
基于改进RFM模型的产品推荐算法
2016-12-20 02:22王召义
宿州学院学报 2016年11期
王召义,汪 琪
安徽商贸职业技术学院经济贸易系,安徽芜湖,241002
基于改进RFM模型的产品推荐算法
王召义,汪 琪
安徽商贸职业技术学院经济贸易系,安徽芜湖,241002
为了提高电子商务产品推荐服务的质量,在传统RFM模型的基础上,先用顾客购买持续力、总利润率代替RFM模型的R、M指标,建立RFT模型;然后对RFT指标赋以权重,计算用户-RFT矩阵;最后引入两个用户对产品RFT值之和的权值,优化了用户相似度计算方法。实验结果表明,该方法在提高推荐满意度和效率上优于传统的基于RFM的产品推荐法。
产品推荐;RFM;RFT;用户相似度
电子商务的本质是流量和转化率,而转化率越来越低、流量获取成本越来越高,导致电子商务企业纷纷涉足电子商务推荐领域,以便进一步满足消费者个性化需求,提升转化率,降低流量获取成本。与此同时,消费者为了提高购物效率,减少购物成本,也在不断寻找既能快速找到所需产品,又能满足个性需求的推荐方法。RFM模型是一种衡量用户价值与创利能力的重要工具,能较好地体现消费者的购买行为和特征。其中,R(Recency,R)表示用户在给定的时段内多久前最后一次购买某商品,F(Frequency,F)表示用户在给定的时段内总共购买某商品次数,M(Monetary,M)表示用户在给定的时段内共花费多少金额购买某商品[1]。RFM模型的这一特点恰好可以弥补传统协同过滤推荐存在的缺点——用户评价太主观、缺乏科学性。因此,本文以RFM综合值为切入点研究基于改进RFM模型的产品推荐算法。
1 改进RFM模型
RFM模型是通过对顾客交易记录进行数据挖掘,以发掘顾客价值和潜在消费能力的重要工具和手段。结合电子商务推荐服务发展现状和RFM模型的缺点,拟对R、M指标进行改进,以适应电子商务推荐服务发展。
1.1 改进R算法
计算R值的一般方法为:数据截止时间点-顾客最近消费时间点。传统计算方法虽然考虑了最近来店时间对顾客价值和潜在消费能力的影响,但却忽略了顾客的持续购买能力[2]。为了能够正确反映顾客持续购买能力,引入最近购买时间差和最远购买时间差两个指标,并根据定义1对R进行改进。
定义1 设t为数据截止时间点,t1为顾客最近购买时间点,t2为顾客最远购买时间点,则顾客最近购买时间差为(t-t1)、顾客最远购买时间差为(t-t2)。由此可规定R值的新计算方法为:
(1)
当t1=t2时,R=1,表明顾客在特定时段内持续购买能力为“零”,很有可能是一名新顾客。R值越小,说明该顾客活跃度越高。
1.2 改进M算法
企业追求的是利润,不是纯粹的高销售额,且高销售额并不一定能带来高额利润,因此在RFM模型中不应该忽略利润这一关键因素。在电子商务企业中,一般以利润率来衡量产品的营利能力。因此,引入总利润率指标,并根据定义2对M进行改进。
定义2 设某产品的成本为c,销售价格为p,某顾客购买该产品的次数为f,则总利润率T可由下面公式求得:

(2)
可知,某物品的利润率一般是不变的,随着购买次数的增加,总利润率值越来越大。
1.3 RFT模型
经过改进R和M指标,定义改进后的模型称为RFT模型。其中R、F、T三个指标的含义分别为:R(Recency,R)表示用户在给定的时段内持续购买能力,F(Frequency,F)表示用户在给定的时段内总共购买某商品多少次,T(Total profit,T)表示用户在给定的时段内的总利润率。
2 产品推荐算法
2.1 构建用户-RFT矩阵
产品推荐算法的核心是计算用户-商品评价矩阵。现通过对用户交易记录进行数据挖掘,计算用户-RFT矩阵,具体计算步骤如下。
第一步,挖掘R、F、T值。根据用户交易记录数据库,制作至少包含用户ID、最近购买时间点、最远购买时间点、商品成本、商品销售价格、销售金额等变量的销售记录统计表。F值可以使用有关数据挖掘工具直接统计得出,而R和T值可由定义1和定义2计算得出。
第二步,数据标准化。在进行数据挖掘时,需要对各类数据进行规范化处理,以保障数据量纲相同,此处采用极差正规比变换方法进行数据规范化处理[3]。因R是成本性指标,F和T是收益性指标,所以规范化公式有所区别,具体如下:
(3)
其中,R、F、T是第一步得到的初始值,Rmin、Fmin、Tmin是初始值中的最小值,Rmax、Fmax、Tmax是初始值中的最大值,R′、F′、T′是预处理以后的值。
第三步,确定R′、F′、T′权重。采用层次分析法计算权重,R′、F′、T′对应权重值分别为w1、w2、w3,且w1+w2+w3=1。
第四步,计算RFT综合值。为了方便数据处理和数据减噪,对R′、F′、T′值进行加权求和操作,得到的综合值记为RFT,计算公式为:
RFT=w1R′+w2F′+w3T′
(4)
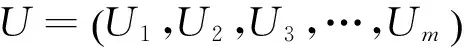
2.2 计算用户相似度
相似度的计算其实就是计算两个向量的距离,距离越近相似度越大。实验分析显示,对于基于用户的推荐系统来说,Pearson相关系数比其他方法更胜一筹。Pearson相关系数计算公式见下:
sim(Ci,Cj)
(5)
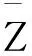
上述计算公式依赖于H,也就是说H越大相似度计算结果越准确;H比较小时,相似度存在一定的偶然性。比如两个用户都只买过一个商品,且综合值Z相同,根据公式,两个用户是完全相似的。因此,根据一个商品就判断两个用户完全相似,显然不合理。罗军和朱文奇[4]改进了Pearson相似度计算公式,如下:
sim′(Ci,Cj)
(6)


2.3 智能推荐
智能推荐是指电子商务推荐系统向目标用户推荐商品或服务,且能够满足目标用户个性化需求。
定义3 设目标用户为C,a是集合N中的元素,则目标用户C对商品j的综合指标的预测值PC,j可以通过集合N中各用户的商品项综合值得到,计算公式为[6]:
(7)
把计算出的PC,j值进行降序操作,把前top-L位的商品推荐给目标用户C。
3 实验研究
3.1 数据来源
本文所用数据来源于A电子商务企业在2015年6-10月的45257条交易记录,共分为退货、赠送、特价和正常四种销售类型,共销售35种商品。经过数据处理,其中退货记录数为1070,赠送记录数为7989,特价记录数为1736,正常记录数为34462。因为退货和赠送交易类型产生的交易额为负数或0消费额,对数据分析无用,所以在数据处理时需要删去退货和赠送类型的交易记录。因此,有效的交易记录数应为36198,用户数为8687,商品种类数为35。
为了保证实验的有效性,把数据源分为训练集和测试集,其中训练集为2015年6月至2015年8月的有效记录26875条,约占75%;测试集为2015年9月和10月的有效记录9323条,约占25%,即阀值r=0.75。
3.2 评价指标

(8)
3.3 实验结果
在上面的实验数据和评价标准的前提下,开展三项实验研究。实验1比较皮尔逊-RFT与皮尔逊加权-RFT推荐质量;实验2比较基于RFM的产品推荐算法与基于改进RFM的产品推荐算法;实验3检验RFT指标权重对产品推荐算法的影响程度。
实验1 比较皮尔逊-RFT与皮尔逊加权-RFT推荐质量。令top-L值分别为3,5,10,15,20,25,30等,观察MAE值变化情况。如图1所示。
由图1可以看出,使用皮尔逊加权-RFT的MAE一直小于皮尔逊-RFT的MAE,即w加权方法能明显提高产品推荐质量。

图1 皮尔逊-RFT与皮尔逊加权-RFT比较
实验2 不同算法比较实验。令top-L的值分别为3,5,10,15,20,25,30等,观察MAE值变化情况。如图2所示。
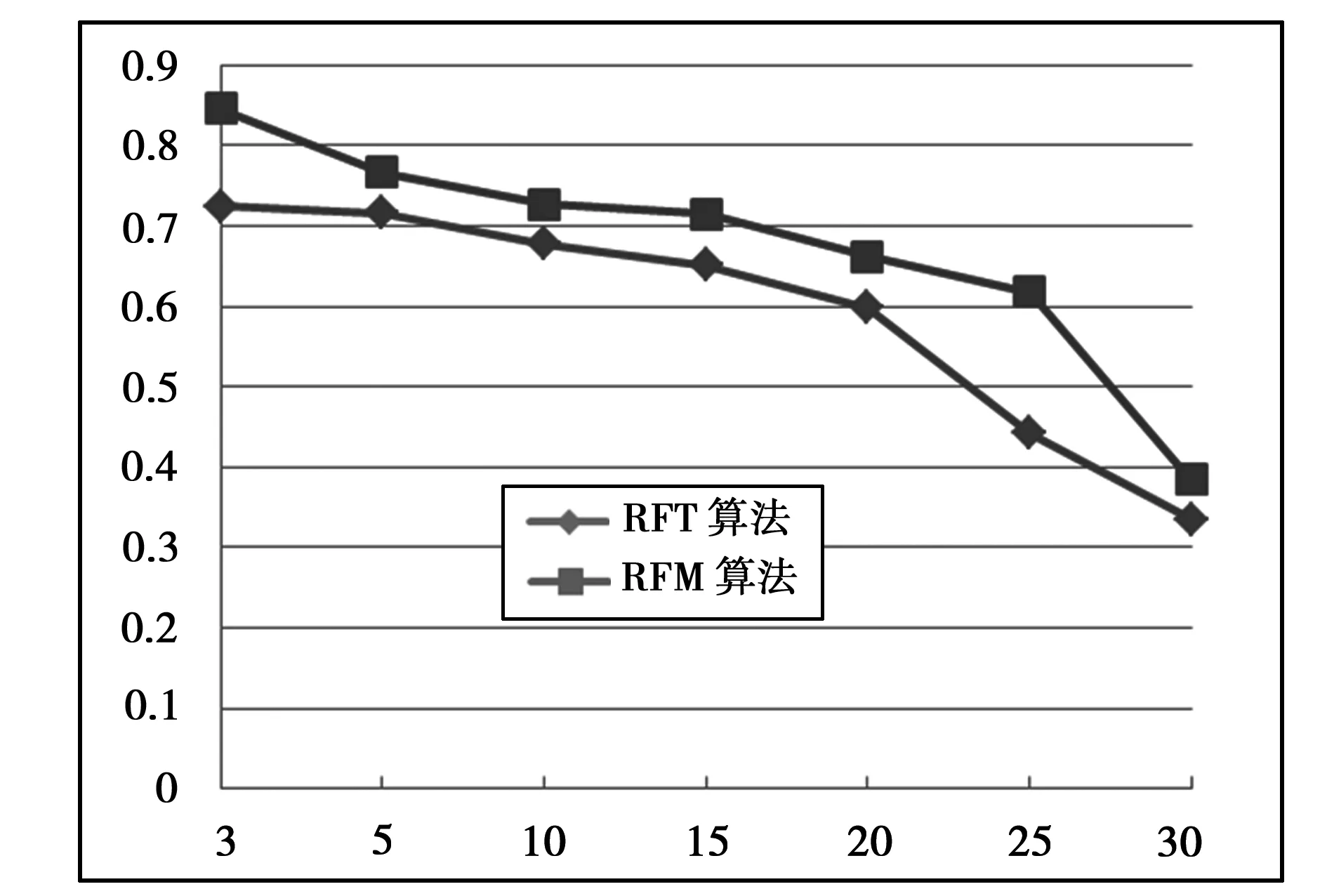
图2 两种算法的比较
由图2可以看出,top-L值逐渐变大时,基于RFT的产品推荐算法的MAE值较好,尤其在top-L大于10后,优势更加明显,证明本文算法可以提高产品推荐的满意度和效率。
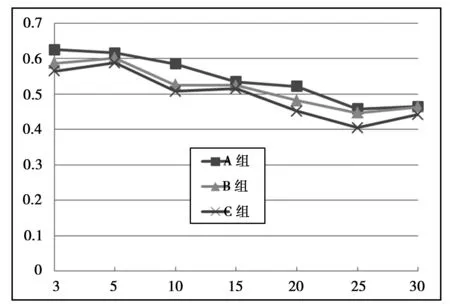
图3 不同RFT指标权重下算法对比
实验3:不同RFT指标权重下算法对比实验。采用层次分析法确定RFT指标权重值,需要组建专家组。在A企业支持下,选择总经理3人,业务经理3人,店长6人,操作人员9人,客户9人,共计30人组建专家团队。为了让实验效果更加科学准确,把专家组平均分为三组:A组、B组和C组,每组10人(总经理1人、业务经理1人、店长2人、操作人员3人、客户3人)。
经过计算,A组结果为Wf=0.255,Wp=0.509,Wr=0.236;B组结果为Wf=0.355,Wp=0.413,Wr=0.232;C组结果为Wf=0.405,Wp=0.375,Wr=0.220。图3为不同RFT指标权重下算法对比情况。
分析实验结果可知,C组MAE值最小,B组MAE值较大,A组MAE值最大,但是随着top-L的增加,A、B两组的MAE值越来越接近;从曲线轨迹来看,A、B、C三组的MAE值有趋于相同的趋势,证明RFT各指标权重的变化对推荐质量有影响,且这种影响会逐渐减弱。因此,企业在开展推荐服务时,应该采用合理的方法,确定合适的指标权重值。
4 结束语
电子商务企业在提供推荐服务时,不仅要考虑用户的消费特点,也要考虑客户价值在产品推荐中的体现。正如以上所述,用购买持续力、总利润率代替R、M指标,更符合企业目标的要求,也让推荐结果更加符合实际情况。以RFT模型来修正基于RFM的产品推荐算法,对电子商务企业开展推荐服务具有一定的借鉴作用。
[1]赵晓煜,黄小原,曹忠鹏.基于顾客交易数据的协同过滤推荐方法[J].东北大学学报:自然科学版,2009(12):1792-1795
[2]季晓芬,贾真.基于RFM行为模型的服装企业VIP顾客数据挖掘[J].浙江理工大学学报:社会科学版,2015,34(2):131-135
[3]赵晓煜,丁延玲.基于顾客交易数据的电子商务推荐方法研究[J].现代管理科学,2006(3):93-94
[4]罗军,朱文奇.考虑物品相似权重的用户相似度计算方法[J].计算工程与应用,2015,51(8):123-127
[5]朱文奇.推荐系统用户相似度计算方法研究[D].重庆:重庆大学计算机学院,2014:11-14
[6]王召义,雷丽丽.基于改进RFM模型的协同过滤推荐算法研究[J].安阳工学院学报,2015,14(2):52-56
[7]Koren Y,Sill J,OrdRec:An ordinal model for predicting personalized item rating distributions[C]//Proc. 5th ACM Conference on Recommender Systems,New York:ACM Press,2011:117-124
[8]Sarwar B,Karypis G,Konstan J,et al.Item-based collaborative filtering recommendation algorithms[C]//Proceeding of the 10th International World Wide Web Conference. New York:ACM Press,2001:285-295
(责任编辑:汪材印)
2016-08-25
安徽省高校自然科学研究重点项目“基于改进RFM模型的电子商务协同过滤推荐算法研究”(KJ2016A253);安徽商贸职业技术学院科研项目“基于支持向量回归的汽车后市场数据预测模型构建”(2016KYZ02)。
王召义(1983-),安徽宿州人,硕士,讲师,主要研究方向:数据挖掘。
10.3969/j.issn.1673-2006.2016.11.027
TP311.13
A
1673-2006(2016)11-0101-04
猜你喜欢
中国石油石化(2021年9期)2021-07-17
初中生世界(2020年43期)2020-12-18
初中生世界·九年级(2020年11期)2020-12-02
当代陕西(2020年17期)2020-10-28
教育教学论坛(2019年7期)2019-03-18
人大建设(2018年5期)2018-08-16
科学与财富(2018年16期)2018-08-10
山东青年(2016年1期)2016-02-28
应用科技(2015年5期)2015-12-09
中国洗涤用品工业(2015年6期)2015-02-28
