
知识图谱数据管理系统的设计与实现
2017-02-23 12:22王丽娟吴刚
电子技术与软件工程 2016年24期
王丽娟+吴刚
本文在调研考察了多种图数据库的基础上,综合考量了分布式、扩展性、可用性、查询语言、容错性、存储后端、一致性等因素,并充分结合知识图谱数据自身所具有的特点,选取了当前流行的图数据库系统Titan作为底层存储,并对其进行进一步深入的研究,在此基础上实现了一个知识图谱数据管理系统。此系统能对知识图谱数据进行管理,包括数据的导入、数据的查询以及数据的修改,能支持billion数据量的存储,以及图上的基本操作,这些操作响应时间都在秒级。
【关键词】大数据 大图 知识图谱 图数据库
1 绪论
知识图谱是一种知识数据的管理方式,通过语义检索技术获取并有机整合多源数据,用于提高搜索引擎的质量。知识图谱本质上是一种语义网络。其结点代表实体(entity)或者概念(concept),边代表实体/概念之间的各种语义关系。知识图谱在语义搜索、智能问答、知识工程、数据挖掘等领域有着广泛的应用。考虑到知识图谱所具有的大规模、图结构等特点,研究知识图谱数据的高效存储,检索,以及展示等问题具有重要的实际意义和应用价值。
图数据库是一种NoSql数据库。采用图数据库的原因很简单,因为知识图谱具有大规模、图结构等特点。图是关系的子集,它能够转化成关系模型,然而通用的关系模型对将图结构拆分成顶点、边、属性这些表,使得简单的图遍历成为开销巨大的join操作,同时也丢失了图结构的整体性。而图数据库的扩展性和灵活性非常好,适合用于复杂关系管理和关系查询推理。多数图数据库提供了适合表达图结构和图查询的查询语言,有利于对图的遍历查询,而且效率高。图数据库在处理这类数据上具有巨大的优势。
2 相关技术介绍
2.1 RDF简介
资源描述框架是由W3C提出的一种数据模型,已经成为语义网领域存储关联数据的推荐标准。RDF提供了一种用于描述信息、使得信息能够在应用程序间不失语义地交换的通用框架。在RDF框架下,数据被描述成主体(subject)、谓词(predicate)和客体(object)。RDF中的数据可以是资源描述符、文字或是空节点。
2.2 图数据库
本文实现的系统基于图数据库。图数据库使用图结构来存储和查询数据,其基本存储单元是:节点、边(也可以称为关系)、属性。图数据库与关系型数据库的一个明显的区别是使用边来连接各个节点,而不是外键。
2.3 Titan图数据库介绍
Titan是一个分布式的图数据库,支持横向扩展,可容纳数千亿个顶点和边。 Titan支持事务,并且可以支撑上千并发用户和计算复杂图形遍历。
2.4 Gremlin介绍
Titan使用Gremlin作为读取并修改数据的查询语言。Gremlin面向路径,能简单表达图的复杂遍历和转化操作,它是一种把遍历操作和路径描述相结合的功能性语言。它是一种Java DSL语言,对图表进行查询、分析和操作时使用了大量的XPath。
2.5 Cassandra介绍
Cassandra是一套开源分布式NoSQL数据库系统。它最初由Facebook开发,用于储存收件箱等简单格式数据。由于Cassandra良好的可扩展性,被Digg、Twitter等知名Web 2.0网站所采纳,成为了一种流行的分布式结构化数据存储方案。
2.6 Elasticsearch介绍
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口,是当前流行的企业级搜索引擎。设计用于云计算中,能够達到实时搜索,稳定,可靠,快速,安装使用方便。
3 系统详细设计
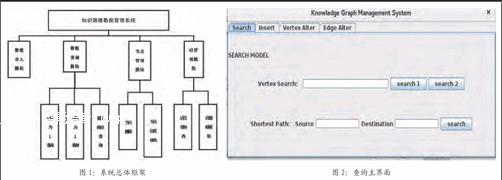
本文实现的知识图谱数据的管理系统,根据需求,主要分为4个模块,分别是:数据导入模块,数据查询模块,节点管理模块,边管理模块。
系统结构图如图1所示。
4 系统实现
限于篇幅,本文只针对主界面和数据查询模块中深度为1的查询做详细介绍。
4.1 主界面的实现
本次设计的界面是用JAVA的Awt和Swing组件来做。用选项卡来做不同的功能界面,一共有4个选项卡。对于每个选项卡本文都写了对应的JPanel类。第1个是实现查询功能的SearchPanel,第2个是实现数据导入功能的InsertPanel,第3个是实现节点修改删除的VertexAlterPanel,第4个是实现边修改删除的EdgeAlterPanel。查询主界面上的三个按钮分别对应了三个查询功能。“search 1”是深度为1的节点查询,对“vertex search”输入框里输入的值进行查询。“search 2”是深度为2的节点查询,对“vertex search”输入框里输入的值进行查询。第三个按钮“search”是最短路径的查询,源节点是“source”输入框里输入的值,目标节点是“destination”输入框里输入的值。界面效果如2所示。
界面效果如下:
4.2 数据查询模块的实现
本模块一共有三个部分:深度为1的查询、深度为2的查询、最短路径查询。
用户把查询条件输入到对应的JTextFedld。从JTextField接收要查询的节点,定义两个JButton,一个的事件处理是深度为1的查询,另一个的事件处理是深度为2的查询。最短路径的查询,是从两个JTextField分别接收源节点和目标节点的值,定义一个JButton,事件处理是查询最短路径。
4.2.1 深度为1的查询
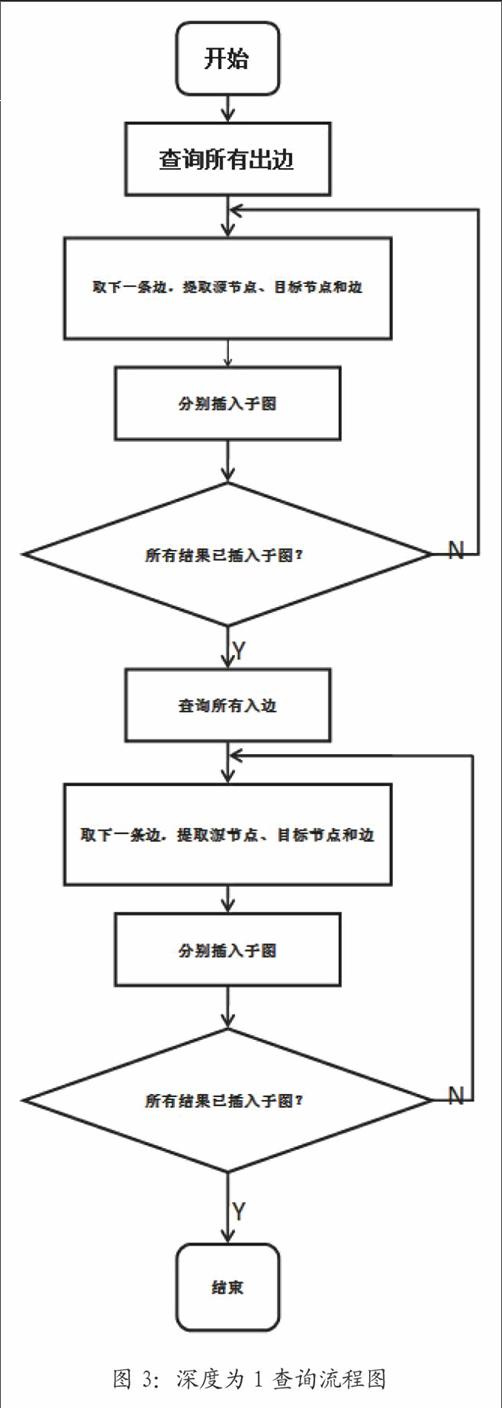
对于深度是1节点查询,在数据库中搜索该节点,得到“节点1--边--节点2”形式的结果集。对于其中的每一个结果,任务是把两个节点和边的信息加入到子图中,从而把子图构建起来以便于返回给用户,具体做法就是分别在子图中查询两个节点,如果子图中没有则添加对应节点,再选出这两个节点,在它们之间查询本文要添加的边,若不存在则添加,反之则不添加。最后将子图返回给用户。流程图如图3所示。
实现深度为1的查询的主类是SearchVertex,类中有个成员org.graphstream.graph.Graphgs;这个就是查询结果的子图。因为Titan中存的是有向图,所以查询需要两次,一次是从出边查,另一次是从入边查。
查询时使用GraphTraversalSource的对象gts,如下面这行利用Gremlin API的代码
Iterator rs=gts.V().has("name",v).as("a").
outE().as("b").inV().as("c").select("a","b","c").by("name");
查询name值为字符串v值的节点的出边及该边的另一个节点,结果提取三个元素的name属性值。最后返回满足查询条件的迭代化结果集rs。从入边查询的代码如下面这行利用Gremlin API的代码所示
Iterator rs=gts.V().has("name",v).as("a").inE().as("b").outV().as("c").
select("a","b","c").by("name");
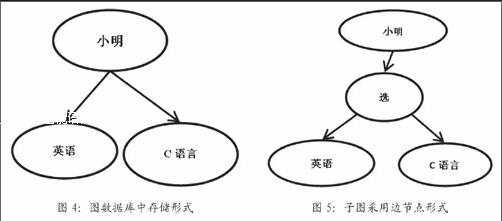
对于结果集中的每一条记录,要把它添加到子图中。从每一条记录中提取源节点值sourcenode、目地节点destinationnode和边节点edgenode。这里需要说明的是边节点的意思。边节点是构建子图时,将源节点和目的节点之间的边也作为一个节点,这个节点两端连着源节点和目的节点。下面用选课的例子来说明。
图4的形式是图数据库中存储的形式,虽然这种形式已经足够简单直观,直接把语义关系表示了出来。但从用户的角度来考虑,如果用户看到的图仍然采用如图4.3的形式,会显得繁琐,因为同一种类型的边存在多条,甚至有时会让用户难以理解,假设上面例子中节点“小明”还有其他的边,比如“住”在“宿舍”等关系,若干种关系同时返回给用户会显得十分混乱。若采用把边转换成边节点的方法更清楚,如图5所示。
有了节点和边,子图的构建模型也有了,具体的插入构建操作也需要相应的查询。对于每一条边,在子图对象中查询源节点和目的节点,没有则添加,如下面这段代码
if(gs.getNode(sourcenode)==null)
{
gs.addNode(sourcenode);
gs.getNode(sourcenode).addAttribute("ui.label",sourcenode);
}
這段代码实现把源节点添加到子图对象gs中,并给这个节点的“ui.label”赋上值,以便子图可视化显示。源节点、边节点同理。
最后插入源节点与边节点、边节点与目的节点之间的边。插入的时候,同样在子图中查询是否存在该边。
这里,本文定义了源节点到边节点的边值是sourcenode+” ”+edgenode的字符串值。边节点到目的节点的边值是edgenode+” ”+destinationnode的字符串值。
下面这段代码向子图插入了源节点到边节点的边。
if(gs.getEdge(sourcenode+" "+edgenode)==null)
{
gs.addEdge(sourcenode+" "+edgenode, sourcenode, edgenode);
}
当rs结果集中所有记录都处理完后,查询结果的子图就构建完了,可以用可视化的方式返回给用户了。
5 结论
本文介绍了知识图谱数据管理系统的设计和实现。重点介绍了界面的实现方法,详细介绍了数据查询模块实现思路及底层代码实现方法。
本文使用的图数据库是Titan,而Titan使用的查询语言是Gremlin。Tinkerpop3的Gremlin和JAVA配合得相当好,JAVA类中的查询API几乎和gremlin shell中的查询语句一致,非常有利于开发人员使用。
参考文献
[1]Zhou XF, Lu JH, Li CP, Du XY. The challenges of big data from the perspective of data management[J]. Communications of the China Computer Federation, 2012, 8(9):16-21.
[2]谷峪,于戈,鲍玉斌.大规模图数据的分布式处理[M].北京:清华大学出版社, 2015.
[3]Robinson I, Webber J, Eifrem E.图数据库[M].北京:人民邮电出版社,2015.
[4]Bollacker K,Cook R,Tufts P. Freebase: A Shared Database of Structured General Human Knowledge[C]// AAAI Conference on Artificial Intelligence.2007:1962-1963.
[5]Angles R, Gutierrez C. Survey of graph Database models[J].Acm Computing Surveys,2009,40(01):178-187.
[6]Han J, Haihong E, Le G, et al. Survey on NoSQLDatabase[C]// Pervasive Computing and Applications (ICPCA), 2011 6th International Conference on. IEEE,2011:363-366.
[7]Angles R. A Comparison of Current Graph Database Models[C]. In Proceedings of the 2012 IEEE International Conference on Data Engineering Workshops (ICDEW 2012), 2012:171-177.
[8]McColl R,Ediger D,Poovey J,Campbell D,et al. A Performance Evaluation of Open Source Graph Databases[C]. In Proceedings of the 2014 Workshop on Parallel Programming for Analytics Applications,2014:11-17.
[9]项灵辉,顾进广,吴钢.基于图数据库的RDF数据分布式存储[J].计算机应用与软件,2014,31(11):35-39.
[10]g Broekstra J, Kampman A, Jarmelen F. Sesame: A generic architecture for storing and querying RDF and RDF schema[C].In Proceedings of the first International Semantic Web Conference(ISWC 2002),2002:54-68.
[11]Vukotic A,Watt N, Partner J,et al. Neo4j in Action[M].New York: Manning Publications,2014.
[12]Apache Cassandra[EB/OL].http://cassandra.apache.org,2016.5.31.
[13]Elasticsearch[EB/OL].http://www.elastic.co/products/elasticsearch,2016.5.31.
[14]ThinkaureliusTitan[EB/OL].http://titan.thinkaurelius.com/,2016.5.31.
[15]TitanDocumentation[EB/OL].http://s3.thinkaurelius.com/docs/titan/1.0.0/,2016.5.31.
作者簡介
王丽娟(1981-),女,江苏省赣榆市人。东北大学硕士。现为徐州工业职业技术学院讲师。研究方向为数据库技术。
作者单位
1.徐州工业职业技术学院 江苏省徐州市 221114
2.东北大学 辽宁省沈阳市 110819
猜你喜欢
小小艺术家(2018年8期)2018-10-11
小朋友·快乐手工(2018年7期)2018-08-15
中国教育信息化·基础教育(2016年9期)2016-10-18
