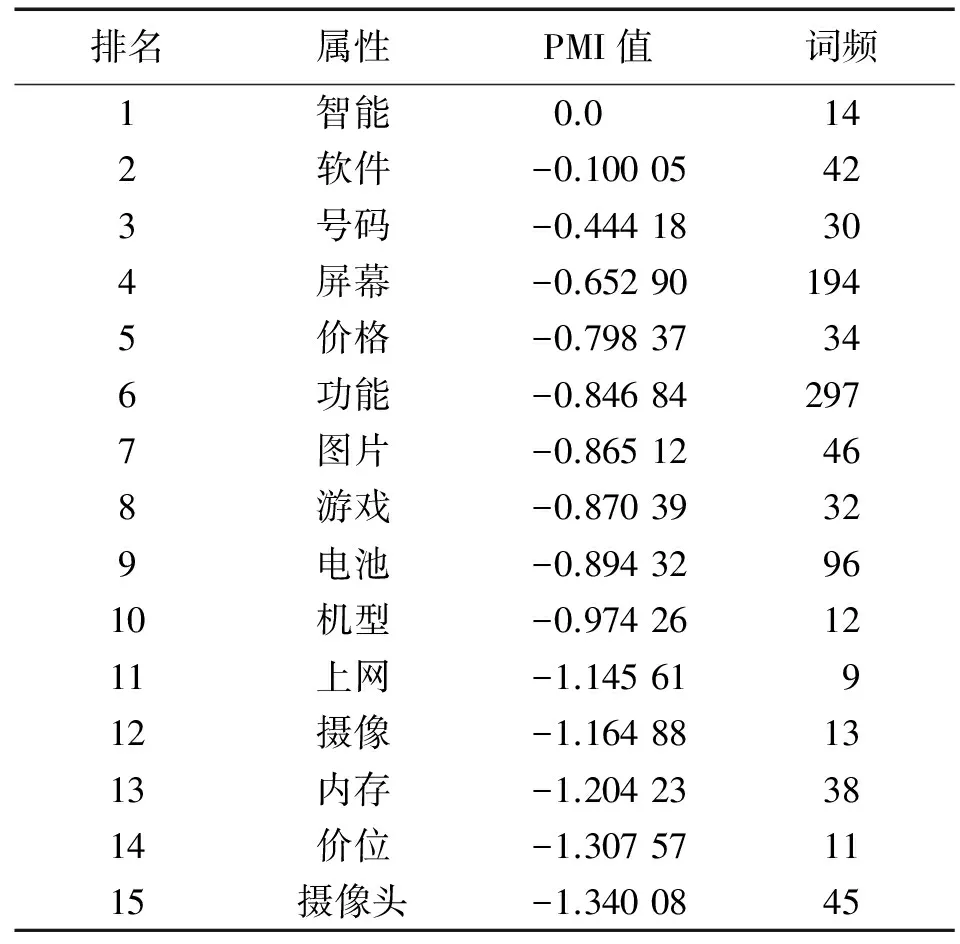
表6 手机产品特征提取结果(按PMI值排序)
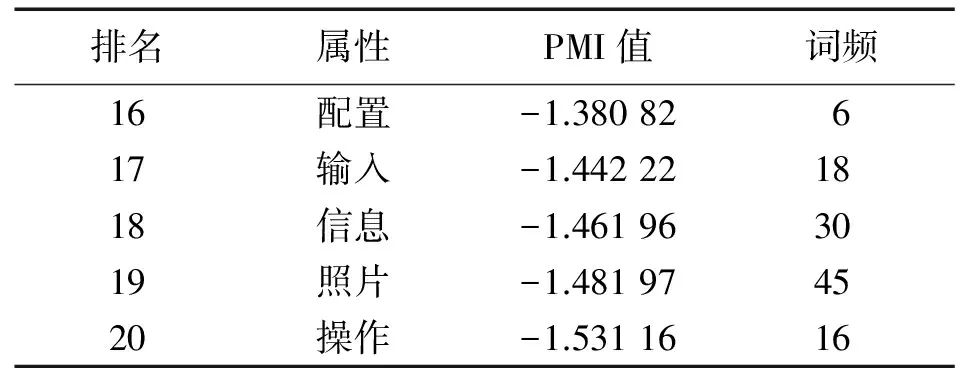
续表6
利用1.2节的方法从实验语料中共抽取到与产品特征相关的主观评论语句949句。语句中情感词及其依存关系的抽取结果(随意选取10句为代表)如表7所示。从表7中可以看出,该方法在提取主观评论信息方面具有不错的效果,为情感倾向分析奠定了好的基础。

表7 包含产品特征的主观评论语句的提取信息
采用1.3节的方法对产品特征进行情感倾向分析,并统计最终的结果,如表8所示。其中,“倾向性”列中的0代表贬义,1代表褒义。受篇幅所限,仅给出10个特征的统计结果作为代表。从表8中的信息可以看出,它能够为客户选购商品以及商家改进商品质量提供更细维度的指导。
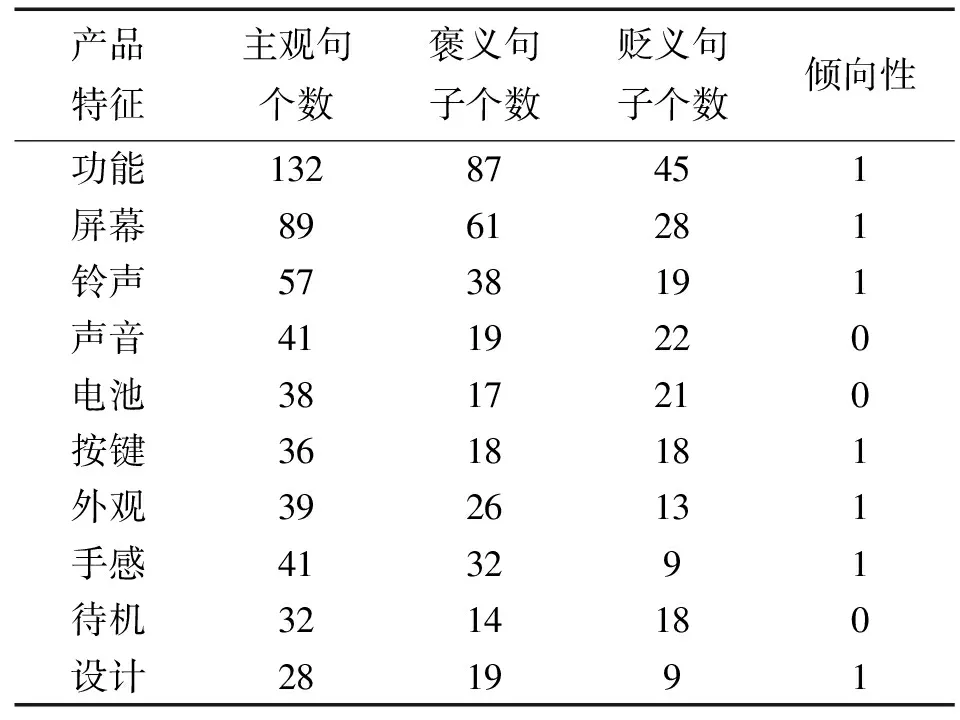
表8 产品特征的情感倾向统计结果
将本文最终得到的产品特征情感倾向结果与人工标注结果进行对比,得到情感分析实验结果的列联表如表9所示。计算得到褒义句子的查全率和查准率分别为84.1%和76.7%,贬义句子的查全率和查准率分别为65.1%和75%,总体的准确率为76.1%。
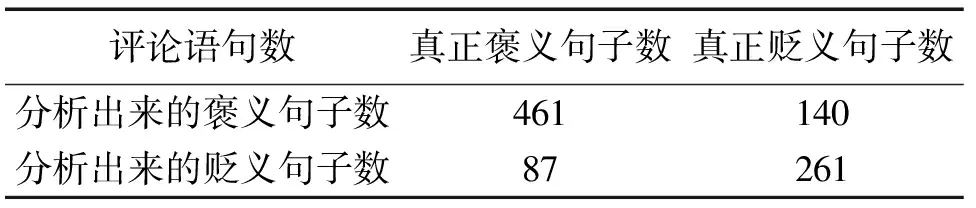
表9 情感分析实验结果列联表
3.3 效率分析
从图1所示的评论信息整体框架图中可以看出,本文方案对评论文本的处理可以划分为3大部分。在特征提取部分,采用循环方式对评论文本逐一进行分词和词性标注等处理,因此,该部分的时间复杂度为O(n)。在评论信息抽取部分,同样是以单个的评论文本为单位,依次进行分句和对句子进行主观信息的抽取,故该步骤的复杂度同样是O(n)。在情感分析部分,以每条主观评论句为单位逐一计算其倾向值,因此,该部分的时间复杂度亦为O(n)。所以,本文方案的时间复杂度为O(n)。
针对不同的评论文本数量,本文方案的处理时间变化如图2所示。从图2可以看出,方案的处理时间与文本数量之间整体上呈线性关系。在评论文本数量为250时,存在一些偏差,这主要是评论文本的字数不完全相同引起的。
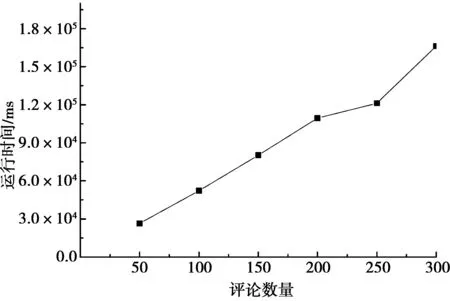
图2 算法时间复杂度分析图Fig.2 Time complexity analysis of the algorithm
3.4 实验结果对比分析
在本文的方法中,特别关注了情感词修饰成分,即程度副词和否定副词对情感倾向值的影响。为验证本文提出的修饰词处理方法对句子情感倾向分析产生的影响,采用同一语料资源,在情感趋向的计算过程中不考虑修饰词的影响,并在其余处理步骤完全相同的情况下进行试验。2种方法的性能评价指标对比如图3所示。从图3中可以很明显看出,本文提出的修饰词处理方法能有效提高句子情感倾向分析的性能。
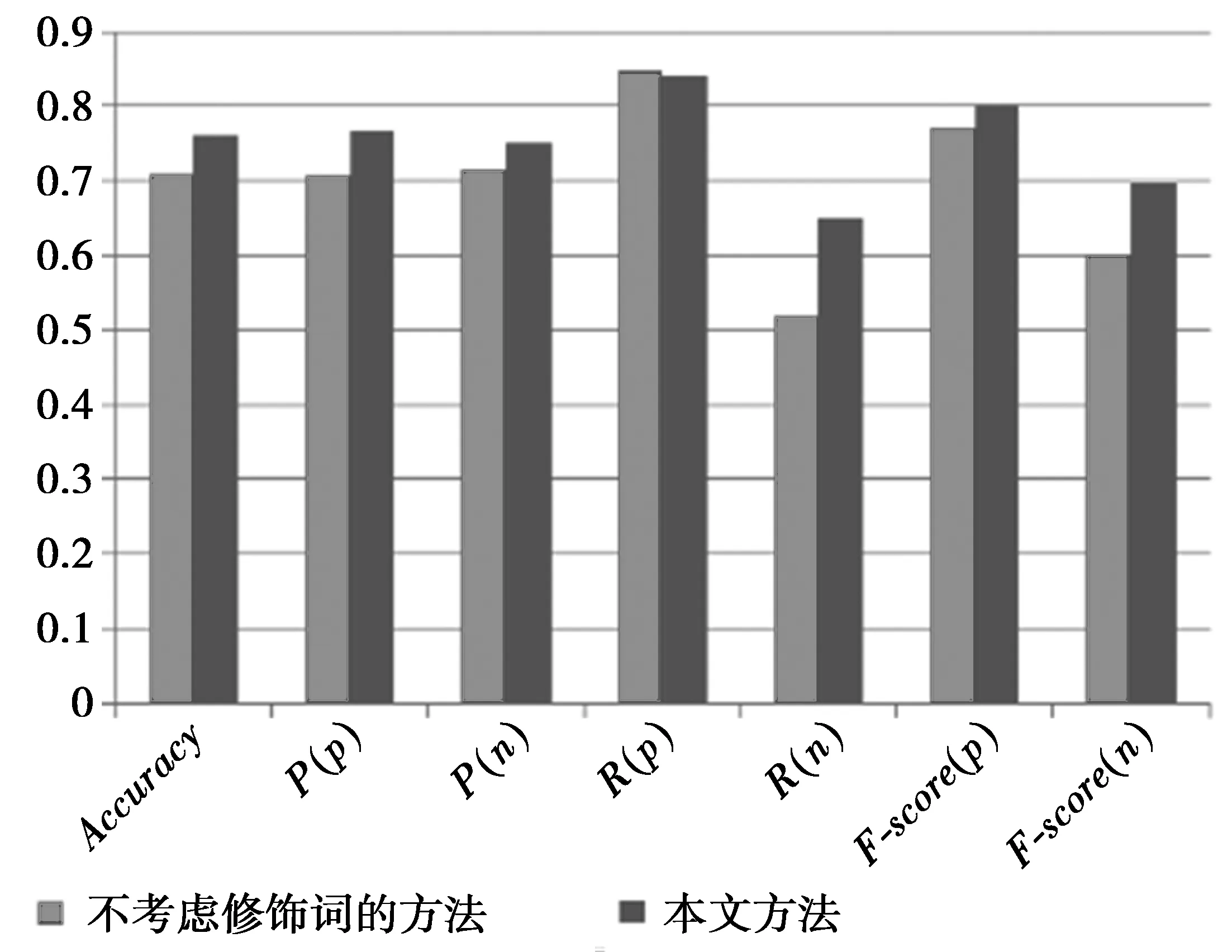
图3 情感倾向分析的性能对比结果Fig.3 Performance comparison of sentiment analysis
对于手机产品特征的情感倾向分析,文献[14]中的评论语句个数为150,为了有相同的比较基础,本文在整体的949条语句中,随机选取了150条语句进行测试并与之比较。将本文提出的方法与其他类似研究方法在性能评价指标上的比较结果如表10所示。
从表10可看出,本文的指标均优于文献[15],这主要是由于文献[15]在建立产品特征和观点词之间的关系时没有考虑到程度副词和否定词对关系的影响。由图3可知,忽略情感词修饰成分会降低情感倾向的准确性。与文献[10]相比较,本文方法的查全率整体优于文献[10],查准率则是本文的贬义句子的查准率较优,而褒义句子略低。文献[10]针对的是英文领域中的产品评论,由于对象不同,两者之间没有绝对的可比性,但从整体上看,本方案的性能接近于英文领域的情感倾向分析研究水平。从整体评估指标准确率看,本文方案略优于文献[14]。文献[14]采用的是机器学习方法,针对每种产品,在使用前都需要使用大量的人工标注样本集进行训练,要达到自动完成评论信息的挖掘还有一定的距离[14]。此外,从运行效率来说,在产品特征提取过程中,本文方案是基于FP-tree算法的,其运行效率远高于文献[14]中采用的基于Apriori的算法。
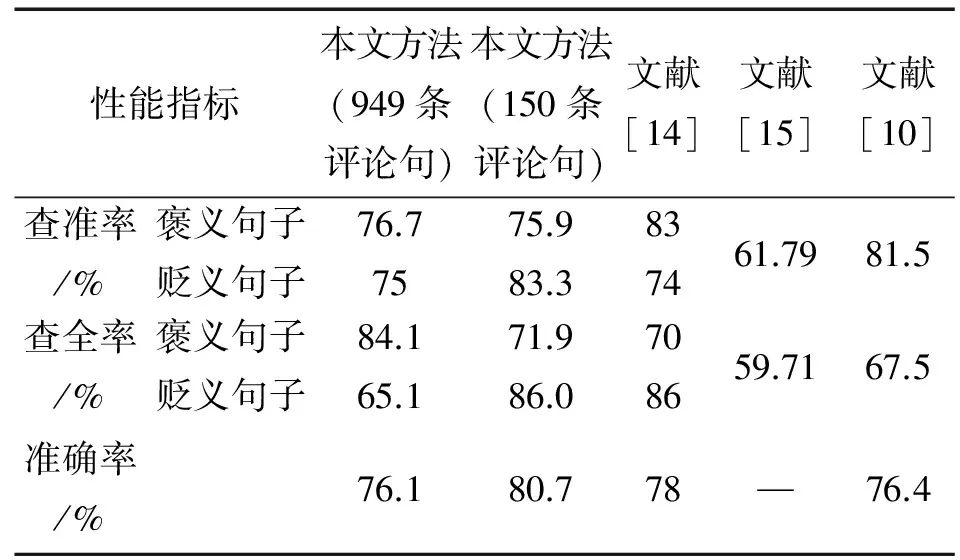
表10 针对手机评论的句子级情感分析结果比较
4 结 语
本文针对中文网络评论中的产品特征的情感倾向分析问题进行了深入的研究。首先,采用基于关联规则的方法抽取产品特征,然后,以句子为单位,提取有关产品特征的主观评论信息,并在计算情感倾向值时综合考虑了情感词、否定词和程度副词对句子情感倾向的影响,提高了情感倾向分析的准确性。最后,以手机评论语料为例,对本文提出的产品特征的情感分析算法进行了实验测试,实验结果表明,该算法具有很好的性能和应用潜力。
[1] QUAN C Q, REN F J. Unsupervised product feature extraction for feature-oriented opinion determination [J]. Information Sciences, 2014, 272(10):16-28.
[2] WANG W, XU X, WAN W. Implicit feature identification via hybrid association rule mining [J]. Expert Systems with Applications, 2013, 40(9):3518-3531.
[3] 李实,叶强,李一军.中文网络客户评论的产品特征挖掘方法研究[J].管理科学学报,2009,12(2):142-152. LI Shi,YE Qiang,LI Yijun,et al.Mining features of products from Chinese customer online reviews[J].Journal of Management Sciences in China,2009,12(2):142-152.
[4] 颜志军,马柏樟.基于潜在狄利特雷分布模型的网络评论产品特征抽取方法[J].计算机集成制造系统, 2014,32(1):96-103. YAN Zhijun, MA Baizhang. Product features extraction of reviews based on LDA model [J]. Computer Integrated Manufacturing Systems, 2014,32 (1):96-103.
[5] MISSEN M M S, BOUGHANEM M, CABANAC G.Opinion mining: reviewed from word to document level[J].Social Network Analysis and Mining,2013,3(1):107-125.
[6] PAN W, ZHOU Y. Chinese Sentiment Orientation Analysis[C]//Computational Intelligence and Security (CIS), 2010 International Conference. Washington, DC, USA:IEEE Computer Society, 2010:1-5.
[7] 叶强,张紫琼,罗振雄.面向互联网评论情感分析的中文主观性自动判别方法研究[J].信息系统学报,2007, 1(1):79-91. YE Qiang, ZHANG Ziqiong, LUO Zhenxiong. Automatically Measuring Subjectivity of Chinese Sentences for Sentiment Analysis to Reviews on Internet[J]. China Journal of Information Systems, 2007,1(1):79-91.
[8] 潘茜,姚天昉.微博汽车领域中用户观点句识别方法的研究[J]. 中文信息学报, 2014,28(5):148-154. PAN Xi, YAO Tianfang. Recongition of Microblog Customer Opinion Sentences in Automobiles Domain [J]. Journal of Chinese Information Processing, 2014, 28(5):148-154.
[9] KM S, HOVY E. Determining the Sentiment of Opinions [C]// Proceedings of the 20th international conference on Computational Linguistics.Stroudsburg,PA,USA:Association for Computational Linguistics,2004:1367-1373.
[10] HU M, LIU B. Mining and summarizing customer reviews[C]//Proceedings of the tenth ACM SIGKDD international conference on Knowledge discovery and data mining. New York, NY, USA: ACM, 2004: 168-177.
[11] 唐晓波,肖璐.基于情感分析的评论挖掘模型研究[J]. 情报理论与实践, 2013, 21(7) :100-104. TANG Xiaobo, XAIO Lu. Research on the Review Mining Model Based on the Sentiment Analysis [J]. Information Studies:Theory & Application,2013,21(7):100-105.
[12] 王晓东,王娟,张征.基于情感词汇本体的主观性句子倾向性计算[J]. 计算机应用,2012, (6) :1678-1681,1684. WANG Xiaodong, WANG Juan, ZHANG Zheng. Computation on orientation for subjective sentence based on sentiment words ontology [J]. Journal of Computer Applications, 2012, 32(6):1678-1681, 1684.
[13] 邱云飞,王雪,邵良杉.基于中文网络客户评论的消费者行为分析方法[J].现代情报, 2012, 32(1): 8-11. QIU Yunfei, WANG Xue, SHAO Liangshan. The Method of Customers’ Behavioral Analysis Based on Chinese Web Clients’ Reviews [J]. Journal of Modern Information, 2012, 32(1): 8-11.
[14] 李实,叶强,李一军,等.挖掘中文网络客户评论的产品特征及情感倾向[J]. 计算机应用研究, 2010, 27(8): 3016-3019. LI Shi, YE Qiang, LI Yijun, et al. Mining product features and sentiment orientation from Chinese customer reviews [J]. Application Research of Computers, 2010, 27(8):3016-3019.
[15] SHI B, CHANG K. Mining Chinese reviews[C]//Data Mining Workshops, 2006. ICDM Workshops 2006. Sixth IEEE International Conference. Washington, DC, USA: IEEE Computer Society, 2006: 585-589.
(编辑:田海江)
Research on sentiment orientation of product feature from Chinese reviews on the internet
WANG Yong1, 2, TAO Yazhi1, ZHANG Qin1
(1.Key Laboratory of Electronic Commerce and Logistics of Chongqing, Chongqing University of Posts and Telecommunications, Chongqing 400065, P.R.China; 2. Computer Engineering Department, San Jose State University, California,USA, 95192)
Data mining in customer reviews of Web is one of the important applications in big data analysis. Extracting semantic orientation on product feature from customer reviews can not only provide customers with more detailed information for purchasing decision, but also help enterprises improve product quality. Aim at the actual requirement of business application, an algorithm of autocratically extracting customers’ semantic orientation on product features from network reviews is proposed. In the proposed algorithm, the product features are obtained based on frequent pattern-tree(FP-tree)method. Then, the subjective review sentences on product features, emotional words and its dependency rules are recognized according to corpus-based approach and dependency parsing method. Finally, the semantic orientation values of product features are calculated by considering the effect of opinion words, negative words, and degree words. The public data set with 600 mobile phone reviews is used to test the performance and validity of the proposed algorithm. Moreover, the comparing results show that the presented algorithm has the high potential to be applied to extract valuable commerce information from network product reviews.
sentiment orientation analysis; product feature; semantic similarity; Web mining; knowledge discovery
10.3979/j.issn.1673-825X.2017.01.012
2016-05-10
2016-10-15 通讯作者:王 永 wangyong_cqupt@163.com
国家自然科学基金(61472464);重庆市前沿与应用基础研究项目(cstc2015jcyjA40025);重庆市社会科学规划管理项目(2015SKZ09);重庆市社科基金(K2015-59);重庆邮电大学社科基金(K2015-10)
Foundation Items:The National Natural Science Foundation of China (61472464);The Chongqing Research Program of Basic Research and Frontier Technology(cstc2015jcyjA40025);The Social Science Planning Foundation of Chongqing(2015SKZ09);The Social Science Foundation of Chongqing(K2015-59);The Social Science Foundation of CQUPT(K2015-10)
TP391.1
A
1673-825X(2017)01-0075-09

王 永(1977-),男,四川自贡人,博士,教授,主要研究方向为Web数据挖掘、知识发现、信息安全与信息管理。E-mail: wangyong_cqupt@163.com。

陶娅芝(1991-),女,重庆人,硕士研究生,研究方向为知识发现、Web数据挖掘。E-mail: tao_yazhi@163.com。

张 勤(1988-),女,河南人,硕士,研究方向为管理信息系统、数据挖掘。E-mail: 1831792821@qq.com。
猜你喜欢
中共云南省委党校学报(2022年1期)2022-04-26
新世纪智能(语文备考)(2020年4期)2020-07-25
小学生优秀作文(低年级)(2020年4期)2020-07-24
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
语言与翻译(2015年1期)2015-07-18
中文信息学报(2015年4期)2015-04-21
语文知识(2014年4期)2014-02-28
武陵学刊(2011年5期)2011-03-20
小雪花·初中高分作文(2009年8期)2009-11-16
