
关于计算机实时互联网信息过滤系统设计探讨
2016-12-15 18:13刘建宇
电脑知识与技术 2016年27期
摘要:设计计算机实时互联网信息过滤系统,对计算机实时互联网信息的内容进行审查,能够对含有不良、敏感等情况的内容,发现并追查,充分利用互联网信息过滤系统,进行自动检查。在当前信息安全需求不断强化下,具有重要应用价值。该文则对计算机实时互联网信息过滤系统设计展开探讨,以为计算机信息安全管理提供有效参考资料。
关键词:计算机;实时互联网信息过滤;系统设计
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2016)27-0027-03
Abstract: Design computer real-time Internet information filtering system, the content of computer real-time Internet information is reviewed, and can be found in the content of bad, sensitive, etc., and to trace, make full use of Internet information filtering system, automatic inspection. In the current information security needs continue to strengthen, has important application value. This paper discusses the design of computer real-time Internet information filtering system, which provides an effective reference for the computer information security management.
Key words: computer; real-time internet information filtering; system design
基于当前计算机技术的发展,互联网实时不良信息日益增多,设计计算机实时互联网信息过滤系统,能够从分词算法、文档语义、关键字方面,准确过滤实时互联网信息,不仅可以确保计算机实时互联网信息安全,也可以提升互联网信息过滤系统性能,发挥积极影响。以下对此做具体分析。
1计算机实时互联网信息过滤系统结构及功能设计
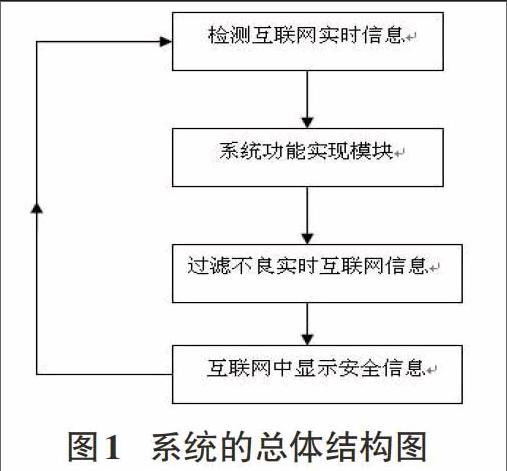
1.1系统总体结构
对于该系统设计中,由于互联网上各网页均采用实时动态发布技术,互联网上的数据非常庞杂【1-2】。因此,在设计计算机实时互联网信息过滤系统中,可以及时检测收集互联网实时信息,并将其传输给系统功能实现模块,对不良实时互联网信息进行过滤,并将过滤后的安全信息显示到互联网中。下图为总体设计结构:
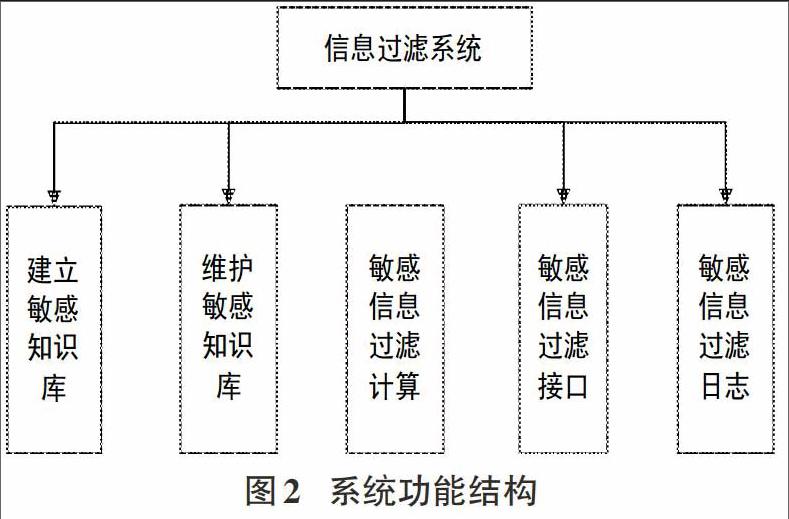
1.2系统功能设计
对于该系统设计中,对于计算机实时信息互联网过滤过程中,确保该系统具备多种功能,能够建立敏感知识库模块、维护敏感词知识库模块、敏感信息过滤计算模块、敏感信息过滤接口开发模块以及敏感信息过滤日志模块,有效完善系统对实时互联网信息过滤的功能。该系统功能结构如下图中所示:
建立敏感知识库:实时互联网敏感知识库由满足过滤需要的敏感词汇构成。敏感词库的建立可以共享国家互联网中心、公安部门等权威部门的数据,也可以通过积累及敏感信息特征构造等产生。在特征构造时需对敏感知识归一化处理,注意包括相近的、拆分的或者加拼音等词汇以及一些繁体字和自造字,比如对 “三去车仑工力”、“法伦功”、“法lun功”、“珐论功”等要统一转化为“法轮功”【3】。同时,需要对敏感知识库应进行分类整理,具体可以分政治敏感性、违法信息、广告宣传等类,比如:
政治敏感信息包括:涉国家安全的实时互联网敏感信息,涉国家领导人、集会游行、64事件、法轮功、中国台湾等。
违法信息包括:违反国家法律、产生社会危害的信息,如枪支、毒品买卖信息,提供色情、赌博服务的信息等。
此外,实时互联网敏感知识库的建立还必须要求能够具有自动识别功能,根据用户选择对误判或漏判词汇和特征的构造,智能识别敏感词汇,并将其自动加入敏感知识库。也可以根据实际进一步细分,比如违法信息细分成黄色、赌博、毒品等等。
维护敏感词知识库:实时互联网敏感词知识库应该是个动态的数据库,应根据需要实现自动更新和手动维护。实现对敏感知识库的可视化管理,能够分类浏览实时互联网敏感词库和其相近的词汇,支持单条和批量敏感词汇的增加、删除、修改操作【4】。此外,还可以支持通过计算机程序进行实时更新或定期手动更新,实现批量多条记录的增加、删除、更新操作。
敏感信息过滤计算:需要设计算法对实时互联网敏感词汇过滤计算。在对敏感信息过滤时,首先需要对过滤的内容进行预处理,其次根据敏感词汇的类型对敏感内容进行过滤计算。预处理过程如下:
1)消重:对需过滤实时互联网内容中重复的敏感知识进行消重。
2)格式化:自动处理过滤内容无效字符,如“ (空格)”、“.”“*”等信息。
3)拼音替换:将预处理内容中出现的拼音进行替换。
4)交叉歧义识别:对过滤内容进行中文分词,涉及交叉歧义的能够准确识别。
敏感信息过滤接口:实时互联网敏感信息过滤接口是将过滤算法进行封装【5】,供企业信用信息公示系统调用,对实时互联网自行填报的文本内容进行过滤,并返回处理结果。该接口返回内容包括:
1)处置动作:通过、可疑、严重;
2)命中高危敏感特征为严重:如“法轮功”、“卖枪”、“小姐上门”等违法信息、政治敏感信息等;
3)命中疑似敏感特征为可疑,如普通敏感等疑似敏感信息;
敏感信息过滤日志:系统自动记录调用敏感信息过滤接口的内容、IP地址、调用时间以及对各地对敏感信息处理的反馈结果等,供进行统计、分析等。
1.3实时互联网信息过滤算法
计算机实时互联网信息过滤系统设计中,能够从分词算法、文档语义、关键字方面,提升系统对不良实时互联网信息的过滤效率。
1)分词算法
建立停用词表,在这里面包括一些汉语中的常用词汇,对于这些常用词汇,也往往包括一些辅助词,确保其能够在许多文档信息中都可以大量出现,确保不能用可以描述文档特征的词汇,同时,也不能理解文档信息。这样的分词,可以确保系统过滤信息的正确性,为提升系统性能,将会产生极大影响【6】。其次,就可以互联网文档中,搜寻出现的过滤关键词,并能够将其提取出来。最后,可以先从文档读取出两个字符,搜寻文档中是否存在相同文档字符;就可以去根据这个假设,从而能够去预先的设定一个词语频率阀值,以此可以来对互联网文档中应该出现的次数进行分析,将次数少的词语进行剔除操作【7】。该方式,可以避免在过滤系统数据过程中,导致稀有词对系统信息过滤带来的干扰。
2)文档语义算法
能够将一篇文档表示为一个形成向量的过程,可以在形成时,提取出在文档之中的特征项信息,从而将其构成一个文档向量,达到过滤实时信息的目的【8】。可以对得到的文档语义特征项列表进行相关排序,然后可以通过特征项标识、权重等,生成该文档的向量模型,从而能够在系统中,以文档语义内容去过滤存在与实时互联网中的不良信息。
3)关键字算法
采用“关键词组抽取(Extractorke)”算法,结合相关概率统计的方法,实现对实时互联网信息中文本关键内容的提取过滤。
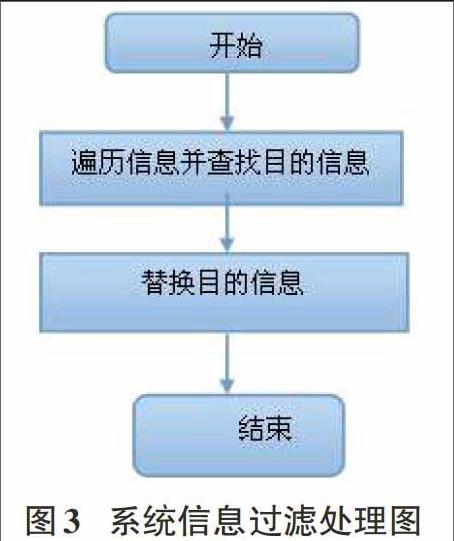
1.4互联网实施信息过滤处理
在该系统设计中,能够运用SPIDER系统,可以获取在网页源文件中的数据信息,并可以进一步去分析超链接中的递归扫描,可以根据其指定范围,确保有效的互联网过滤信息可以保存到网页资源库中。能实现可视化的配置扫描,附加实时信息的筛选、加信息过滤条件、能够进行最深层数的信息过滤。并且,还可以进行各类JavaScript的特殊解析,剥离出互联网实时用户所需信息,对互联网信息中的标题、正文以及作者等内容进行分析。建立系统模块内部过滤处理方法doFilter(),其信息过滤处理流程如下:
具体代码为:
public String doFilter(String str) {
//process the html tag <>
String r = str.replace(<, [)
.replace(>, ]);
return r;
}
1.5系统信息过滤测试
设计计算机实时互联网信息过滤系统,可以有效过滤在计算机中实时互联网中的不良信息,对于涉及敏感问题、敏感关键字、敏感信息的相关内容,均可以被系统过滤掉,不再互联网中显示。如下为一个系统测试代码实例:
public class Main {
/**
* @param args
*/
public static void main(String[] args) {
String msg = "大家好:),
公司地址: 北京市西城区德外大街83号德胜国际中心B-11
客服热线:400-656-5456 客服专线:010-56265043 电子邮箱:longyuankf@126.com
电信与信息服务业务经营许可证:京icp证060024号
Dragonsource.com Inc. All Rights Reserved

猜你喜欢
小学科学(学生版)(2021年7期)2021-07-28
趣味(数学)(2020年9期)2020-06-09
科技传播(2019年22期)2020-01-14
科技传播(2019年22期)2020-01-14
消费导刊(2017年20期)2018-01-03
衡阳师范学院学报(2015年3期)2015-02-10
