
一种利用虚拟数据学习的电力部件识别方法
2017-02-03 05:04:10吴亮谢予星邹鹏飞
电子设计工程 2017年21期
吴亮,谢予星,邹鹏飞
(1.武汉大学遥感信息工程学院,湖北武汉430079;2.克莱姆森大学计算学院,美国克莱姆森29634)
近年来,随着电力线路智能巡检的发展,采用直升机、无人机等收集影像越来越多的代替了人工攀塔勘察,因此相应的关于电力设备的图像数据量也越来越大。同时,通过使用基于机器学习的方法来自动总结归纳特征,目标检测问题越来受益于日渐丰富的图像数据。但是由于电力方面的应用专业性强、使用范围窄而没有公开的相对完善标注的电力设备影像数据集,因此在影像目标检测越来越受到数据驱动的今天,电力设备的检测一直受数据不足或者标记数据质量不高的制约而发展较为缓慢。虚拟数据具有获取相对方便,可自动生成标注等的优点,研究虚拟数据的生成、虚拟数据在机器学习中的使用对解决上述问题具有重要意义。
在前人研究的基础上,本文旨在解决在电力设备实拍数据以及相应标注信息数量较少或没有的情况下,得到相对准确的检测结果的问题。因此本文先通过通用虚拟场景生成引擎,模拟出防振锤可能存在的场景以及电塔等容易对防振锤造成遮挡的物体,再将防振锤虚拟模型放入场景中通过一定的策略获取虚拟样本集,并以该虚拟样本集作为训练样本,实验了HOG[7]特征、类Haar特征[8]与卷积神经网络(Convolutional Neural Network,CNN)[10],并通过对实验结果以及理论进行分析,得出比较可靠的防振锤检测结果,以作为之后深度学习的初始标注,或者在不能得到实拍训练数据的特殊情况下的使用。
1 虚拟数据集构建
1.1 利用虚拟引擎构建目标和场景模型
在本文实验中,待训练和识别的目标以防振锤为例,配套设备主要包括高压电塔和电线。这类设备均是按照实物的相关参数和剖面图在3DS Max软件中人工建模而成。其尺寸可人为根据所处的虚拟场景进行参数上的调整和控制,以保证虚拟物件与虚拟场景具有合适的比例关系。本文实验所选用的防振锤是最常见的两种型号——FD型和FR型,如图1所示。

图1 防振锤模型
1.2 虚拟样本数据生成
虚拟影像数据的获取,是借助游戏引擎中的相机(Camera)功能,对待获取目标(本实验中为防振锤)进行模拟拍照并将拍照结果实时渲染输出成通用的图片影像格式。其主要流程如图2所示,其中N表示拍摄的影像张数,n表示当前已拍摄影像数目,W表示影像的宽度(像素为单位),H表示影像的高度(像素为单位),Xmax表示待摄目标在影像水平方向上的最大像素坐标,Xmin表示待摄目标在影像水平方向上的最小像素坐标,Ymax表示待摄目标在影像竖直方向上的最大像素坐标,Ymin表示待摄目标在影像竖直方向上的最小像素坐标。
在获取虚拟影像的过程中,还需要考虑如下几个方面:
1)保证训练的有效性,虚拟数据集应避免相机位置、摄影姿态、拍摄视场角等摄影要素过于单一。本文设置了两个矩形区域作为相机的随机运动区域。
2)保证目标样本影像成像角度的多样性,可以目标为中心设置一长方体或立方体区域并随机运动。

图2 虚拟样本生成流程
3)减少人工标注的工作量,在虚拟场景中可以对兴趣结构预设最小外接长方体。本文的防振锤3个部分的外包围盒。
4)进行拍照之前,还应判断待拍摄目标是否完整位于影像中。
5)在游戏3D虚拟引擎中,事件的进行通常以帧为单位。因此在完成1)-3)所述准备工作后,按帧执行相应的函数功能,每一帧获取一张影像并输出。
按照本节所阐述方法,本文实验共产生了7 062张防振锤目标样本,其中FD型3 529张,FR型3 533张,如图3所示为5种典型的防振锤及其背景。

图3 虚拟样本示例
2 基于机器学习的目标检测
在本文实验中,采用的是Faster R-CNN、DPM以及组合类Haar级联分类器3种方法进行检测试验。Faster R-CNN[10]是一种用于目标检测的多层深度网络,由共享权值层以及其后连接的两个并行网络——区域提取网络(Region proposal network,RPN)和目标检测网络(Fast R-CNN)所组成。其中RPN向Fast R-CNN网络提供候选区以供目标检测,Fast RCNN又可以分为两个并行的外接框回归网络和目标类别分值网络,因此网络输出是被检测图像中可能含有防振锤的区域位置坐标和可能性得分值。
DPM[9]通过提取HOG特征得到目标的轮廓信息,建立目标整体与各部件间在一定程度上可变的相对位置关系来检测目标物体。DPM可以在没有使用防振锤部件标注的情况下,分别使用大小两个分辨率的图像来获得防振锤整体和部分的HOG特征,用多模型来表达防振锤的不同视角,最后通过latent-svm方法学习得到防振锤各个模型、子模型以及模型和子模型之前的位置关系。在检测的阶段,则通过与训练得到的模型、子模型以及相互之前的位置关系来判断一个区域是否是防振锤,给出可能性分值以及防振锤的外接矩形。
虚拟仿真场景在拍摄时可以精确的知道目标物体及其各部件的位置,在训练类haar特征的级联分类器时可以分别对防振锤整体、连接器与两边的锤体建立3个级联分类器。在用adaboost计算训练分类器时都是用统一大小的正方形样本作为输入数据集以及级联分类器的特性,类haar特征的级联分类器的输出结果分别是防振锤整体、连接器与锤体的外接正方形。但是这些分类器单独使用由于特征较少而不能产生很好的分类效果,本文采用将整体与部件分类器根据其几何位置组合起来的方法进行实验。
3 检测实验与分析
文中针对实际拍摄的防振锤影像用第二章所提到的方法对训练得到的分类器进行结合,来得到最终的检测结果。
3.1 分类器的训练
本文实验了3种分类器,分别为Faster R-CNN分类器、DPM分类器以及基于类Haar特征的级联分类器。其中,基于类haar特征的级联分类器又分别由防振锤整体、连接器以及锤体分类器所组成。
对于Faster R-CNN分类器,本文采用了两种CNN网络结构作为对比试验,第一种是在论文[11]中所提出较浅的ZF网络,除了输入输出层共有5层共享权值层;另一种是论文[12]中提出的VGG16网络,共有13层共享权值层。由于Faster R-CNN自动选择候选区域作为负样本,因此其所有样本均是用第1节方法生成的虚拟样本,为7062张虚拟影像样本。
DPM分类器中,对于训练用的正样本与上述相同,使用虚拟影像。负样本不需要进行标注,本实验使用了50幅从1 500万像素到2 400万像素不等的负样本。本实验采用的模型数为3,同时训练了两种子模型数分别为3个与8个的分类器来做比较。
类haar级联分类器的训练使用的是OpenCV中所提供的Adaboost级联分类器的训练方法。虚拟影像可以提供包括防振锤整体和其各部件在图像上的精确位置,对于防振锤整体与连接器的训练,其样本与DPM分类器相同。最终,防振锤整体分类器共使用了2 064个特征;连接器分类器共用了1 181个特征;锤体分类器共包含1 623个特征。
3.2 检测及结果分析
本文的检测实验是在19幅没有参与训练的含有防振锤的实拍电力场景影像上进行,影像中总共包含有88个人眼可辨别或者人工可根据场景上下文推断出的防振锤。在本文的检测实验中,本文将与图像上的真实防振锤矩形区域交集与并集之比大于0.5的检测矩形框视为正确的检测结果。
表1为使用3种方法所得的实验结果,检测精度使用的是平均精度,表中加粗的部分是最好结果项。图4是与表1相对应的接收者操作特征(Receiver Operating Characteristic,ROC)曲线。其中,组合Haar指的是将防振锤整体与连接器、锤体分类器根据几何位置组合起来的检测器。从表中与图中可以看出,DPM取得了最好的结果,其次是Faster R-CNN,而组合Haar检测器则得到了较差的检测结果。
虽然Faster R-CNN具有检测速度快,准确率高等的优点,但是虚拟防振锤与真实拍摄的防振锤在特征表达上还具有一定的差异性。因此只用虚拟仿真模型生成的图像样本训练得到的深度模型对实际目标物体的预测能力并不十分理想。而DPM由于其主要代表的是梯度也即目标的轮廓特征,从而避免了虚拟数据对颜色、纹理等特征模拟的不足,因而能够得到最好的效果。组合类Haar检测器则因为模拟数据中的矩形类Haar特征并不能很好的代表真实世界中防振锤与背景环境的复杂相对关系,所以即使采用组合的分类器也不能得到很好的效果。

图4 检测结果ROC曲线
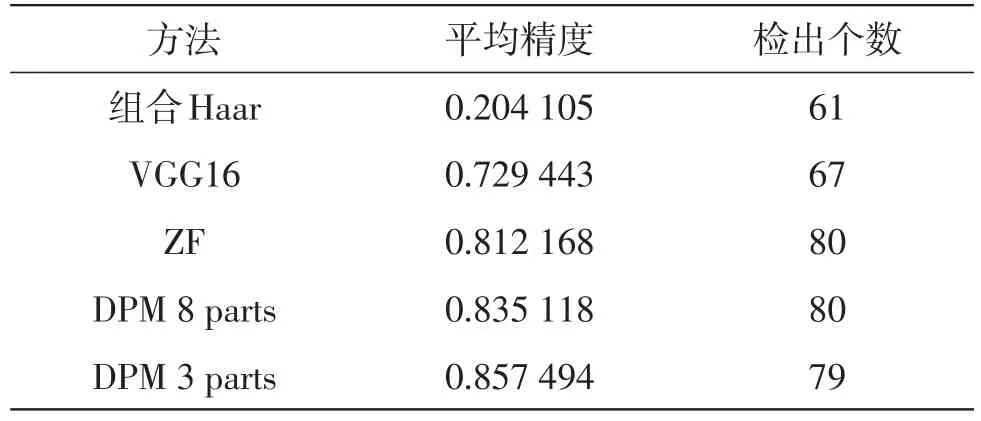
表1 检测结果
如图5所示为DPM所学习到的防振锤特征图,可以看出DPM特征与防振锤内部纹理相关性较小,体现的主要是其轮廓信息。从表1检测结果可以看出,具有3个子模型的分类器比有8个子模型的分类器有着更好的表现,这表明了在训练DPM时,根据目标物体本身的特征先验知识选择模型数与子模型数是非常必要的,而不是模型数越多越好。如图5(a)与图5(b)所示,防振锤可分解为三个部分,那么3个子模型已经可以较好的表达出防振锤的各部件特征关系,而且与我们对防振锤的先验知识相近,但8个子模型则略显冗余。另外,3个子模型的DPM也具有较为明显的速度优势,相比于8个子模型的DPM可节省近40%的检测时间。

图5 防振锤DPM特征图
根据Faster R-CNN检测器的结果可以看出,虽然有着更深层网络的VGG16在训练时有更低的损失值,但是在检测时相对于ZF网络不论对前景防振锤还是对背景防振锤都只得到了较低的AP。同时基于ZF网络的Faster R-CNN分类器检测出了更多的防振锤,这是因为VGG16网络虽然有着更为强大的拟合能力,可对训练集进行更精确的学习和描述,但是作为训练集的虚拟样本与真实样本还存在一定的数据域偏置,而对训练域出现了一定程度的过拟合,导致检测效果不如ZF网络。另外可以看到使用了VGG16网络的虽然AP较低,但这主要是由于VGG16检测出的防振锤较少造成的,由ROC曲线可以看到,基于VGG16的Faster R-CNN在得分较高的区域具有较好的精度,也即对与训练集更相像的目标有着更好的表现。这也说明了如果在后续训练中如果能够加入实拍数据集,如利用DPM在实拍数据集上检测结果再加上少量的人工筛选,那么更深的网络就会得到更好的表现。
4 结束语
文中针对电力设备影像及可靠标记数据缺乏的问题,提出了一种电力设备虚拟场景生成、虚拟影像及标记的获取方法,并基于虚拟样本集在没有迁移学习的情况下实验了一系列不同的目标检测方法,并以防振锤为对象证明了DPM在虚拟数据集上有着最好的效果。通过实验,本文还得到以下两个结论:
由于虚拟样本的数据域偏置,较浅的ZF网络相对于较深VGG16取得了更好的效果。但是VGG16由于有较强的拟合能力,在对防振锤成像质量较好的部分可以得到更高的分值,因此当通过本文的方法在实拍影像上进行检测,并以检测结果作为补充样本对基于更深层网络的Faster R-CNN进行迁移学习时,将会得到更好的表现。
通过防振锤的检测说明,基于先验知识选择DPM分类器的模型数与子模型数可以得到更好的效果。因此在训练其他电力设备分类器时,要合理利用相应电力设备的先验拍摄与结构知识,并对复杂结构的电力设备进行适当的分解,才会在DPM分类器上得到较好的结果。
[1]于旭,杨静,谢志强.虚拟样本生成技术研究[J].计算机科学,2011,38(3):16-19.
[2]Pishchulin L,Jain A,Andriluka M,et al.Articulated people detection and pose estimation:Reshaping the future[C]//Computer Vision and Pattern Recognition (CVPR) ,2012 IEEE Conference on.IEEE,2012:3178-3185.
[3]余萍,董保国.基于SIFT特征匹配的电力设备图像变化参数识别[J].中国电力,2012,45(11):60-64.
[4]张宏钊,黄荣辉,姚森敬,等.对嵌入式系统的电力设备紫外监测系统设计的分析[J].电子设计工程,2016,24(11):112-114.
[5]翟永杰,伍洋.基于3D模型和AdaBoost算法的绝缘子检测[J].传感器世界,2014(10):11-14.
[6]翟荔婷,张冰怡,冯志勇,等.基于3D塔架配准的绝缘子自爆缺陷检测[J].计算机工程与科学,2016,38(8):1688-1694.
[7]Dalal N,Triggs B.Histograms of oriented gradients forhuman detection[C]//2005 IEEE Computer Society Conference on ComputerVision and Pattern Recognition(CVPR'05).IEEE,2005,1:886-893.
[8]Viola P,Jones M.Rapid object detection using a boosted cascade of simple features[C]//International Conference on Computer Vision and Pattern Recognition,Kauai,USA:IEEE,2001:511-518.
[9]Felzenszwalb P F,Girshick R B,Mcallester D,et al.Object detection with discriminatively trained part-based models[J].IEEE Transactionson Pattern Analysis and Machine Intelligence,2010,32(9):1627-1645.
[10]Ren S,He K,Girshick R,et al.Faster R-CNN:Towards real-time object detection with region proposal networks[C]//Advances in Neural Information Processing Systems.2015:91-99.
[11]Zeiler M D,Fergus R.Visualizing and understandingconvolutionalnetworks[C]//EuropeanConference on Computer Vision.Springer International Publishing,2014:818-833.
[12]Simonyan K,Zisserman A.Very deep convolutional networks for large-scale image recognition[J].arXiv preprint arXiv:1409.1556,2014.
[13]Marin J,VáZquez D,GeróNimo D,et al.Learning appearance in virtual scenarios for pedestrian detection[C]//Computer Vision and Pattern Recognition(CVPR),2010 IEEE Conference on.IEEE,2010:137-144.
[14]Aubry M,Maturana D,Efros A A,et al.Seeing 3d chairs:exemplar part-based 2d-3d alignment using a large dataset of cad models[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition,2014:3762-3769.
[15]Girshick r,Donahue j,Darrell T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.2014:580-587.
[16]Girshick R.Fast r-cnn[C]//Proceedings of the IEEE International Conference on Computer Vision,2015:1440-1448.
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
电子测试(2018年1期)2018-04-18 11:52:35
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
数学学习与研究(2017年3期)2017-03-09 18:12:42
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
中国老区建设(2016年1期)2016-02-28 09:32:00
