
Hadoop MapReduce新旧架构的对比研究综述*
2017-02-09 09:52于金良朱志祥李聪颖
计算机与数字工程 2017年1期
于金良 朱志祥 李聪颖
(西安邮电大学 西安 710061)
Hadoop MapReduce新旧架构的对比研究综述*
于金良 朱志祥 李聪颖
(西安邮电大学 西安 710061)
Hadoop MapReduce架构经过了一次重构,新旧架构有着巨大的差异。论文首先介绍了旧版本MapReduce的架构,作业执行的流程与其中的任务的调度、资源分配等,指出了旧框架的局限性。再介绍了新框架的架构,任务调度和资源分配等。并从二者的架构、任务调度、资源分配等方面进行了对比,指出了新框架的优势。新一代的MapReduce框架YARN是共享模式的,可以在同一集群上运行使用不同的计算框架编写的应用程序,同时也减少了运维的难度,提高了集群资源的利用率。
MapReduce; YARN; 任务调度; 资源分配
Class Number TP274.2
1 引言
MapReduce[1]是谷歌在2004年提出的能够并发处理大规模数据集(大于1TB)的编程模型。它的名字来源于函数式编程模型中的两个核心操作:Map和Reduce,当然它们的思想也是一致的。Map是把数据分开的过程,而Reduce则是把分开的数据合并的过程。它的特点是简单易学、使用广泛,能够降低并行编程难度,让程序员从繁杂的并行编程工作中解脱出来,轻松地编写简单、高效地并行程序[2]。
随着近年来大数据的发展,数据规模越大,对其挖掘可能得到的价值更大[3],MapReduce可以很好地做这些工作。Hadoop MapReduce是谷歌MapReduce的开源版本,作为一种编程模型MapReduce是高语言等级的,它屏蔽了底层实现细节,降低了编程难度,提高了编程效率[4]。它即使部署在廉价的机器组成的集群上,也可以拥有很高的性能。但是作为一个计算引擎,它还有很多的劣势,如它存在单点故障的问题,由于它拥有一套自己的资源分配、任务调度的功能,即使做MapReduce的高可用(High Availability),由于主节点上存储了很多任务的信息、资源的信息,使得故障的恢复变得极其困难,所以需要一种新的任务调度工具完成MapReduce作业的调度和资源分配。
2 MapReduceV1研究
MapReduce采用了“分而治之,然后整合”的处理思想。Hadoop会将一个大任务分解多个小任务,然后并行执行。每一个MapReduce任务都被初始化为一个Job。每个Job又可以分为两个阶段,Map阶段和Reduce阶段[5]。这两个阶段分别有两个函数来表示。Map函数接收一个〈key,value〉形式的输入,然后产生同样的〈key,value〉形式的中间输出,执行Reduce任务的机器负责拉取所有的具有相同Key的〈Key,Value〉数据,然后传递给Reduce函数,Reduce函数接收一个如〈key,(list of value)〉形式的输入,然后对这个value集合处理并输出结果,Reduce的输出也是〈key,value〉形式的[6]。如图1是MapReduce处理数据的变化流程。

图1 Mapreduce数据流变化
MapReduce采用的是主/从架构,其中主节点是JobTracker(作业服务器),从节点是TaskTracker(任务服务器)。二者之间通过定时心跳进行通信。
JobTracker主要负责与客户端通信,接受客户端的命令,如提交作业,杀死作业等,并将这些命令发送给TaskTracker来执行。它与TaskTracker之间的通信是以定时心跳的形式进行的,它为TaskTracker分配任务、所需要的计算资源(CPU、内存、带宽等),以及记录任务状态等,它之中保存着关于作业的所有信息。
TaskTracker是沟通JobTracker和tasks之间的桥梁:一方面,接收并执行JobTracker发送来的命令;另一方面将本节点上各个任务的状态、执行的进度以定时心跳的形式发送给JobTracker[7]。
下面是MapReduce作业执行的具体流程:
1) 提交作业
一个MapReduce作业提交到Hadoop之后,会进入完全地自动化执行过程,在这个过程中,用户除了监控作业的执行情况和强制终止作业之外,不能对作业的执行过程进行干扰,所以在作业提交之前,用户需要将作业所有的需要的参数配置完备。
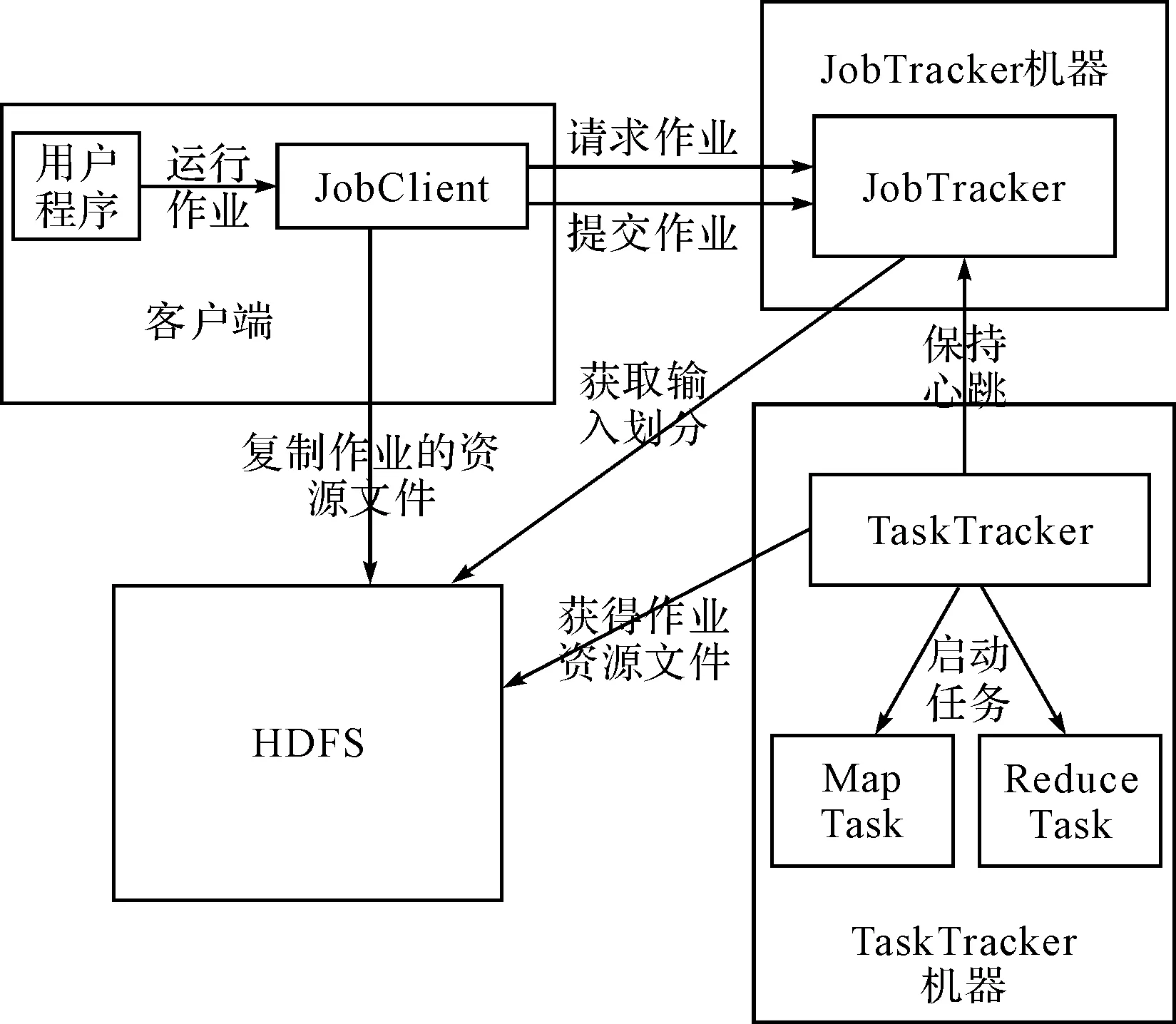
图2 MapReduce架构图
2) 初始化作业
在客户端中,当用户作业调用JobTracker对象的submitJob()方法之后,JobTracker会把这个作业放在一个作业队列中去,进行调度,默认的调度方式是FIFO。当作业被调度执行时,JobTracker会对此作业进行初始化,根据处理数据的情况为其创建Map任务和Reduce任务。
3) 分配任务
TaskTracker是一个单独循环运行的软件,每间隔一段时间向JobTracker发送心跳信息(heartbeat),包括告知JobTracker此TaskTracker是否存活,是否准备好执行新的任务。在JobTracker接收到心跳信息后,如果任务队列中有待分配的任务时,它就会给一个准备好的TaskTracker分配一个任务,并将分配信息(包括要执行的任务信息和分配的资源信息)封装在心跳信息返回值返回给TaskTracker,TaskTracker根据此返回信息来执行任务。在JobTracker为TaskTracker分配任务时,为了减少数据移动I/O开销大的问题,会考虑将任务分配到数据所在的TaskTracker上。
4) 执行任务
TaskTracker根据心跳返回值的信息来执行任务,并跟踪任务执行的状态,并定时向JobTracker报告任务的状态,直到任务执行完成[8]。
· 错误处理机制:
在作业调度过程中,故障处理是一个很重要的方面。这里主要两种故障:硬件故障和任务执行失败。
· 硬件故障就是服务器宕机:
从MapReduce任务执行的角度出发,所涉及的硬件主要是JobTracker和TaskTracker。显然硬件故障就是JobTracker和TaskTracker机器故障。
在Hadoop集群中,任何时候都只有唯一的一个JobTracker。所以JobTracker的单点故障是所有故障中最严重的。到目前为止,在Hadoop中还没有相关的解决办法,能够想到的是通过创建多个备用JobTracker节点,在主JobTracker失败之后采用选举算法(一种Hadoop中常用的确定主节点的算法)来重新确定JobTracker节点。一些企业提供Hadoop服务时,就是通过使用了这种方法来解决这种问题[8]。
TaskTracker故障相对较为常见。并且MapReduce也有相应的解决办法,主要是重新执行任务。在实际任务中,MapReduce作业还会遇到用户代码缺陷或进程崩溃引起的任务失败等情况。用户代码缺陷会导致它在执行过程中抛出异常,导致任务执行失败,这种情况下TaskTracker会报告给JobTracker,JobTracker会重启这个任务。
3 MapReduceV2研究
新版本的MapReduceV2又称为YARN,是为了解决旧版的MapReduce的问题才出现的。旧版MapReduce的局限性在于:
· 可靠性差,旧版采用了主从结构,导致主节点存在单点故障,一旦主节点出现问题整个集群就无法工作,而且单点故障发生后恢复的难度很大。
· 可扩展性差,在旧版本的MapReduce中JobTracker同时作为资源管理器和作业调度器两个角色,当集群逐渐扩大时,JobTracker的压力会越来越大,成为了Hadoop系统的瓶颈,制约了Hadoop集群的可扩展性。
· 只能支持MapReduce编程框架,随着互联网的高速发展,MapReduce的简单离线批处理框架已经很难满足所有需求,出现了实时流处理框架如storm、迭代计算框架Spark等,但是旧版的MapReduce不能支持这些框架。
· 资源利用率低。为了解决旧版MapReduce的这些局限性,促进Hadoop更加长远的发展,Hadoop对MapReduce框架进行了完全重构,从根本上发生了变化。
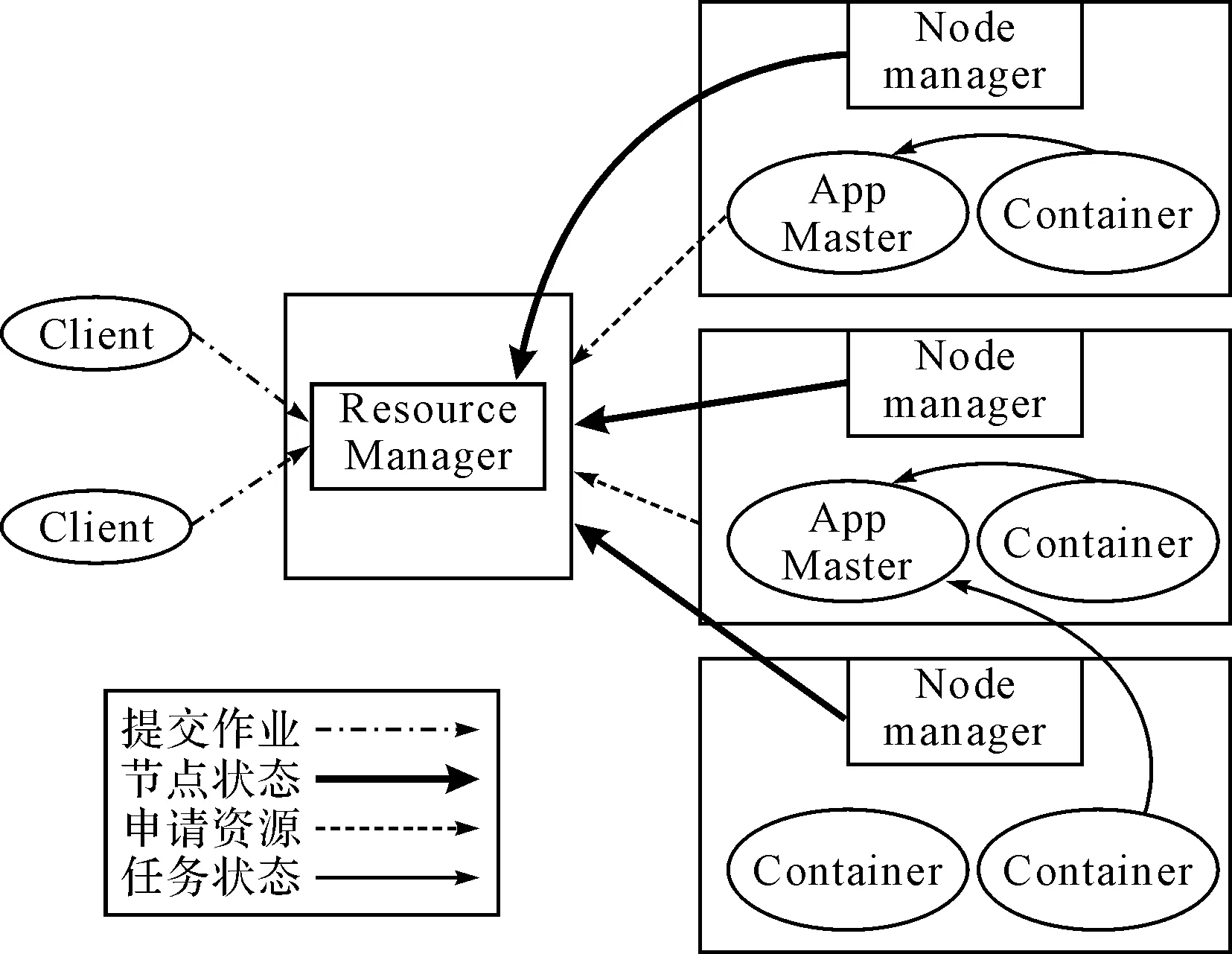
图3 MapReduce2架构图
重构的根本思想是将JobTracker的资源管理和任务调度这两个主要功能进行分离,由两个单独的组件完成。新的资源管理器全局管理整个集群上所有计算资源的分配;YARN为每一个应用分配一个ApplicationMaster,由它负责相应作业的调度和资源的协调。
RsourceManager是一个主节点,它负责管理集群中所有资源的统一管理和分配,它接受来自各个节点上NodeManager的资源汇报信息[9]。它主要由两个组件构成:资源调度器和ApplicationMaster管理器。资源调度器根据作业的情况、集群中计算资源的情况,将系统中的资源分配给正在运行的应用程序。资源调度器为每个应用程序分配的资源的单位是Container,它是一个抽象的单位,是一种动态的资源分配单位,将CPU、内存、磁盘、网络等资源封装在一起[10]。应用程序管理器负责生成、管理整个集群中运行的所有ApplicationMaster,监控ApplicationMaster的运行情况,在它失败时重启。
YARN的主节点ResourceManager只是负责简单的任务调度和资源分配,不在监控和记录每个任务的执行状态,也不再负责执行失败任务的重启等,只负责监控和重启ApplicationMaster,极大的减少了本身的资源开销,而且单点故障对整个集群的影响变得很小,恢复也因此变得更加容易。
NodeManager是从节点,是单个节点上的任务和资源管理器,部署在集群的每台机器上,它管理这集群中的单个节点中的资源,监控Container的生命周期和资源使用情况,还负责与ResourceManger进行通信,报告节点计算资源的使用情况、节点的健康状况等。
ApplicationMaster是单个作业的管理器和任务监控,每个作业都有一个相对应的,负责向ResourceManager的资源调度器申请资源,管理监控整个作业所有任务的状态[11]。
YARN是一个弹性的计算平台,它不再只局限于MapReduce编程模型,而是同时支持多种编程模型如Spark,即是共享集群的模式。YARN的优势:
· 资源利用率高,一个框架一个集群会造成资源占用的不均衡,某个框架因应用多而造成集群资源紧张,而某个框架因应用少而造成集群资源浪费。而YARN通过多种计算框架共享一个集群,使得集群利用率更高。
· 数据共享,随着数据量的增加,移动数据的代价越来越大,YARN模式可以有效的降低这种代价。
· 运维成本低。从运维多个集群到一个集群,大大降低了运维成本。
4 新旧版本的对比
首先说下相同点,客户端不变,应用程序调用的API接口大部分保持了兼容,使得以前的代码可以很容易的移植到新的框架上。
区别:
原来框架中的JobTracker和TaskTracker不见了,取而代之的是ResourceManager、NodeManager和ApplicationMaster三个。
其中ResourceManger起到了JobTracker的资源分配的作用,它做的关于作业调度的就只有启动、监控每个作业所属的ApplicationMaster,并重启故障的ApplicationMaster。不再负责原来框架中JobTracker的监控、重启每个Task。使得单点故障的影响变得更小,恢复更加容易。ApplicationMaster负责一个作业的整个生命周期,起到了原来框架JobTracker的任务调度的作用,但是每一个作业都有一个ApplicationMaster,它可以运行在ResourceManager机器上,也可以运行在NodeManager机器上,所以不存在Application Master单点故障的问题。
新框架的优势:
1) 新框架将JobTracker的分离,减少了它的资源消耗,使系统更容易从单点故障中恢复,并且监测每个作业子任务状态的程序分布式化了,更安全。
2) 在新框架中,ApplicationMaster是可变的,可以为不同的计算框架编写自己的ApplicationMaster,使得更多的计算框架可以运行在Hadoop集群上。
3) 在老框架中,JobTracker最大的负担就是要监控每个作业下的任务的运行情况,还要负责重启故障的任务,新框架中这部分由ApplicationMaster来完成,而ResourceManager上的任务管理器只需要监控ApplicationMaster的状态。
4) Container很好地起到了资源隔离的作用。
5 结语
新框架的出现,不仅仅解决了旧框架的很多问题如单点故障恢复,还增加了很多新的特性,本文先任务调度、资源分配等方面介绍了两种框架的特点,然后对比了二者的不同,注重新框架带来的相对于旧框架的优势。
[1] 李建江,崔健,王聃,等.MapReduce并行编程模型研究综述[J].电子学报,2011,11:2635-2642. LI Jianjiang, CUI Jian, WANG Dan, et al. Survey of MapReduce Parallel Programming Model[J]. Acta Electronica Sinica,2011,11:2635-2642.
[2] 杜江,张铮,张杰鑫,等.MapReduce并行编程模型研究综述[J].计算机科学,2015,S1:537-541,564. DU Jiang, ZHANG Zheng, ZHANG Jiexin, et al. Survey of MapReduce Parallel Programming Model[J]. Computor Science,2015,S1:537-541,564.
[3] 李芬,朱志祥,刘盛辉.大数据发展现状及面临的问题[J].西安邮电大学学报,2013,5:1-3.
[4] 亢丽芸,王效岳,白如江.MapReduce原理及其主要实现平台分析[J].现代图书情报技术,2012,2:60-67. KANG Liyun, WANG Xiaoyue, BAI Rujiang. Analysis of MapReduce Principle and Its Main Implementation Platforms[J]. New Technology of Library and Information Service,2012,2:60-67.
[5] 韩海雯.MapReduce计算任务调度的资源配置优化研究[D].广州:华南理工大学,2013. HAN Haiwen. Researches on Optimization of Resource Allocation for MapReduce Scheduling[D]. Guangzhou: South China University of Technology,2013.
[6] 徐淑琦.基于MapReduce的高性能云计算任务调度技术的研究[D].北京:北京工业大学,2013. Xu Shuqi. The Research on High Performance Task Scheduling Technology Based on Mapreduce in Cloud Computing[D]. Beijing: Beijing University of Technology,2013.
[7] 王博,陈莉君.Hadoop远程过程调用机制的分析和应用[J].西安邮电学院学报,2012,6:74-77. WANG Bo, CHEN Lijun. Analysis and application of mechanism of Hadoop RPC communication[J]. Journal of Xi’an University of Posts and Telecommunications,2012,6:74-77.
[8] 戎翔,李玲娟.基于MapReduce的频繁项集挖掘方法[J].西安邮电学院学报,2011,4:37-39,43. RONG Xiang, LI Lingjuan. A method for frequent set mining based on MapReduce[J]. Journal of Xi’an University of Posts and Telecommunications,2011,4:37-39,43.
[9] 詹文涛,艾中良,刘忠麟,等.一种基于YARN的高优先级作业调度实现方案[J].软件,2016,3:84-88. ZHAN Wentao, AI Zhongliang, LIU Zhonglin, et al. A Kind of High-priority Job Scheduler Implementation based on YARN[J]. Computer Engineering & Software,2016,3:84-88.
[10] 董春涛,李文婷,沈晴霓,等.Hadoop YARN大数据计算框架及其资源调度机制研究[J].信息通信技术,2015,1:77-84. DONG Chuntong, LI Wenting, CHEN Qingxia, et al. Research on the Framework and Resource Scheduling Mechanisms of Hadoop YARN[J]. Information and Communications Technologies,2015,1:77-84.
[11] http://hadoop.apache.org/[EB/OL]. 2016.
Comparative Study of Old and New Architecture of Hadoop MapReduce
YU Jinliang ZHU Zhixiang LI Congying
(Xi’an University of Posts and Telecommunications, Xi’an 710061)
After a reconstruction of Hadoop MapReduce framework, it changes a lot. This paper firstly describes the architecture of the old version of MapReduce, processes in which the job execution scheduling, resource allocation and other tasks, it points the limitations of the framework. And then it introduces the new architecture, task scheduling and resource allocation. Compared both new and old architecture, it points the advantages of the new framework. With the new generation MapReduce framework YARN, it applications using different computational framework on it, and reduce the difficulty of operation and maintenance, improve the utilization of cluster resources.
MapReduce, YARN, task schedule, resource allocation
2016年7月13日,
2016年8月28日
2015年工信部通信软科学研究项目(编号:2015-R-19);2015陕西省信息化技术研究项目课题(编号:2015-002)资助。
于金良,男,硕士研究生,研究方向:大数据分析处理。朱志祥,男,教授,研究方向:计算机网络、信息化应用和网络安全。李聪颖,女,硕士研究生,研究方向:云计算与大数据。
TP274.2
10.3969/j.issn.1672-9722.2017.01.018
猜你喜欢
吉林大学学报(信息科学版)(2022年2期)2022-08-15
计算机测量与控制(2022年2期)2022-03-30
英语文摘(2020年10期)2020-11-26
军事运筹与系统工程(2019年4期)2019-09-11
信息化建设(2019年2期)2019-03-27
电子制作(2018年11期)2018-08-04
计算机系统应用(2018年7期)2018-07-18
智富时代(2018年3期)2018-06-11
智富时代(2018年3期)2018-06-11
计算机应用(2016年10期)2017-05-12
