
CryptDB密文数据库系统并行方案研究
2017-02-22 08:01张成果
计算机技术与发展 2017年2期
王 伟,杨 庚,张成果
(南京邮电大学 计算机学院,江苏 南京 210003)
CryptDB密文数据库系统并行方案研究
王 伟,杨 庚,张成果
(南京邮电大学 计算机学院,江苏 南京 210003)
加密数据库对隐私数据的加密存储保护是解决当前互联网中用户隐私数据泄露的一种可行方案。鉴于互联网中每日产生的用户隐私数据规模巨大,传统的串行计算会导致隐私数据的加密存储时间消耗较长。为提高加密存储等数据处理的速度,将MapReduce并行框架与CryptDB密文数据库系统进行有机结合,设计并实现了CryptDB密文数据库系统并行加密和分布式存储的方案。并行方案采用任务调度算法、文件分割算法来提高其并行性和可控性,通过重写MapReduce框架中的Map方法来实现CryptDB密文数据库系统的并行加密和分布式存储。基于由1个Master节点、3个CryptDB节点和3个MySQL服务器构成的实验平台,进行了并行方案的实验验证及其性能分析。实验结果表明,所构建的并行方案在3个CryptDB节点集群中的加速比可达到2.51,加密和存储时间节省了60.2%,可用于大规模关系数据的加密存储。
加密数据库;MapReduce;CryptDB系统;并行加密;分布式存储
0 引 言
随着互联网的普及和互联网技术的高速发展,网络数据库安全成为了新兴的研究领域。计算机安全研究所(CSI)和FBI统计发现,平均每年有超过70%的用户曾遭受过网络攻击。这表明,传统的防火墙技术已经无法保证网络数据库的绝对安全。攻击者可以利用网络应用的安全漏洞窃取用户的隐私数据,对数据好奇的数据库管理员也会对用户隐私数据造成泄漏的风险。因此,如何设计并实现可检索的加密方案并运用到传统的数据库中,以加密用户隐私数据并支持在密文上进行SQL操作,成为了目前亟需解决的问题。
1995年,Benny Chor等提出了私有信息检索的概念,并在不泄露检索信息的前提下,实现从数据库中检索到用户所需的信息[1]。2000年,D.Song等提出一种可检索的对称加密方案(SSE)[2],开创了在不解密的情况下查询密文的先例,具有很高的实用性。在此之后,可检索加密机制进展迅速,并且支持对密文数据进行多关键词和模糊关键词搜索[3-6]。2004年,D.Boneh等提出了真正意义上的可搜索公钥加密方案(PEKS),为此业界把2004年定义为可搜索公钥加密的元年[7]。另外,可检索加密机制不但在理论上有了多样化的发展,许多研究者也将它们应用到了实际的场景之中。例如,MIT计算机科学和人工智能实验室(CSAIL)研发了一个加密数据库系统CryptDB[8]。该数据库系统允许用户查询加密的SQL数据库,而且能在无需解密储存信息的情况下返回结果。由于CryptDB系统采用了多层加密的洋葱加密方案来加密数据,并把数据加密成多份以适用于多种检索场景,当数据规模巨大时,其加密存储对服务器的运算和存储开销是巨大的。为了解决大规模数据加密时间开销巨大的问题,Kamara等在2013年提出了并行同态加密方案[9]。该方案支持通过评估算法对加密数据进行并行处理;并且研究了在MapReduce并行计算模型下的各种操作,包括关键词检索。2015年,F Wang 等提出了使用Hadoop集群对明文数据库中已存在的数据进行并行加密并存储的方案,适用于企业级大型数据库中明文数据加密成密文存储的场景,相比于单一服务器时间开销更小[10]。
文中以CryptDB系统的加密存储过程为出发点,利用云计算MapReduce框架对海量数据运算高效的特点,设计并实现了基于任务并行的CryptDB系统优化方案,实现了对大规模隐私数据进行高效加密及存储的处理。该方案对DML/DDL语句进行分组,然后把每组操作分发到部署有CryptDB系统的节点上,并对其进行加密计算并存储,以达到缩短加密及存储时间的目的。
1 并行方案设计
1.1 CryptDB密文数据库系统
CryptDB[8]是一个密文数据库系统,它在可信的MySQL-Prxoy代理服务器端对明文SQL语句进行拦截,之后对隐私字段进行加密,随后将改写后的SQL语句提交到不可信的MySQL服务器端执行存储以实现对隐私数据的保护。CryptDB系统可直接对密文数据进行SQL操作。实现该操作的核心是三个创新的方案[11]:
(1)利用支持SQL的加密策略将SQL操作映射到加密框架中;
(2)可调整的加密方案使得可以根据用户的查询语句来调整数据的加密等级;
(3)洋葱加密方案可以高效地调整数据的加密等级。
1.2 并行方案模型
为了保证数据的安全性及密文的可检索,CryptDB系统利用多个洋葱模型对数据进行加密。因此利用CryptDB密文数据库系统对隐私数据进行加密存储的计算开销是巨大的。文中提出基于MapReduce计算框架的CryptDB系统任务并行方案,结合云计算环境的特性与CryptDB密文数据库系统的特点,将巨大的计算任务分发到各个部署有CryptDB系统的节点上进行计算并提交到对应的MySQL服务器上存储,方案中负责任务调度的主节点和负责加密的CryptDB节点都是可信服务器,因此不会造成明文的泄漏。并行方案如图1所示。
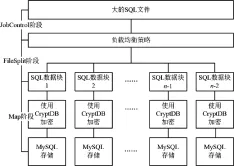
图1 任务并行方案
MapReduce的编程模型一般包含三个重要的组成部分:分片、map阶段和reduce阶段。首先,该方案根据负载均衡策略将大的SQL指令分割成多个分块;ResourceManager根据MapReduce框架的调度机制将各个分块分发到相应的CryptDB节点上,并启动mapper对分块中的明文SQL进行字段提取;最后调用CryptDB系统对数据进行加密。加密后的密文SQL将提交到MySQL服务器端执行。由于方案中每个CryptDB节点都对应一台MySQL服务器,并且加密后的SQL仍为标准的SQL语句,可直接被MySQL解析。提交到MySQL服务器执行后,数据将直接以密文形式存储在MySQL数据库中。因此方案中不需对数据进行Reduce操作。
1.3 任务分配算法
该方案中的并行策略是基于任务的分割,考虑到每个节点的计算能力不同,若将任务平均分配,计算能力较弱的节点完成任务的时间会较长,得不到最优解。方案中提出了任务分配算法,该算法致力于在任务并行阶段提高并行度,得到较优的map时间。
算法1:任务分配算法。
输入:节点个数m,SQL语句的条数N;
输出:每个节点的任务规模Xm。
(1)输入参数为集群中CryptDB节点的个数m,以及待加密的任务规模即SQL语句的条数N。
(2)随机生成n条与待加密SQL语句属性个数及类型相同的测试SQL语句。
(3)将测试SQL语句通过JDBC分发到m个CryptDB节点上进行加密存储,得到时间开销tm。
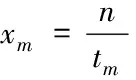
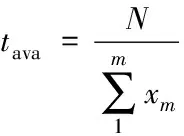
(6)分别用最优的map时间乘以各节点计算能力,得到每个节点应分配到的任务规模Xm=tava·xm。
说明:
(1)该算法不会影响整个方案的效率。第2步中的参数n为预先设定的一个常量(n≪N)。因此该算法时间开销相对于之后的加密存储操作而言,可以忽略不计。
(2)该算法应用于JobControl阶段,产生任务分配的策略,以提高方案的整体性能。
(3)该算法在每次执行任务前都会被执行,以根据实时计算能力产生分配策略。
1.4 文件分割算法
由于集群中有m个节点,所以文中方案加入文件分割算法,根据每个节点的计算能力,将大的SQL文件分割成相应大小的SQL文件,并按相应的编号命名文件块。map阶段,每个mapper会根据文件名处理对应的文件。
算法2:文件分割算法。
输入:大的SQL文件;
输出:分割后小的SQL文件。
(1)将大的SQL文件读到内存中。
(2)从文件的起始位置开始,按行读取SQL语句,保存到temp变量中。
(3)当累加器的SQL语句达到当前节点所需规模时,将temp中的内容保存到HDFS文件系统中,并以节点编号命名。
MapReduce框架中的InputFormat算法是将大的文件分割成对应的文件块,分配给相应的mapper处理。文中提出的文件分割算法有别于InputFormat算法,将大的文件以小的文件格式保存在HDFS文件系统中。该算法使得mapper根据文件名处理相对应规模的小任务文件,而不是MapReduce框架中的随机分配任务。提高了并行方案的可控性,有利于提高方案的并行度。
1.5 Map函数
算法3:Map。
输入:文件路径、容器大小、节点个数。
(1)从HDFS中获取待处理文件的文件名,即节点的编号,该文件的文件名由算法2给出。
(2)根据编号从properties文件中读取节点的地址等信息,将该文件分发到对应的CryptDB节点进行解析处理。
(3)CryptDB节点接收到待处理的SQL文件后,首先读取文件内容,然后对SQL语句中的关键词进行处理,提取出待加密的属性值。
(4)将提取出的属性值根据预先设定的容器大小进行拼接,构建成新的标准SQL语句。
(5)通过JDBC调用CryptDB密文数据库系统,执行SQL语句,加密并存储数据。
说明:
实践教学是学生掌握知识的重要渠道,是学生把所学的理论知识转化为实际技能的重要途径,也是培养学生创新能力的源泉;也是拓展学生职业能力的根本途径,同时还是展现学生个性化的舞台。
(1)该算法第2步提到的properties文件为构建CryptDB集群时所记录的配置信息,所包含的内容为节点编号及IP地址。
(2)该算法第4步中提到的容器大小为新建MapReduce任务时给出的值,该值应小于CryptDB密文数据库系统单次所能处理SQL的最大属性值个数。
2 并行方案性能分析
2.1 串行性能分析
文中首先讨论CryptDB系统INSERT操作的串行执行时间。CryptDB系统INSERT操作可以看成三个部分:第一部分是查询元数据表,第二部分是对数据进行加密,第三部分是将加密后的数据插入到MySQL数据库。设这三个部分的时间分别为Tmeta、Tenc、Tinsert,如式(1)所示。
Ts=Tmeta+Tenc+Tinsert
(1)
CryptDB系统中任何类型的数据都利用“等值洋葱”和“保序洋葱”进行加密[12],数值型数据还会利用“HOM洋葱”加密,字符型数据会利用“SEARCH洋葱”加密。其中,等值洋葱中分别对数据使用了DETJOIN算法、DET算法和RND算法进行加密。保序洋葱使用了OPE算法和RND算法对数据进行加密。HOM洋葱使用同态算法加密。SEARCH洋葱使用了SEARCH算法进行加密[13]。
对于数值型的数据,RND采用的是添加初始化向量IV的Blowfish算法,DET采用的是Blowfish加密算法,DETJOIN采用的是基于ECC(椭圆加密)的ECJoin算法。对于字符型数据,RND采用的是带初始化向量IV(即salt值)的CBC模式的AES加密算法,它能保证密文加密的随机性,即相同的明文加密后密文可能不相同;DET采用的是初始向量相同的CMC模式(即初始化向量都为“0”的CBC模式)AES加密算法,所以相同的明文加密后能得到相同的密文;OPE采用的是mOPE加密算法;HOM采用的Paillier加密算法;SEARCH采用的SWPSearch加密算法。设Blowfish加密算法Blowfish、AES、ECJoin、mOPE、HOM的复杂度分别为Rblowfish、Raes、Recjoin、Rmope、Rpaillier。由于CryptDB系统的代码中没有实现OPEJOIN算法和SEARCH洋葱,所以不进行讨论。并且由于CryptDB使用的加密算法明文在加密前都会进行填充操作,所以输入和输出的规模都是定长。对于数值型的数据,“等值洋葱”的复杂度为:
UoEq_int=Recjoin+2·Rblowfish
(2)
“保序洋葱”的复杂度为:
UoOrder_int=Rmope+Rblowfish
(3)
“HOM洋葱”的复杂度为:
UoAdd=ReAdd
(4)
对于字符型数据,“等值洋葱”的复杂度为:
UoEq_str=Recjoin+2·Raes
(5)
保序洋葱的复杂度为:
UoOrder_str=Rmope+Raes
(6)
由式(2)~(4)可知,加密一个数值型的数据的复杂度为:
Uint=UoEq_int+UoOrder_int+UoAdd= Recjoin+3·Rblowfish+Rmope+Rpaillier
(7)
由式(5)、式(6)可知,加密一个字符型数据的复杂度为:
Ustr=UoEq_str+UoOrder_str= Recjoin+3·Raes+Rmope
(8)
设待加密字段有a个数值型数据和b个字符型数据,则:
Uenc=a·Uint+b·Ustr=(a+b)· (Recjoin+Rmope)+3a·Rblowfish+(a+4b)· Raes+a·Rpaillier
(9)
由文献[14]可知,ECJoin的椭圆计算和mOPE编码的复杂度都为O(logn)。由文献[15-16]可知,AES、Blowfish、Paillier的复杂度为O(n)。ECJoin中除了椭圆计算外还会使用AES对明文进行编码,因此ECJoin的复杂度为O(n+logn)。mOPE编码后还会使用DET对B树的叶子进行加密,所以mOPE的复杂度也为O(n+logn)。由于当n>0时,n>logn,因此n+logn<2n。所以ECJoin、mOPE的复杂度都可表示为O(n)。因此可设Recjoin、Rblowfish、Rmope、Rpaillier分别为Raes的α1,α2,α3,α4倍,即:
Uenc=(a+b)·(α1+3α2+2α3+α4+3)Raes
(10)
设查询元数据表的时间和插入MySQL数据库的复杂度分别为δ次和ε次浮点计算,设浮点计算的时间为Tfc,则:
(11)
因此,由式(1)、式(9)、式(10)得:
Ts=(Uenc+δ+ε)·Tfc
(12)
2.2 并行性能分析
设共有p个CryptDB节点处理包含a个数值型数据和b个字符型数据的SQL文件。该SQL文件被分割成了p个数据块,对应p个mapper。则每个分块中包含a/p个数值型数据和b/p个字符型数据。
因为CryptDB系统并行化方案没有Reduce阶段,所以只讨论map部分。设Map算法的复杂度为M,则得到:
M=(Uenc+ε)/p+δ
(13)
在map阶段,每个mapper开始前和结束后都会和ResourceManager进行通信。又因为数据被分割成了p块,所以至少有2p次通信。设通信耗时为:
Ttr=ζ·p·Tfc
(14)
则并行时间为:
Tp=M·Tfc+Ttr
(15)
则加速比可表示为:
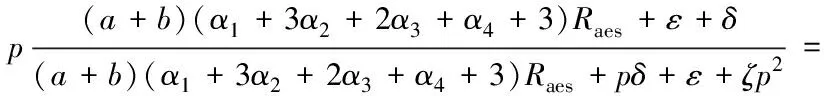
(16)
实际工程应用中,CryptDB节点数远小于待加密的数据的规模,即p≪a+b,此时通信时间可以忽略不计,即ζ→0。由于加密数据规模较大时,查询元数据表的时间相对于加密时间可忽略不计,即δ→0。由式(16)可知,加速比理想值为p。
3 实 验
3.1 实验环境
实验的硬件平台包括1个Master节点和3个CryptDB节点及3个MySQL服务器。Master节点负责工作的监控和调度,CryptDB节点负责密文计算,MySQL服务器负责执行密文SQL并存储的任务,其配置均为:
CPU:Intel(R) Xeon E3-1225 v3, 3.2 GHz/8 M Cache;
Memory:16 GB (2x8 GB) 1 333 MHz Dual Ranked RDIM;
Disk:1 TB 3.5-inch 7.2 K RPM SATA II Hard Drive。
软件平台为:Ubuntu 12.04,Java 1.7.0,Hadoop版本为Hadoop-2.5.2,CryptDB为2015年3月下载版本。
3.2 CryptDB并行方案INSERT性能
实验的数据集为随机生成的SQL文件。测试文件所含的SQL语句条数为1 000~10 000,间隔为1 000,共十个文件。每条数据有五个数值型字段和五个字符型字段。实验中,当mapper的个数为1时,为串行时间。当mapper的个数为n时,表示SQL文件被分割成了n个数据分块,对应n个CryptDB节点,即n个CryptDB节点计算并行时间。
文中用相同的测试数据在原生的CryptDB系统中进行实验,并记录了不同规模的测试数据插入操作的总时间、系统吞吐量、方案的加速比以及方案的效率(加速比/节点个数)。结果如表1和图2所示。
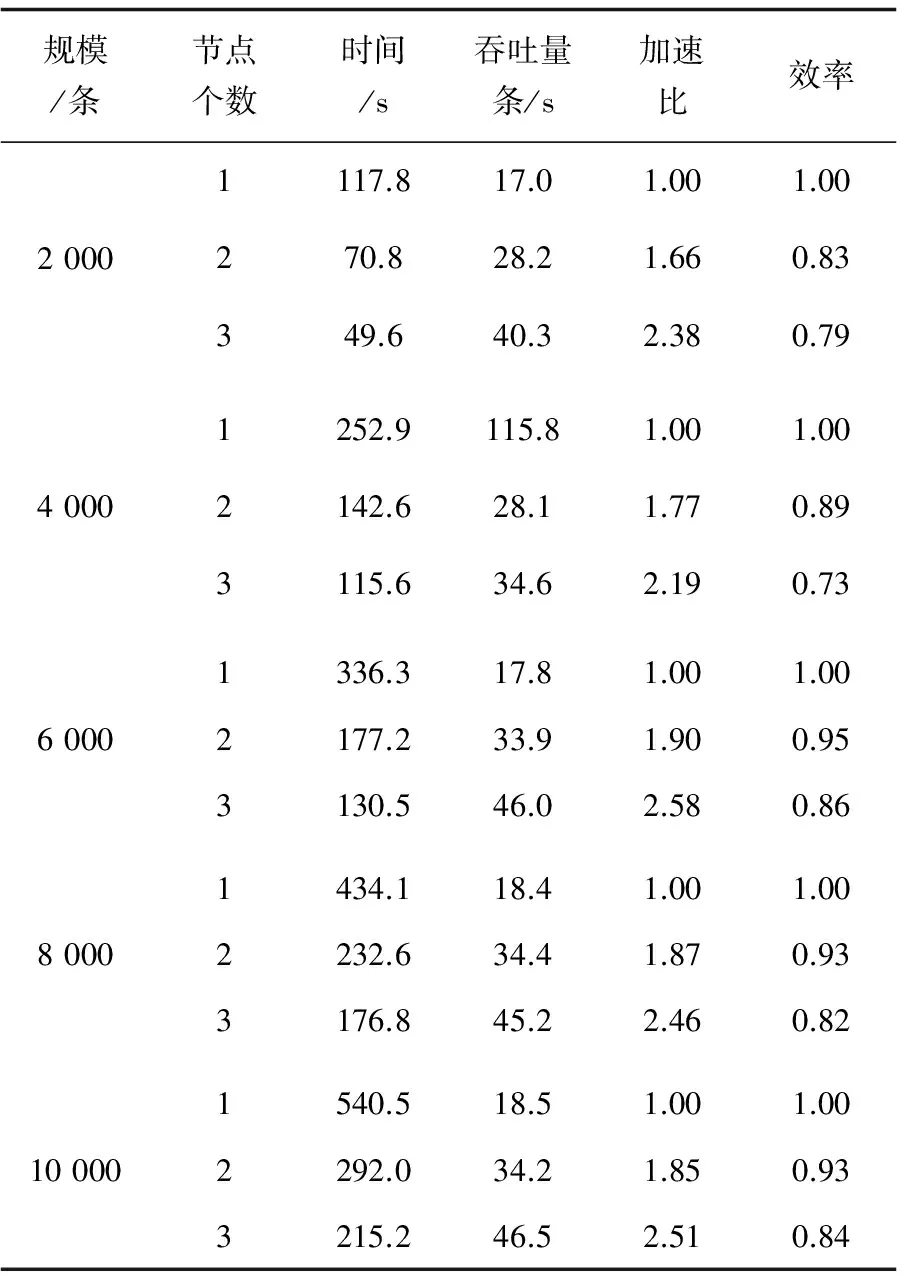
表1 部分实验结果
从表1的数据和图2中的曲线变化趋势可以得出:
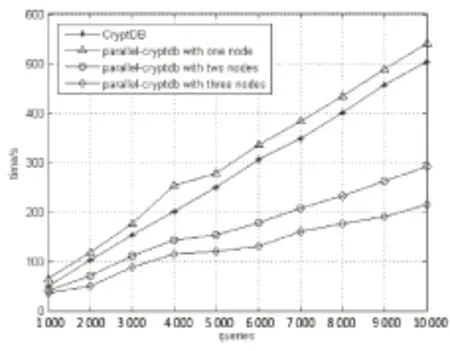
图2 INSERT操作时间
(1)对于相同规模的SQL语句,CryptDB系统的执行时间比CryptDB并行方案单节点执行时间短。这是由于Hadoop并行框架中有任务调度和通信时间开销。
(2)随着CryptDB节点个数的增加,算法的总耗时呈下降趋势。这是由于集群的计算能力会随着节点个数的增加而增大。加速比和效率总体呈上升趋势,这是由于当数据规模足够大时,算法中对数据的加密时间占主导地位。通信的耗时在整体时间中可以忽略不计,所以加速比和效率都会逼近理想值。算法的加速比在最好的情况下,接近于CryptDB节点个数p,与理论分析相符。并行方案的吞吐量随着节点个数增加接近于比例上升。这是由于在任务的分配阶段,使用了任务调度算法。该算法会根据集群中计算节点的计算能力动态分配任务,使得所有参与计算的节点不会存在闲置或等待的情况,表明了该方案有较高的并行度。
3.3 CryptDB并行方案空间性能
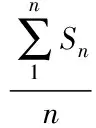
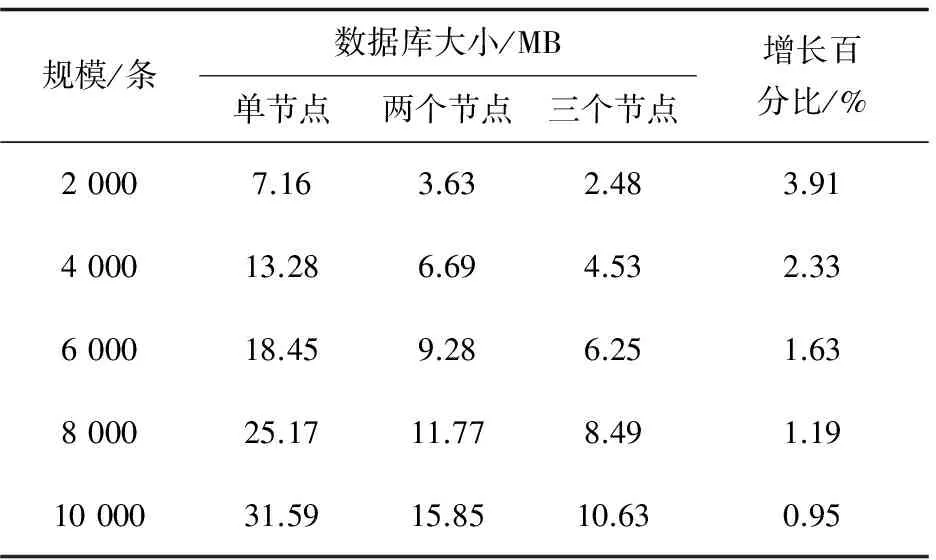
表2 数据库大小
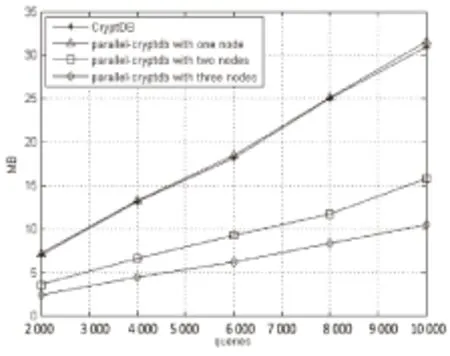
图3 数据库文件平均大小
图3和表2反应的是:集群中平均每个CryptDB节点上的加密数据库文件所占的空间随着节点个数改变的变化趋势。并行方案单节点数据库文件大小接近于CryptDB的数据库文件大小。这表明该并行方案不会造成额外的空间开销。变化趋势表明,每个节点上的数据库平均大小接近于比例下降,当插入数据规模较大时,数据库的增长百分比接近于零。这是由于该并行方案中仅在每个数据库节点中冗余了表信息及部分索引信息,并且随着数据库插入内容规模的增大,该部分信息所占的存储空间的比例呈下降趋势。结论表明,该方案达到了分布存储的目的,数据规模较大时,对减小服务器的存储压力具有重要意义。
4 结束语
提出并实现了一种基于MapReduce框架的并行CryptDB加密数据库系统加密存储的并行方案。实验结果表明,该方案能够提高大规模关系数据库数据的加密和存储速度。方案中设计并实现了任务调度算法以产生任务分配策略,并对SQL文件按照产生的分配策略进行分割以提高方案的并行度。在SQL语句预处理、加密并存储的过程中,充分利用了MapReduce框架的并行性,提高了CryptDB加密数据库系统对于大规模数据加密并存储的效率。方案整体的加速比接近于CryptDB节点个数p。和传统单节点加密数据库相比,每个CryptDB节点上的数据库大小和节点个数成反比,即在每个CryptDB计算能力相同的理想环境下,数据库大小为单节点的1/p。当数据规模较大时,对减小服务器存储压力有着重要意义。
未来的工作重点是:将任务调度方案调整为任务执行过程中动态实时分配;设计并实现其他SQL操作的并行化方案。
[1]ChorB,GoldreichO,KushilevitzE,etal.Privateinformationretrieval[J].JournaloftheACM,1998,45(6):965-981.
[2]SongDX,WagnerD,PerrigA.Practicaltechniquesforsearchesonencrypteddata[C]//ProceedingoftheIEEEsymposiumonsecurityandprivacy.[s.l.]:IEEE,2000:44-55.
[3]XiaZH,WangXH,SunXM,etal.Asecureanddynamicmulti-keywordrankedsearchschemeoverencryptedclouddata[J].IEEETransactionsonParallel&DistributedSystems,2016,27(2):340-352.
[4]SunW,WangB,CaoN,etal.Verifiableprivacy-preservingmulti-keywordtextsearchinthecloudsupportingsimilarity-basedranking[J].IEEETransactionsonParallel&DistributedSystems,2014,25(11):3025-3035.
[5]LiJ,WangQ,WangC,etal.Fuzzykeywordsearchoverencrypteddataincloudcomputing[C]//Internationalconferenceoncomputercommunications.[s.l.]:[s.n.],2010:1-5.
[6]CaoN,WangC,LiM,etal.Privacy-preservingmulti-keywordrankedsearchoverencryptedclouddata[J].IEEETransactionsonParallel&DistributedSystems,2011,25(1):829-837.
[7]BonehD,CrescenzoG,OstrovskyR,etal.Publickeyencryptionwithkeywordsearch[C]//ProceedingsoftheEUROCRYPT.Berlin:Springer-Verlag,2004:506-522.
[8]RalucaA,PopaN,ZeldovichH,etal.CryptDB:apracticalencryptedrelationalDBMS[R].Cambridge,MA:ComputerScienceandArtificialIntelligenceLaboratory,2011.
[9]KamaraS,RaykoyaM.Parallelhomomorphicencryption[M].Berlin:Springer-Verlag,2013:213-225.
[10]WangF,MathiasK,AndreasS.InitialencryptionoflargesearchabledatasetsusingHadoop[C]//Proceedingsofthe20thACMsymposiumonaccesscontrolmodelsandtechnologies.[s.l.]:ACM,2015:165-168.
[11]TuS,KaashoekMF,MaddenS,etal.Processinganalyticalqueriesoverencrypteddata[J].ProceedingsoftheVLDBEndowment,2013,6(5):289-300.
[12]PopaRA,LiFH,ZeldovichN.Anideal-securityprotocolfororder-preservingencoding[C]//ProceedingoftheIEEEsymposiumonsecurityandprivacy.[s.l.]:IEEE,2013:463-477.
[13]PopaRA,RedfieldCMS,ZeldovichN,etal.CryptDB:protectingconfidentialitywithencryptedqueryprocessing[C]//ProceedingoftheSOSP.[s.l.]:[s.n.],2011:85-100.
[14]PopaRA,ZeldovichN.CryptographictreatmentofCryptDB'sadjustablejoin[R].Cambridge,MA:ComputerScienceandArtificialIntelligenceLaboratory,2012.
[15]MartinL.XTS:amodeofAESforencryptingharddisks[J].IEEESecurity&Privacy,2010,8(3):68-69.
[16]BrakerskiZ,VaikuntanathanV.Efficientfullyhomomorphicencryptionfrom(standard)LWE[J].SIAMJournalonComputing,2014,43(2):831-871.
Investigation on Parallel Scheme of CryptDB Encrypted Database System
WANG Wei,YANG Geng,ZHANG Cheng-guo
(College of Computer Science,Nanjing University of Posts and Telecommunications, Nanjing 210003,China)
Encrypting data with encrypted DBMS is a feasible way to protect privacy of customer’s sensitive data on the Internet.Due to the massive privacy data generated by Internet every day,the traditional serial calculation can lead to longer time consumption of encrypted storage of privacy data.Combined the characteristic of MapReduce and CryptDB,a parallel insert and distributed storage scheme is designed and realized to improve the accelerate the speed of encrypting.Another two algorithms named JobControl and FileSplit are also proposed to improve the parallelism and controllability of this scheme.Map method in MapReduce is rewritten to achieve the parallel encryption and distributed storage of CryptDB system.After doing the experiments and performance analysis on the platform consists of 1 Master node and 3 CryptBD nodes and 3 MySQL server nodes,the experimental results show that the speed-up radio of this proposed scheme can reach 2.51,and the total time cost of CyrptDB parallel scheme can be reduced to 39.8% on the cluster consisting of 3 CyrptDB nodes.It can be used into the encryption and storage of large-scale relational data.
encrypted DBMS;MapReduce;CryptDB system;parallel encryption;distributed storage
2016-04-11
2016-08-05
时间:2017-01-10
国家自然科学基金资助项目(61272084,61572263)
王 伟(1992-),男,硕士研究生,研究方向为加密数据库、并行计算;杨 庚,博士,教授,博士生导师,CCF高级会员,研究方向为网络与信息安全、分布与并行计算、大数据隐私保护。
http://www.cnki.net/kcms/detail/61.1450.TP.20170110.1019.060.html
TP31
A
1673-629X(2017)02-0090-06
10.3969/j.issn.1673-629X.2017.02.021
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机仿真(2021年10期)2021-11-19
密码学报(2021年4期)2021-09-14
南京邮电大学学报(自然科学版)(2021年6期)2021-02-24
成都信息工程大学学报(2021年6期)2021-02-12
新世纪智能(语文备考)(2020年4期)2020-07-25
沈阳工业大学学报(2020年2期)2020-04-11
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
小学生·多元智能大王(2014年6期)2014-07-09
