
欧美国家图书馆书目数据关联化案例研究
2016-12-20 08:11邹美辰
图书馆理论与实践 2016年11期
邹美辰,胡 瀛
(1.中国科学院大学;2.中国科学院文献情报中心)
欧美国家图书馆书目数据关联化案例研究
邹美辰1,2,胡 瀛2
(1.中国科学院大学;2.中国科学院文献情报中心)
针对当前我国图书馆对书目关联化的研究不够深入、广泛的问题,剖析欧美国家图书馆书目数据关联化的9个典型案例,总结其特点与不足,以期提高我国图书馆对书目数据关联化的关注度,促进我国图书馆的书目数据关联化进程。采用网站调研法、案例分析法和对比分析法,详细分析欧美国家图书馆书目数据关联化的数据来源、数据规模、数据模型、发布格式和许可协议等内容。总结欧美国家图书馆书目数据关联化的成效与不足之处,并针对我国图书馆的书目数据关联化提供可行性建议。
书目数据;关联数据;数据发布;数据模型
1 引言
书目数据是图书馆领域最具价值的信息资源之一,是图书馆服务的基础和核心,也是连接用户和图书馆的桥梁。传统的书目数据一直是图书馆的内部独立资源,大部分采用面向数值的机器可读目录(Machine Readable Cataloguing,MARC)格式进行编目,即将所有的对象和属性值当作文字看待。随着网络环境的变化,用户对于书目数据的需求开始发生转变,用户希望通过书目数据获取更加丰富的信息,也希望通过搜索引擎发现和获取书目数据。2010年联机计算机图书馆中心(Online Computer Library Center,OCLC)的研究报告显示,在数字化网络环境中,信息消费者的检索起点大部分为搜索引擎,图书馆网站的占比很低。[1]因此,书目数据急需打破自身的资源壁垒,摆脱信息孤岛的束缚,融入更加广阔的网络环境中,更多的被搜索引擎索引,提升资源的利用率。
针对上述情况,图书馆界开始寻求新的技术手段和解决方案。2006年,“万维网之父”Tim Berners-Lee提出关联数据的概念,即构建数据之间的关联,形成一个能被计算机理解的数据网络,从而将现存的信息孤岛整合成一个巨大数据库。[2]这一概念的提出为书目数据的发展提供了新的契机,将书目数据发布为关联数据,实现书目数据关联化已经成为各个图书馆打破资源壁垒的共识。书目数据关联化之所以能够实现与其他资源的关联,其根本在于从面向数值到面向对象的思想转变,即将所有的对象和属性值当作实体看待,构建实体之间的关联。本文选取了欧美国家图书馆书目数据关联化的若干案例进行研究与分析,并阐述其对我国图书馆书目数据关联化的启示。
2 欧美国家图书馆书目数据关联化的现状
欧美国家图书馆一直关注书目数据关联化的相关研究。2008年,瑞典国家图书馆首次将书目数据发布为关联数据,是世界上第一个被整体发布为关联数据的联合目录,并且建立了与DBpedia和美国国会图书馆主题词表(Library of Congress Subject Headings,LCSH)之间的连接,标志着书目数据开始真正融入网络环境中。[3]2010年5月,W 3C成立了图书馆关联数据孵化小组,推动了关联数据在图书馆领域的发展,提升了数据的互操作性。[4]2010年后,书目数据关联化达到高潮,欧美各国的国家图书馆纷纷开始进行书目数据关联化实践。笔者以datahub[5]数据中心为主要调查对象,结合最新的检索结果和欧美国家图书馆网站调研结果可知,欧美共有8个国家图书馆实现了书目数据关联化(分别为瑞典、匈牙利、西班牙、英国、法国、意大利、德国和俄罗斯)。本文选取了9个典型案例进行剖析,其书目数据关联化情况统计如表1所示。OCLC和欧盟数字图书馆虽然不是国家图书馆,但属于欧美十分重要的图书情报机构,其书目数据关联化具有一定的代表性。

表1 典型案例的书目数据关联化情况统计
3 欧美国家图书馆书目数据关联化的分析
3.1 数据来源与规模
实现书目数据关联化,首先需要考虑的就是书目数据的来源,图书馆在选择数据来源时需要思考两个问题:一是要进行关联化的数据类型,二是要进行关联化的数据比例。数据类型决定了后续实体及实体属性的构建,当前的书目数据类型除了书籍、期刊等传统类型外,还包括地图、乐谱、音频和视频等新兴类型。数据比例则关系着该机构进行书目数据关联化的目的,是实施一项实验性工作,还是提供实质性的用户服务。经过调研,欧美国家图书馆的书目数据来源与规模如表2所示。
由表2看出,欧美国家图书馆在书目数据关联化过程中,其数据类型是十分多元的,大部分都同时涵盖传统和新兴类型。在数据比例上,除欧盟数字图书馆外,其他机构都选择将其内部的全部书目数据进行关联化,表明其目的大多着眼于提供实质性的用户服务,在其网站上都有相应的用户服务界面。欧盟数字图书馆只选择一部分数据进行关联化的原因在于有一些数据提供者不愿意将数据公开,因此只能进行部分关联化。[12]此外,有些国家在书目数据关联化过程中,还将自身的主题词表和规范文档也一同进行了关联数据化。例如,法国国家图书馆的主题词表RAMEAU,德国国家图书馆的人名、机构和主题规范文档GND,以及OCLC的虚拟国际规范文档VIAF等。
其次要考虑的就是数据规模,它关系着存储技术方案的选择。原先一般采用书目记录的条数作为图书馆数据规模的定量指标,但由于现在转换为RDF形式,因此大多采用Triple的条数来反映数据规模。一条Triple代表书目数据的一条描述,书目数据的数量越多,描述得越详尽,产生的Triple越多。由表2可以看出,各机构的数据规模基本都在千万级以上。
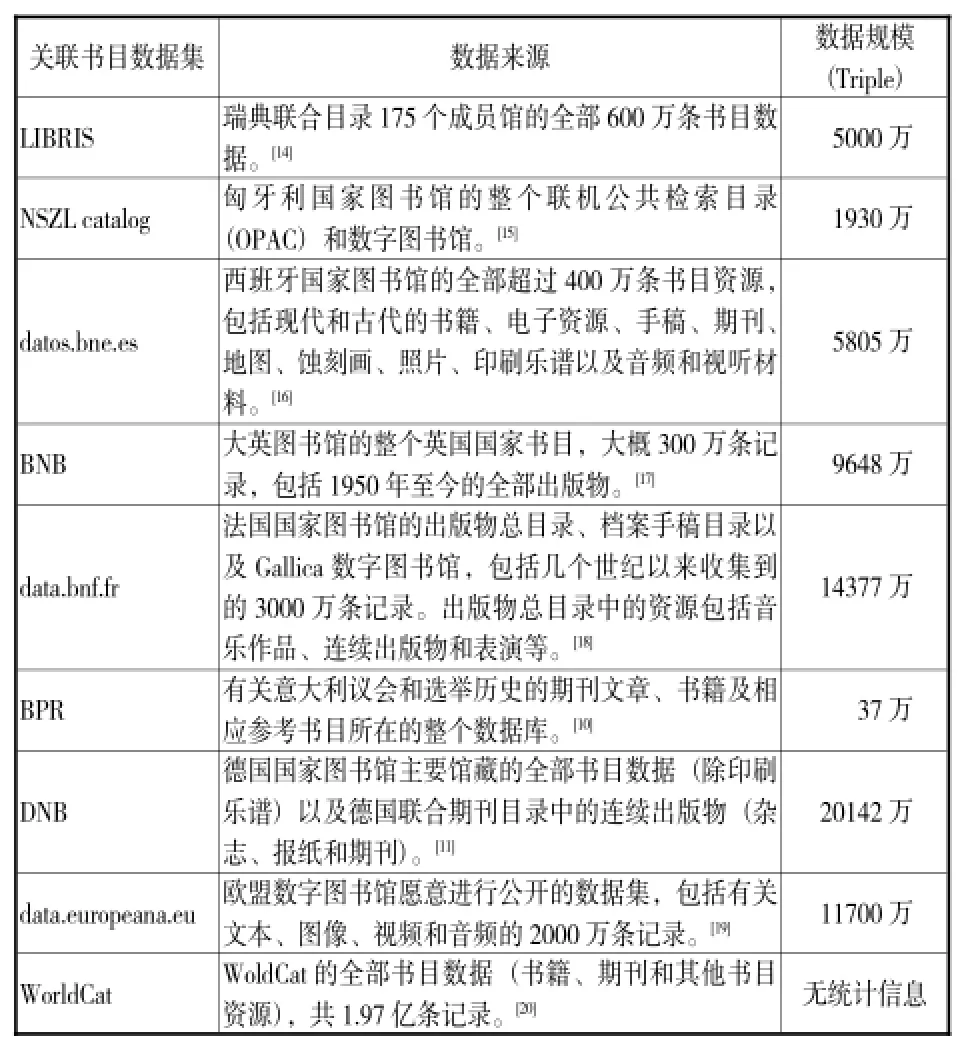
表2 欧美国家图书馆的书目数据来源与规模
3.2 关联数据模型
3.2.1 实体抽取
书目数据的原始格式大多为一维线性的MARC格式,包含标识项、题名与责任者项、主题信息项和附注项等,采用面向数值的思想,信息对象为一条记录。但随着网络环境的变化,信息对象越来越细小,从记录逐步发展为数据,需要更具结构化的组织方式。实体抽取的本质就是从面向数值到面向对象的思想转变,即根据书目数据的特点从MARC记录中抽取不同类型的实体,将对象和属性值当做实体看待。欧美国家图书馆的书目数据实体类型如表3所示。
由表3看出,欧美国家图书馆的书目数据实体抽取可以分为三大类。第一类是根据已有模型进行实体抽取。例如瑞典、匈牙利、西班牙和法国都是根据FRBR模型,而OCLC则以Schema.org为基础模型。这些国家采用已有模型的原因有两点:一是这些模型由权威机构发布,并且经过实践验证具有可行性;二是这些模型与其书目数据的特点相契合,符合自身需求。
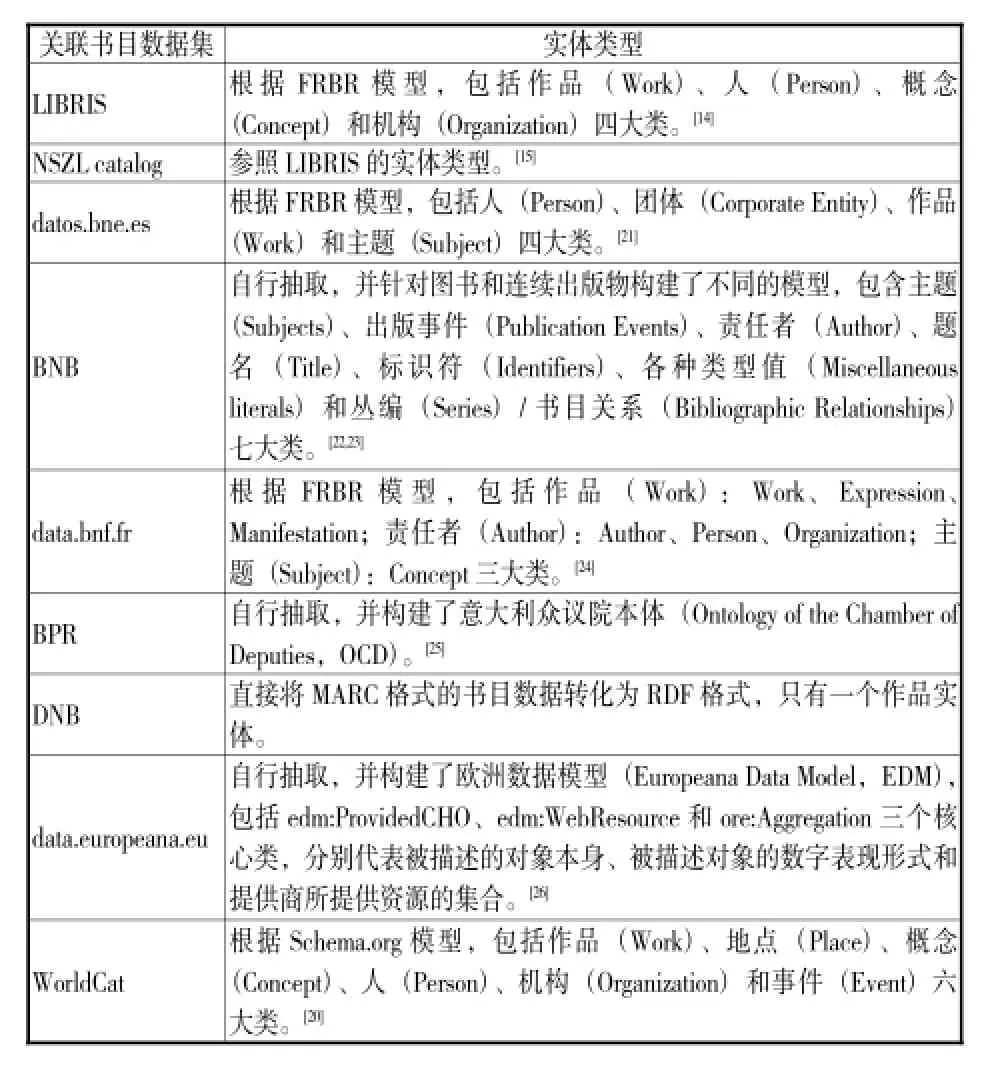
表3 欧美国家图书馆的书目数据实体类型
下面笔者将以法国国家图书馆为例进行具体分析。法国国家图书馆于2010年11月正式启动data. bnf.fr项目,其目标是提升其内部数据在网络上的影响力,并发布到关联开放数据(Linked Open Data,LOD)云图中供大家获取和使用。该项目根据FRBR模型进行实体抽取,实体类型共分为三大类,分别为作品(frbr:Work、frbr:Expression、frbr:Manifestation)、责任者(foaf:person、foaf:Organization)和主题(skos: Concept),并通过dc:contributor、foaf:focus、rdarelationships:expressionOfWork等属性实现了实体间的关联。为了扩展书目数据的内容,法国国家图书馆还建立了与外部数据集的连接,包括法国研究图书馆联合目录SUDOC、法国联合目录CCFR、OCLC的在线编目联合目录WorldCat、欧盟数字图书馆data.europeana. eu和DBpedia等。该项目于2011年7月正式开通网上服务,并获得了斯坦福图书馆研究创新奖(Stanford Prize for Innovation inResearch Libraries,SPIRL)。[18]
第二类是机构自行抽取。例如英国、意大利和欧盟都是根据书目数据特点自行抽取,并构建了相应的模型。英国没有采用FRBR模型的原因是当时的设计者认为FRBR是一个过于复杂的模型,[17]但在其网站的最新报告中明确指出要重新建立一个基于FRBR的实体模型。意大利没有采用已有模型的原因则是其数据类型比较特殊,重新设计可以更好地定义实体间的关系。而欧盟则是由于其目标是将全欧洲的图书馆馆藏聚合起来,涉及的问题比较复杂,已有模型无法满足其需求。
以大英图书馆为例进行具体分析。2011年7月,大英图书馆提出要将英国国家书目(British National Bibliography,BNB)发布为关联数据,并开放到LOD云图中。大英图书馆之所以作出这样的决定,有两点原因:首先,从2009年起英国政府就承诺开放公共数据,以达到广泛使用的目的,BNB的关联数据化正好可以作为大英图书馆对于此项承诺的回应;其次,大英图书馆希望在关联数据化的过程中受益,成为关联数据浪潮中的一部分。[17]大英图书馆针对图书和连续出版物抽取了不同的实体类型,以图书为例其实体类型可以划分为四大部分,分别为出版事件、主题、责任者和其他。出版事件包括出版事件类以及与其相关的主体类、空间类和时间类,其中出版事件类是事件类的子类,出版开始事件类和出版结束事件类是出版事件类的子类。主题包括七大类,概念类、LCSH主题类、人名概念类、家族概念类、机构概念类、DDC主题类和地点概念类,其中概念类是其他六类的父类。责任者包括人名类、机构类、出生日期类和死亡日期类。其他则包含标识符、题名、语言和附注类等。虽然大英图书馆根据实体类型构建了相应的模型,但只是将现有的MARC书目记录直接转化为RDF格式,其本质的内容描述规则没有改变。
第三类则是直接在MARC格式的基础上进行转化。例如,德国国家图书馆就是直接进行MARC21字段到词表属性的映射,没有改变其本质的内容描述规则。MARC21字段可以被划分为题名信息、责任者信息、出版信息、标识信息、丛书系列信息和语言信息等。以题名信息为例,其映射情况见表4。
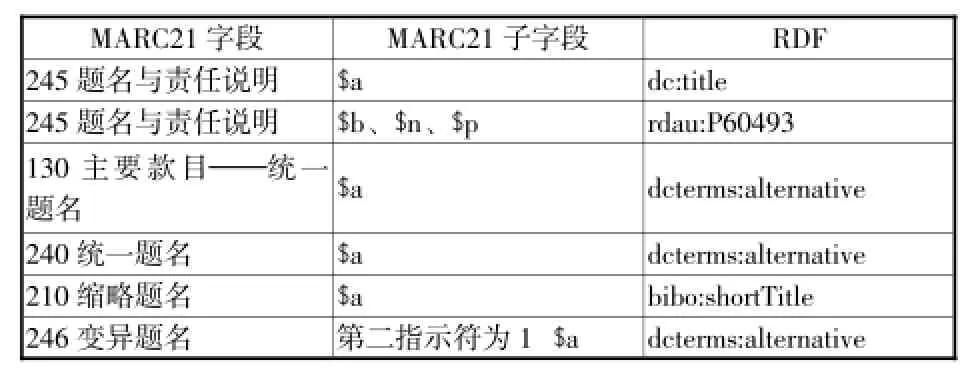
表4 德国国家图书馆题名信息映射表[27]
3.2.2 实体命名
实体命名就是为每个实体赋予一个永久标识符,即URI。URI比较通用的结构为:<基地址>/<实体类型名称>/<标识符>,欧美国家图书馆的书目数据URI格式如表5所示,基地址用粗体标出。

表5 欧美国家图书馆的书目数据URI格式
由表5可以看出,URI的基地址一般采用各机构的网站首页地址,实体类型名称则根据数据特点来命名。标识符是URI唯一性的重要保证,其命名方式主要有两种。第一种是依赖于外部资源,例如人名可以采用VIAF和ORCID进行描述,作品可以采用DOI和ISBN进行唯一标识。法国国家图书馆采用了面向数字资源长期保存的资源永久标识符系统——存档资源键(ARK)。[28]第二种是由机构自己命名,例如大英图书馆内部的BNB ID,此外有时候为了让URI可读性更好,有些机构还使用了人名、地名或者机构名作为URI的一部分。
3.2.3 实体属性描述
在确定实体类型之后,下一步就是对各种不同类型的实体进行属性描述。实体属性绝大多数来自原有的MARC格式,还有一部分是通过与其他数据集关联获得。在描述实体属性的过程中,十分重要的一点就是根据实体属性选择或设计特定的词表。书目数据的词表来源大致可以分为两类:一类是已经发布的成熟词表,另一类是自己创建的独特词表。欧美国家图书馆的书目数据词表来源如表6所示。
由表6可以看出,书目数据的词表来源大部分为已经发布的成熟词表,只有小部分属性采用了自己创建的独特词表,例如瑞典国家图书馆和大英图书馆的LIBRIS和British Library Terms。对于作品的属性描述,出现频率较高的词表有都柏林核心元数据词表DC和描述书目信息的书目本体BIBO;对于作者的属性描述,大部分都采用描述人物信息的词表FOAF;对于主题的属性描述,出现频率较高的为描述受控词表概念信息的词表SKOS。欧美国家图书馆基本上都同时采用了这四个词表,它们在书目数据关联化的过程中占有十分重要的地位。复用已有词表能够减少机构的工作量,提升数据的互操作性,保证开放关联书目数据在框架上的基本一致性,以及书目数据的统一管理、共享和利用的便利性。
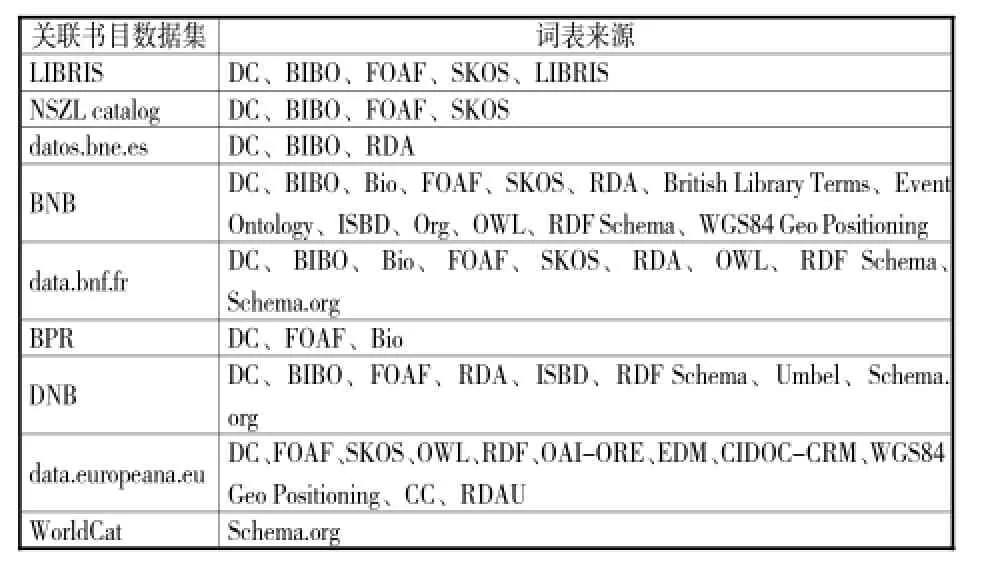
表6 欧美国家图书馆的书目数据词表来源
3.2.4 实体关联
建立实体关联就是选择合适的内外部资源,丰富书目数据的关联性。这一部分是书目数据关联化的核心价值所在,能够打破图书馆的资源壁垒,建立书目数据与图书馆资源和外界资源的连接。欧美国家图书馆的书目数据实体关联情况如表7所示。
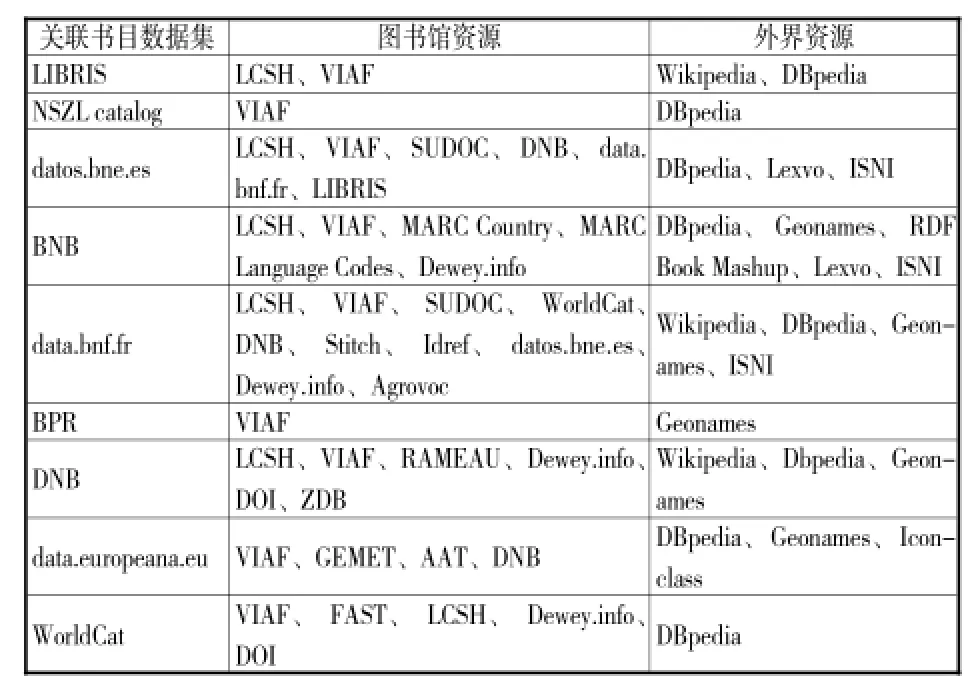
表7 欧美国家图书馆的书目数据实体关联情况
由表7可以看出,书目数据在选择图书馆资源的过程中,偏向于两类。第一类是各个图书馆发布的关联书目数据集,即书目数据之间的资源互联。例如,西班牙国家图书馆、德国国家图书馆、法国国家图书馆和瑞典国家图书馆的书目数据集都有相互之间的关联。第二类是权威机构发布的主题词表和规范文档,构建关联最多的主题词表是美国国会图书馆的LCSH,规范文档则大多集中于VIAF。VIAF由OCLC发布,集合了各个图书馆有关人名和机构的规范文档,是图书馆界资源互联的首选。外界资源的选择则偏向于公共领域,例如DBpedia和Geonames等重要开放数据集。在实体互联的过程中,实现关联较多的数据项为作品名、人名、机构名、地名和主题名。
此外,还需要考虑的一个关键问题就是关联发现算法的设计。在关联数据的权威教程中,关联发现算法可以分为三种:人工创建、基于模式的算法和基于属性的算法。[29]除此之外,人们还开发了一系列的关联发现框架。例如,基于规则的关联发现框架SILK,[30]基于三角形不等式的关联发现框架LIMES[31]和完全针对关系型数据的语义连接发现框架LinQuer等。[32]根据资料显示,英国、德国、法国、意大利、西班牙等国的国家图书馆都选择人工与自动相结合的方式实现实体的关联化。[33]
3.3 数据发布格式与许可协议
在书目数据关联化过程中,需要考虑的问题还包括数据发布格式和许可协议。关联数据可以采用不同的关联序列化方法,从而以不同的格式呈现。当前的关联数据发布格式可以分为四类:①HTML类型:HTML、RDFa、Microdata;②XML类型:RDF/XML、RDF/XML-ABBREV;③N3类型:N3、Turtle、N-Triple、N-Quads、TriG、TriX;④JSON类型:RDF/JSON、JSON-LD。HTML类型可以在网站上为用户提供数据服务,是为人们理解和使用而设计的。XML类型是W 3C的推荐标准格式,但复杂度高,可读性低。N3类型简化了XML类型的复杂度,提升了互动性和可读性。JSON类型是互联网最流行的数据交换格式,适合于现代网络,解析效率较高但难以书写和阅读。欧美国家图书馆的书目数据发布格式和许可协议如表8所示。由表8可以看出,书目数据的发布格式一般都包括多种类型,这样可以同时满足机器和用户的需求,并兼顾标准化和可读性。
在关联书目数据的发布、消费和再创造过程中,一定会涉及参与者的利益问题。因此最好明确声明其许可协议,避免不必要的法律纠纷,为书目数据的发展提供法律基础和保障。目前,欧美国家图书馆对关联书目数据进行授权和声明的许可协议可以大致分为两类:①开放数据共用(Open Data Commons,ODC)家族,其中ODC-BY是一种数据库的许可协议,需要署名数据库;②知识共享(Creative Commons,CC)家族,其中CC0是对自己所拥有作品版权和其他权利放弃的一种声明协议,即任何人可以以任何方式和任何目的使用该作品。[34]由表8可以看出,大部分书目数据集的许可协议为CC0,这一点保证了书目数据的普遍性和开放性。

表8 欧美国家图书馆的书目数据发布格式和许可协议
4 欧美国家图书馆书目数据关联化的特点与不足及对我国图书馆的启示
4.1 特点与不足
4.1.1 欧美国家图书馆书目数据关联化的特点
(1)欧美国家图书馆书目数据关联化的步骤基本相同,并且都逐步将各类资源有条不紊地纳入了关联化序列,建立了各个资源实体之间的关联。(2)欧美国家图书馆都在书目数据关联化的基础上推出了各种用户服务。例如在网站上提供关联书目数据的浏览和检索、提供以RDF文件的格式下载书目数据或通过SPARQL端点进行书目数据的检索,力图深层次挖掘关联数据的潜力与优势,提升其服务方式和服务深度。
4.1.2 欧美国家图书馆书目数据关联化的不足
(1)没有与外界资源广泛建立关联。欧美国家图书馆在丰富书目数据关联性的过程中,选择的资源类型大部分为图书馆内部资源,包括书目数据、主题词表和规范文档等。对于外界资源的选择有较大的局限性,主要为公共领域的重要开放数据集DBpedia和Geonames。(2)有些机构在实体建模的过程中,没有从本质上改变书目数据的内容描述规则。它们只是将现有的MARC记录直接转化为RDF格式,其本质仍然是面向数值的思想,不符合时代发展的潮流,很容易被逐步淘汰以致消失。
4.2 对我国图书馆的启示
(1)提高对书目数据关联化的关注度。目前,我国图书馆对书目数据关联化的关注度较低,这个问题应该引起重视。近年来,书目数据关联化发展迅速,得到了欧美各国国家图书馆的广泛支持,其资源内容、服务方式和服务深度较之前都有了很大提升。建议我国图书馆也积极投身于书目数据关联化的浪潮当中,关注书目数据关联化的发展。
(2)尽量在已有模型的基础上进行实体建模。首先,拥有明确的实体模型是十分必要的,可以提升书目数据关联化的灵活性和扩展性,便于复杂关系的表达和知识发现的进行。其次,在已有模型的基础上进行扩展能够转变书目数据的传统内容描述规则,符合时代发展的潮流。最后,已有模型是由权威机构发布的,经受过实践的考验,比较全面和完善。
(3)优先复用已有的成熟词表。书目数据关联化的词表来源包括已有的成熟词表和自己创建的独特词表,建议我国图书馆优先复用已有的成熟词表,这样能够减少机构的工作量,提升数据的互操作性,保证开放关联书目数据在框架上的基本一致性,以及书目数据的统一管理、共享和利用的便利性。
(4)广泛建立与外界资源关联。当前图书馆在进行书目数据关联化过程中,对于外界资源的选择有较大的局限性,资源领域比较单一。今后,我国图书馆可以扩大选择范围,将书目数据不断渗透到其他领域,丰富书目数据的关联性。
(5)提供多种类型的数据格式和明确的许可协议。多种类型的数据格式可以同时兼顾标准化和可读性,而明确的许可协议则可以避免不必要的法律纠纷。我国国家图书馆如果想要提供开放数据服务,最好同时提供HTML类型和JSON类型,因为现在的网络服务已经越来越多地使用JSON格式进行数据交换。
[1]PerceptionsofLibraries.2010:ContextandCommunity[EB/OL].[2016-01-12].http://www.oclc.org/ content/dam/oclc/reports/2010perceptions/2010perceptions_all_singlepage.pdf.
[2]Tim Berners-Lee.Linked data-design issues[EB/OL].[2016-01-12].http://www.w3.org/DesignIssues/ LinkedData.html.
[3]LIBRIS[EB/OL].[2016-01-12].https://datahub. io/dataset/libris.
[4]W3C Library Linked Data Incubator Group[EB/OL].[2016-01-12].https://www.w3.org/2005/Incubator/ lld/.
[5]Datahub[EB/OL].[2016-01-12].https://datahub. io/dataset.
[6]HungarianNationalLibrary(NSZL)catalog[EB/OL].[2016-01-12].https://datahub.io/dataset/hungarian -national-library-catalog.
[7]Datos.bne.es[EB/OL].[2016-01-12].https:// datahub.io/dataset/datos-bne-es.
[8]British National Bibliography(BNB)-Linked Open Data[EB/OL].[2016-01-12].https://datahub. io/dataset/bluk-bnb.
[9]Data.bnf.fr-Bibliot h侉q uenationaledeFrance[EB/OL].[2015-01-12].https://datahub.io/dataset/data-bnf-fr.
[10]BPRBibliographyof the Italian Parliamentand electoral studies[EB/OL].[2016-01-12].https://datahub. io/dataset/bpr.
[11]Deutsche Nationalbibliografie(DNB)[EB/OL].[2016-01-12].https://datahub.io/dataset/deutschenationalbibliografie-dnb.
[12]Europeana Linked Open Data[EB/OL].[2016-01-12].https://datahub.io/dataset/europeana-lod.
[13]OnlineComputer LibraryCenter:WorldCat[EB/OL].[2016-01-12].https://datahub.io/dataset/oclc.
[14]Malmsten M.Making a library catalogue part of the semanticweb[C]//Proceedingsof the2008 International Conferenceon Dublin Coreand Metadata Applications. Dublin CoreMetadata Initiative,2008:146-152.
[15]National Sz佴ch佴nyi Library(national library of Hungary)on the semanticweb[EB/OL].[2016-01-12].http://nektar.oszk.hu/wiki/Semantic_web.
[16]Datasources[EB/OL].[2016-01-12].http://www. bne.es/en/Inicio/Perfiles/Bibliotecarios/DatosEnlazados/ FuentesDatos/.
[17]DeliotC.Publishing the British National Bibliography as linked open data[J].Catalogue&Index,2014(174):13-18.
[18]Aboutdata.bnf.fr[EB/OL].[2016-01-12].http: //data.bnf.fr/en/about#Ancre1.
[19]EuropeanaLinkedOpenData[EB/OL].[2016-01-12].http://labs.europeana.eu/api/linked-open-dataintroduction.
[20]Linked dataatOCLC[EB/OL].[2016-01-12]. http://www.oclc.org/en-asiapacific/data.htm l.
[21]Datamodel[EB/OL].[2016-01-12].http://www. bne.es/en/Inicio/Perfiles/Bibliotecarios/DatosEnlazados/ Modelos/.
[22]British LibraryDataModelBook[EB/OL].[2016-01-12].http://www.bl.uk/bibliographic/pdfs/bldatamodelbook.pdf.
[23]British LibraryDataModel-Serial[EB/OL].[2016-01-12].http://www.bl.uk/bibliographic/pdfs/bldatamodelserial.pdf.
[24]SemanticWeb and datamodel[EB/OL].[2016-01-12].http://data.bnf.fr/en/semanticweb.
[25]Graph OCDOntology[EB/OL].[2016-01-12]. http://data.camera.it/data/en/datasets/grafo_ontologia. htm l.
[26]Europeana Data Model Primer[EB/OL].[2016-01-12].http://pro.europeana.eu/files/Europeana_Professional/Share_your_data/Technical_requirements/EDM _Documentation/EDM_Primer_130714.pdf.
[27]MARC 21-RDF-Mapping[EB/OL].[2016-01-12].https://wiki.dnb.de/display/DINIAGKIM/MARC +21-RDF-Mapping.
[28]曲云鹏.存档资源键研究[J].数字图书馆论坛,2014(12):29-34.
[29]Heath T,et al.How to publish linked dataon the web[C]//Tutorial in the 7th International Semantic Web Conference,Karlsruhe,Germany,2008.
[30]Volz J,etal.Silk-A Link Discovery Framework for theWeb of Data[J].LDOW,2009(4),538-542.
[31]Ngomo ACN,Auer S.Limes:A time-efficientapproach for large-scale link discovery on theweb ofdata[J].Integration,2011(15):3-7.
[32]Hassanzadeh O,etal.A framework for semantic link discoveryover relationaldata[C]//Proceedingsof the 18th ACM conference on Information and knowledge management,ACM,2009:1027-1036.
[33]姜恩波.欧美国家级图书情报机构资源关联数据化比较研究[J].图书馆建设,2015,253(7): 19-23.
[34]张春景,等.关联数据的开放应用协议[J].中国图书馆学报,2012(1):43-48.
Research on Bibliographic Data Association ofNational Librariesin Europeand America
Zou Mei-chen,Hu Ying
In view ofsolvingexistingproblemsofdomestic research on bibliographic dataassociation in domestic librariessuch as not in-depth and broad,thisarticle analyzes9 typical casesofnational libraries in Europe and America to improve the attention degree and promote theprocessofbibliographic dataassociation in domestic libraries.Applying themethodsofwebsite research, case analysisand comparative analysis,this articlemakesa detailed analysis on some issuesof bibliographic data association of national libraries in Europe and America.Meanwhile,itsummarizes theirachievementsand deficiencies toprovide feasible suggestions for domestic libraries.
Bibliographic Data;Linked Data;DataDissemination;DataModel
G254.3
A
1005-8214(2016)11-0061-06
邹美辰(1992-),女,中国科学院大学、中国科学院文献情报中心硕士研究生,研究方向:信息资源组织与建设;胡瀛(1964-),女,中国科学院文献情报中心馆员,研究方向:书目数据库建设。
2016-03-10[责任编辑]王岗
猜你喜欢
华人时刊(2022年11期)2022-09-15
大学图书馆学报(2022年3期)2022-06-24
图书馆论坛(2022年3期)2022-02-08
英语世界(2021年13期)2021-01-12
天一阁文丛(2020年0期)2020-11-05
西夏学(2018年2期)2018-05-15
国际贸易(2018年2期)2018-04-04
海外星云(2016年17期)2016-12-01
出版人(2016年8期)2016-08-19
华人时刊(2016年17期)2016-04-05
