
新浪微博数据爬取研究
2017-01-21 22:11陈智梁娟谢兵傅篱
物联网技术 2016年12期
关键词:新浪微博
陈智++梁娟++谢兵++傅篱

摘 要:新浪微博的快速发展促进了基于微博数据的研究发展,如何获取微博数据是开展相关研究的首要问题。文中就分析爬取新浪微博数据的方法,提出了一种基于Python的语言,直接设置已登录用户Cookie信息,模拟浏览器访问的新浪微博数据爬取方案,解决了不使用新浪微博开放平台API爬取微博数据的主要问题,所实现的爬虫程序编程简单、性能稳定,能有效获取微博数据。
关键词:新浪微博;数据爬取;微博爬虫;Python
中图分类号:TP391;TP311 文献标识码:A 文章编号:2095-1302(2016)12-00-04
0 引 言
随着互联网的不断普及,人们越来越多地参与到互联网的社交活动中,微博作为典型的互联网社交活动,得到了迅速发展。新浪微博是国内出现最早,也是规模最大的微博社区,新浪微博数据中心发布的“2015微博用户发展报告”指出:“截止2015年9月,微博月活跃人数已达到2.22亿,较2014年同期相比增长33%;日活跃用户达到1亿,较去年同期增长30%。随着微博平台功能的不断完善,微博用户群逐渐稳定并保持持续增长。”[1]
微博用户群的增长使得基于微博数据的社交网络分析[2]、用户行为分析[3, 4]和网络数据挖掘[5]等相关研究越来越受到人们的重视,而如何从微博爬取感兴趣的数据则成为研究者要解决的首要问题。本文分析微博数据的爬取方式,提出一种基于Python模拟浏览器登录的微博数据爬取方案,并讨论针对微博反爬机制的相关处理。
1 微博数据的爬取方式
微博数据的爬取通常有两种方式,一种是调用新浪微博开放平台提供的微博开放接口,另一种是开发爬虫程序,模拟微博登录,分析获得的HTML页面,提取所需信息。
1.1 调用微博开放接口
新浪微博开放平台[6]提供了二十余类接口,覆盖了微博内容、评论、用户及关系的各种操作,理论上该方法是最直接、方便的方式。但新版的微博开放接口存在一些限制,对于小型研究团队或个人而言不是很方便,突出表现在以下几点:
(1)微博开放接口使用Oauth2.0认证授权,如果希望得到另外一个用户的个人信息和微博内容,则必须由该用户授权;
(2)微博开放接口存在访问频次限制,对于测试用户的每个应用,每小时最多只能访问150次;
(3)很多研究所需要的数据只能通过高级接口才能访问,需要专门申请和付费。
正是因为这些限制的存在,自己设计开发网络爬虫程序获取微博数据就成了必不可少的备选或替代方案。
1.2 开发微博爬虫程序
设计开发微博爬虫程序需要分析新浪微博的特点、明确爬取数据的目的及用途,选择合理的开发语言,保证高效、稳定地获取微博数据。
1.2.1 新浪微博的特点
与一般网站相比,新浪微博具有以下特点:
(1)新浪微博面向登录用户,在访问微博数据前,用户必须先登录;
(2)微博博文的显示采用了延迟加载机制,一次只显示一个微博页面的部分博文,当用户浏览博文滚动到底部时,才继续加载当页的其他博文;
(3)新浪微博有较完备的反爬虫机制,一旦微博服务器认定爬虫程序,就会拒绝访问。
基于新浪微博的上述特点,在设计微博爬虫时,需要对以上特点进行针对性处理。
1.2.2 开发语言选择
从快速获取微博数据的角度看,Python是开发微博爬虫的首选语言,其具有如下特点:
(1)Python是一种解释型高级语言,具有文字简约、容易学习、开发速度快等特点;
(2)Python具有较丰富的库及第三方库,在开发爬虫方面比其他语言方便。考虑新浪微博在一段时间后就会微调其数据格式,因此使用Python开发微博爬虫程序具有较高的易维护性。
2 微博爬虫的实现
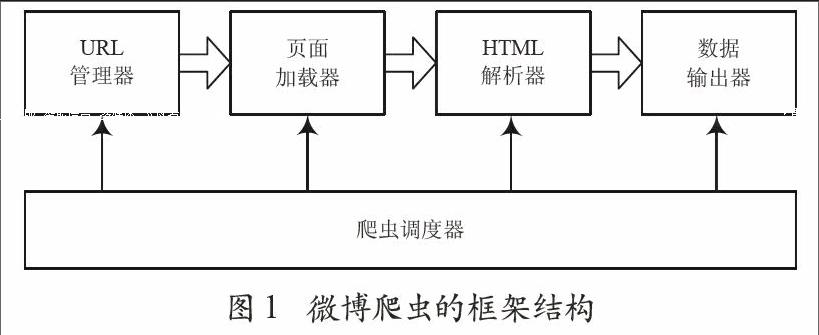
2.1 微博爬虫的框架结构
本文讨论的微博爬虫程序包括爬虫调度器、URL管理器、页面加载器、HTML解析器和数据输出器五个功能模块,其框架结构如图1所示。
图1 微博爬虫的框架结构
2.1.1 爬虫调度器
爬虫调度器是爬虫的控制程序,主要负责协调和调度微博爬虫的各个模块,其核心功能包括以下几项:
(1)实现爬取微博数据的流程;
(2)控制其他模块的执行;
(3)模拟浏览器登录,为页面请求添加Headers信息;
(4)控制微博访问频率,避免反爬虫机制拒绝访问。
2.1.2 URL管理器
微博爬虫采用广度优先遍历策略提取需要的数据,URL管理器需维护已经爬取的URL列表和等待爬取的URL列表。在得到新URL之后,首先检查已经爬取的URL列表,如果该URL不在列表中,则将其添加到等待爬取的URL列表。
2.1.3 页面加载器
页面加载器根据爬虫调度器提供的Headers信息以及URL管理器提供的URL,向微博服务器发出请求,获得所请求的HTML页面。为了避免爬取过于频繁,导致微博服务器无法及时响应,或被服务器反爬虫机制拒绝访问,页面加载器采用定时机制限制加载页面的频率。
2.1.4 HTML解析器
HTML解析器对页面加载器提供的HTML页面进行解析,获取需要的数据。如某位微博用户发表的博文内容、转发数、点赞数、评论数等。同时HTML解析器会根据需要将新得到的URL反馈给爬虫调度器。
2.1.5 数据输出器
数据输出器输出HTML解析器解析后的数据。输出的数据采用JSON格式,其格式与使用新浪微博开放平台API获取的数据格式基本一致,保证不同爬取方式得到的数据能够被统一分析和处理。
2.2 模拟浏览器登录
要访问微博数据,必须要先登录。可以用爬虫程序模拟微博用户登录[7, 8]。爬虫程序首先向微博用户服务器发送登录请求,然后接收服务器返回的密钥,再结合用户名、密码、服务器返回的密钥生成验证信息,登录服务器。只要保持与服务器的Session会话,就可以从服务器获取微博数据,从而进一步分析。
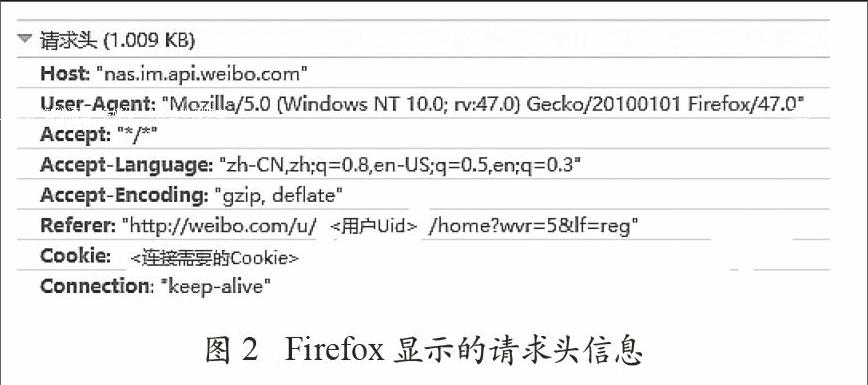
这种做法实现比较复杂,并且需要了解服务器验证信息的细节。因此采用另一种相对简单的做法,即本文微博爬虫的做法。首先在浏览器中登录微博,然后使用浏览器提供的开发者工具查看请求页面的请求头信息。例如使用Firefox登录微博后,利用Firefox提供的开发者工具可以看到如图2所示的请求头信息。
从图2可以看出,“Referer”的内容是访问微博的URL,其中“<用户Uid>”是当前用户在微博的唯一标识id;“Connection”的值为“keep-alive”,标识Cookie永不过期;“Cookie”的内容是成功连接微博服务器后保存在本地的Cookie,利用它可以简单、快速地访问新浪微博。首先需复制“<连接需要的Cookie>”的内容,然后在Python中定义headers对象,设置Cookie和Connection,最后在每次访问微博页面时,都将headers作为参数添加到Request对象中,得到微博页面。这样在Cookie的有效期内就可以直接访问微博,并提取自己需要的数据。采用这种做法,只需以下代码就可以实现微博的登录并简单获取页面数据:
headers = {'Cookie': ‘<连接需要的Cookie>,Connnection:keep-alive}
url = u'http://weibo.com/u/<用户Uid>/home?wvr=5&lf=reg'
request = urllib.request.Request(url, headers=headers)
rsponse = urllib.request.urlopen(request)
page = response.read()
2.3 微博页面解析
爬虫程序成功登录到微博,获取微博页面后,就可以对得到的HTML脚本进行解析,提取需要的数据。一条博文的数据主要包括发表博文的用户昵称、用户Uid、主页链接、博文内容、发表时间、转发数、评论数、点赞数等。除此以外,转发其他用户的微博是非常常见的现象,因此在提取博文数据时,也需要考虑被转发的微博用户的相关数据信息。
进一步分析微博页面可以发现,每一条博文均是以
开始,内部以
标签形成树结构,其主结构如表1所列。


2016年12期
- 资讯博览
- 物联网产业(2016年11月)
- 陕西物联网产业联盟出席2017“物联中国”年度盛典启动仪式
- 秦鹭话物联,合作共发展
- 五种技术趋势重塑制造业
- 2016智能家居产业年度解析:安全仍是最大难题
- 斑点猫:以安全为核心,定义物联网智能指纹锁
- 绿茵舞者
- 天使的守护
- 智能药箱
- 陕西物联网产业联盟(ASII)
- 学术研究
- 基于ZigBee的人体健康数据采集系统的设计
- 气压高度计的测量误差分析及修正方法
- 基于ZigBee养老院室内外定位系统的实现
- 动态心电心阻抗监测系统的研究
- 基于ZigBee+云服务器的桥梁基质稳定性监测系统
- 基于ODAC的权限管理机制
- MDCF压接式微矩形型电连接器的研制
- 老龄化社区智能服务平台及其数据分析
- 仿微信扫码登录系统的实现与改进
- 监狱安全防范综合管理系统效能评估指标体系分析
- 一种基于微信平台的智能家居系统
- 一种应用于低功耗植入式医疗芯片的无线能量管理单元
- 基于云计算的智能充电桩管理系统的研究
- B/S架构下的学生信息管理系统的设计
- 基于物联网的小区天气反馈调节智能窗户系统设计
- 新浪微博数据爬取研究
- 基于物联网的晋陕豫黄河金三角地区智慧旅游研究
- 浅谈基于物联网技术的能源管理系统
- 基于ZigBee技术的智能家居系统设计
- 基于物联网的智能检测飞行器设计
- 基于涡旋谐振环的人工磁导体的设计与应用
- 智能穿戴设备监测数据的分析及研究
- 基于视频的带电作业中组合间隙的智能检测
- 快递物品远程自动接收系统设计与开发
- 基于Netty+WebSocket的社区增值服务平台的推送设计
- 有刷式航空直流电机装配试验中的关键工艺分析
- 语音业务多系统融合技术研究与实现
- 基于改进演化算法的自适应医学图像多模态校准
- 基于WiFi和移动终端的智能照明控制系统设计
- 军工企业集中式信息化平台方案研究
- 一种基于微信的智能灯光控制系统的设计
- 去除印制板三防涂覆材料的工艺研究
- 基于开源平台Arduino的大学创客实践探索
- 高职课程信息化教学设计实践与研究
- 大数据背景下高职计算机网络专业课程体系改革研究
- 移动教育App的研究现状分析
公司地址: 北京市西城区德外大街83号德胜国际中心B-11
客服热线:400-656-5456 客服专线:010-56265043 电子邮箱:longyuankf@126.com
电信与信息服务业务经营许可证:京icp证060024号
Dragonsource.com Inc. All Rights Reserved
一种处理办法是多次发送模拟HTTP请求的GET方法,构建响应的URL,完成整页加载[8];另一种处理办法是使用selenium模拟浏览器滚动条操作,在Ajax加载后再获取页面数据,这种方法的参考代码如下:
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Firefox()
driver.set_page_load_timeout(30)
def scroll(driver):
driver.execute_script("""
( function () {
var y = document.body.scrollTop;
var step = 100;
window.scroll(0, y);
function f() {
if (y < document.body.scrollHeight) {
y += step;
window.scroll(0, y);
setTimeout(f, 50);
} else {
window.scroll(0, y);
document.title += "scroll-done";
}
}
setTimeout(f, 1000);
""")
3 反爬虫机制及对策
如果爬虫爬取过“猛”,就会为微博服务器带来不小的压力。新浪微博有比较完备的反爬虫机制,用以识别和拒绝爬虫访问。虽然新浪官方并没有提供具体的反爬虫机制说明,但是通过分析常用的反爬虫策略[9],可以发现主要的爬虫识别方法有以下几种:
(1)通过识别爬虫的User-Agent信息来拒绝爬虫;
(2)通过网站流量统计系统和日志分析来识别爬虫;
(3)通过实时反爬虫防火墙过滤爬虫。
为了避免微博反爬虫机制拒绝访问,本文的微博爬虫采取了伪装User-Agent与降低请求访问频率来反爬虫对策。
3.1 伪装User-Agent
User-Agent用于描述发出HTTP请求的终端信息。浏览器及经过企业授权的知名爬虫如百度爬虫等都有固定的User-Agent信息,本文讨论的微博爬虫伪装浏览器通过微博登录来爬取特定数据。在请求头headers中,采用交替伪装User-Agent的方法来避免爬虫User-Agent的识别和访问流量统计异常。
例如以下四个User-Agent信息,分别从使用Windows Edge、Firefox、Chrome和360浏览器访问微博时的请求头中提取。
Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2486.0 Safari/537.36 Edge/13.10586
Mozilla/5.0 (Windows NT 10.0; rv:47.0) Gecko/20100101 Firefox/47.0"
Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.94 Safari/537.36
Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36
在Python中定义headers对象时,交替随机选择其中的一条添加到headers对象中,将爬虫的HTTP请求伪装成某个浏览器的访问。
3.2 降低请求访问频率
如果爬虫程序爬取过于频繁,则会降低微博服务器的响应效率,影响一般用户的正常使用。反爬虫防火墙往往会根据请求的访问频率来判断客户端是一般用户的人工操作还是爬虫程序的自动运行。因此适当降低爬虫程序的请求访问频率既可以避免连接超时错误的发生,还可有效应对反爬虫机制。
4 结 语
综上,本文实现的微博爬虫能够有效爬取新浪微博数据,实现简单、性能稳定,并能较好的避免反爬虫机制的检测。其具有如下主要特点:
(1)直接获取已登录用户的Cookie,避免了模拟登录的繁琐;
(2)基于lxml解析微博数据,简化了数据筛选的操作;
(3)使用selenium模拟滚动条滚动,解决了Ajax延迟加载页面的问题;
(4)使用伪装User-Agnet以及延迟访问来避免反爬虫机制的过滤。
但该设计的主要缺陷是没有使用多线程导致爬取效率不高,不适用于海量数据爬取,用户可根据需要进行适当改动。
参考文献
[1]新浪微博数据中心.2015微博用户发展报告[R].2015.
[2]曹玖新,吴江林,石伟,等.新浪微博网信息传播分析与预测[J].计算机学报,2014(4):779-790.
[3]叶勇豪,许燕,朱一杰,等.网民对“人祸”事件的道德情绪特点——基于微博大数据研究[J].心理学报,2016,48(3):290-304.
[4]王晰巍,邢云菲,赵丹,等.基于社会网络分析的移动环境下网络舆情信息传播研究——以新浪微博“雾霾”话题为例[J].图书情报工作,2015,59(7):14-22.
[5]丁兆云,贾焰,周斌.微博数据挖掘研究综述[J].计算机研究与发展,2014,51(4):691-706.
[6]微博开放平台API文档[EB/OL].http://open.weibo.com/
[7]周中华,张惠然,谢江.基于Python的新浪微博数据爬虫[J].计算机应用,2014,34(11):3131-3134.
[8]吴剑兰.基于Python的新浪微博爬虫研究[J].无线互联科技,2015(6):94-96.
[9]邹科文,李达,邓婷敏,等.网络爬虫针对“反爬”网站的爬取策略研究[J].电脑知识与技术,2016,12(7):61-63.
