
基于FPGA的CAVLC解码器设计
2017-02-03 05:04:45马雨然任超伟张文明
电子设计工程 2017年21期
马雨然,任超伟,张文明
(中国科学院光电技术研究所四川成都610209)
H.264视频编解码标准是由ITU-T视频编码专家组和ISO/IEC运动图像专家组(MPEG)共同提出的数字视频压缩标准[1]。H.264的熵编码部分采取了3种编码方式,不同的方式对应不同的解码方法。在基本档次中,残差数据的编码采用基于上下文的自适应变长CAVLC编码,而图像参数集,序列参数集等码流控制信息采用指数哥伦布(Exp-Golomb)编码。主要档次采用基于上下文的自适应二进制CABAC编码。扩展档次只支持CAVLC而不支持CABAC,并且包含了基本档次的所有功能。
H.264标准具有优异的解压缩性能和良好的网络亲和性,但这都是以较高的算法复杂度作为代价换取的。为了解决在CAVLC查表耗时较长的问题,国内外学者对CAVLC解码算法和结构进行了大量研究。黄明政等采用计算方法代替查表方法减少条件判断,实现零内存存取,以此提高解码速[2]。贾俊玲利用码字头部对码表分组,在熵解码质量没有下降的情况下,解码速度提高了4倍[3]。李桃中等人提出了伪并行结构的幅值解码,半个时钟周期解码一个幅值,实现了1080P高清视频实时解码[4]。Lo C C等人也提出了最大匹配查找表方法[5]。韩一石等人对码字前缀进行一级索引,对码字后缀进行二级索引,显著提高了解码时间和存储空间[6]。这些方法都旨在改变CAVLC解码器的吞吐量,调高解码速度。
文中介绍了H.264标准解码的原理和过程,在此基础上介绍了CAVLC的解码过程并分析了该过程各个部分的复杂度。最后提出了分组与计算结合的算法,提高解码速度。
1 CAVLC解码器
1.1 H.264解码器结构
H.264标准并没有明确规定解码器如何实现,只是规定了视频比特流的句法以及解码方法。解码器分为两个模块:码流解析和图像重构。其中熵解码、反变换、反量化是属于码流解析部分。解码过程如图1所示。

图1 H.264解码器结构
开始解码时,由编码器的NAL输出一个压缩后的H.264压缩比特流,经熵解码得到量化后的一组变换系数X,再经反量化、反变换,得到残差利用从该比特流中解码出的头信息,解码器就产生一个预测块P,它和编码器中的原始P是相同的。当该解码器产生的P与残差相加后,就产生再经滤波后,最后就得到滤波后的这个就是最后的解码输出图像。其中熵编码部分采用可选的CAVLC和CABAC,下面将对CAVLC进行分析。
1.2 CAVLC解码器结构
图像中相邻的残差块相关性比较大[7],CAVLC将码表设计成与图像残差块的非零系数和拖尾系数相关,并且本残差块的系数要由相邻残差块的非零系数个数解出,这体现的CAVLC基于上下文的思想。
CAVLC主要用于亮度和色度的残差块编解码。经过编码器的预测、变换和量化后,码流中的残差块数据具有以下特点[8]:
1)非零系数主要集中在低频部分,而高频部分主要是0。
2)量化后的数据经过Zig-zig扫描后,在直流DC附近的系数幅值都比较大,而在高频的非零幅值大部分都是+1和-1。
3)相邻的残差块的非零系数的个数是相关的。
CAVLC编解码充分利用了这些码流特性,减少数据中的冗余信息,提高H.264标准的压缩比。
CAVLC解码主要包括非零系数个数TotalCoeffs模块、拖尾系数符号TrailingOnes模块、非零系数幅值Levels模块、总零个数TotalZreos模块和游历零个数RunBefores模块。对于TrailingOnes模块,其本质也是对于非零系数幅值的解析,本文将其与Levels归并为同一模块。这些模块之间通过一个状态机控制进行协调解码。每一个模块解析完成之后,都要计算出所消耗的码流长度,通过指针偏移调整码流的输入。CAVLC解码结构如图2所示。

图2 CAVLC解码器结构
通过对CAVLC的运算复杂度分析,查表部分占23%,RunBrfores占24%,非零系数幅值的计算占53%[9]。在CAVLC的4个子解码器中,TotalCoeffs和TotalZeros是基于查表的。Runbefores一部分是用通过查表解析每个非零系数前0的个数,另一部分是完成Levels和Runbefores的合并,最终形成残差系数。而Levels通过不断循环计算每个幅值的前缀和后缀,耗时较多。
1.3 CAVLC状态控制
虽然在H.264标准中明确说明了解码的流程,但是对于不同的设计方法会根据自身设计的特点定制不同的状态机。如果严格按照H.264的解码流程设计状态图,则状态较多且状态跳转繁琐[10]。本文在采用了一种改进的状态机,简化后如图3所示。
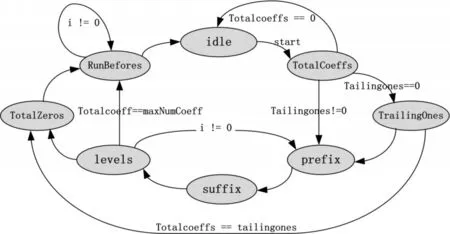
图3 CAVLC状态转换图
首先解析非零系数个数TotalCoeffs,如果TotalCoeffs=0,则整个残差数据块全部为0,直接回到初始状态。若TrailngOnes=0,不需要解析拖尾系数的符号,直接开始解析Levels;若TotalCoeffs=TrailingOnes,表示除了拖尾系数之外没有其他的非零系数,则进行TotalZeros解析。不断循环解析幅值的前缀和后缀,直到所有幅值解析完毕。解析完幅值之后,当TotalCoeffs=maxNumCoeff,表示没有0存在,直接输出残差系数。
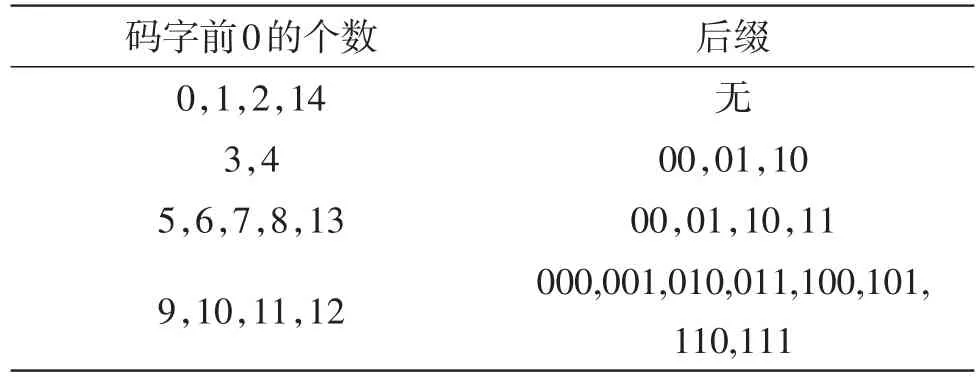
表1 码表规律
对于不同的后缀,可以才采用不同的计算方法,例如当码字前的0个数为5时,规律如表2所示。
2 混合分组和计算的查表
CAVLC关于TotalCoeffs和TrailingOnes的码表共有5个,其中定长码表1个,变长码表4个。关于Level_prefix的码表1个,关于TotalZeros的码表15个,关于RunBefores的码表7个。整个CAVLC解码的过程,本质就是查表的过程。对于码流的查表,已经提出的有全码表法,二叉树法,分组码表法等[11-13]。本文采用计算方法解析定长码表,分组方法解析变长码表,在分过组的变长码表中部分采用计算方法。
文献[14]将码字分解为码字头和信息码,根据码字头进行分组,从而提高了解码速度。但是这没有考虑到CAVLC码字的特性。CAVLC根据大量视频统计,出现概率高的码字长度短,出现概率低的码字长度较长。基于以上特点,本文根据码字前0的个数进行分组来提高解码速度。
分组查表过程受限于对码字的判断和比较,而计算方法可以不通过比较而直接进行解析,提高解码的速度。不同码表分组情况不同,在分组后尽量使用计算方法代替查找方法。以变长码表0<=nC<2为例,分组情况如表1所示[11]。

表2 前缀0个数为5时码表规律
不难发现,这种方法将变长编码分组后,转化为了定长编码。除了后缀rbsp_data[6:7]为00时,TotalCoeffs和TrailingOnes满足如下关系:

nC>=8时为定长表格,计算方法与上述码字前个数为5的方法类似。当码流rbsp_data[0:5]!=000011时,TotalCoeffs和TailingOnes满足如下关系:

在解码时,只需要判断检测码流是否为000011。若不是000011,直接根据码流计算出非零系数个数TotalCoeffs和拖尾系数个数TrailingOnes的值,而无需二次查表,减少查找和判断的次数。
这种方法缩短了CAVLC解码过程中对输入码流作判断的次数、减少了表的遍历深度和访问次数,是一种具有可行性的优化方案。综上所述,可概括此CAVLC解码算法的步骤如下:
step1:根据nC的取值确定所需要的码表。
step2:读取码流,检测码流前缀0的个数。
step3:根据前缀0的个数确定码表分组,再根据后缀计算所需要的解码参数。
3 实验结果
对上述的CAVLC解码器用verilog HDL硬件语言编写了程序代码,采用Xilinx的ISim的仿真功能对代码进行了功能仿真和时序仿真。综合时选定的FPGA器件为Zynq XC7Z045。
测试序列通过264文件转化为文本文件,作为ISim的Testbench的输入序列。当000101000000 00000000101011(nC=0),1(nC=1),000100111100((nC=1)),1(nC=1),1(nC=0)作为输入序列时,仿真结果如图4所示。通过与264文件产生的残差系数对比,可知本文的CAVLC解码器功能正确。
时序仿真过后,结果显示CAVLC解码器的关键路径延时为11.870 ns,采用83.3 MHz时钟,选取三组视频序列对本文所述的解码器进行测试,统计每个宏块所消耗的时间周期。实验结果如表3所示。

图4 CAVLC解码器仿真图
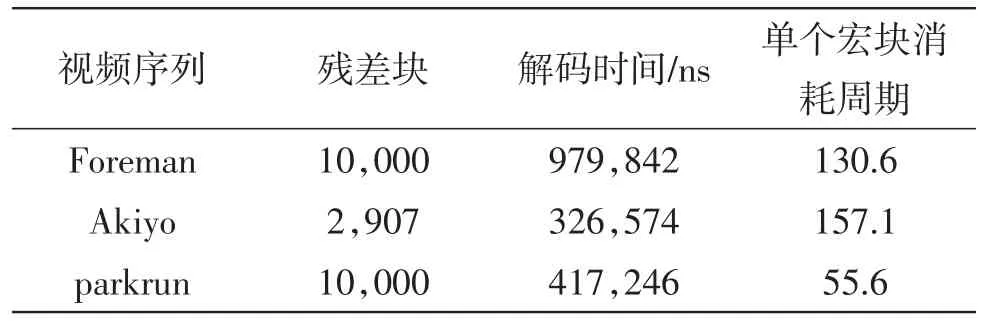
表3 解码器测试
从统计结果可以看出,Akiyo每个宏块平均消耗的时钟周期最多,为157.1。为了保证余量,假设每个宏块消耗的时钟周期为200个。根据吞吐率公式[15](1)计算得到本文所述的设计吞吐率为416 500 MB/s。

FCLK表示时钟频率,NMB表示解码一个宏块消耗的平均时钟周期,表4列出了帧率为30的不同清晰度视频的吞吐率和本设计的吞吐率对比。
对比结果显示,本设计的吞吐率要高于1080P视频所要求的吞吐率,满足1080P@30fs的视频解码。如需解码帧率为60的视频码流,相应的吞吐率会变成帧率为30的2倍,本设计可以满足720P@60fs的解码要求。

表4 吞吐率对比
4 结论
文中从CAVLC解码原理出发,分析了各个解码模块的复杂度。为了提高CAVLC解码器的解码速度,本文提出了CAVLC解码码表进行分组查表,查表之后通过计算得到残差系数的方法,提高了CAVLC解码系统的吞吐率。实验结果表明,本文设计可以正确的完成解码,并满足帧率为30的1080P视频解码要求。
[1]International Telecommunication Union.Advanced Video Coding for Generic Audio Visual Services[EB/OL].(2011-11-01).http://citeseerx.ist.psu.edu/showciting?cid=323674.
[2]黄明政,韩一石.一种可实现零内存存取的CAVLC 解码算法[J].计算机工程,2014(3):60.
[3]贾俊玲,刘彦辉.码字前缀分组的CAVLC解码优化[J].中国新技术新产品,2010(4):2-3.
[4]李桃中,王进祥,苏阳平,等.H.264中CAVLC解码器的设计与优化[J].微电子学,2015(3):372-375.
[5]Lo C C,Hsu C W,Shieh M D.Low-complexity multi-standard variable length coding decoder using tree-based partition and classification[J].IET Image Processing,2013,7(3):185-190.
[6]韩一石,王建华,黄明政,等.基于索引查询的CAVLC解码算法优化[J].计算机工程与应用,2012,48(13):167-170.
[7]何腾波,盛利元,蒋文明.H.264/AVC中CAVLC编码器的硬件设计与实现[J].电子技术应用,2010(7):66-68.
[8]何腾波.H.264/AVC中CAVLC编码器的硬件设计与FPGA实现[D].长沙:中南大学,2010.
[9]Tsai T H,Fang T L,Pan Y N.A novel design of CAVLC decoderwith low powerand high throughput considerations[J].Circuits and Systems for Video Technology,IEEE Transactions on,2011,21(3):311-319.
[10]Xu K,Liu T M,Guo J I,et al.Methods for power/throughput/area optimization ofH.264/AVC decoding[J].Journal of Signal Processing Systems,2010,60(1):131-145.
[11]付永庆,姜灵灵.H.264硬件解码核的FPGA实现[J].电视技术,2012,36(19):59-63.
[12]李芬,包晓敏.基于CAVLC解码算法优化的研究[J].浙江理工大学学报,2013,30(4):550-553.
[13]黄明政,王建华,韩一石,等.一种基于CAVLC解码的快速码表查找算法[J].计算机工程,2013,39(2):23-26.
[14]Ghorbani S,Zargari F.A unified architecture for implementation of the entire transforms in the H.264/AVC encoder[J].InternationalJournalof Multimedia and Ubiquitous Engineering,2013,8(1):41-54.
[15]李桃中.高清H.264熵解码器设计与实[D].哈尔滨:哈尔滨工业大学,2014.
猜你喜欢
电视技术(2021年8期)2021-10-21 08:19:48
视听(2021年8期)2021-08-12 10:53:42
扬子江诗刊(2018年1期)2018-11-13 12:23:04
中国自行车(2018年9期)2018-10-13 06:17:04
舰船电子对抗(2018年3期)2018-08-28 02:02:56
扬子江(2018年1期)2018-01-26 02:04:06
优雅(2017年8期)2017-08-08 06:01:53
中国自行车(2017年1期)2017-04-16 02:54:07
中国自行车·骑行风尚(2014年6期)2015-01-06 00:58:23
电子技术与软件工程(2014年20期)2014-11-19 09:55:45
