
一种新的自适应的视频关键帧提取方法
2016-12-17 08:04汪荣贵
合肥工业大学学报(自然科学版) 2016年11期
王 宇, 汪荣贵, 杨 娟
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
一种新的自适应的视频关键帧提取方法
王 宇, 汪荣贵, 杨 娟
(合肥工业大学 计算机与信息学院,安徽 合肥 230009)
针对目前关键帧提取存在的关键帧数目难以确定、对内容渐变的视频的处理效果欠佳和算法复杂等问题,文章提出一种自适应的视频关键帧提取方法,利用梯度方向直方图(histogram of oriented gradients,HOG)特征计算当前帧的代表性指标,初步选出候选关键帧,使用结合目标分割和颜色直方图的高级特征进行冗余度检查,最终确定关键帧集合。通过对大量包含各种场景的视频进行实验,结果表明使用该文算法提取的关键帧能更全面地表达视频的主要内容,尤其是处理内容渐变的视频时,效果更佳,并且能够根据视频的内容自适应地确定关键帧数目。
关键帧;颜色直方图;梯度方向直方图;目标分割;自适应
由于多媒体技术的进步,所生成的视频数据的量正在迅速增加,并且面向消费者的多媒体存储设备变得日趋普及。大量的视频数据需要高效的视频内容管理方案来赋予消费者一个更好的多媒体体验,一个可能的视频数据管理方案是生成视频摘要,以提供给用户浏览。除了浏览,视频摘要还可以帮助用户快速定位到一个视频语义相关的位置。
视频浓缩和关键帧提取是视频摘要的2个基本方法。视频浓缩是产生一个持续时间比实际视频短得多的短视频,关键帧提取技术是通过提取最具代表性的帧生成视频摘要。一般地,视频浓缩比关键帧更具表现力,然而,关键帧可以不受时间和同步等问题的困扰并能以各种方式进行浏览和导航使用。此外,对于小型设备,关键帧比视频浓缩可以提供更好的浏览功能,这是因为它们使用户能够快速浏览视频中的突出内容。
视频使人们的生活更加丰富多彩,同时视频本身却充斥着大量的冗余信息,只有一小部分的关键帧承载着有用的信息。然而,在所有的多媒体流中,视频是最复杂的一种数据。视频是无结构化的,并且内容复杂多样(通常伴随着相机运动、光照变化、场景混乱),质量参差不齐,时长从数秒到数小时不等,而少数的关键帧就可以帮助用户了解视频的内容,所以关键帧提取算法被广泛研究。近些年,学者们提出了很多巧妙的关键帧提取方法。
(1) 基于镜头分割的方法。这是一种最快速直观的提取方法,利用镜头边界检测方法,将一个视频流分割成很多镜头,文献[1]提取一个镜头中的首帧、中间帧和尾帧作为视频的关键帧。虽然方法简单,但是该方法并没有充分考虑到视频的内容,因此当视频内容比较复杂的情况下往往不能真实地反映视频的内容。
(2) 基于运动分析的方法。文献[2]通过分析光流来计算镜头的运动,并选择运动中拥有局部最小值的帧作为关键帧。这种方法可以选择出适当数量的关键帧,但算法计算量太大,并且它取决于局部信息,因此没有较强的鲁棒性。
(3) 基于核聚类[3-4]的方法。算法思想是首先初始化聚类中心,通过计算当前帧和聚类中心的距离,判断当前帧被加入这种类别或者作为一个新类别,所有帧处理结束后,距离聚类中心最近的帧被选为关键帧。文献[3]提出了一种层次聚类算法,先把每帧都看做是一个类别,并且类别间的距离等于帧间距,然后距离最近的2个类别聚合成一个新的类别,并计算新的类别和其他聚类的距离,如此反复直到所有的帧都属于一个类别或者达到一定的阈值时结束。这种方法计算量大,并且结束阈值难以确定。
(4) 基于内容分析的方法。主要思想是通过帧间颜色、纹理或其他视觉信息的突变来提取关键帧,首先镜头的第1帧作为关键帧,文献[5]计算当前帧和上一个关键帧的颜色直方图的差值。文献[6]通过计算当前帧和前N帧的颜色直方图的平均值的差值,如果差值比初始设定的阈值大,就把当前帧选为关键帧。这些方法都是计算帧间差值,并和一个阈值作比较,提取在视觉内容上突变的帧作为关键帧,这种方法的缺点是仅依赖于像素间的灰度差值并且阈值难以确定,从而会导致提取的关键帧不太可靠。
上述方法中,提取关键帧时主要是利用视频的低级别特征,而未利用视频的语义信息和人类感知视频的特点。文献[7]将关键帧选取转化为一个最优化问题,并给出一个关于帧的代表性和冗余性的计算公式,选取使公式获得最大值的帧集合作为关键帧。文献[8]研究了基于目标分割的方法,以提取包含能够引起人眼注意的目标或事件的帧作为关键帧,但是该研究忽略了如下情况:不是所有视频内容的前景和背景都是可以分得很清楚;前景和背景都是相对而言的,尤其是对于内容渐变的视频。因此,本文提出将最优化方法和高级特征互补融合的关键帧提取方法。首先,利用最优化方法对帧内容变化的敏感性选择出候选关键帧;其次,候选关键帧可能与已有的关键帧集合存在冗余;最后,结合高级特征与已存在的关键帧进行比较来解决冗余关键帧的问题。
1 预备知识
1.1 梯度方向直方图
梯度方向直方图(histogram of oriented gradients,HOG)是2005年CVPR会议上,法国国家计算机科学及自动控制研究所的Dalal等人提出的一种解决人体目标检测的图像描述子,该方法使用HOG特征来表达人体,提取人体的外形信息和运动信息,形成丰富的特征集。HOG主要用于目标检测领域,特别是行人检测和智能交通系统,也可用于手势识别、人脸识别等方面。
HOG描述子最重要的思想是:在一副图像中,局部目标的表象和形状(appearance and shape)能够被梯度或边缘的方向密度分布很好地描述。具体的实现方法是:首先将图像分成小的连通区域,叫做细胞单元,然后采集细胞单元中各像素点的梯度的或边缘的方向直方图,最后把这些直方图组合起来就可以构成特征描述子。为了提高性能,还可以把这些局部直方图在图像的更大的范围内(叫做区间或block)进行对比度归一化(contrast-normalized),所采用的方法是先计算各直方图在这个区间(block)中的密度,然后根据这个密度对区间中的各个细胞单元做归一化,通过这个归一化后,能对光照变化和阴影获得更好的效果。
HOG的优势在于其表示的是边缘(梯度)的结构特征,因此可以描述局部的形状信息,并且位置和方向空间的量化一定程度上可以抑制平移和旋转带来的影响;另外,采取在局部区域归一化直方图,可以部分抵消光照变化带来的影响。由于一定程度忽略了光照颜色对图像造成的影响,使得图像所需要的表征数据的维度降低了;而且由于这种分块分单元的处理方法,也使得图像局部像素点之间的关系可以很好地得到表征。
1.2 模糊粗糙区域分割
模糊粗糙区域分割技术的思想首先应用分水岭算法,其次是一个区域增长的过程,主要是根据直方图的相似性去合并子分水岭区域,目的是为了克服分水岭算法中的过度分割现象。
分水岭分割方法是一种基于拓扑理论的数学形态学的分割方法,其基本思想是把图像看作是测地学上的拓扑地貌,图像中每一点像素的灰度值表示该点的海拔高度,每一个局部极小值及其影响区域称为集水盆,而集水盆的边界则形成分水岭。分水岭的概念和形成可以通过模拟浸入过程来说明,在每一个局部极小值表面,刺穿一个小孔,然后把整个模型慢慢浸入水中,随着浸入的加深,每一个局部极小值的影响域慢慢向外扩展,在2个集水盆汇合处构筑大坝,即形成分水岭。
直接应用分水岭分割算法的效果往往并不好,如果在图像中对前景对象和背景对象进行标注区别,再应用分水岭算法会取得较好的分割效果。分水岭算法对微弱边缘具有良好的响应,图像中的噪声、物体表面细微的灰度变化,都会产生过度分割的现象。分水岭算法所得到的封闭的集水盆,为分析图像的区域特征提供了可能。另外为消除分水岭算法产生的过度分割,可以采用根据直方图的相似性合并相邻的子分水岭区域。
2 本文算法
关键帧提取通常面临以下几个主要问题:① 传统的关键帧提取方法坚持宁多勿缺的原则,为了不遗漏关键帧,却引入了大量冗余帧;② 一些算法计算量巨大,如基于核聚类的算法和Wolf的光流分析方法等无法满足实时性的要求;③ 面对视频中复杂的场景,很难找到合适的阈值,从而限定了方法的适用范围;④ 一些算法在计算帧间差时忽略了像素的空间位置关系,比如摄像师经常把重要目标聚焦在画面中央。
因此,在经典算法的基础上,本文提出一种新的关键帧提取方法,并能够自适应地确定关键帧的数目。首先,利用HOG特征计算当前帧的代表性指标,若其代表性越过障碍项,说明当前帧可能非常具有代表性,但也有可能已经存在于关键帧集合,因此将其初步选为候选关键帧;其次,使用结合目标分割和颜色直方图的高级特征进行冗余度检查,最终确定当前帧是否加入关键帧集合。使用本文算法所提取的关键帧能更全面地表达视频的主要内容,尤其是处理内容渐变的视频时,效果更佳,并且能够根据视频的内容自适应地确定关键帧数目。本文算法流程如图1所示。
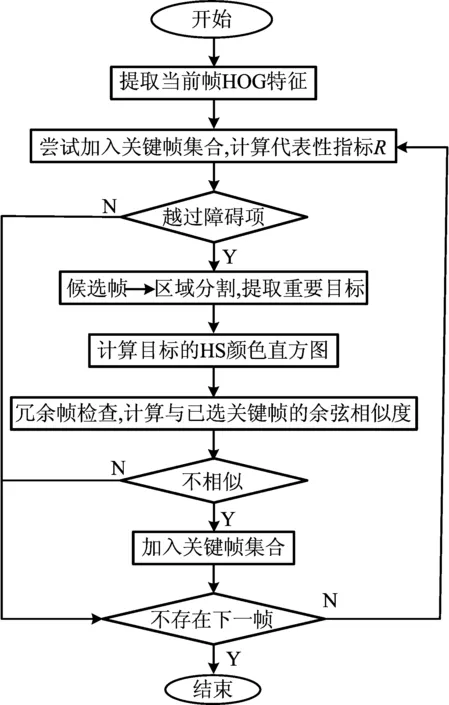
图1 本文算法流程
2.1 候选关键帧
衡量关键帧提取方法好坏的一个指标是所选择的关键帧集合能否最大程度地反映出原始视频的主要内容,即关键帧集合最大程度地包含了视频中的主要事件。
鉴于HOG[9]表示的是边缘特征,并且能够抑制平移和旋转带来的影响,另外可以部分抵消光照变化带来的影响,这些优点使得图像像素点之间的关系可以很好地得到表征。因此本文首先基于HOG特征量化关键帧集合对原始视频的代表性,初步筛选出具有代表性的候选关键帧。假设V={v1, v2,…,vn}代表着一个视频中所有帧的集合,S表示关键帧集合,为了计算帧的代表性,通过计算2帧特征向量的夹角余弦值来评估其相似度,余弦值越接近于1,它们的方向更加吻合,则越相似。设向量A=(A1,A2,…,An),B=(B1,B2,…,Bn),则有:
(1)
计算S对V的代表性R(S):
(2)
其中,θij为帧vi和帧vj的余弦相似度;R(S)为S中每一帧和V中每帧相似度的最大值的和。
用vt表示当前帧,首先假设vt是关键帧,则加入vt的关键帧集合S*(S*=S∪vt)对V的代表性一定会显著提高。即(3)式大于0,说明当前帧的加入提高了关键帧集合的代表性,可以作为候选关键帧。
(3)
因为没有明确需要提取的关键帧的个数,而且(2)式是递增的,会引起(3)式恒大于0,所以将导致所有的帧都被选为关键帧,很明显不满足对冗余度的要求。为了解决这个问题,本文给(2)式加上一个障碍项,即要想证明自己具有代表性(代表新的事件或目标),必须越过障碍,即
(4)
(5)
其中,|V|为视频帧总数;|S|为已选关键帧个数。
因为障碍项恒大于0,所以不会改变(2)式的单调性,但是只有代表性增加到一定的程度,(3)式才能大于0,即越过障碍项才能证明当前帧与众不同(具有代表性)。这避免了所有帧都会被选为关键帧的情况,保证了只有帧的内容囊括了视频中某些重要事件或目标时才有资格被选为关键帧。参数ρ对最终选取关键帧的数目影响重大,如果值偏小,则计算结果很容易跨过障碍项,会选出很多的冗余帧;反之,如果值偏大,则会出现对重要场景遗漏的情况;根据视频内容的不同,不可能为关键帧数目设置一个统一的阈值,本文中ρ动态取决于已选取的关键帧的代表性,这为自适应确定关键帧数目奠定了基础;并且ρ的动态取值也决定了障碍项的大小是根据具体场景自适应调整的,面对内容渐变的视频时,视频内容波动得不那么剧烈,障碍项也相对较小,更不容易遗漏关键帧;最后φ=2是在对大量包含不同场景、光照等场景的视频实验得出的经验值。
2.2 冗余度检查
关键帧提取技术的另一指标是关键帧的冗余度,冗余帧的出现不仅没有增加关键帧集合的代表性,反而会浪费大量存储空间,在遵循“宁多勿缺”的原则时,再加上传统方法对冗余帧检查时使用的都是low-level特征,很容易造成误检,必然会出现很多冗余帧,因此单独使用low-level特征非常不可靠。本文使用联合目标分割和颜色直方图特征的high-level特征检测帧的冗余,为图像提供一个高层次级别的特征描述。首先,使用模糊区域分割技术将图片中重要目标分割出来;其次,针对目标提取其颜色直方图特征,并和关键帧集合作比较来检测当前目标是否存在。
目标分割使用一种叫做模糊粗糙区域分割的技术[10]。首先应用分水岭算法,初步提取场景中的目标;其次是一个根据直方图相似性合并子分水岭区域的区域增长过程。在很多领域,这种分割技术都得到了广泛的应用,但分水岭分割却有一个致命的弱点,那就是容易产生过分割,对于噪声和细密纹理非常敏感,使其常常产生严重的过分割结果,另外针对分水岭算法运算量大,速度慢的问题,本文采取降分辨率的方法降低计算量。
针对过度分割的问题,直接应用分水岭分割算法的效果往往并不好,如果在图像中对前景对象和背景对象进行标注区别,再应用分水岭算法会取得较好的分割效果。有多种方法可以用来获得前景标记,如形态学技术“基于开的重建”和“基于闭的重建”,这些标记必须是前景对象内部的连接斑点像素,这样做的目的是减少小的积水盆,从而减少过分分割区域的数量。分割后处理即在应用分水岭分割之后对结果图像进行合并处理。初始分割会产生过多小区域,不同的合并准则会得到不同的分割结果,本文基于相邻区域的颜色直方图匹配的合并准则,得到的是目标边界,且是连续、闭合、等像素宽的边界,如图2所示。
在得到目标后,提取所有目标区域的颜色直方图特征。传统的RGB颜色模型的可分辨色差是非线性的,且不直观,所以不是一个好的颜色描述系统。HSV颜色模型与人的视觉特征比较接近,它由色度H、饱和度S和亮度V 3个分量组成。因为这种模型具有线性伸缩性,而且可感知的色差与颜色分量相对应样值上的欧几里德距离成正比,所以HSV颜色模型比RGB颜色模型更直观、更容易被接受。用Dist(vi,vj)表示2帧重要目标的HS直方图的匹配程度(卡方距离[11]),若当前帧和任一已经选取的关键帧的前景直方图匹配程度满足一定阈值,则应该将候选关键帧抛弃;反之,则说明包含重要目标,将候选关键帧加入关键帧集合。

图2 模糊粗糙区域分割技术提取目标
3 实验结果与分析
本文实验在Windows7系统环境下使用VS2010和OpenCV2.4.9实现,机器内存为2 G。为证明算法的有效性,测试大量的视频(来自标准视频库OpenVideo),结果表明本文方法提取的关键帧能够有效地突出视频的内容,关键帧的冗余度低,而且能够自适应确定关键帧数目。本文选择了3个视频来展示本文算法和核聚类算法[4]、自适应的帧差法和直方图平均法等经典算法的效果对比,结果见表1所列。

表1 测试视频结果
视频关键帧提取算法的评估可以使用查全率和冗余度来衡量。查全率就是正确检出的关键帧数占实际关键帧数的比例,冗余度就是冗余帧占所有检出的关键帧数的比例。
第1个视频描述了有关航天领域的一些画面,共9个主要场景,这个视频最大的特点就是场景切换时过渡非常平缓。4种方法的提取效果如图3所示,结果表明本文提出的算法对内容渐变视频的提取结果比其他方法更优。
第2、第3个视频分别包含22、34个场景,场景变化复杂多样,视频2展现的是一系列的自然风景,大海、火山爆发、峡谷等,视频3描述地震前后城市的废墟、市民活动及重建后面貌的场景。本文提出的算法和3种经典算法的效果对比见表2、表3所列。

图3 第1个视频提取的关键帧
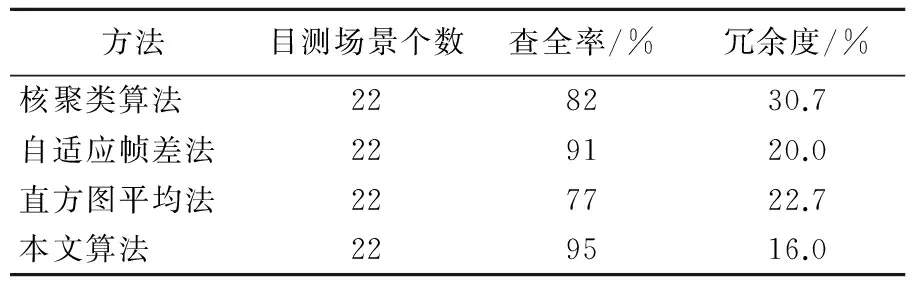
方法目测场景个数查全率/%冗余度/%核聚类算法228230.7自适应帧差法229120.0直方图平均法227722.7本文算法229516.0
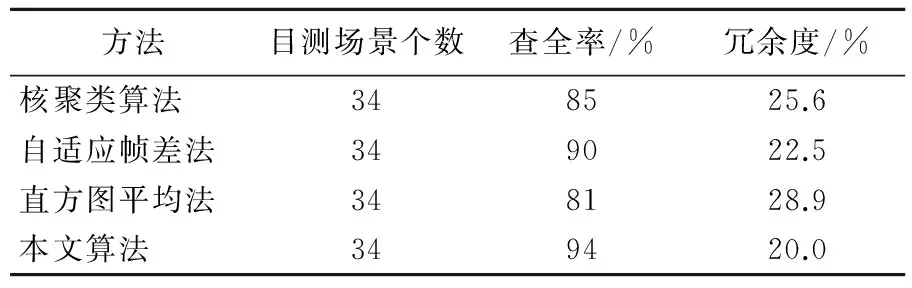
表3 4种算法对第3个视频提取结果比较
通过对实验数据的对比分析表明,本文提出的算法相比于其他几种方法拥有更高的查全率和更低的冗余度。体现出使用本文算法所提取的关键帧具有代表性,能够更加全面地突出视频的主要内容,并且能够更有效地控制冗余帧。
4 结 论
本文使用基于HOG的帧代表性计算指标量化了帧的重要程度,自适应变化的障碍项使本文算法对内容渐变的视频的处理结果比其他方法效果更好,提取的关键帧较全面地突出了视频的主要内容;然后利用高级特征进行冗余帧检查,节约了存储空间。
实验结果表明该算法具有以下特点:① 能够根据视频内容自适应确定关键帧数目;② 更加细致、全面地突出视频的主要内容;③ 更好地控制冗余帧。本文算法对背景很复杂的视频处理效果有待提高,今后的研究工作将进一步提高算法对场景更加复杂的视频的鲁棒性。
[1] NAGASAKA A,TANAKA Y.Automatic video indexing and full-video search for object appearance[J].Information Processing Society of Japan,1992,33(4):543-550.
[2] WOLF W.Key frame selection by motion analysis[C]//IEEE Int Conf On Acoustics,Speech,and Signal Processing Atlanta:[s.n.],1996:1228-1231.
[3] HANJALIC A,ZHANG H J.An integrated scheme for automated video abstraction based on unsupervised cluster-validity analysis[J].IEEE Transaction on Circuits and Systems for Video Technology,1999,9(8):1280-1289.
[4] ZHUANG Y T,RUI Y,HUANG T S,et al.Adaptive key frame extraction using unsupervised clustering[C]//International Conference on Image Processing[S.l.]:IEEE,1998:866-870.
[5] ZHANG H J,WU J H,ZHONG D.An integrated system for content-based video retrieval and browsing[J].Pattern Recognition,1997,30(4): 643-658.
[7] CHAKRABORTY S,TICKOO O,IYER R.Adaptive keyframe selection for video summarization[C]//IEEE Winter Conference,2015:702-709.
[8] BARHOUM W,ZHGROUBA E.On-the-fly extraction of key frames for efficient video summarization[J].AASRI Procedia,2013,4:78-84.
[9] DALAL N,TRIGGS B.Histograms of oriented gradients for human detection[C]//IEEE Conference on Computer Vision & Pattern Recognition.Washington,D.C.:IEEE Computer Society,2005:886-893.
[10] BARHOUMI W,GALLAS A,ZAGROUBA E.Effective region-based relevance feedback for interactive content based image retrieval[J].Studies in Computational Intelligence,2009,226:177-187.
[11] IEE Y J,GHOSH J,GRAUMAN K.Discovering important people and objects for egocentric video summarization[C]//IEEE Conference on Washington,D.C.:IEEE Computer Society,2012:1346-1353.
(责任编辑 张 镅)
A novel adaptive video key frame extraction method
WANG Yu, WANG Ronggui, YANG Juan
(School of Computer and Information, Hefei University of Technology, Hefei 230009, China)
In view of the problems in the existing methods of key frame extraction including the difficulty in determining the critical number of key frames, the unsatisfied treatment effect of the gradient of the content of video and the complex algorithm, an adaptive video key frame extraction method is proposed. Firstly, the value of representativeness of current frame is calculated by using histogram of oriented gradients(HOG) and the candidate key frame is selected. Then the redundancy check is made by using the target partition and color histogram features to determine the set of key frames. The experiments are carried out by means of a large number of videos containing various scenes, and the results show that the key frames extracted by the proposed algorithm can describe the main content of the video more comprehensively, the effect is better especially when dealing with a gradient of video content, and the key frame number can be determined adaptively according to the content of the video.
key frame; color histogram; histogram of oriented gradients(HOG); target partition; adaptive
2015-08-07;
2016-01-07
国家自然科学基金资助项目(61075032); 安徽省自然科学基金资助项目(J2014AKZR0055)
王 宇(1992-),男,安徽灵璧人,合肥工业大学硕士生; 汪荣贵(1966-),男,安徽池州人,博士,合肥工业大学教授,博士生导师.
10.3969/j.issn.1003-5060.2016.11.009
TP391
A
1003-5060(2016)11-1483-06
猜你喜欢
运输经理世界(2022年1期)2022-09-20
重庆科技学院学报(自然科学版)(2022年6期)2022-02-04
微型电脑应用(2020年12期)2020-12-25
长江丛刊(2020年13期)2020-11-19
沈阳理工大学学报(2019年3期)2019-08-21
兽医导刊(2019年1期)2019-02-21
四川水泥(2019年3期)2019-02-19
黑龙江交通科技(2017年7期)2017-09-20
百姓生活(2017年5期)2017-05-15
黑龙江交通科技(2017年10期)2017-03-01
