
Variable-length sequential dynamic features-based malware detection①
2016-12-29 05:34DuDonggao杜冬高LiGaochaoMaYan
High Technology Letters 2016年4期
Du Donggao (杜冬高), Li Gaochao, Ma Yan
(*Network and Information Center, Institute of Network Technology, Beijing University of Posts and Telecommunications, Beijing 100876, P.R.China)(**Beijing Key Laboratory of Intelligent Telecommunications Software and Multimedia, Beijing University of Posts and Telecommunications, Beijing 100876, P.R.China) (***National Computer Network Emergency Response Technical Team/Coordination Center of China, Beijing 100029, P.R.China)(****Institute of Information Engineering,Chinese Academy of Sciences, Beijing 100029, P.R.China)
Variable-length sequential dynamic features-based malware detection①
Du Donggao (杜冬高)②*, Li Gaochao*******, Ma Yan***
(*Network and Information Center, Institute of Network Technology, Beijing University of Posts and Telecommunications, Beijing 100876, P.R.China)(**Beijing Key Laboratory of Intelligent Telecommunications Software and Multimedia, Beijing University of Posts and Telecommunications, Beijing 100876, P.R.China) (***National Computer Network Emergency Response Technical Team/Coordination Center of China, Beijing 100029, P.R.China)(****Institute of Information Engineering,Chinese Academy of Sciences, Beijing 100029, P.R.China)
In order to solve the problem that traditional signature-based malware detection systems are inefficacious in detecting new malware, a practical malware detection system is constructed to find out new malware. Application programming interface (API) call sequence is introduced to capture activities of a program in this system. After that, based on variable-length n-gram, API call order can be extracted from API call sequence as the malicious behavior feature of a software. Compared with traditional methods, which use fixed-length n-gram, the solution can find more new malware. The experimental results show that the presented approach improves the accuracy of malware detection.
application programming interface (API) call order, variable-length, n-gram, malware detection
0 Introduction
Short for malicious software, malware is designed to exhaust system/network resources or infringe on a person’s privacy. Examples of such malware include virus, worms, Trojans and bots. Currently, the main difficulty of malware detection is the explosive growth of malware, which also presents great challenges to our nowadays society. According to China Internet Security Research Report in 2013, 1.2G suspicious samples were received, and 40.8 million samples were identified. Thus, signature-based malware detection systems need to update the signature repository constantly. However, it is impossible because of the exponential growth of malware. Actually, the number of the malware increases continuously because most of them have been widely adopted by self-protection techniques. Malware based on these techniques is divided into two categories: polymorphic and metamorphic[1]. Polymorphic malware has embedded encrypt engines. Therefore, it uses a random key to generate a new copy while being copied. As a result, the new copy generated by this technique is different from original malware, which leads to a large number of samples. Obviously, it is too hard to detect this type of malware by conventional detection of signature-based malware. Compared with polymorphic malware, metamorphic malware is the most complex type of malware because it can change self-forms each propagating and produce a new variant. The ways that malware alters itself are as follows: dead code insertion such as NOP instruction, register renaming, code transportation and instruction substitution. Thus, these transform techniques make many signature-based detection ineffective.
In the beginning, to extend the capabilities of string based signatures, various algorithms have been employed to detect malware variants with superior classification. The n-gram algorithm was first used in natural language processing field which assumed that the probability of the m-th byte conditions is on the occurrence of the preceding m-1 bytes. Then, n-gram algorithm was used in intrusion and malware detection field. Ref.[2] used varied-length n-grams in intrusion detection. Ref.[3] used n-gram algorithm to extract features from byte sequences. In malware detection field, an n-gram is one of all possible fixed or varied sized substring extracted from a larger string. Traditionally, it is a fixed-length byte string. For example, Ref.[4] first used machine learning to extract feature from PE head file as a signature that consisted of byte sequence based on four-gram. Refs[5,6] used data mining, machine learning and four-gram-based methods, then computed the information gain (IG) to select the most relevant 500 features which were formed from four byte strings in binary executables. Ref.[7] conducted several experiments in which they evaluated the mixtures of seven kinds of feature selection techniques, three classifiers and n-gram byte. However, n-grams are ineffective with polymorphic malware because of the changes of instruction level content[8].
In order to avoid the defects of n-gram byte based signature, malware behavior has been investigated. Since API is a procedure call interface to system’s resource, API call sequence is an excellent candidate for analyzing any malware behavior. For example, Ref.[9] firstly regarded API call sequence as a feature of a malware. Moreover, he constructed normal behavior profiles by short sequence of system call and used Hamming distance matching to construct an intrusion detection system. Besides, different order of each API in sequence infers different behavior model. Afterward, an extensive research worked on API calls, such as Ref.[10], Ref.[11] and Ref.[12].
Ye analyzed API call sequence extracting from PE files and used it as the feature to construct the intelligent malware detection system (IMDS)[13]. Ref.[14] constructed a signature for an entire malware family by static statistical comparison of the correlation of malware semantics and its API calls. They created a profile of a program behavior based on the frequency of critical API calls extracted from a program by statistical technique, then used them as a signature for malware family.
Therefore, it is a good choice to combine API call sequence with n-gram algorithm in malware detection. For example, Ref.[15] extracted API call sequence from an execution program by the dynamic analysis method, then utilized conventional fixed-length n-gram to constitute the feature set which consisted of the feature obtained from API call sequence. Finally, they used a best first selection method to reduce the size of feature set and got the optimal solution of n equaled four according to experimental results.
Currently, the most popular method of analysis of API call sequence uses fixed-length n-grams. Because the host makes fixed n-gram presentation, which is simple and more susceptible, the intruders desire that they could gain benefits by secreting malware and reaching the host. Moreover, some malware producers can escape the conventional detection, which is based on fixed-length n-gram, by inserting independent API call or irrelevant API call transposition obfuscation techniques in process.
To solve the above problems, a novel method is proposed to extract API call order from API call sequence as the feature by using variable-length n-gram. The rest of the paper is organized as follows: Section 1 presents our proposed approach. In Section 2, the experimental results are described and discussed. Finally, the study will come to the conclusion.
1 Proposed approach
A novel method based on variable-length sequential dynamic features for malware detection is proposed, which focuses on mining API call sequence for detecting unknown malware and malware variants. Above all, it is needed to extract the API call order of variable length from the API call sequence. Feature extraction model is shown in Fig.1.
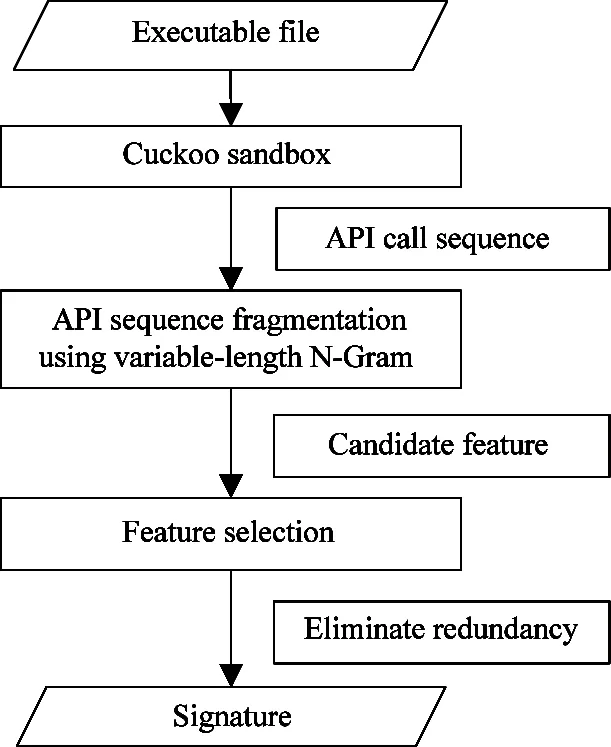
Fig.1 Feature extraction model
In the feature extraction model, firstly, API call sequence is extracted by executing program in Cuckoo Sandbox, an open source simulator of operating system. Secondly, API call order is extracted from the API call sequence by using variable-length n-gram. At last, the most discriminative features are selected to speed up the system.
1.1 API call sequence
At first, it is needed to extract API call sequence from executable files. There are two categories of methods to extract API call sequence. One is static analysis, the other is dynamic analysis.
Although static analysis can find all executing paths of malware, three main problems exist. To begin with, for most of packed malware, they need to be unpacked by particular tools such as UPX and PEID, which leads to hard work and failure sometimes. Then, it is fail to deal with polymorphic malware which could not be decrypted. Furthermore, it is hard to make a conclusion in some decision points so that a random decision is generally made in these points.
Compared with static analysis, dynamic analysis can solve these defects above. Dynamic analysis refers to analyze behaviors of the running executable program[16]. It is a method which actually executes a program in a controlled environment and monitors its behavior, system interaction, and the effects on the host machine. Generally, a program is running in a virtual machine or a sandbox, at the same time, it is monitored and logged API call sequence.
These sequences are usually used as feature sets in heuristic malware detection methods. The proposed approach is based on mining these features. There are some problems in dealing with API call sequence by data mining technique.
1.2 API sequence fragmentation
It is needed to construct a feature set according to extracted API call sequence when using the data mining technique. It is simple that each API call is used as a feature. Common method uses the identifying distinct API call order from this sequence set as a new feature to construct feature set. Although this method is simple and fast, it leads to low accuracy of detection method based on the feature set that misses an important portion of behavioral information of programs.
The n-gram method can fragmentize the API call sequence without missing significant information about call ordering. Eskandari extracted features from API call sequence and these features are based on conventional fixed-length n-gram method. And also, their experimental results showed that this method was better than the aforementioned one.
However, the method based on fixed-length n-gram has some problems. On one hand, different behavior of a malware corresponds to the different API call order. Furthermore, the number of API call is variable when malware completes different operations. Therefore, it is difficult for fixed API call to fully describe the behavior of malware. For example, malware completes a malicious operation through combination of CopyFileA, RegOpenKeyExA and RegSetValueExA (n equals tree), which is also used as a feature and can improve the accuracy of malware detection. However, Ref.[15] set n to the only value four according to their experimental results and they must not choose the 3-gram. In our experiments, the above combination appears with RegCloseKey, DeleteFileA, RegCreateKeyExA, WSAStartup or CreateThread, and these new combination (n=4) will no longer be used as features. On the other hand, the malware producers can escape the conventional detection, which use fixed-length n-gram method by inserting independent API call in process.
To solve above problems, different length grams are selected as features and set n to two, three, and four. Therefore, a new approach is proposed to extract fragments from each API call sequence by using variable-length n-gram and build a feature set with these fragments.
Algorithm 1: extract variable-length fragment from API calls and join the Ctmp
Input: Sin: set of API call sequences; //each sequence corresponds to a sample;
N: window length;
Output: Cout: constructed candidate feature set;
Ctmp: an empty set;
for each sequence s in Sin do
for each API i in s do
for each k in N do
fk= get a set of ithAPI up to (k+i)thitem;
add fkto Ck// Ckis a set of k length;
End
Add Ckto Ctmp
end
end
Cout= fetch unique features from Ctmp
Return Cout; //A set of subsequences
1.3 Candidate signature selection
(1) Information gain (IG)
Information gain is the reduction of entropy (or uncertainty) caused by partitioning a collection of examples according to a feature. It is a measure of the effectiveness of a feature in classifying examples[17]. The information gain IG(Ng) of a given n-gram(Ng) is defined in Eq.(1), and features are selected by computing the information gain for each fragment.
(1)
where Ng is a fragment (n-gram of API call sequence), C is the class of the samples and can be divided into two categories: Benign (B) and Malware (M), VNgis the value of n-gram Ng, VNg=1 if n-gram Ng occurs in the sample. It is 0, otherwise. P(VNg, C) is the proportion that feature Ng has the value VNgin the class C, P(VNg) is the proportion that feature Ng has the value VNgin the training data, P(C) is the proportion of the training samples belonging to the class C. (2) Candidate feature selection
Each fragment (n-gram) can be used as a feature, but not every feature is valuable. Such as, Email-Worm-Win32.NetSky.a has 44 kinds of 1-gram, 174 kinds of 2-gram, 321 kinds of 3-gram, 443 kinds of 4-gram and 568 kinds of 5-gram. In particular, all samples resulted in 44306 kinds of distinct n-gram when N equals five. One problem in this method is that the number of features is very large, which is dimension required, so the grams that have more valuable are chosen as candidate features.
According to the information gain, the best first selection method is used to choose the optimal features as a candidate signature. To further reduce the amount of features, the elements in the set of Ckare sorted by descending order according to the information gain. By parameter ε, the number of feature selected from Ckis |Ck|×ε.
(3) Signature selection
For further reduce the number of the features, a new algorithm is constructed.
Algorithm 2: generate the signature of variable-length gram
Input: Cout: Candidate feature set;
N:windows length;
Output: Dout: feature set;
Dout: an empty set;
for each k in N do
for each fkin Cout
if (mc>bc and α>0.6) then

End
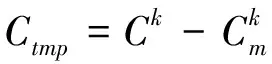
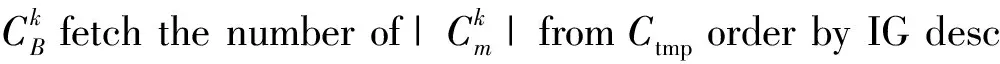

end
add Dkto Dout
end
return Dout
2 Experimental setup
In this section, the presented approach is evaluated. The used database and performance measures are described in detail.
2.1 Dataset description
Our experimental data consists of 172 benign executables and 183 Massive Mailing Worms as malware set, all of which are in Windows PE format. A mailing worm spreads copies of itself by email according to system mail addresses. These malware families include Bagle, Netsky, Zhetalin, Mydoom, and so on. And all downloaded from VX Heavens[18].
2.2 Experimental environment
API call sequences of samples are dynamically extracted from a fresh installed Microsoft Windows XP SP3 on a virtual machine. Moreover, some popular softwares are installed on that machine such as Microsoft Office, Python, Foxmail. The hardware configuration includes a Core(TM) i3-2.3GHz processor and 4 GB of RAM. The host is Ubuntu 13.04 server 64 bit operation system and the sandbox is Cuckoo 1.0.
2.3 Performance measure and classification
In this section, some commonly used measures are presented for evaluating the approach and measuring quantitatively of classification results.
Main parameters are described as follows:
(2)
where TP refers to true positive rate, FP indicates false positive rate.
(3)
where FN refers to false negative rate.
The evaluation system is verified by the harmonic mean F-measure.
(4)
The classifier described is a Naïve Bayes classifier[19]. In order to reduce variability, five-fold cross validation is used.
2.4 Discussion
Firstly, feature set via algorithm 1 is constructed when parameter N is set to four. Table 1 shows the results of both traditional and our algorithms when N equals four.
Secondly, optimal parameter ε is chosen according to Algorithm 2. Parameter ε determines the number of candidate features. Finally K is set to 2, 3, and 4 to construct variable-length feature set as new signatures. α is a parameter in Bayes classification, which is the probability that the test sample is malicious when samples contain the feature. The threshold of 0.6 is chosen empirically through experimental testing.
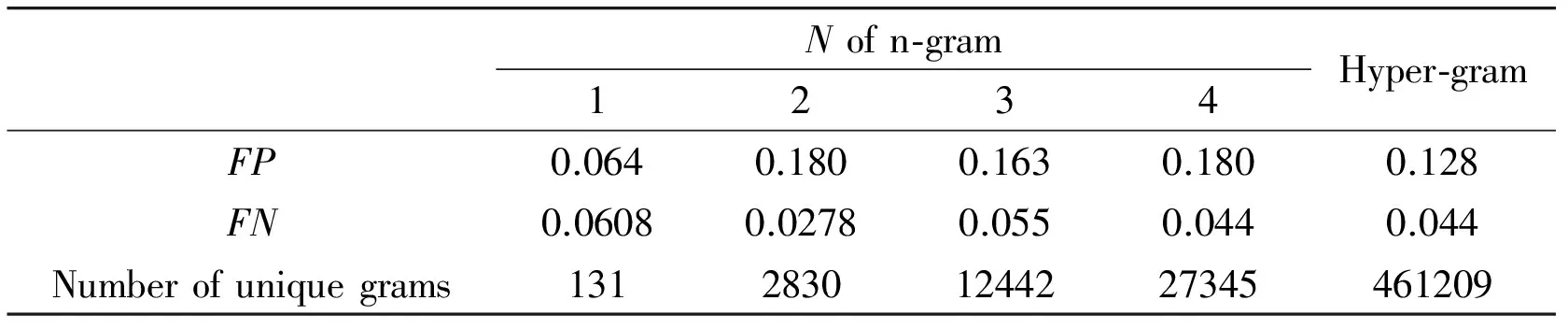
Table 1 Parameter N and the number of unique gram
In the experiments, the number of signature is zero sometimes when parameter ε is equal to 0.1 or 0.2. Fig.2 shows a mean of F-measure of different parameter ε. When value of parameter ε is more than 0.7, F-measure tends to a fixed value. Results indicate that the approach achieves best performance when value of parameter ε is 0.5.
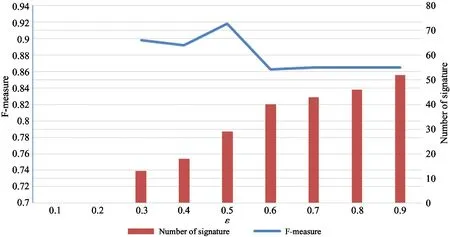
Fig.2 The F-measure value and the number of signature of different Parameter ε
The classifier mentioned above has higher detection accuracy, the comparison of the proposed approach with traditional approach (fixed-length n-gram, N equals four) in the aspect of accuracy sees Table 2. Results show that the approach achieves better performance.

Table 2 F-measure results of classification for traditional approach and the approach
3 Conclusion
A novel method is proposed to extract API call order from API call sequence as the feature by using variable-length n-gram instead of conventional fixed-length n-gram. Moreover, these algorithms are implemented in a prototype and the performance of the system is evaluated. According to the results, the approach is better than conventional approaches.
In the future work, testing this method is done over a larger set of malware and benign executables. In addition with a larger data set, evaluating this method will be carried out on different types of malware such as virus and Trojans. Furthermore, other classification such as decision tree, random tree and support vector machine will be tested. Finally, the API call sequences, which are used by a program, represent a good choice and have been widely used in behavioral analysis of malware. Compared with syntactic features, control flow is more invariant and can be a good choice. Therefore, API call sequence will be combined with the control flow in malware detection.
[ 1] Dube T, Raines R, Peterson G, et al. Malware target recognition via static heuristics. Computers & Security, 2012, 31(1): 137-147
[ 2] Jiang G F, Chen H F, Ungrureanu C, et al. Multiresolution abnormal trace detection using varied-length n-grams and automata. IEEE Transactions on System, Man, and Cybernetics, 2007, 37(1): 86-97
[ 3] Kephart J O, Arnold W C. Automatic extraction of computer virus signature. In: Proceeding of the 4th Virus Bulletin International Conference, Abingdon, England, 1994. 179-194
[ 4] Schultz M, Eskin E, Zadok E, et al. Data mining methods for detection of new malicious executables. In: Proceeding of IEEE Symposium on Security and Privacy, Los Alamitos, USA, 2001. 38-49
[ 5] Kolter J Z, Maloof M A. Learning to detect malicious executables in the wild. In: Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, USA, 2004. 470-478
[ 6] Kolter J Z, Maloof M A. Learning to detect and classify malicious executables in the wild. Journal of Machine Learning Research, 2006, 7: 2721-2744
[ 7] Cai D M, Gokhale M, Theiler J. Comparison of feature selection and classification algorithms in identifying malicious executables. Computational Statistics and Data Analysis, 2007, 51(6): 3156-3172
[ 8] Cesare S, Xiang Y, Zhou W L. Control flow-based malware variant detection. IEEE Transactions on Dependable and Secure Computing, 2014, 11(4): 307-317
[ 9] Hofmeyr S, Forrest S, Somayaji A. Intrusion detection using sequences of system calls. Journal of Computer Security, 1998, 6(3):151-180
[10] Bergeron J, Debbabi M, Desharnais J, et al. Static detection of malicious code in executable programs. In: Proceedings of the 2001 Symposium on Requirements Engineering for Information Security, Indianapolis, USA, 2001. 184-189
[11] Sekar R, Bendre M, Bollineni P, et al. A fast automaton-based approach for detecting anomalous program behaviors. In: Proceedings of the 2001 IEEE Symposium on Security and Privacy, Oakland, USA, 2001. 144-155
[12] Sung A H, Xu J, Chavez P, et al. Static analyzer of vicious executables. In: Proceedings of the 20th Annual Computer Security Applications Conference, Tuson, USA, 2004. 326-334
[13] Ye Y F, Wang D D, Li T, et al. IMDS: intelligent malware detection system. In: Proceedings of the 13th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Jose, USA, 2007. 1043-1047
[14] Sathyanarayan V S, Kohli P, Bruhadeshwar B. Signature generation and detection of malware families. In: Proceedings of the 13th Australia Conference on International Security and Privacy, Wollongong, Australia, 2008. 336-349
[15] Eskandari M, Khorshidpur Z, Hashemi S. To incorporate sequential dynamic features in malware detection engines. In: Proceedings of the 2012 European Intelligence and Security Informatics Conference, Odense, Denmark, 2012. 46-52
[16] Egele M, Sholte T, Kirda E, et al. A survey on automated dynamic malware analysis techniques and tools. ACM Computing Surveys, 2012, 44(2): 1-42
[17] Ding Y X, Yuan X B, Zhou D, et al. Feature representation and selection in malicious code detection methods based on static system calls. Journal of Computer Security, 2011, 30(6-7): 514-524
[18] VX Heavens, http://vx.netux.org: Netux, 2013
[19] Lewis D. Naïve (Bayes) at forty: The independence assumption in information retrieval. In: Proceedings of the 10th European Conference on Machine Learning, Chemnitz, Germany, 1984. 4-15
Du Donggao, born in 1978. He is a Ph.D student in Institute of Network Technology of Beijing University of Posts and Telecommunications. He received his M.S. degree in Computer Science Department of East China University of Science and Technology in 2008. He also received his B.S. degree from Henan Polytechnic University in 2001. His research interests include information security, malware detection.
10.3772/j.issn.1006-6748.2016.04.004
① Supported by the National High Technology Research and Development Programme of China (No. 2013AA014702), the Fundamental Research Funds for the Central University (No. 2014PTB-00-04) and the China Next Generation Internet Project (No. CNGI-12-02-027).
② To whom correspondence should be addressed. E-mail: dudonggao@126.com Received on Oct. 29, 2015
 High Technology Letters2016年4期
High Technology Letters2016年4期
- High Technology Letters的其它文章
- Research of refrigeration system for a new type of constant temperature hydraulic tank①
- A visual awareness pathway in cognitive model ABGP①
- Measurements and analysis at 400MHz and 2600MHz in corridor radio channel①
- Clustering approach based on hierarchical expansion for community detection of scientific collaboration network①
- Fluid simulation of internal leakage for continuous rotary electro-hydraulic servo motor①
- Fuzzy image restoration using modulation transfer function①