
交互式数据探索综述*
2017-02-20 10:47王蒙湘李芳芳
计算机与生活 2017年2期
王蒙湘,李芳芳,谷 峪,于 戈
东北大学 计算机科学与工程学院 计算机科学系,沈阳 110819
交互式数据探索综述*
王蒙湘,李芳芳,谷 峪,于 戈+
东北大学 计算机科学与工程学院 计算机科学系,沈阳 110819
大规模数据集已经超过TB和PB级,现有的技术可以收集和存储大量的信息。虽然数据库管理系统一直在不断提高提供复杂的多种数据管理的能力,但是管理查询工具并不能满足大数据的需求,如何精准理解和探索这些大规模数据集仍然是一个巨大的挑战。交互式数据探索(interactive data exploration,IDE)的关注点是强调交互、探索和发现,能让用户从海量的数据中用最小的代价更精确地找到他们需要的信息。首先对交互式数据探索及其应用背景进行了介绍,总结了通用的探索模型和IDE的特点,分析了交互式数据探索中的查询推荐技术和查询结果优化技术的现状;随后分别对IDE原型系统进行了分析和比较;最后给出了关于交互式数据探索技术的总结和展望。
交互式数据探索;查询推荐;查询结果优化;用户反馈;机器学习
1 引言
目前,随着大数据研究的兴起,数据探索这种探索数据价值的方式,引起了人们的关注[1]。数据探索在某些领域也被称为探索式搜索。2014年,数据库领域顶级会议SIGMOD针对数据探索举办了首次研讨会[2],相关专家从多个角度对数据探索的重要性和必要性进行了讨论。而交互式数据探索(interactive data exploration,IDE)目前还没有统一的定义。通常来说,交互式数据探索是指用户在不十分明确自己查询输入的前提下,系统通过列举样例、协同过滤、机器学习等技术和方式与用户进行交互和反馈,从而逐渐接近用户的真实查询意图,最终提供给用户与其查询意图最匹配的查询结果或返回相应的查询语句。IDE的应用已经涉及到科学计算、财务分析、循证医学和基因组学等领域[2],并且有效的IDE会以前所未有的速度增加数据的采集。IDE在根本上是应对一个不精确的最终目标的多步骤、非线性的过程。例如,在数据驱动的科学发现过程中,常常需要非专业用户通过IDE迭代地与系统进行交互,从非确定形式的数据集中确定用户感兴趣的模式。如果要充分利用复杂大型数据集,用户将需要一个“专家助理”,能够有效地引导用户浏览数据空间。
交互式数据探索[3]是一组多样的发现式应用程序的关键因素。在这些应用程序中,数据发现是一个非常特别的交互过程,其交互式性能应该支持在线查询处理,这是不断更新分析和探索的关键。帮助用户在数据空间进行简单的导航,允许用户很容易地表达出形式化的探索查询序列,即:自动生成“查询会话”,查询会话很少来自用户的输入或提供建议,甚至用户无需精确表达自己的兴趣数据,便可以利用用户的兴趣、目标,并与数据库交互后,生成模型,显示用户感兴趣的部分数据。IDE可以很容易地成为高度劳动资源密集型的过程。因此,需要一种支持这些用户参与的应用程序,来帮助他们在数据中导航,找到用户感兴趣的对象。
2 交互式数据探索概述
交互式数据探索系统的模型如图1所示。首先,给定一个数据库D,在数据库中提取包含m个样本的初始数据集S(x1,x2,…,xm)。假设用户已经决定探索n个属性(n个属性中可以包含相关属性和不相关属性),每个样本xi由d个属性描述,每个样本xi= (xi1,xi2,…,xid)是d维样本空间X中的一个向量,xi∈X,其中xij表示xi在第j个属性上的取值,d为样本xi的维数。加入用户相关性反馈,系统进行迭代式处理过程,开始数据探索。用户的相关性反馈要求按属性将数据分类,用户标记的第i个样本记为(xi,yi),其中yi∈Y是样本xi的标记,Y是所有标记的集合或输出空间。标记样本后,训练分类模型,建立用户感兴趣的模型M。建立起用户模型后,对给出的查询进行查询推荐和查询结果优化。当达到一个令人满意相关对象集合或者当他不希望标记更多样本时,用户显式地终止该过程时,指导处理过程完成。最后,在一个SQL查询表达式中将用户模型转变成最终的分类模型(数据提取查询)。
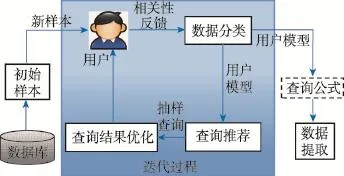
Fig.1 Model of interactive data exploration system图1 交互式数据探索系统模型
IDE的典型应用有循证医学EBM(evidencebased medicine)[2],一门遵循证据的医学。它的核心思想是在医疗决策中将临床证据、个人经验与患者的实际状况和意愿三者相结合。EBM运用最新、最有力的科技信息,指导临床医生采用最适宜的诊断方法、最精确的愈后估计和最安全有效的治疗方法来诊治病人。其核心是要求医生在疾病诊治过程中以当前全世界大样本随机对照实验(randomized control test,RCT)的结果为证据。这样的应用程序通常涉及系统的评价,全面评估收集的证据后,给定一个定义明确的问题,如对死亡率的影响,给药和不给药情况下3小时内症状。而关于内容方面,专家可以判断给定的临床实验是否感兴趣(如检查参数值、疾病的种类、病人年龄等),专家可以对确切的属性没有先验知识,而是制定一个查询来收集所有相关的临床实验。
又如在科学方面的应用。在分析天体物理学的观察时,也遇到过类似的情况:科学家可能无法精确地表达自己的感兴趣数据;相反,他们可能想要浏览的一个子空间数据集(对应天空的一个区域),找到感兴趣的对象,也可能希望看到几件样本,提供是或者不是的反馈意见,期望系统找到更多类似对象。
3 交互式数据探索的特点
传统的Web数据探索查询或以Google、Baidu为代表的搜索引擎,虽然具有基于关键字、通用性等特点,但其局限性和缺点在信息爆炸的时代显得尤其明显。例如,基于内容过滤的方法,可以根据用户以前的兴趣来推测用户以后的兴趣,但不能为用户发现新的感兴趣的资源,只能发现与用户已有兴趣相似的资源。又如基于协作过滤方法的优点是能为用户发现新的感兴趣的信息,但难以解决稀疏性和可扩展性的问题。
交互式数据探索的特点可概括为三方面。
3.1 查询动态性
在交互式数据探索中,查询动态性可体现在两方面:一是输入数据动态性[3]。在数据探索开始时,要求用户加入到与系统的“对话”,通过用户反馈,作为输入数据,捕获用户的偏好,多次迭代后形成初步的用户模型。二是数据信息的动态性。在探索中加入用户反馈后,数据信息是实时更新的,形成了信息循环,通过查询结果优化给出的查询结果不再单纯是基于关键字的内容,也许会偏离初始的输入,但一定是用户感兴趣的内容。
3.2 交互反馈性
交互式数据探索的查询动态性和交互反馈性是相辅相成的。交互反馈性体现在系统可以根据用户的行为动态地调整查询,准确预测数据,给出匹配用户兴趣的集合,为用户提供更精准的、个性化的查询结果。例如,AIDE[4]系统中,在发现相关的对象阶段,依靠用户的相关性反馈将数据分类,确定抽样区域,以提高标记样本的精度,这样使得下一步空间探索中查询结果优化的范围更精确。
3.3 学习主动性
在交互式数据探索中,引入学习主动性,可以提高数据探索的效率和准确性。将机器学习的方法应用于数据探索的各个阶段[2]。例如,自动化交互式数据探索框架[5]通过学习用户感兴趣的数据区域,自动“引导”用户。用户参与以及与系统的“对话”显示用户的兴趣,同时在后台系统自动制定流程,收集数据,查询匹配用户的兴趣。又如,可以应用主动学习,最大化模型的准确性同时将最小化样本的数量显示给用户;分类算法[6]可用于建立用户兴趣模型和信息检索;基于偏移感知的聚类方法[6]可用于处理倾斜属性和确定抽样区域等。
4 交互式数据探索研究技术现状
基于交互式数据探索的框架设计,以及交互式数据探索的上述特点,交互式数据探索对信息的获取也是通过查询来实现的。因为目标不确定是交互式数据探索的重要特点,所以查询层需要提供更多的功能支持交互层。相关研究主要从查询推荐和查询结果优化方面展开。
4.1 交互式数据探索的查询推荐
在过去的几十年里,虽然数据库管理系统(database management sysem,DBMS)进化提供复杂的多种数据管理能力,但管理查询工具相对大数据来说都较为原始。原因之一是查询通常是通过应用程序输出。调试成功一次后,可多次重复使用。随着交互方式发生变化,科学家在诸如生物学、物理学、天文学、地球科学等领域需要收集、存储、检索、探索和分析大量的数据,他们需要可以提出探索性分析数据查询的能力。在这些新的背景下,数据管理系统必须提供强大的查询管理功能,经过查询推荐和对查询结果优化来改进技术,从而能完成从查询浏览到自动查询建议的实现。
现有的查询推荐技术已有很多改进方案,在交互式数据探索方面可以借鉴,下面简要介绍几种较成熟的推荐技术。目前推荐系统可分为4类,即基于内容的推荐、基于协同过滤的推荐、基于知识的推荐、组合推荐。
4.1.1 基于内容的推荐
基于内容的推荐方法是指根据用户已选择的项目,推荐其他类似属性的项目,是一种基于项目间相似性推荐方法。系统基于用户所评价对象的特征,学习用户兴趣模型,从而判断用户资料与候选推荐项目之间的匹配度。其优点在于用户独立性,不需要依赖其他用户的评价信息,只需根据新项目的特征及活动用户概貌即可完成推荐。缺点在于内容局限性,对图形、视频等内容特征难以提取的格式会影响推荐结果;无法区分内容质量的高低;推荐内容有限。典型的基于内容的推荐系统有:Kompan提出的新闻推荐系统[7],麻省理工大学的Lieberman开发的Letizia系统[8],Mladenic提出的PersonalWebWatcher[9],加利福尼亚大学的Billsus推出的Syskill&Webert系统[10]等。
4.1.2 基于协同过滤的推荐
传统的协同过滤推荐算法的原理是利用用户的历史喜好信息来计算用户之间的距离,然后利用目标用户的“最近邻居”对商品评价的加权评价值来预测目标用户对特定商品的喜好程度,系统根据此喜好程度来对目标用户进行推荐。优点是对推荐对象没有特殊的要求,能处理非结构化的复杂对象。比如在文献[11]中,提出一个支持关系数据库交互式探索的查询推荐框架QueRIE(query recommendations for interactive database exploration),如图2所示。采用user-item矩阵方法生成建议。用户之间的相似性可以表示为查询或片段之间的相似性。系统中使用可视化查询接口,确保系统为数据库的活跃用户生成实时推荐,并设计了一种压缩矩阵的方法,加快相似性的计算。
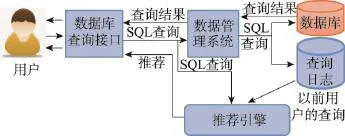
Fig.2 Architecture of QueRIE图2 QueRIE体系结构
随着电子商务用户、商品规模的剧增,基于协同过滤的推荐受到了一些因素的制约,比如准确性、稀疏性、可扩展性和冷启动等问题。在这种情况下,许多研究人员提出了基于协同过滤的改进算法,改进算法主要体现在与聚类、贝叶斯、维数约简等技术的结合。
(1)结合聚类技术。邓爱林等人[12]根据用户对项目评分的相似性进行聚类,从而只需要在与目标项目最相似的若干个聚类中就能寻找到目标项目中大部分的最近邻。Ranshid等人[13]聚类生成每个聚类的代理用户,基于目标用户的相似代理用户进行推荐。George等人[14]采用co-clustering算法构建了一个动态框架,有效解决了实时性问题,同时并行处理用户和项目,提高了系统的可扩展性。结合聚类技术的推荐虽然可以采用离线方式建立模型以确保实时性,但聚类的缺点是无论是用户或是项目,分在一个类后就不能出现在其他类中(而实际上用户的兴趣是广泛的),从而导致推荐的质量不高。
(2)结合贝叶斯技术。孟宪福等人[15]根据用户的偏好对项目进行分类,其实验表明随着评分数据的增加,数据稀疏度在一定程度上增加,但可以提高推荐的精度。赵永梅等人[16]采用动态贝叶斯网,不断学习更新推荐模型,提高了模型的适应性,其推荐结果更加满足客户的需求。贝叶斯技术可以利用训练集创建相应的模型,缓解数据稀疏性问题,但是由于用户和项目的不断增加,需要定期重建模型,并且训练模型的成本高。
(3)结合维数约简技术。Paterek[17]使用奇异值分解,将用户-评分矩阵分解得到与其最接近的低阶矩阵,提高了可扩展性,并有效缓解了同义性问题。李慧等人[18]利用维数约简技术对评分矩阵进行优化,采用分类近似质量计算用户间的相似性并形成最近邻居,从而降低数据稀疏性和提高最近邻寻找准确性。结合维数约简技术的优点是提高了推荐系统的可扩展性,一定程度上缓解了数据稀疏问题,但缺点是降维会导致信息损失。
4.1.3 基于知识的推荐
基于知识的推荐(knowledge based recommendation)[19]在某种程度上可以看成是一种推理(inference)技术[20]。它不是建立在用户需要和偏好基础上进行推荐,而是针对特定领域制定规则(rule)来进行推理。艾磊等人[21]建立了基于有限状态机(finite state machine,FSM)的用户交互模型。根据所推荐物品的特征建立用户交互行为的有限状态机模型,通过求解有限状态机模型的有效路径,生成用户的个性化需求和偏好。谭红叶等人[22]提出了一种基于知识脉络的科技论文推荐方法,利用文本中关键词之间的同义关系、上下文关系构建成知识脉络,结合基于内容过滤的方法为作者进行科技论文推荐。基于知识的推荐方法的核心内容来自于两个方面,即领域知识的聚集和用户需求的获取。对于不同的应用领域,领域知识的聚集规则和实例分类方法存在较大差异,因此这类推荐不存在普遍的适用性,只适用于特定的应用领域。
4.1.4 组合推荐
组合推荐(hybrid recommendation)相对于独立的推荐系统具有更高的推荐准确率。组合推荐[23]通过组合后应能避免或弥补各自推荐技术的弱点。推荐技术组合方式的不同会带来不同的推荐结果,Robin Burke提出了7种组合策略:加权(weighted)、变换(switching)、混合(mixed)、层叠(cascade)、特征组合(feature combination)、特征扩充(feature augmentation)、元级别(meta level)。例如,马建威等人[24]提出了一种基于混合推荐和隐马尔科夫模型(hidden Markov model,HMM)的服务推荐方法,在云环境下,根据对基于内容的过滤和协同过滤方法进行改进,并基于隐马尔科夫模型提出一种冗余服务消解策略,在推荐的准确性和时效性等方面都有较大提升。李程等人[25]提出一种混合型并行推荐算法,利用基于用户的方法划定出定量的邻居范围,保证了推荐的个性化,同时利用基于项目的协同过滤算法进行推荐,最终根据综合因素调整评分预测方法得出符合实际的推荐结果,有效地提高了推荐系统的有效性。
4.1.5 各类推荐方法对比
每一类推荐方法都有其各自的优点和缺点,针对不同的数据类型,推荐效果也有所不同。如在基于内容的推荐方法中,对于特征提取的方法很难应用于媒体数据等非结构化数据。随后发展的协同过滤技术,在一定程度上解决了推荐结果不丰富等问题,但这种技术大部分应用于单一应用系统数据源,并且它是基于大量历史数据集进行的推荐,因而存在稀疏性、准确性等问题。基于知识的推荐虽然不存在冷启动和稀疏性问题,但对知识的建模存在困难。组合推荐策略由于各种组合方式差异较大,不在此讨论。几种推荐方法的优缺点对比如表1所示。
4.2 查询结果优化
查询推荐在传统的搜索引擎中得到了充分的运用,上文也对较成熟的推荐技术做了总结。若当前给出的查询推荐结果不能满足用户的意图,用户会进行下一轮查询,但用户往往对数据缺乏了解,因而需要对查询结果进行优化、重构和抽取等工作。交互式数据查询的查询结果优化是整个交互式数据探索的关键,直接影响数据探索的效果。
在查询结果优化方面,主要关注如何处理空结果查询处理和多结果查询处理两个方面。
空结果查询:当查询条件太严格时,探索的答案可能为空。在这种情况下,用户希望系统给出的选择是近似匹配元组的排名列表,而无需指定排序函数便可捕获较为接近的查询。
多结果查询:当查询条件宽松时,探索的答案会对应很多元组。在这种情况下,用户希望系统可以自动选择排序,并且返回的元组能有最好的匹配结果。
处理多结果查询问题的典型解决方案是利用得分函数和只返回Top-k排名结果[26-27]。这种方法的主要问题是对得分函数的规定,可能不是现成的。此外,Top-k查询处理通常是执行单个表,优化Top-k查询连接是一个具有挑战性的问题[28]。在解决多结果查询时,文献[29]使用了一个交互式查询优化框架,其查询优化关键是在查询结果上提炼SQL查询来满足基数限制。其中包含通过用户反馈捕获用户的偏好,在数值范围内的等式谓词和分类属性上处理查询,并且通过添加支持分类的谓词引入用户的偏好。

Table 1 Comparison of typical recommendation algorithms表1 典型推荐算法的对比
有很多研究通过检测或者放宽查询条件解决空结果查询问题。Agrawal等人介绍了一种利用排名算法的方法[30]。Luo提出了一种利用从以往查询收集的历史信息检测空结果查询的方法[31],但使用物化视图匹配的方法不能通用地推广到其他问题上。同样,Koudas等人的方法是基于窗口语义计算一组最接近原始查询的结果[32],放宽空查询中的查询条件。但该方法需要昂贵的框架来计算结果的大小,并且不能提供有保证的松弛条件策略。Fontoura等人的方法是采用基于查询分解的多个层次分类法的文本文档检索模型[33]。在多个分类的情况下,可以选择多个问题同时放宽查询条件的策略,以避免条件松弛过度产生额外的匹配。随后,人们更关注有针对性的测试性查询,在多个中间子表达式中满足基数约束的条件下,利用抽样和空间剪技术快速生成测试查询所需的属性[34-35]。
在对查询结果的重构和抽取方面,为了让用户更加直观地获取所需要的信息,系统需要将返回的结果进行重构和抽取,以更加结构化的方式展示给用户。Tran等人[36]发现有些用户很难将他们的信息需求抽象成查询,但当他们获取到一些有关信息之后,可以顺利重构查询。MobEx[37]是一个基于移动设备的数据探索系统,该系统通过Web端结果获取页面信息后,采用信息抽取的方式将文本信息以图的形式展现给用户。类似的系统还有微软的人立方。Hippalus系统[38]通过分析返回结果,将内容以多级层次的形式展现给用户,用户可以通过筛选层次以及分类来快速定位到他们所需要的信息。
5 交互式数据探索原型系统对比
近年来,已经存在很多原型系统针对交互式数据探索进行处理,包括YmalDB系统[39]、DICE系统[40]、SciBORQ系统[41]、Blink系统[42]、Charles系统[43]、AIDE系统[5]、SnapToQuery[44]系统。这些系统从不同的方面提出了不同的探索技术。
5.1 YmalDB系统
YmalDB系统[39]的目标是协助用户在数据库中探索,增强数据库系统的推荐功能。对于每个用户查询的结果,YmalDB将计算并提供用户兴趣以外的结果称为Ymal[39](即You may also like)结果(即与原来的结果高度相关的查询)。计算这些结果时,使用的是用户认为与其兴趣最匹配的属性值集合(Fa-Sets)。Ymal采用基于存储ɛ-CRF的频率估计方法,探索数据库搜索结果建议[39,45]。虽然Ymal给出的结果可能不属于用户原始查询的结果,但有可能是他们感兴趣的,这就允许用户获得他们可能还未意识到的但确实感兴趣的信息。YmalDB的系统架构如图3所示。
5.2 DICE系统
DICE[40](distributed and interactive cube exploration)是一个分布式系统,使用一种面向会话的数据立方体模型进行探索,可以为用户提供交互式的特定精度标准的体验。DICE的框架结合了3个概念:数据立方体的多面探索、查询推测和在数据子集查询。使用查询推测技术和在线数据抽样技术,确保快速、交互式多维数据集探索能够物化整个数据立方体。但在可接受的延迟范围内应该限制这样的设置,因为一个完全物化的多维数据集是原始数据集的好几倍,通常大于可用内存。因此,一个常用的方法是离线计算样本数据[42,46-47],但这种方法不能适应底层数据的变化。DICE提供的技术可以在需要的情况下离线采样。
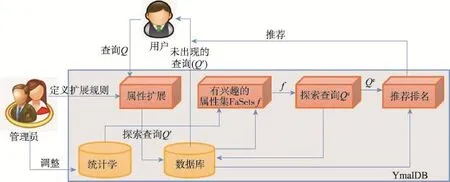
Fig.3 Architecture of YmalDB图3 YmalDB体系结构
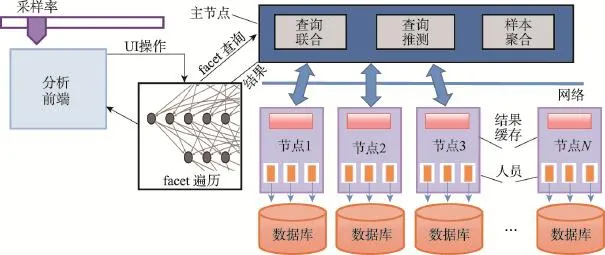
Fig.4 DICE approach图4 DICE方法
DICE方法如图4所示。允许在低延迟前端上具有可调采样率,将UI的操作翻译成在数据立方体上的遍历查询。查询执行的主体部分在分布式节点上。在DICE方法中,主节点管理包括会话状态、推测查询和结果聚合三部分。对于每个查询,查询分发到每个从节点。每个从节点的结果随后聚合,计算误差范围,并返回给用户。
5.3 SciBORQ系统
查询巨大的数据库需要相当大的计算集群,在理想情况下,最初的查询应该使用尽可能少的资源进行交互。SciBORQ[41]的思路是:在任何给定的时间内,只将一部分主要属性的数据作为一个特定的查询对象。这部分数据通过特别的查询结果优化的迭代过程成为查询对象。通过数据操纵来满足科学发现的要求,保证查询的执行时间。此外,误差的严格上限需要满足科学使用的要求,这样查询结果能够可靠地用来测试假设。
传统的近似查询应答和在线聚合方法不能使系统满足完全控制资源消耗和精确查询结果的要求。SciBORQ是一种数据探索型科学数据仓库体系结构,它可以精确控制执行时间,提高查询应答的质量。在SciBORQ中,将一种获得用户感兴趣的多个数据样本的抽样方法称为印象(impression)。印象不同于以往的抽样方法,它偏向科学数据探索的兴趣点,这种偏差抽样很有价值,可以在更多感兴趣的区域进行数据采样。SciBORQ的独特之处在于其多层的架构方法,重新优化可以保证所需的误差范围,即使它们偏离相关性。SciBORQ最终目标是把科学数据探索和发现过程构成一个完整的系统,在严格的误差范围和预定义的时间框架内产生高质量的结果。
5.4 BlinkDB系统
BlinkDB[42]是一个用于在海量数据上运行交互式SQL查询的大规模并行查询引擎,其数据探索的侧重点在于允许用户通过权衡数据精度来提升查询响应时间,其数据的精度被控制在允许的误差范围内。为了达到这个目标,BlinkDB使用两个核心思想:一个是自适应优化框架,从原始数据随着时间的推移建立并维护一组多维样本;另一个是动态样本选择策略,选择一个适当大小的且基于查询的实例,以提高准确性或达到响应时间需求。
BlinkDB利用大规模并行复杂处理框架可以优化交互式应答大量的数据。BlinkDB支持SPJA(selection,projection,join,aggregate)方式SQL查询。聚合查询可以标记误差或最大执行时间约束。Blink-DB的总体体系结构如图5所示,BlinkDB添加了两个主要组件:(1)组件创建和维护样本;(2)用组件预测查询响应时间和准确性,选择一个最好的样本满足给定的约束条件。这样可以使其依赖于运行时样本选择与统计误差,确保提供实时的应答。
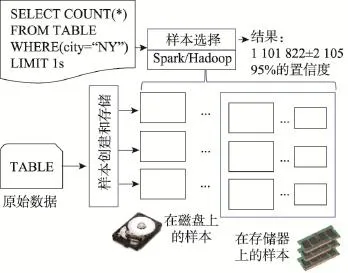
Fig.5 Architecture of BlinkDB图5 BlinkDB体系结构
5.5 Charles系统
Charles系统[43]解决的核心问题是如何将查询空间与给定的数据库相关联。查询空间被认为是由连接谓词组成的,Charles系统引入分段描述语言(segmentation description language,SDL)来描述这些谓词,使得用户可以深刻理解描述集,并为用户提供了进一步探索的方向。Charles系统从几个方面来查询一组用户提供的元组。每个饼形图代表一组查询,数据库切成不相交的部分称之为分割。Charles的目标是分离和描述大量的数据交互,并提出算法HB-cuts(hierarchical-binary分割),将数据集分为可能同样宽的块。Charles在MonetDB系统的环境下,简化了代码的可移植性。
5.6 AIDE系统
AIDE[5](automatic user navigation system for inter-active data exploration)是一种支持IDE的自动化用户导航系统,可以自动学习用户的兴趣,对这些兴趣相关的数据进行探索。该系统数据探索的侧重点在于依靠用户的反馈提供查询建议,专注于收集样本,理解用户的兴趣。AIDE依赖一个主动式学习模型,反复迭代地请求用户的反馈[4],设计一定策略,有选择地收集数据样本。AIDE将机器学习、数据探索和样本采集技术相结合,提供了一个高精度预测用户兴趣与交互性能的线性模式[48]。简而言之,用户参与“对话”,系统通过描述一组数据样本作为他相关或不相关的兴趣。将用户反馈数据逐步纳入系统,用于逐步提高其有效性,最终生成一个用户模型,准确预测数据匹配用户兴趣结果的集合。
AIDE工作流程框架是如图6所示。首先,用户提出了样本数据库对象(初始的样本采集),要求按特征使用CART决策树方法[6]将探索任务分为相关与不相关的样本。假设有一个二元无噪音的关联系统,用户可以知道一个数据对象与他是否相关,这个分类在下一个迭代中不能修改。当用户提供反馈时,系统迭代地指导处理过程,标记样本,用分类算法训练分类模型,描述用户兴趣。例如:系统预测的相关用户的临床实验是基于目前收集到的反馈(数据分类)。对象属性的分类模型可以使用任何子集描述用户的兴趣。当前用户模型来确定抽样区域(空间探索),从数据库中获取下一个样本集(样本提取)。新标签对象合并已标记样本集,构建一个新的分类模型。当达到一定条件,如达到一个令人满意相关对象的集合或者当他不希望标记更多样本时,用户显式地终止指导过程。最后,AIDE在一个查询表达式中“翻译”成分类模型(数据提取查询)。这个查询将检索对象特征作为相关的用户模型(查询公式)。

Fig.6 Framework ofAIDE图6 AIDE的框架结构
5.7 SnapToQuery系统
SnapToQuery[44]是一种基于Snapping技术[49-50]的反馈机制,通过“快照”用户可能感兴趣的查询,指导用户在查询规范过程中提供互动反馈。这些预期的查询可以从现有的查询日志或从数据本身提取。为了在大型数据集提供交互式响应时间,SnapToQuery在快照查询时提出两个数据简化技术。一种是Naive方法,主要思想是聚合,用分割空间的方式代替分割大型数据集的方式。另一种是Data Contour方法,处理低维数据集查询时,采用边缘检测方法和基于网格的聚类方法;处理高维数据集查询时,采用KMeans+直方图的方法。
SnapToQuery系统的整体架构如图7所示。系统的后端应用Naive方法和Data Contour方法对数据集进行了简化,在前端增加了可视化的基于链接的可调节直方图[51]。用户可以通过操作滑块条,在3个设备(鼠标、平板电脑、跳跃运动)上发布范围查询,随后SnapToQuery系统在查询规范内进行快照查询。
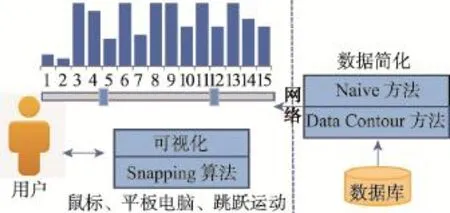
Fig.7 Overall architecture of SnapToQuery图7 SnapToQuery的整体构架
5.8 系统对比
针对上述系统,从系统的侧重点、缺点和使用的主要技术等层面对各个交互式数据探索的原型系统进行了对比。比如YmalDB系统[39]是对关系数据库查询结果进行分析,推荐出用户可能感兴趣属性值对的组合,引导用户进一步探索数据库中的数据。其侧重点是信息推荐。SciBORQ系统[41]依靠严格的层次数据库样本,支持在严格的查询执行时间内进行科学探索查询,进而快速返回查询结果以提高交互性能。而AIDE系统[5]依靠用户的反馈提供查询建议,专注于收集样本,提高系统理解用户的兴趣的能力。其侧重点通过用户反馈对数据分类,从而提高交互性能。由于各个系统的侧重点不同,实验数据集不同,这里对系统的准确性和效率不做讨论。各个系统的对比如表2所示。
6 研究展望
数据探索已经成为研究热点,然而将数据探索与用户反馈机制和机器学习结合起来依然存在诸多不足,面临着诸多挑战,有很多需要进一步研究的内容。
(1)用户与系统的交互方式
面对结构复杂、规模庞大的数据库,用户通常难以明确自己的信息需求并通过简单的查询检索到理想的数据。在没有历史数据或历史数据较少的条件下,交互式数据探索系统的冷启动问题会成为解决最终结果准确性的关键。目前,交互式数据探索中大部分应用的反馈机制是建立在二元无噪音的关联系统[5],但为了让系统能收集到更精确的反馈信息,未来研究可考虑提供用户在数据探索反馈信息时输入带有不确定度的信息,如允许用户选择“有点像”、“更像了”、“完全不是”等这样的选项来对结果作判定,并使用更多的主动学习模型,如贝叶斯模型、深度学习策略等,来解决系统冷启动问题。
交互界面是用户与系统直接对话的平台,在交互式数据探索系统中,需要良好的交互层以协助用户更准确地表达和获取信息需求。在交互层设计的环节上,应根据应用层的不同需求进行个性化的设计,其设计的好坏直接影响到系统的易用性。未来研究可考虑结合AR(augmented reality)技术实现用户与系统的交互,建立基于时间树AR交互数据的用户注意力模型,捕捉用户信息,预测用户的下一步搜索。另外,对探索结果进行可视化也是需要研究的内容之一。目前可视化技术与交互式数据探索的结合不深入,应针对不同数据的特点,对探索的结果可视化,展示查询结果与数据之间的关联。
(2)数据处理
随着数据规模和复杂性的增加,用户的查询意图很容易被淹没在数据中。由于数据集的大小从几十到几百万亿字节不等,而且每个科学领域中的非结构化数据有一个约定的分类,用户很难对数据集进行理解和探索。在大规模数据集中,快速将各种数据进行抽取实体、自动地整理与挖掘以及支持小规模数据量的分析,是数据处理面对的挑战。未来研究可考虑利用数据预取(data prefetching)的方法和查询近似(query approximation)技术相结合,在用户可接受的误差范围内,牺牲部分精度,快速返回近似结果。
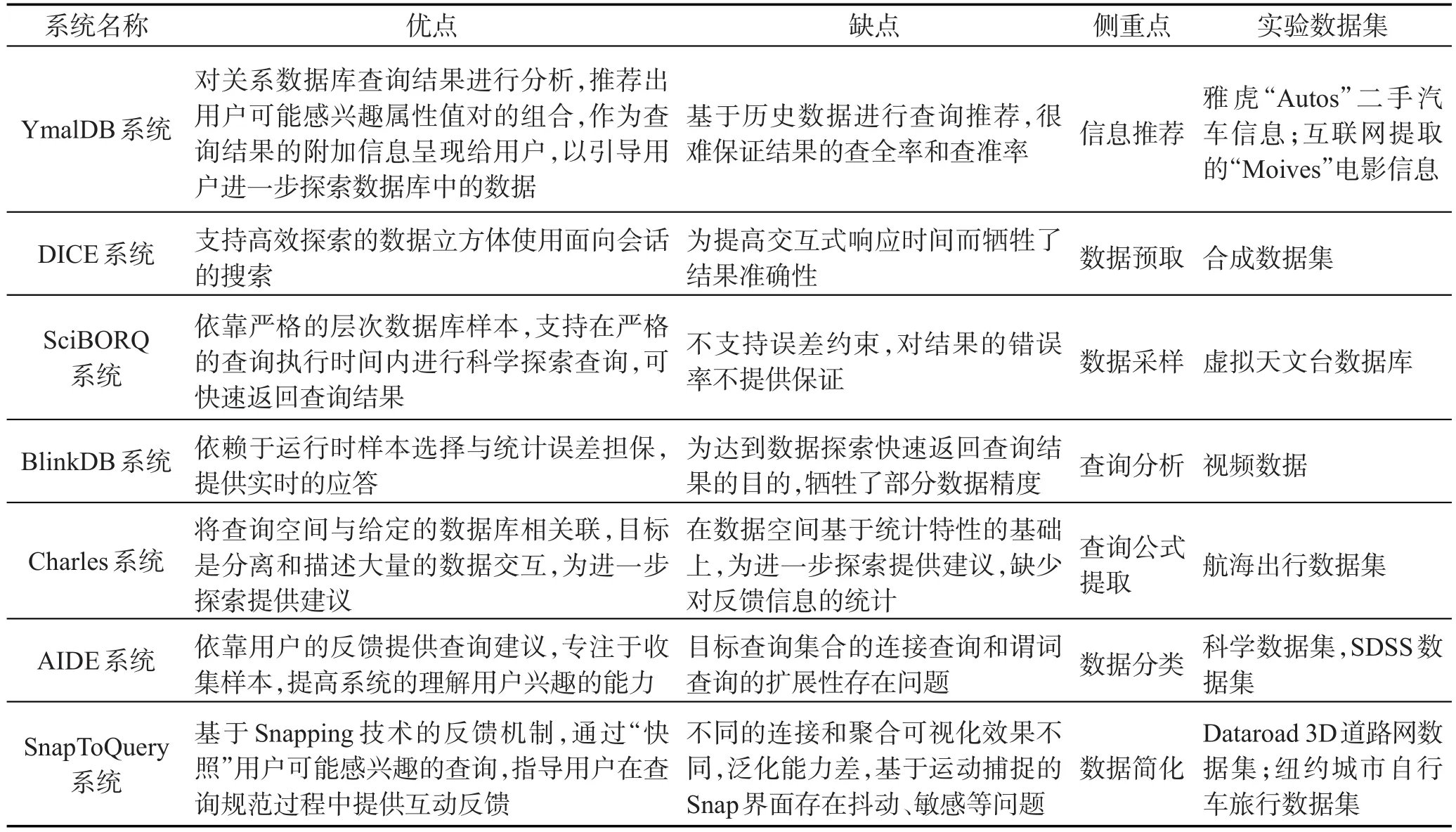
Table 2 Comparison of prototype systems of interactive data exploration表2 交互式数据探索的原型系统对比
(3)查询构建
在交互式数据探索中,提高查询的准确性,势必要增加样本标签的数量,用户提供的样本标签越多,得到的查询结果越准确,但这会降低数据探索的效率。此挑战在于要根据不同的应用环境和用户需求,权衡收集所有相关的信息量与减少返回数据量之间的关系。未来研究可考虑采用查询主题扩展的方法,在给出少量样本数据的同时,满足用户关注的更多主题。比如利用多属性效用函数在给定时间内,将一部分主要属性的数据作为一个特定的查询对象,构建查询以保证查询的执行时间。其次,交互式数据探索对信息的需求是多样变化的,需要通过多轮交互模式达到学习和调研的目的。如果当前的查询不满足用户的需求,用户会进行再一次的查询操作,但由于用户对探索的目标是模糊不确定的,缺乏对探索数据的了解,需要交互式数据探索系统支持用户快速重构查询。未来研究可考虑结合最近的查询结果,并且联系之前的查询条件,在用户当前查询的基础上加上限制条件,帮助用户逐步地构建准确的查询。
7 总结与展望
本文基于交互式数据探索的应用背景,对其进行了简要介绍,总结了探索模型,分析出交互式数据探索具有查询动态性、交互反馈性、学习主动性三大特点;总结了IDE中的查询推荐技术,重点介绍了基于协同过滤技术提出的交互式推荐框架;总结了出现空结果查询和多结果查询情况下的查询优化技术;对IDE原型系统进行了分析和比较。交互式数据探索是个新兴的重要课题,目前正处于高速发展阶段,虽然有很多相关领域的研究成果可以借鉴,但仍有大量问题需要解决。随着知识库数量和数据规模的不断增加,将会有更多的系统涌现出来,为用户与系统构建一个主动学习的交互式平台,并推动大数据应用不断发展。
[1]Marchionini G.Exploratory search:from finding to understanding[J].Communications of theACM,2006,49(4):41-46.
[2]Koutrika G,Lakshmanan L V S,Riedewald M,et al.Report on the first international workshop on exploratory search in databases and the Web(ExploreDB 2014)[J].ACM SIGMOD Record,2014,43(2):49-52.
[3]Dimitriadou K,Papaemmanouil O,Diao Yanlei.Explore-byexample:an automatic query steering framework for interactive data exploration[C]//Proceedings of the 2014 ACM SIGMOD International Conference on Management of Data, Snowbird,USA,Jun 22-27,2014.New York:ACM,2014: 517-528.
[4]Dimitriadou K,Papaemmanouil O,Diao Yanlei.Interactive data exploration based on user relevance feedback[C]//Proceedings of the 2014 IEEE 30th International Conference on Data Engineering Workshops,Chicago,USA,Mar 31-Apr 4,2014.Piscataway,USA:IEEE,2014:292-295.
[5]Diao Yanlei,Dimitriadou K,Li Zhan,et al.AIDE:an automatic user navigation system for interactive data exploration[J].Proceedings of the VLDB Endowment,2015,8 (12):1964-1967.
[6]Trendowicz A,Jeffery R.Classification and regression trees [M]//Software Project Effort Estimation.Springer International Publishing,2014:1174-1176.
[7]Kompan M,Bieliková M.Content-based news recommendation[C]//Proceedings of the 2010 International Conference on E-Commerce and Web Technologies,Bilbao,Spain, Sep 1-3,2010.Berlin,Heidelberg:Springer,2010:61-72.
[8]Lieberman H.Letizia:an agent that assists Web browsing [C]//Proceedings of the 14th International Joint Conference on Artificial Intelligence,Montréal Québec,Canada,Aug 20-25,1995.San Francisco,USA:Morgan Kaufmann Pub-lishers Inc,1995:924-929.
[9]Mladenic D.Personal WebWatcher:design and implementation[R].Department of Intelligent Systems,Stefan Institute, 1996.
[10]Pazzani M,Muramatsu J,Billsus D.Syskill&Webert:identifying interesting Web sites[C]//Proceedings of the 13th National Conference on Artificial Intelligence,Portland, USA,Aug 4-5,1996.Palo Alto,USA:AAAI Press,1996: 54-61.
[11]Chatzopoulou G,Eirinaki M,Polyzotis N.Query recommendations for interactive database exploration[C]//LNCS 5566:Proceedings of the 21st International Conference on Scientific and Statistical Database Management,New Orleans,USA,Jun 2-4,2009.Berlin,Heidelberg:Springer, 2009:3-18.
[12]Deng Ailin,Zuo Ziye,Zhu Yangyong.Collaborative filtering recommendation algorithm based on item clustering[J]. Mini-Micro Systems,2004,25(9):1665-1670.
[13]Rashid A M,Lam S K,Karypis G,et al.ClustKNN:a highly scalable hybrid model-&memory-based CF algorithm[C]// Proceedings of the 8th International Workshop on Knowledge Discovery on the Web,Philadelphia,USA,Aug 20-23,2006.New York:ACM,2006.
[14]George T,Merugu S.A scalable collaborative filtering framework based on co-clustering[C]//Proceedings of the 5th IEEE International Conference on Data Mining,Houston,USA,Nov 27-30,2005.Piscataway,USA:IEEE,2005: 625-628.
[15]Meng Xianfu,Chen Li.The collaborative filtering recommendation mechanism based on Bayesian theory[J].Journal of ComputerApplications,2009,29(10):2733-2735.
[16]Zhao Yongmei,Ren Dayong,Zhang Hongmei,et al.An approach to collaborative filtering recommendation based on HMM and DBN[J].Science Technology&Engineering, 2011,11(9):2012-2016.
[17]Paterek A.Improving regularized singular value decomposition for collaborative filtering[C]//Proceedings of the 2007 KDD Cup&Workshop,San Jose,USA,Aug 12,2007. New York:ACM,2007:39-42.
[18]Li Hui,Hu Yun,Li Cunhua,et al.Personalization recommendation algorithm based on nearest neighbor relation[J]. Computer Engineering and Applications,2012,48(36):205-209.
[19]Middleton S E,Shadbolt N R,De Roure D C.Ontological user profiling in recommender systems[J].ACM Transactions on Information Systems,2004,22(1):54-88.
[20]Xu Hailing,Wu Xiao,Li Xiaodong,et al.Comparison study of Internet recommendation system[J].Journal of Software, 2009,20(2):350-362.
[21]Ai Lei,Zhao Hui.A user interaction model for knowledgebased recommender system[J].Software Guide,2015,14 (3):15-17.
[22]Tan Hongye,Yao Yilu,Liang Yinghong.Knowledge veinbased recommendation of academic papers[J].Journal of Shandong University:Natural Science,2016,51(5):94-101.
[23]Yoshii K,Goto M,Komatani K,et al.An efficient hybrid music recommender system using an incrementally trainable probabilistic generative model[J].IEEE Transactions on Audio Speech&Language Processing,2008,16(2):435-447.
[24]Ma Jianwei,Chen Honghui,Stephan R-M.Based on the hybrid recommendation and hidden Markov models of service recommendation method[J].Journal of Zhongnan University: Science and Technology,2016,47(1):82-90.
[25]Li Cheng,Cao Han,Shi Jun.Hybrid recommendation algorithm based on MapReduce and its application[J].Journal of Computer Technology and Development,2016,26(4): 74-77.
[26]Fagin R,Lotem A,Naor M.Optimal aggregation algorithms for middleware[J].Journal of Computer&System Sciences,2002,66(4):614-656.
[27]Chaudhuri S,Das G,Hristidis V,et al.Probabilistic ranking of database query results[C]//Proceedings of the 30th International Conference on Very Large Data Bases,Toronto, Canada,Aug 31-Sep 3,2004:888-899.
[28]Ilyas I F,Aref W G,Elmagarmid A K.Supporting top-k, join queries in relational databases[C]//Proceedings of the 29th International Conference on Very Large Data Bases, Berlin,Germany,SEP 9-12,2003:754-765.
[29]Mishra C,Koudas N.Interactive query refinement[C]//Proceedings of the 12th International Conference on Extending Database Technology:Advances in Database Technology, Saint Petersburg,Russia,Mar 24-26,2009.New York:ACM, 2009:862-873.
[30]Agrawal S,Chaudhuri S,Das G,et al.Automated rankingof database query results[C]//Proceedings of the 1st Biennial Conference on Innovative Data Systems Research,Asilomar,USA,Jan 5-8,2003:888-899.
[31]Luo Gang.Efficient detection of empty-result queries[C]// Proceedings of the 32nd International Conference on Very Large Data Bases,Seoul,Sep 12-15,2006.New York:ACM, 2006:1015-1025.
[32]Koudas N,Li C,Tung A K H,et al.Relaxing join and selection queries[C]//Proceedings of the 32nd International Conference on Very Large Data Bases,Seoul,Sep 12-15,2006. New York:ACM,2006:199-210.
[33]Fontoura M,Josifovski V,Kumar R,et al.Relaxation in text search using taxonomies[J].Proceedings of the VLDB Endowment,2010,1(1):672-683.
[34]Bruno N,Chaudhuri S,Thomas D.Generating queries with cardinality constraints for DBMS testing[J].IEEE Transactions on Knowledge&Data Engineering,2006,18(12): 1721-1725.
[35]Mishra C,Koudas N,Zuzarte C.Generating targeted queries for database testing[C]//Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver,Canada,Jun 9-12,2008.New York:ACM,2008: 499-510.
[36]Tran Q T,Chan C Y,Parthasarathy S.Query by output[C]// Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data,Providence,USA,Jun 29-Jul 2,2009.New York:ACM,2009:535-548.
[37]Neumann G,Schmeier S.MobEx:a system for exploratory search on the mobile Web[C]//Communications in Computer and Information Science 358:Proceedings of the 4th International Conference on Agents and Artificial Intelligence, Vilamoura,Portugal,Feb 6-8,2012.Berlin,Heidelberg: Springer,2012:116-130.
[38]Tzitzikas Y,Papadakos P.Hippalus—a preference enriched faceted exploratory system[J].Language,2014:167-172.
[39]Drosou M,Pitoura E.YmalDB:a result-driven recommendation system for databases[C]//Proceedings of the 16th International Conference on Extending Database Technology, Genoa,Italy,Mar 18-22,2013.New York:ACM,2013: 725-728.
[40]Kamat N,Jayachandran P,Tunga K,et al.Distributed and interactive cube exploration[C]//Proceedings of the 30th IEEE International Conference on Data Engineering,Chicago, USA,Mar 31-Apr 4,2014.Washington:IEEE Computer Society,2014:472-483.
[41]Sidirourgos L,Kersten M,Boncz P.SciBORQ:scientific data management with bounds on runtime and quality[C]//Proceedings of the 5th Biennial Conference on Innovative Data Systems Research,Asilomar,USA,Jan 9-12,2011:296-301.
[42]Agarwal S,Iyer A P,Panda A,et al.Blink and it's done:interactive queries on very large data[J].Proceedings of the VLDB Endowment,2012,5(12):1902-1905.
[43]Sellam T,Kersten M L.Meet Charles:big data query advisor [C]//Proceedings of the 6th Biennial Conference on Innovative Data Systems Research,Asilomar,USA,Jan 6-9,2013.
[44]Jiang Lilong,Nandi A.SnapToQuery:providing interactive feedback during exploratory query specification[J].Proceedings of the VLDB Endowment,2015,8(11):1250-1261.
[45]Drosou M,Pitoura E.ReDRIVE:result-driven database exploration through recommendations[C]//Proceedings of the 20th ACM International Conference on Information and Knowledge Management,Glasgow,UK,Oct 24-28,2011. New York:ACM,2011:1547-1552.
[46]Wang Fan,Agrawal G.Effective stratification for low selectivity queries on deep Web data sources[C]//Proceedings of the 20th ACM International Conference on Information and Knowledge Management,Glasgow,UK,Oct 24-28,2011. New York:ACM,2011:1455-1464.
[47]Chaudhuri S,Das G,Narasayya V.Optimized stratified sampling for approximate query processing[J].ACM Transactions on Database Systems,2007,32(2):2198-2216.
[48]Query patroller[EB/OL].[2016-05-10].http://www.ibm.com/ software/data/db2/querypatroller/.
[49]Eick S G,Wills G J.High interaction graphics[J].European Journal of Operational Research,1995,81(3):445-459.
[50]Baudisch P,Cutrell E,Hinckley K,et al.Snap-and-go:helping users align objects without the modality of traditional snapping[C]//Proceedings of the 2005 Conference on Human Factors in Computing Systems,Portland,USA,Apr 2-7,2005. New York:ACM,2005:301-310.
[51]Fernquist J,Shoemaker G,Booth K S.“Oh Snap”—helping users align digital objects on touch interfaces[C]//Proceedings of the 13th IFIP TC International Conference on Human-Computer Interaction,Lisbon,Portugal,Sep 5-9,2011.Berlin,Heidelberg:Springer,2011:338-355.
附中文参考文献:
[12]邓爱林,左子叶,朱扬勇.基于项目聚类的协同过滤推荐算法[J].小型微型计算机系统,2004,25(9):1665-1670.
[15]孟宪福,陈莉.基于贝叶斯理论的协同过滤推荐算法[J].计算机应用,2009,29(10):2733-2735.
[16]赵永梅,任大勇,张红梅,等.用动态贝叶斯网络构建协同过滤推荐的新方法[J].科学技术与工程,2011,11(9): 2012-2016.
[18]李慧,胡云,李存华,等.基于近邻关系的个性化推荐算法研究[J].计算机工程与应用,2012,48(36):205-209.
[20]许海玲,吴潇,李晓东,等.互联网推荐系统比较研究[J].软件学报,2009,20(2):350-362.
[21]艾磊,赵辉.基于知识的推荐系统用户交互模型研究[J].软件导刊,2015,14(3):15-17.
[22]谭红叶,要一璐,梁颖红.基于知识脉络的科技论文推荐[J].山东大学学报:理学版,2016,51(5):94-101.
[24]马建威,陈洪辉,Stephan R-M.基于混合推荐和隐马尔科夫模型的服务推荐方法[J].中南大学学报:自然科学版, 2016,47(1):82-90.
[25]李程,曹菡,师军.基于MapReduce的混合推荐算法及应用[J].计算机技术与发展,2016,26(4):74-77.

WANG Mengxiang was born in 1991.She is an M.S.candidate at Northeastern University,and the member of CCF.Her research interests include database system and machine learning,etc.
王蒙湘(1991—),女,内蒙古赤峰人,东北大学硕士研究生,CCF会员,主要研究领域为数据库系统,机器学习等。

LI Fangfang was born in 1977.She received the Ph.D.degree in computer science from Northeastern University in 2009.Now she is a lecturer at Northeastern University,and the member of CCF.Her research interests include database and data management of CPS,etc.
李芳芳(1977—),女,黑龙江哈尔滨人,2009年于东北大学获得博士学位,现为东北大学计算机科学与工程学院讲师,CCF会员,主要研究领域为数据库,CPS数据管理等。

GU Yu was born in 1981.He received the Ph.D.degree in computer science from Northeastern University in 2010. Now he is a professor and Ph.D.supervisor at Northeastern University,the member of ACM,and the senior member of CCF.His research interests include distributed computing and big data analysis,etc.
谷峪(1981—),男,辽宁鞍山人,2010年于东北大学获得博士学位,现为东北大学计算机科学与工程学院教授、博士生导师,ACM会员,CCF高级会员,主要研究领域为分布式计算,大数据分析等。

YU Ge was born in 1962.He received the M.S.degree in computer science from Northeastern University in 1986, and Ph.D.degree in computer science from Kyushu University of Japan in 1996.Now he is a professor and Ph.D. supervisor at Northeastern University,and the member of ACM and IEEE,and the senior member of CCF.His research interests include database theory and technology,distributed system,parallel computing and cloud computing,etc.
于戈(1962—),男,辽宁大连人,1986年于东北大学获得硕士学位,1996年于日本九州大学获得计算机工学博士学位,现为东北大学教授、博士生导师,中国计算机学会理事,ACM、IEEE会员,CCF高级会员,主要研究领域为数据库理论,分布式系统,并行计算,云计算等。
Survey on Interactive Data Exploration*
WANG Mengxiang,LI fangfang,GU Yu,YU Ge+
Department of Computer Science,College of Computer Science and Engineering,Northeastern University,Shenyang 110819,China
+Corresponding author:E-mail:yuge@mail.neu.edu.cn
Large data sets have exceeded the scale of terabytes and petabytes,and existing techniques can collect and store massive information.While database management systems have been constantly improved to offer a variety of complex data management capabilities,but the query tools cannot satisfy the needs of large data,so how to precisely understand and explore the massive data set remains a huge challenge.The focus of interactive data exploration(IDE) is to emphasize interaction,exploration and discovery.Users will accurately find the information they need with the minimum cost in the vast amounts of data.Firstly,this paper introduces the IDE and its application background,summarizes the general model and features of IDE,and analyzes the present situation of the query technology and the optimization techniques for query results.Furthermore,this paper analyzes and compares IDE prototype systems respectively.Finally,this paper summarizes and forecasts the techniques of IDE.
interactive data exploration;query recommendation;optimization for query results;user feedback;machine learning
10.3778/j.issn.1673-9418.1606010
A
:TP315
*The National Natural Science Foundation of China under Grant No.61272180(国家自然科学基金);the Fundamental Research Funds for the Central Universities of China under Grant No.N161604005(中央高校基本科研业务费专项资金).
Received 2016-06,Accepted 2016-10.
CNKI网络优先出版:2016-10-18,http://www.cnki.net/kcms/detail/11.5602.TP.20161018.1622.004.html
WANG Mengxiang,LI fangfang,GU Yu,et al.Survey on interactive data exploration.Journal of Frontiers of Computer Science and Technology,2017,11(2):171-184.
猜你喜欢
导航定位学报(2022年4期)2022-08-15
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
领导决策信息(2018年16期)2018-09-27
汽车导报(2017年5期)2017-08-03
数学学习与研究(2017年3期)2017-03-09
商用汽车(2016年11期)2016-12-19
商用汽车(2016年5期)2016-11-28
商用汽车(2016年6期)2016-06-29
中学生数理化·高二版(2016年4期)2016-05-14
