
复杂背景下基于定位的人体动作识别算法
2016-12-20 06:29刘长征张荣华马金利
实验室研究与探索 2016年2期
刘长征, 张荣华, 郭 理, 马金利
(石河子大学 a. 信息科学与技术学院; b. 人事处, 新疆 石河子 832003)
复杂背景下基于定位的人体动作识别算法
刘长征a, 张荣华a, 郭 理a, 马金利b
(石河子大学 a. 信息科学与技术学院; b. 人事处, 新疆 石河子 832003)

当前大多数对人体动作识别算法要求大量训练数据或MoCAP来处理多视角问题,且依赖于干净的人体轮廓。本文提出了一种复杂背景下单人体动作识别算法,通过从3D动作模型中采样,并对每个姿态样本进行定位实现人体姿态识别。首先通过对2D关键姿态进行注解,然后将其提升为线条画,再计算3D关键姿态外形间的变换矩阵。考虑到从粗犷的动作模型中采样获得的姿态可能与观察不够匹配,文章提出了一种通过生成姿态部位模型(PSPM)来实现姿态高效定位的方法,所生成的PSPM模型用树结构有效描述了合适的运动学和遮挡约束。此外,本文提出的方法不需要姿态的轮廓。最后基于两种公开数据集及一种新的带有动态背景的增强型数据集,证明本文方法相比以前算法实现了性能提升。
人体动作识别; 变换矩阵; 姿态; 定位; 遮挡约束
0 引 言
对单个相机获得的视频进行单人体动作识别[1]在监视、HCI、视频检索等多种领域中得到了广泛应用,是近年来的研究热点。当人体外观发生变化时,当前动作识别方法的效果较优,但如何在较低训练要求下对视角变化并处理带噪动态背景仍然是个难题[2]。
实现动作识别的直观方法就是首先估计人体姿态,然后根据姿态动态特征来推断出相应动作[3]。然而,这些方法的有效性取决于可靠的人体姿态跟踪算法。常见方法是避免姿态跟踪,利用支持向量机或图形模型(比如CRF[4]或LDA[5])进行动作分类器学习,进而直接将图像描述符与动作模型相匹配。然而,这些模型难以获得时域关系,并且这些方法往往需要大量多视角训练数据。
另一种方法是同时进行姿态跟踪和动作识别,我们将其称为联合跟踪和识别方法。这些方法需要学习可以描述人体3D姿态变化的动作模型,并且在推断期间使用动作先验知识来跟踪姿态,使用估计出来的姿态来识别动作。这些方法在多视角条件下性能优异,其中大多数方法为了提高模型学习的准确性需要3D MoCAP数据[6],或者假设背景为静态背景,然后利用人体轮廓进行定位和匹配[7-8]。文献[9]提出了一种不需要MoCAP的多视角方法,通过将动作模型采样获得的姿态与人体轮廓相匹配,利用2D关键姿态注释来学习3D动作模型,进而实现动作识别。然而,从这些粗犷模型中采样获得的姿态往往导致严重的匹配误差,而且这些误差会随时间累积,显著降低了识别效果,在带噪场景下更是如此。
人们已经证明,基于部位的图形模型可以实现复杂背景下2D姿态的准确定位[10],但是这些方法没有对部位间的遮 挡现象进行建模。部位间遮挡条件下的姿态定位问题要求同时对人体运动学特征和部位间遮挡现象进行建模,增加了推理难度。当前方法使用公因子模型[11]或多个树来建模这些约束,然后使用无参数消息传输或分支定界法[12]来推断出姿态。然而,这些方法要么使用人体轮廓,要求各视角下的训练数据,要么跟踪效率太低。文献[13]通过训练多个单视角模型来估计走动姿态。然而,当有多个动作时需要训练大量模型。为此,我们提出一种联合跟踪和识别算法,通过从3D动作模型中采样并对每个姿态样本进行定位实现人体姿态识别,最后通过仿真实验验证了本文方案的有效性。
1 动作识别
本文提出一种联合跟踪和识别算法,既利用先验知识进行跟踪,又根据跟踪结果进行动作识别。为每个动作在一个尺度和泛正规化3D空间获得一个合适的人体动作动态特征近似模型,实现尺度和视角不变表示。具体是将姿态缩放到固定大小的已知高度。在进行推理时,使用动作受限姿态空间的一种3D人体模型进行跟踪,进而对图像观察结果与动作模型进行匹配,找到匹配指数最高的动作。 先讨论动作表示和模型学习及讨论动作和姿态推理,再分析姿态定位。
1.1 表示与学习
本文为每个动作单独学习可以描述人体姿态动态特征的模型。该模型基于如下概念:单人体动作可表示为在多个代表性关键姿态间进行的线性变换所组成的一个序列。受文献[9]启发,将一对关键姿态间的线性变换看成一个基元。例如,走路动作可以表示为4个基元:左腿向前→右腿越过左腿→右腿向前→左腿越过右腿。在这里,每个基元是身体部位旋转所组成的集合,比如在走动时包括上腿围绕臀部的旋转和下腿围绕膝盖的旋转,因此每个基元可被表示为连接角空间的一个线性变换,见图1。其中,红色虚线曲线表示走动姿态的不同实例;分段曲线(灰色)表示被学习的动作模型;关键姿态用圆表示(黑色)。

图1 走动姿态的几何特征阐述
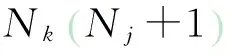
通过标注训练视频内的2D姿态和基元动作边界来学习动作模型。对每个动作模型,首先人工选择每个动作的关键姿态集合;直观来说,每当姿态动态特征发生较大变化时选择一个关键姿态;或者当3D MoCAP可用时,关键姿态可自动获取为姿态能量中的不连续点。然后,采取提升策略,根据2D标注学习每个关键姿态的3D模型。对每个基元,通过从动作边界标注中采集基元长度并对高斯变量进行拟合来获得过程中的预期变化。
1.2 有条件动作网络
已知动作模型时,可以将其嵌入动态条件随机域,得到有条件动作网络(CAN),如图2所示。

图2 有条件动作网络二维部位模型
(1)
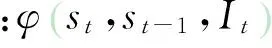
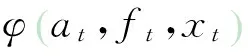
(2)
其中:P表示姿态模型的单位集合;xi表示姿态x的第i个部位。利用余弦距离来对观察到的光流与每个部位的运动方向进行匹配,进而计算运动似然概率。
权重学习:假设不同的动作/基元的跃迁权重均匀分布,因此权重学习只涉及3个权重值,每个位势一个。在本文中,使用文献[14]中效率较高、部署比较简单的投票感知算法。利用本文的推断结论以及序列的已知动作标签便可以获得所有帧的实际姿态估计。
1.3 跟踪和识别
为了对人体姿态进行准确地跟踪和识别,使用粒子滤波算法先从动作模型中采样姿态,然后对每个姿态和场景观察结果进行匹配。在跟踪时,首先利用完整人体和头部-肩部行人检测器[15]来寻找人体,然后,从动作模型中对姿态均匀采样,对姿态定位,利用检测响应提供的合适位置(颈部)和尺度(人体站立高度)来对观察结果进行拟合。当视角不变时,在多个左右转动角度下对姿态与观察现象进行匹配。

2 基于3D先验知识的准确姿态定位
本节给出相对图像观察现象如何对假设姿态(来自动作模型)进行准确定位。已知尺度和位置等先验信息后,定位过程主要是搜索姿态空间以推断出哪个姿态最能有效描述图像证据。在利用近似动作模型跟踪姿态时,关于姿态的先验信息包括粗糙的2D位置和尺度信息及可能包括真实姿态的姿态子空间。可假设在带噪环境下,2D位置和尺度先验信息的噪声较大。此外,对于快速移动的部位(比如挥手时的手部位置),动作模型推断出来的姿态子空间可能非常大。
为了提高定位的效率,首先将3D姿态搜索空间投影到二维空间上,以获得2D姿态的空间先验信息,然后使用图像观察现象对2D姿态进行定位,进而利用经过调整的2D姿态来估计三维姿态。为了进行二维姿态定位,使用基于部位的图形模型方法(与文献[10]类似),利用部位来表示人体(见图3(a)),然后在推论期间对部位施加两两约束。这些两两约束模拟了部位间的运动学和部位间遮挡关系。然而,当施加完所有这些约束后,图形模型将出现循环(见图3(b))。即使我们试图利用带有循环的模型来推断姿态,它们的计算成本仍然较大。因此,使用树结构模型更能提高推断的效率和准确性。
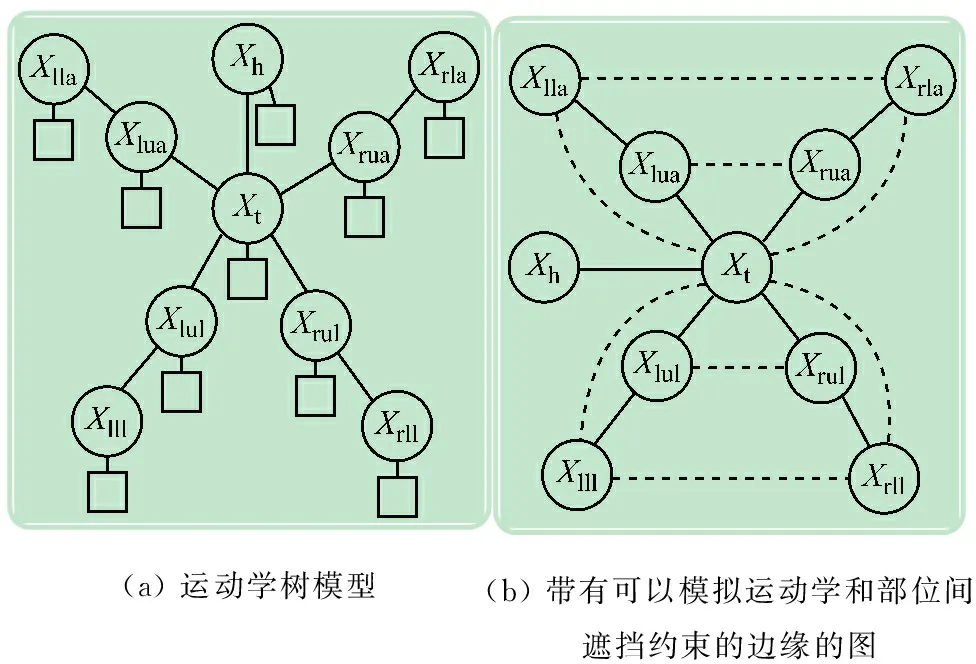
图3 二维姿态的图形模型
本文中,我们提出了一种树结构模型自动选择算法,提高了姿态已知时定位的准确性。该算法思想如下:当发生遮挡时,可以对部分动力学约束进行放松,以便对有助于定位的约束进行建模。将该模型称为姿态部位模型(PSPM)。然后,给出基于树结构部位模型的二维姿态定位方法,其次介绍PSPM选择和学习,及基于PSPM的三维姿态定位。
2.1 基于部位模型的二维姿态定位
在二维姿态模型中,每个部位被表示为一个结点,结点间的边缘表示部位间的两两约束。在推断期间,对图像单独运行所有部位的检测器,于是通过使如下联合似然概率最大化来获得最优姿态x:
(3)

2.1.1 部位检测
高性能的部位检测器可以显著提升定位结果,然而,部位检测器的计算成本太大。因此,本文利用两种效率较高的模板展开实验:
(1) 几何模板。每个部位用一个简单的几何对象来模拟,比如用椭圆模拟头部,用有向矩形模拟躯干,用一对直线段模拟手臂。通过累积边界点上的边缘长度和方向匹配度,可以获得一个部位的对数似然概率指数。
(2) 边界和区域模板。每个模板是有向条形滤波器的加权和,其中的权重通过使有条件联合似然概率最大化来实现。
2.1.2 两两约束
与文献[10]类似,使用高斯分布来定义部位间的两两运动学位势。为了避免重叠的部位占据完全相同的地方,我们专门增加排斥约束,以降低被遮挡部位与遮挡部位重叠的概率。对部位xi和xj,若xi遮挡了xj,则我们定义两两位势为:
(4)

2.2 用于定位的姿态部位模型
已知三维姿态的空间先验知识,PSPM模型是个树结构图,因此可以在调整后对具体姿态进行准确定位。获得一个姿态的PSPM模型需要首先选择模型(部位集合P,结构E),然后估计出可以实现联合似然概率最大化的模型先验知识,或先验模型)Θ。使式(3)最大化即可实现准确定位。
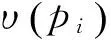
(5)
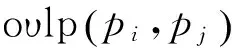
(2) 结构选择。这一步骤主要是从所有可能树中选择可以有效描述定位已知姿态相关约束的一个树。为了定位部分部位被遮挡或所有部位被遮挡的姿态,放松标准树模型图3(a)中的部分运动学约束,增加一个近似邻域和非重叠约束,使生成的模型仍然是树模型。以图4(a)中的姿态为例。标准运动学模型的替代模型将左下侧腿部与右下侧腿部连接起来,生成的姿态估计高于使用标准运动学树模型。因为人体的上部和下部很少发生耦合(即运动学上互相关联或遮挡),所以忽略手臂和腿部间的边缘。图3(b)给出了选择结构时考虑的边缘。

图4 基于PSPM模型的姿态定位
结构的标准选择方法是寻找可使似然概率在被标记数据上最大化的树结构。这需要估计互相连接的两两部位的先验参数(均值和方差),然后寻找指数最低(所有边缘的方差之和)的树结构。因为姿态不同,可使联合似然概率最大化的树结构也不同,所以标准的学习方法要求动作模型各个视角所有姿态的被标记数据,这样的数据量非常大。在本文中,提出一种基于姿态几何特征的模型指数度量指标。
为了获得合适的指标,标注200幅图像的二维和三维姿态,并对图3(b)图形中的所有树结构模型进行穷尽搜索,估计出定位指数最高的树模型。请注意,大量树模型存在可能性。为了缩小搜索空间,只考虑包括运动学边缘以及两两相连部位发生重叠的非运动学边缘的树结构。

(6)
(7)
(3) 估计先验模型Θ。我们使用一个高斯变量来定义两两位势(在第3.1.2节)。先前的方法主要针对先验知识未知时,因此需要从被标记的数据中学习高斯参数[10]。但是在本文情况中,姿态的先验知识是已知的,所以学习姿态参数更具意义。然而,学习姿态参数要求大量的姿态样本(各视角下的所有姿态)。于是,我们使用关于三维姿态的先验知识来估计这些参数。
通过将模拟为高斯分布的三维姿态先验知识投影到二维空间来估计每个关节的参数(均值和方差)。例如,部位i相对于部位j的平均相对位置μij仅仅表示部位pi末端关节中点与部位pj相应位置之差。
2.3 基于三维动作先验知识的姿态定位
动作的先验知识包括用高斯分布(每个关节一个)表示的姿态三维先验知识以及跟踪器提供的人体近似位置和尺度。有了这些先验知识后,可以使用PSPM模型获得该姿态的准确二维位置。在推理期间,我们只使用每个部位投影之后的二维位置、方向和尺度领域内的部位检测器。
在定位二维姿态后,根据二维关节位置来估计三维姿态。利用二维关节来估计三维姿态可能存在歧义;在本文中,动作模型提供的关于姿态的空间先验知识以及跟踪信息可以帮助去除这样的歧义。为了利用已知的部位深度排序和二维姿态来准确估计三维姿态,可利用非线性最小均方来拟合二维估计,同时约束关节位于姿态搜索空间,进而估计三维关节。本文假设部位的三维长度不会改变,然后从颈部开始更新每个关节的位置。通过对站立姿态的正则三维模型进行尺度缩放来获得三维部位长度的初始估计,于是模型的高度与观察到的人体高度相同(通过跟踪确定)。
3 实 验
首先利用带有姿态标注的图像数据集来评估本文基于PSPM模型的姿态定位方法。然后,利用两个公开数据集来评估本文基于PSPM模型的动作识别算法:文献[6]的完整人体姿态数据集和文献[9]的手部姿态数据集。这些数据集中的视频背景为带噪复杂背景且从多视角拍摄而得。本文还给出了动态环境下的手部姿态数据集实验结果。
3.1 姿态定位
从当前动作识别数据集中选择部分帧,用具有多种姿态的195个图像组成一个集合。对每个图像,标记二维关节位置及其相对深度来对人体三维姿态进行标注,然后提升到三维(与关键姿态标注类似)。为了定量评估姿态定位,计算了可见部位的平均定位指数:如果一个部位与真实部位重叠70%以上,则认为该部位被正确定位。
姿态先验知识包括跟踪器提供的近似二维尺度和位置信息以及近似三维姿态(表示为一组关于三维关节位置的高斯分布)。为了模拟动作模型提供的带噪先验知识,设置每个三维关节的方差为部位长度的5%。然后使用这一先验知识作为各种定位算法的输入。首先部署本文图示结构(PS)[10],该结构是个带有动力学边缘的树结构模型且使用信息不明的先验知识。当使用边界模板(BT)时,PS的定位精度可达44.53%。然后,对PS进行修改,只使用先验知识提供的搜索空间内的部位检测器,利用先验知识估计出来的参数进运动学分析。将这称为带约束图示结构(CPS)。使用边界模板CPS时定位精度可达63.74%,与PS相比,明显证明了使用姿态先验知识的重要性。然后,利用PSPM模型,定位精度高达71%,证明了对基于遮挡的约束进行建模的重要性。文献[6]中的方法使用姿态边界和canny边界间的Hausdorff距离作为形态似然概率度量来定位姿态,这种方法的精度只有62.71%。
测试了本文方法面对跟踪时可能出现的姿态位置和尺度不确定性时的稳定性。图5给出了各种定位算法在不同不确定性程度下的精度曲线,其中,图5(a)表示位置不确定性条件下不同方法的定位精度(位置误差与人体高度之比),图5(b)表示高度估计(尺度)存在不确定性时不同方法的定位精度。与Hausdorff方法相比,基于PSPM和边界模板CPS的方法的稳定性更高。当不确定性较低时,几何特征模板和边界模板CPS的精度相当,但是当不确定性上升时精度下降。在图5(b)中,边界模板PSPM方法可以容忍高度估计中出现少量误差( 10%)。

图5 不同方法的定位精度
3.2 动作识别
在姿态定位实验中,发现当预测姿态与真实姿态距离较近时Hausdorff距离定位方法的效果较好。因此为了提高效率,每5个帧运行一次PSPM模型,并对中间帧运行Hausdorff距离定位方法。此外,为了提高基于PSPM模型定位方法的效率,缩小图像尺寸,于是人体高度≈100像素。整个系统每秒运行1个帧左右,实验平台为运行Windows/C++程序的3GHz Xeon CPU。现给出3个数据集的实验结果,见表1。
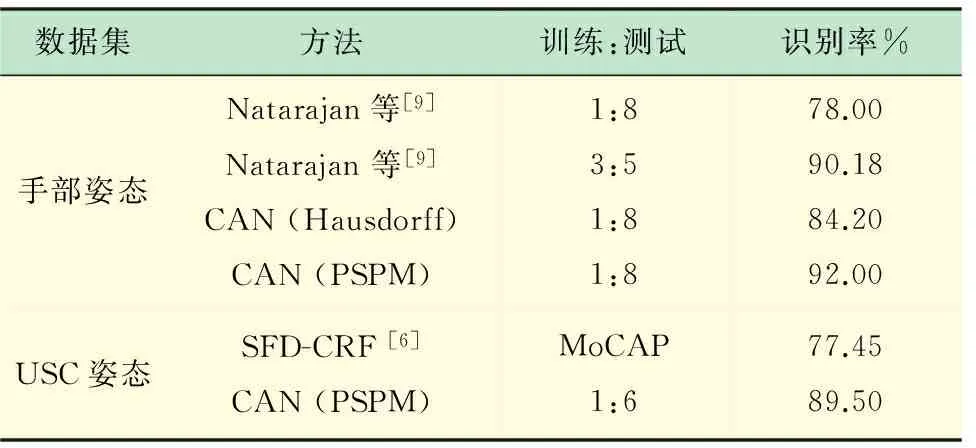
表1 手部姿态数据集的评估结果
(1) 手部姿态数据集。该数据集是室内实验室环境下8个不同人体12种动作的5或6个实例,共有各种动作共495个动作序列。虽然背景为无噪声背景,动作识别的难度仍然较大,因为大量动作的姿态差异较小。为了展开评估,利用部分人体来训练模型,用其他人体进行测试。与文献[9]中的方法进行比较,该文献中的方法使用了类似的关节跟踪和识别策略,但是基于离散型动作时间模型和基于前景的特征来实现定位和匹配。该文献中的训练和测试集之比为1∶8和3∶5时识别率分别为78%和90%。当训练和测试集之比为1∶8时,本文方法的识别率为92%。如果我们用Hausdorff距离方法来替代PSPM方法,则识别率降低到84%。这表明,即使在不带噪的干净背景下,使用PSPM也可以提升动作识别性能。
(2) 增强型手部姿态数据集。为了证明本文方法在带噪动态背景下的稳定性,从原始数据集中选择45个动作实例嵌入到带有复杂动态背景的视频中,以生成新的数据集(图6(f)~(k))给出了样本图像)。数据集有215个视频,包括3个人体在5种不同场景下的手部姿态。本文方法的识别准确率达91%。为了处理这些视频,我们使用了基于原始手部姿态数据集训练而得的参数。此外,还采集了25个视频,包括动态场景(摄像机发生抖动或对象在背景下移动)下的4个手部姿态,本文算法经过原始数据集训练后,成功识别出其中的20个动作实例(≈80%准确率)。
(3) USC姿态数据集。该数据集包括6个在多个平移和倾斜角度下拍摄的完整人体动作视频,动作类型包括:坐、站在地面、坐在椅子上、从椅子起立、从地面起立和控球姿态。利用倾斜角为0°的6个不同背景(包括带噪室内场景和室外行驶车辆前场景)下拍摄而得的部分数据集评估本文方法,数据集其余部分在其他倾斜角和相对干净平稳的背景下拍摄而得。被选择的数据集包括相对于人体的5种不同镜头平移角度条件下拍摄获得的动作(0°, 45°, 90°, 270°, 315°),共有240个动作实例,每个动作要么摄像机平移角度不同,要么人体、背景不同。我们在实验中利用来自同一人体的两个动作来训练本文模型,然后利用其他动作展开评估。对被分割的动作实例,本文方法的准确率达75.91%。图6(n-s)给出了样本结果。文献[6]的准确率为77.35%,但是它假设坐在椅子上和坐在地面上两个动作的后续动作分别为从椅子起立和从地面起立。如果我们也有这一假设,则本文方法的准确率达89.5%,比文献[6]提升12%。

图6 各姿态数据集的实验结果。(a)~(e):手部姿态数据集[9],(f)~(m):增强型手部姿态数据集,(n)~(s):USC姿态数据集[6]
姿态估计覆盖于每个图像上(红色),利用PSPM模型获得的相应部位分布显示在旁边。
4 结 语
本文提出一种带噪动态环境下的联合姿态跟踪和动作识别算法,该算法的训练要求较低,不需要三维MoCAP数据。仿真实验结果表明,本文方法面对手部姿态和带噪动态环境下的完整人体姿态USC数据集时,具有优异的动作识别性能。下一步工作的重点是分析现有的人体动作识别方法只重点关注视频的非静态部分而忽略大部分静态部分,从而影响了动作识别和定位的效果,拟提出新的分层空间-时间分段表示法来进一步提高人体动作识别的精度。
[1] 肖 玲, 李仁发, 罗 娟. 体域网中一种基于压缩感知的人体动作识别方法[J]. 电子与信息学报, 2013, 35(1): 119-125.
[2] 郭 利, 姬晓飞, 李 平, 等. 基于混合特征的人体动作识别改进算法[J]. 计算机应用研究, 2013, 30(2): 601-604.
[3] Ferrari V, Marin-Jimenez M, Zisserman A. Pose search: retrieving people using their pose[C]∥Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on IEEE, 2009: 1-8.
[4] Morency L, Quattoni A, Darrell T. Latent-dynamic discriminative models for continuous gesture recognition[C]∥Computer Vision and Pattern Recognition, 2007. CVPR'07. IEEE Conference on IEEE, 2007: 1-8.
[5] Messing R, Pal C, Kautz H. Activity recognition using the velocity histories of tracked keypoints[C]∥Computer Vision, 2009 IEEE 12th International Conference on IEEE, 2009: 104-111.
[6] Natarajan P, Nevatia R. View and scale invariant action recognition using multiview shape-flow models[C]∥Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on IEEE, 2008: 1-8.
[7] Hu Y, Cao L, Lv F,etal. Action detection in complex scenes with spatial and temporal ambiguities[C]∥Computer Vision, 2009 IEEE 12th International Conference on IEEE, 2009: 128-135.
[8] Weinland D, Boyer E, Ronfard R. Action recognition from arbitrary views using 3d exemplars[C]∥Computer Vision, 2007. ICCV 2007. IEEE 11th International Conference on IEEE, 2007: 1-7.
[9] Natarajan P, Singh V K, Nevatia R. Learning 3d action models from a few 2d videos for view invariant action recognition[C]∥Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on IEEE, 2010: 2006-2013.
[10] Felzenszwalb P F, Huttenlocher D P. Pictorial structures for object recognition [J]. International Journal of Computer Vision, 2005, 61(1): 55-79.
[11] Lan X, Huttenlocher D P. Beyond trees: Common-factor models for 2d human pose recovery[C]∥Computer Vision, 2005. ICCV 2005. Tenth IEEE International Conference on IEEE, 2005, 1: 470-477.
[12] Tian T P, Sclaroff S. Fast globally optimal 2d human detection with loopy graph models[C]∥Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on IEEE, 2010: 81-88.
[13] Andriluka M, Roth S, Schiele B. Monocular 3d pose estimation and tracking by detection[C]∥Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on IEEE, 2010: 623-630.
[14] Collins M. Discriminative training methods for hidden markov models: Theory and experiments with perceptron algorithms[C]∥Proceedings of the ACL-02 conference on Empirical methods in natural language processing-Volume 10. Association for Computational Linguistics, 2002: 1-8.
[15] Huang C, Nevatia R. High performance object detection by collaborative learning of joint ranking of granules features[C]∥Computer Vision and Pattern Recognition (CVPR), 2010 IEEE Conference on IEEE, 2010: 41-48.
Human Action Recognition Algorithm Based on Localization in Complex Backgrounds
LIUChang-zhenga,ZHANGRong-huaa,GUOLia,MAJin-lib
(a. College of Information Science and Technology; b. Human Resources Dept., Shihezi University, Shihezi 832003, China)
Most existing human action recognition approaches require a large amount training data or MoCAP to handle multiple viewpoints, and often rely on clean actor silhouettes. The paper presents an approach to recognize single actor human actions in complex backgrounds. The method tracks the actor pose by sampling from 3D action models. The action models in our approach are obtained by annotating key poses in 2D, lifting them to 3D stick figures and then computing the transformation matrices between the 3D key pose figures. In addition, poses sampled from coarse action models may not fit the observations well, to overcome this difficulty, we propose an approach for efficiently localizing a pose by generating a pose-specific part model (PSPM), which captures appropriate kinematic and occlusion constraints in a tree-structure. In addition, our approach does not require pose silhouettes. We show improvements to previous results on two publicly available datasets as well as on a novel, augmented dataset with dynamic backgrounds.
human action recognition; transformation matrices; figures; localization; occlusion constraints
2015-07-07
国家社会科学基金项目(14XXW004);兵团科技攻关与成果转化项目(2015AD018,2012BA017);兵团社会科学基金项目(13QN11);石河子大学重大科技攻关计划项目(gxjs2012-zdgg03)
刘长征(1979-),男,山东惠民人,硕士,副教授,主要从事计算机应用等方面的研究。
Tel.: 18999335349; E-mail: liucz@sina.cn
张荣华(1980-),女,山东梁山人,硕士,讲师,主要从事大数据等方面的研究。Tel.: 13325663320; E-mail: zrh_oea@sina.com
TP 391
A
1006-7167(2016)02-0107-07
猜你喜欢
红蜻蜓·低年级(2022年5期)2022-05-25
红蜻蜓·低年级(2022年5期)2022-05-11
中华养生保健(2020年2期)2020-11-16
学生天地(2020年3期)2020-08-25
成都信息工程大学学报(2019年3期)2019-09-25
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
华人时刊(2018年23期)2018-03-21
自动化学报(2017年5期)2017-05-14
探测与控制学报(2015年4期)2015-12-15
