
Web日志矩阵挖掘算法研究
2017-01-13 09:06邵天会
中国新通信 2016年22期
邵天会
【摘要】 Web日志常用的挖掘算法焦点在用户访问习惯上提取相关数据,主要的算法有Apriori,最大向前算法,拓扑算法等,这些算法只是简单的设计用户的访问频度,通过用户访问频度进行达到用户兴趣度的测量,其实这不是很精确的解决方法。因为影响网页相应的因素很多,比如网页之间的自动链接,页面和页面之间的相对位置都会起到至关重要的作用。矩阵算法进行有向图的转换,用户信息的存储利用,同时利用Apriori算法进行事务集的筛选,统计,综合各种算法的优点,提出一种基于矩阵的改进的挖掘算法进行用户兴趣度的挖掘。
【关键字】 Web日志 挖掘算法 用户兴趣度
一、基础概念
定义 1:会话矩阵:用户会话集合的二维矩阵,列为会话,行为访问路径,每行代表一个用户访问一次的记录,一列代表用户对该站点访问的总量。
定义 2:用户访问的遍历矩阵:行为访问路径,列为当前访问路径结束或者跳转。添加支持度m,构成路径:引用页面----访问页面----页面访问频度。同时在矩阵的第一个单元格设置一个null值,表示用户直接进入该网站的url,而没有通过其他的页面跳转,如果网站有n个url,该网站可以形成n+1矩阵。
定义 3:页面的距离:会话矩阵任意两行x,y。如果x>0则x=1,同理y>0则y=1,构成向量x,y-à0,1。我们就称x,y之间的页面距离为d。
定义 4:兴趣支持度:假设所有访问路径S中,t是属于S的子集,如果x属于t,那么可以认为x和S中的路径前m位是相同的,不同的t就得出多种相同m位,归集相同的部分得出用户的兴趣支持度
定义 5:支持----偏向度:设支持度是s,兴趣支持度为 P则支持----偏向度为Ps=(S×P)。
二、基于用户访问的矩阵算法实现
算法步骤:数据清理、用户识别、会话识别、相似用户的相关页面聚类及频繁路径。
2.1 数据清理
只保留get方式获取的数据,过滤掉其他和算法不相关信息。
2.2 用户识别
通过IP地址进行识别用户。
2.3会话识别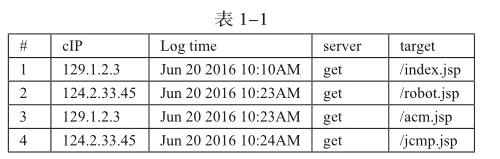
结合最大向前路径和时间窗口模式进行设计算法-----用户事务识别算法,该算法由事务分割、事务合并两部分组成。事务分割:将web数据库通过最大向前路径和时间窗口模式进行分割为符合两者标准的短事务;分割原则:当相邻的访问路径超过了设定的时间窗口,或者不同的IP事务集中已经存在该路径,那么就进行分割。分割结果:一个页面只包含在一个事务中。例如表1-1中第1-3条记录,由于IP地址不同相同的页面被分割为3个事务。
记录合并:将用户本来属于同一路径,但是在分割阶段进行不同实务分割,进行按照IP地合并,即相同用户访问记录合并。
例如:表1-2显示的是进行合并后的结果。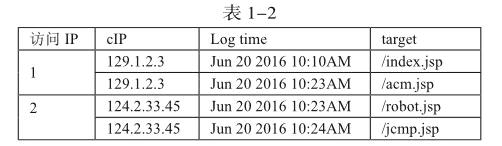
按照定义 4建立用户会话矩阵:以访问路径为行,回话ID为列,建立会话矩阵SM[][],SM[m][n]:用户访问页面m中第n次访问。SM[m][]:针对某具体页面m的访问记录。SM[][n]:访问记录n对所有浏览过的页面。用户会话矩阵无法显示用户访问先后次序问题,因此我们设计了用户访问的遍历矩阵。根据定义5得出:以访问路径为行,标识ID为列生成路径MT[][]矩阵,MT[m][n]:m页面链接访问n页面的会话集合。第一行表示用户直接访问该网页,不经过其他跳转,一般可视为用户首次进行会话。第一列表示用户结束本次会话,跳转到其他页面或者结束访问。
2.4 相似用户的相关页面聚类
本算法的设计中,关键是利用访问页面频度st和页面访问距离dt对网页进行筛选,根据预先设定的访问页面频度st,将页面的访问次数归集到Fs中,从而把Fs中的小于dt页面距离值的进行聚类。
2.5 访问路径的挖掘
假设S_Set={pag-1, pag-2,…pag-n},通过用户访问的遍历矩阵MT[i][j]中pag-1,pag2…pagn相对应的i和j值,生成新的矩阵MT[n+1][n+1],然后在其中找出所有大于偏向----支持度的项,最后构成我们需要的访问路径集合,再将得到的频繁路径合并,到无法合并停止,即我们需要的频繁访问路径
三、验证性试验
平台:IOS平台利用Edv C++ 实现该挖掘算法和经典的Apriori算法,在某学校的网站上对50M日志文件进行分析,以1M,2.7M,3.2M,5.9M,6.7M,7.2M,8.7M7个测试点进行用例分析。在Intel(R)Celeron(R)CPU 2.8 GHz,2GRAM平台进行数据测试,试验结果如图1-1所示。
图1-1得出相同数据和平台上,用户矩阵算法比Apriori算法用时明显降低,并且随着数据的增大用户矩阵算法表现出良好的稳定性,曲线变化平缓,表现出算法的扩展性优点,而Apriori算法随着数据的增大时间曲线波动变化明显,因此在面对此类问题时本文的用户矩阵算法明显优于Apriori算法。
参 考 文 献
[1]Bing Liu(美).Web Data Mining[M].北京:清华大学出版社,2009.
[2]朱志勇,徐长梅,刘志兵,胡晨刚.基于贝叶斯网络的客户流失分析研究[J].计算机工程与科学.2013(03)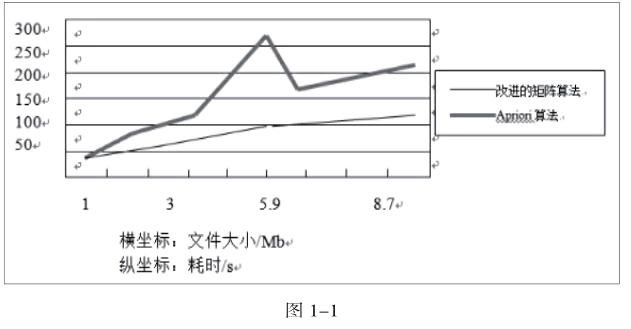
猜你喜欢
电脑爱好者(2021年21期)2021-11-04
发明与创新·中学生(2021年1期)2021-01-19
诗选刊(2020年12期)2020-12-03
思维与智慧·上半月(2018年10期)2018-11-30
思维与智慧·上半月(2018年9期)2018-09-22
电脑知识与技术(2017年27期)2017-11-20
计算技术与自动化(2017年3期)2017-10-26
妇女之友(2017年3期)2017-04-20
科技创新与应用(2017年3期)2017-02-18
电脑知识与技术(2014年30期)2014-11-19
