
面向用户需求的自适应学习系统个性化学习路径推荐研究
2017-01-03 22:04赵学孔岑磊
中国教育信息化·高教职教 2016年11期
关键词:关联规则
赵学孔 岑磊

摘 要:面向用户需求构建个性化学习环境是当前E-learning领域研究的热点。自适应学习系统(Adaptive Learning System,ALS)是E-learning个性化学习支持服务的解决方案。针对ALS推荐学习资源的精准性与有效性问题,文章尝试性从用户学习路径的视角出发,在对学习者与领域知识建模的基础上通过关联规则挖掘技术动态匹配与重组学习资源,进而实现ALS个性化学习路径推荐机制。仿真实验结果表明,利用本推荐机制在一定程度上能有效推荐学习资源,进而较好地满足当前用户个性化学习需求。
关键词:自适应学习系统;个性化学习路径;学习者模型;领域知识模型;关联规则
中图分类号:G434 文献标志码:A 文章编号:1673-8454(2016)21-0028-04
当前,数字化学习(E-learning)席卷远程教育领域,成为网络信息时代盛行的一种重要学习方式。E-learning打破了传统面授式教育模式的常态化,突破学习的时空限制,为学习者“随时随地”学习提供了可能。然而,调查显示,当前许多E-learning支持平台的实际应用效果并不理想,其中最为突出的问题是平台忽视了“以学习者为中心”的现代教学理念,不能根据用户的个性化需求准确提供学习资源,进而导致在线学习效果不明显。[1]正因如此,关于E-learning环境下的个性化学习理论与实践研究受到众多学者关注,构建支持用户个性化学习需求的E-learning系统成为当前迫切而重要的研究主题。
一、ALS及其研究现状
ALS,即自适应学习系统,亦称适应性学习系统,是在建构主义“以学习者为中心”的现代教育模式引领下提出的一种针对当前学习者的个体特征差异(如年龄、专业背景、兴趣偏好、认知水平等)而动态提供其个性化学习支持服务的系统,其最早由国外以智能教学系统和适应性超媒体系统的术语提出,近年已成为E-learning远程教育领域研究的热点。[2][3]个性化推荐机制是ALS的核心部件,其主要功能是对学习资源的有效匹配与重组,进而满足当前用户的个性化学习需求。
目前,关于ALS的研究尚处于探索时期。国外介入该领域研究较早,典型的代表主要有:Brusilovsky等人首次提出了适应性学习系统,并认为可以从课程序列化与适应性导航技术实现系统的适应性效果;[4]Tang等人采用聚类分析与协同过滤方法将用户访问页面序列和内容进行筛选与分类并推荐给用户,进而构建了ALS系统原型;[5]美国匹兹堡大学Weber G等人通过个性化导航策略实现了ALS适应机制,并开发了ELM-ART、Knowledge Sea系统原型;[6]Castro等人阐述了数据挖掘技术在网络学习过程中的重要作用,为基于数据挖掘的E-learning个性化学习研究奠定了基础。[7]国内该领域研究起步较晚,典型的代表有:华南师范大学陈品德教授从内容呈现和导航支持两方面考虑适应性,设计了A-Tutor原型系统;[8]中国台湾淡江大学利用Agent技术研发了分布式智能学习系统MMU,该系统具有一些简单的智能交互功能。[9]
纵观上述研究,国内外提出的许多ALS系统仍处于原型实验阶段,其适应性及个性化推荐机制还需要不断探索。因此,本研究拟尝试性地从用户学习路径的视角出发,在对学习者与领域知识建模的基础上,通过关联规则挖掘技术动态匹配与重组个性化学习路径,进而实现ALS推荐机制,以期满足当前用户个性化学习需求,同时为本领域相关研究提供参考借鉴。
二、ALS个性化学习路径推荐的解决方案
1.学习者建模
学习者是ALS的主要参与者与体验者,也是个性化资源获取的主体,因此ALS的设计首先应重点考虑学习者的个性化需求特性。为了更清晰地表征学习者对象在系统中的属性,我们需要将其实例化,即对学习者进行建模。可以说,学习者模型是ALS实现的基础,其主要借助用户建模组件或第三方代理软件实时收集并处理学习者个性化信息来实现。[3]本研究鉴于IMS LIP(Learner Information Package)标准,采用四元组的形式从基本特征、学习风格、认知水平和学习记录四个维度来表征学习者模型,其方法如下:
LearnerModel=(BaseInformation,LearningStyle,CognitiveLevel,AccessRecords)。
其中,BaseInformation用于表示学习者一些基本的静态信息,例如昵称、姓名、性别、年龄、专业背景、个人简介等。LearningStyle表示学习者的学习风格,其可借鉴Felder学习风格模型构建,包含值域定义为:{“直觉型-感知型”,“视觉型-言语型”,“活跃型-反思型”,“全局型-序列型”},该值域可通过ALS系统设定或完成Felder学习风格量表(ILSs)的形式获得。CognitiveLevel表示学习者当前所达到的认知水平,可以从“初级”、“中级”、“高级”三个层次表征,其主要以学习者的单元测试成绩为参考依据由系统自动评定。AccessRecords表示学习者在整个学习过程中的访问记录,包含访问者编号、访问时间、访问地址以及访问内容描述等基本信息,AccessRecords的表示方法为AccessRecords(Ri)=(LearnerId,AccessTime,AccessAdress,ContentInfo)。
2.领域知识建模
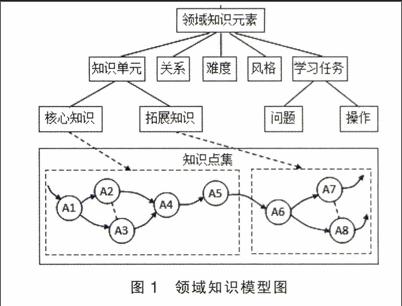
领域知识泛指专业领域内所有经验、理论、方法论的知识单元集群,而在计算机世界中我们将其界定为:针对某特定领域需要,采用某种(或若干种)表示方法将知识实体化与结构化,使其能在计算机存储、系统组织和管理方面具有易操作等特性的知识集群。[10]ALS中领域知识是对学习资源的结构化,其为学习者个性化学习提供数据来源。领域知识模型要求知识体系具有良好的结构关系,以便系统推荐资源路径时做出准确的判断。通常情况下,领域知识可用课程、知识单元和知识点(或知识项)三种粒度表征,知识之间的关系包括前驱后继关系、并列或包含关系以及相关关系三种类型,而每个知识单元或知识点都应包含难度、风格和学习任务属性。根据它们之间的逻辑关系,我们给出了领域知识模型的一般结构,如图1所示。
根据以上分析,我们将领域知识的结构模型表征为:KObject={Kid,Kname,Klevel,Kstyle,Kcontent,KOR}。其中,Kid表示知识点的唯一标识,Klevel表示知识点难度水平,Kstyle表示知识点的偏向风格,Kname表示知识点名称,Kcontent表示知识点内容信息,KOR表示知识点所属关系集合。基于上述三种关系类型,本研究中领域知识对象间的关系模型KOR可用如下表达式表示:
KOR(a,b)={
其中,Ktype表示关系类型(Ktype {“前驱”,“后继”,“并列”,“包含”,“相关”}),Kweight关系的权重值(Kweight [0,1],该值越高代表知识间的相关性越大)。例如,某领域知识a与b的关系记为KOR(a,b)={
3.关联规则定义及其推荐方法
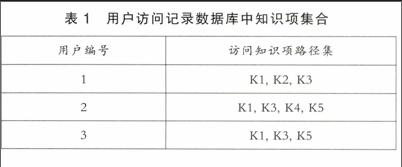
关联规则是数据挖掘领域研究的一个范畴,其最早由Agrawal等人提出,主要用于从数据集合中发现频繁项并找出项集间的关联关系。从本质上讲,关联规则挖掘是在事务数据集合D中发现满足用户给定的最小支持度min_support和最小置信度min_conf的频繁项集并挖掘其关联关系。[11]为了更清晰地反映ALS基于关联规则挖掘的推荐过程与方法,在此我们设定用户访问记录集(即日志事务集合)结构如表1所示。
(1)产生频繁项集
频繁项集是关联规则挖掘的第一环节,需要利用AprioriAll算法将表1中知识项集中频繁项找出。在此,设定最小支持度为0.6,则最小支持度计数为0.6×len(users)=1.8,频繁项集产生过程为:通过第一轮扫描得到候选集C1(Item,Support)={
(2)产生路径关联规则
通过上述频繁项集产生过程,用户访问记录集合产生的知识项集I={K1,K3,K5},设定最小置信度min_conf为0.8,那么得到候选关联规则置信度如表2所示。
由表2可知,当最小置信度为0.8时得到三条强关联规则,即:{K1,K5}?圯{K3},{K3,K5}?圯{K1},{K5}?圯{K1,K3}。由此得到当前用户的学习路径存在三种可能:KPa={K1,K5,K3},KPb={K3,K5,K1}或KPc={K5,K1,K3}。
(3)推荐路径预处理
推荐路径预处理是对学习路径的优化处理,该过程主要根据领域知识的关系模型KOR对强关联规则路径进行匹配,以选择最优学习路径。例如,设定本例中K1、K3和K5之间存在如下关系:KOR(1,3)={
三、仿真实验及其结果分析
为了检测本研究中ALS个性化学习路径的推荐效果,我们利用VC工具与C语言开发了ALS仿真运行环境。实验初始化数据由系统按照预先定义的权重参数随机自动生成,且设定系统每次随机生成30个知识项集,当最小支持度和最小置信度分别设置为0.6和0.8时,其运行效果如图2所示。
实验中,我们首先固定最小支持度和最小置信度阈值分别为0.8和0.6,经过10轮实验后从知识项平均访问频次与系统推荐频次两个维度对ALS推荐效果进行的分析,结果发现满足最小支持度时知识项平均访问轨迹与系统推荐路径轨迹趋势基本相似,说明系统推荐路径基本有效。然后,我们尝试性以0.05递增幅度调整最小支持度,再次经过10轮试验后从最小支持度Minsup与推荐知识项个数Kcount的分布关系进行分析(见图3),结果显示系统推荐知识项数量会随着Minsup的不断增加而减少,进一步说明系统推荐路径的精确性会随着Minsup的增加而提高。
四、结束语
基于Web的ALS是未来远程学习的一种有效途径,是个性化学习环境建设的趋势,目前仍有很大的探究空间。ALS主要是通过个性化推荐机制对学习内容进行有效筛选与重组来实现的,而学习者模型、领域知识模型以及关联规则挖掘技术是ALS个性化推荐机制形成的有效保障,对改进系统的推荐质量、提高学习者学习效率起着关键性作用。当然,由于诸多局限性因素,本研究仍存在不足之处,例如,ALS推荐路径的优化处理、推荐机制的效率问题等,这也是本研究下一步的趋向。
参考文献:
[1]刘丽萍,魏书敏,赵新云.个性化网络学习支持系统的研究[J].中国教育信息化,2010(23):47-51.
[2]牟连佳.网络化学习系统的适应性研究[J].电化教育研究.2009(5):48-53.
[3]赵学孔,徐晓东,龙世荣.B/S模式下自适应学习系统个性化推荐服务研究[J].中国远程教育,2015(10):71-80.
[4]Brusilovsky,P.(2001)Adaptive hypermedia.User Modeling and User Adapted Interaction,Ten Year Anniversary Issue(Aifred Kobsa,ed.)11(1/2):87-110.
[5]TangC.,Yin H.,LiT.,LauR.,LiQ.,&Kilis D.: Personalized courseware construction based on web data mining[C].In Proceedings of the first international conference on web information systems engineering,2000:204-211.
[6]Weber G,Brusilovsky P.ELM-ART: an adaptive versatile system for Web-based instruction [J].International Journal of Artificial Intelligence in Education,2001:351-384.
[7]CastroF.,VellidoA.,NebotA.,MugieaF.:Applying Data Mining Techniques to E-learning Problems[J].Studies in Computational Intelligence.2007(62):183-221.
[8]陈品德,李克东.适应性教育超媒体系统——模型、方法与技术[J].现代教育技术,2002(1):11-16.
[9]莫赞,冯珊,唐超.智能教学系统的发展与前瞻[J].计算机工程与应用,2002(6):6-7.
[10]李卫.领域知识的获取[D].北京:北京邮电大学,2008.
[11]Agarwal S. Data Mining: Data Mining Concepts and Techniques.International Conference on Machine Intelligence and Research Advancement.IEEE,2013:203-207.
(编辑:王天鹏)
