
数据挖掘算法分析及其并行模式研究
2016-12-21 11:21单银龙
电子技术与软件工程 2016年20期
单银龙
摘 要 所谓数据挖掘,就是指采用一些算法,通过利用算法,发现隐藏在数据中事先未知的、用户感兴趣的知识的一个过程。在本文中,首先对数据挖掘任务和挖掘方法进行了阐述,并对其数据挖掘算法并行模式进行了相关研究。
【关键词】数据挖掘算法 并行模式
1 数据挖掘的挖掘任务和挖掘方法
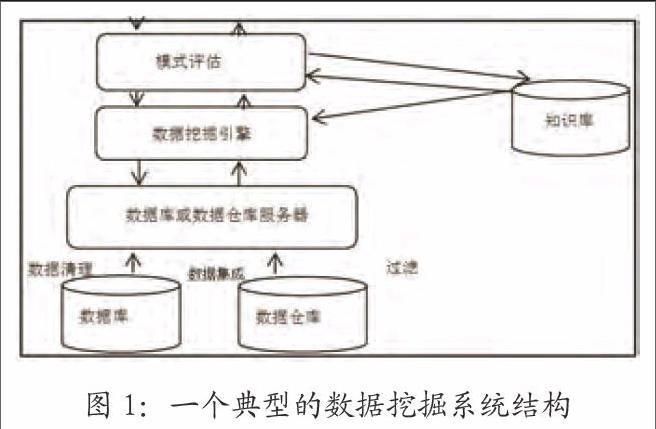
跟数据挖掘相关的学科门类较多,其涉及的分类方法多种多样。根据挖掘角度的差异性,可对数据挖掘方法归类。由挖掘任务的不同,可将数据挖掘分为这几种类型:关联规则发现、数据总结、聚类、异常和趋势发现等;由挖掘对象的不同,可将数据挖掘分为:面向对象数据库、文本数据源、异质数据库等;下文根据挖掘任务以及挖掘方法角度,重点对数据抽取、分类发现、聚类和关联规则发现四种非常重要的发现任务进行阐述。一个典型的数据挖掘系统结构一般包括数据库、数据仓库等几个部分。如图1所示。
1.1 数据抽取
数据抽取是对给定数据的紧凑描述,其运用的手段就是对数据进行浓缩处理。其中,最简单的一种数据抽取方法就是对数据库中的各字段上的统计值进行计算,这些统计值一般包括和值、均值、方差值等,另外,使用折线图等图形对数据库字段进行表示也是一种比较传统而简单的数据抽取方法。数据挖掘关注的焦点是以数据泛化的视角来讨论数据总结。所谓数据泛化,把低层次的数据抽象到高层次的一个过程。之所以把低层次的数据抽象到高层次,这是因为大家有对视图从较高层次处理或者浏览有关数据的需要,所以,通过对数据进行多层次的泛化是有其合理的解释的。
1.2 分类发现
在数据挖掘的所有任务中,分类是其中极为重要的任务之一。在所有商业应用的数据挖掘任务中,分类得到了最大范围的应用。我们知道,分类的目标是构造分类函数或分类模型。在数据库中,数据项在分类模型的作用下映射到某一个给定类别。在分类的用途中,预测是其中一个较为重要的用途。通过预测,从历史数据记录中推论得到给定数据的推广描述,最后实现对未来数据的预测目标。在对分类器进行构造的过程中,必须使用训练样本数据集作为输入。训练集一般由数据库记录或元组构成,其中,元组是由特征向量组成的。样本的一般形式为(u1,u2,...,un;c);其中 ui为字段值,c为类别。
1.3 聚类
聚类是把个体依据某种规律归类成为若干类别的过程。其最终目标是使相同类别的个体之间距离最小,而不同类别个体间距离最大化。对于聚类而言,其研究方法一般有四种:统计方法、机器学习方法、神经网络方法和面向数据库。通过对聚类分析方法的应用实践发现,其仅仅适合于数据库较小的情形,这是因为其不具备线性计算复杂度。
1.4 关联规则发现
关联规则发现的主要对象是事务型数据库,针对的应用是货篮数据。一般而言,事务的组成部分不仅包括客户订购的物品,还包括客户的标示号。随着条形码技术不断得到推广和应用,采用前端收款机也可以获得大量的售货数据。所以,通过分析历史事务数据,可从顾客那里得到一些有价值的信息。比如,更好的解决摆放货架商品和规划市场的问题。所以,如果能从事务数据中找到关联规则,这对于零售业等商业活动决策的重要性是不言而喻的。
2 关联规则挖掘的并行算法分析
2.1 并行算法的基本概念
所谓并行算法,即对可同时执行的进程集合,通过进程的协调作用,达到求解问题的目的。并行算法的设计是为了使并行机的众多处理机作用得到最大程度的发挥,这样就能更加快速有效解决问题。一般而言,并行算法对并行机存在非常强的依赖性。并行机的不同算法对其有效性会产生影响。
2.2 并行计算模型
要想对一个应用问题进行求解,那么设计良好的并行算法极为重要。如果想让并行算法作为一个由程序实现结构依赖的算法,那么抽象的并行计算机结构是非常有必要的。这样才能保障并行算法具有更广泛的适应性。并行计算模型作为一种并行计算机的抽象结构,主要考虑到的是为了并行算法的设计。所以,并行计算模型从实质意义上来讲,它是某一类并行计算机的抽象。
2.3 并行挖掘关联规则的算法
在通常情况下,找出频繁项目集的付出的资金要比从频繁项目集中找出关联规则的费用高的多。鉴于此,发现频繁项目集的并行算法就具备了重要的意义。产生候选集的算法的计算工作,通常来讲,可归类为两个步骤。其一为生成候选集,其二为对候选集的计数。为达到处理器间进行工作分配的目的,就需要使事务和候选集分配给各处理器的形式多样化。为达到更优的并发度,候选集可选择并行计算,或者是并行产生,还可以是两者并行完成。
3 小结
数据挖掘算法的并行性可对系统运行速度进行提升,从而提高工作效率,这是因为数据挖掘算法可实现对多个任务的执行。数据挖掘算法并行方式存在差异性,所以,必须根据实际情况使用恰当的挖掘方法,从而让决策的作用得到最大程度的发挥。随着数据量处理规模的逐渐增大,所以,对数据挖掘算法并行性研究的意义是不言而喻的。
参考文献
[1]赵峰,李庆华.并行序列挖掘的一种改进算法[J].华中科技大学学报(自然科学版).2003,31(10):38-40.
[2]陈国良,安虹等.并行算法实践[M].北京:高等教育出版社,2004.
[3]马传香,简钟.序列模式挖掘的并行算法研究[J].计算机工程,2005,31(06).
[4]施建强,刘晓平.基于遗传算法的数据挖掘技术的研究[J].电脑与信息技术,2003(01):9-14
作者单位
金陵科技学院 江苏省南京市 211169
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
电力与能源(2017年6期)2017-05-14
读者(2017年5期)2017-02-15
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
电子设计工程(2014年18期)2014-02-27
