
公安警务领域视频图像侦查关键技术综述
2016-12-07 03:39唐文杰
中国公共安全 2016年15期
□ 文/唐文杰
公安警务领域视频图像侦查关键技术综述
□文/唐文杰
引言
随着视频联网监控系统在公安警务领域的应用,实时视频监控和历史视频调阅等基本功能为公安人员巡查治安、办案取证等工作带来了很大帮助,同时,视频监控系统的普及也为公安行业积累了海量的视频图像数据,如果对这些重要数据进行智能分析和处理,快速高效的获得精确警报或线索,能够充分发挥视频图像资源的作用,使得公安日常工作和刑事侦查更加快捷高效。然而,视频图像数据以指数速度增长,成为具有数据容量大(Volume)、数据类型繁多(Variety)、数据价值高(Value)、处理速度快(Velocity)4V特性的非结构化大数据,导致以人工方式从海量视频图像中发现线索非常耗时耗力,海量视频资源的高效能应用正在成为公安警务领域案件侦破和治安管控的新要求。
视频图像侦查技术通过运动目标检测、目标跟踪、目标分类与识别、浓缩摘要、行为分析等技术手段对视频图像数据进行分析处理,得到结构化的简短视频和语义描述,转化为公安实战的重要情报。通过对实时视频进行智能行为分析,并与提前设定好的规则进行比对,比如入侵、绊线、人群聚集等等,及时获得异常事件的报警信息,使得视频监控工作变得高效、准确及全面;通过对涉案视频进行浓缩摘要,自动去除视频中的静止画面,留下有价值的活动目标视频,可以大大缩短办案人员调阅历史视频的时间,比如一个120分钟的视频,在浓缩处理后,可能只需要1分钟就可以快速浏览到视频中所有的活动目标,大大提高了办案效率,并解决了视频的海量存储问题,节约了存储成本;通过对视频图像数据进行结构化,对检测到的活动目标进行分类,检测出涉案的行人、车辆及物品,与重点人员库、车辆库、物品库等进行专业的识别比对,帮助办案人员迅速发现重要线索,追捕嫌疑人。总之,视频图像侦查技术已成为智能视频监控技术创新发展的一个重要方向,也是公安警务领域智能信息化的必由之路。
公安警务中视频图像侦查技术架构
视频图像侦查技术源自于计算机视觉技术和人工智能技术,目标是对视频图像数据进行多维度的特征提取,进而让计算机读懂视频图像的含义,定位跟踪感兴趣的运动目标,实时分析目标行为,并根据预定的规则进行处理,实现异常事件的前期预防和快速反应;也可以对目标进行分类识别,将视频图像按照人、车、物等线索进行关联,实现案事件的后期侦破和高效处理。
视频图像侦查技术在公安警务场景中的基本应用有视频浓缩摘要和检索和行为分析预警,视频浓缩摘要和检索包括行人检测、车辆检测、人脸识别、车牌识别、特征检索等,行为分析预警包括入侵检测、绊线检测、人群聚集检测、物品丢失检测、遗留物检测等。公安警务领域的视频图像侦查技术架构如图1所示,分为三个阶段:
首先,采用图像增强、背景建模等技术将实时视频流或历史视频中的目标与背景分离,并对目标进行跟踪。
然后,对成功跟踪的目标进行分类,便于进行识别。目标分类将视频检测的运动目标分类为事先定义好的类别,实质上是提取目标的结构和语义特征,与类别特征进行映射,类别为从语义意义上选取的典型物体,目前在公安警务领域典型物体一般分为行人、车辆、人骑车三类,然后对这三类物体形态进行识别。
最后,在目标检测跟踪、分类识别的基础上,对目标进行进一步的应用,可以进行压缩拼接,形成摘要视频,便于后续检索,或者对目标的行为进行判定,如果有符合预先设定规则的行为,则触发报警或进一步处理。
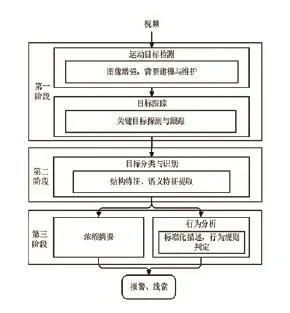
▲图1 公安警务中图像视频侦查技术架构
公安警务中图像视频侦查关键技术
本文研究公安警务领域涉及到的视频侦查关键技术,包括运动目标检测、目标跟踪、目标分类和识别、浓缩摘要和行为分析。
运动目标检测
公安警务领域的运动目标检测通过预处理、背景建模、目标分割等流程从视频或图像中提取出感兴趣的目标,比如人、车、物等,并确定当前目标所在画面的位置、大小,为后续的行人识别、车辆识别等做准备。运动目标检测是后续跟踪识别等算法的基础,其准确率和性能直接影响了后续算法的效果,根据处理的对象不同,运动目标检测算法分为基于背景建模的检测算法和基于目标建模的检测算法。
(1)基于背景建模的运动目标检测
基于背景建模的运动目标检测具有简单、速度快、受遮挡影响小等优势,但是背景建模要求背景固定、目标运动,因此在要求实时性强、摄像机固定的场景中应用广泛。
基于背景建模的运动目标检测首先进行背景建模,然后通过当前画面与背景图像的相减即可得到运动目标。但是模型建立后,可能对场景的变化比如阳光、云影、树叶、波浪等比较敏感,而良好的背景模型能消除或减少背景动态变化对于运动目标检测带来的影响。目前有很多研究致力于背景建模与维护,如卡尔曼滤波建模、均值滤波、中值滤波、最大值最小值滤波、线性滤波、非参数化模型、近似中值滤波、基于高斯假设的迭代方法、基于聚类的方法、基于隐马尔科夫的方法、基于自回归模型的方法、基于在线学习的方法以及基于时空背景随机更新的VIBE方法.其中,混合多高斯背景建模方法是目前普遍应用的一种前景提取方法.
(2)基于目标建模的运动目标检测
相比于基于背景建模的方法,基于目标建模的运动目标检测能良好的适应背景的运动,对目标的运动状态也没有要求,但是由于要对大量训练目标进行统计学习,所以速度相对较慢,一般适用于对实时性要求不强的应用场景。基于目标建模的运动目标检测一般采用滑动窗口的策略,扫描每个滑动窗口的图像,根据模型判定图像是目标还是背景,目标检测的效果取决于模型的鲁棒性。根据建模的方法不同,基于滑动窗口的目标检测主要分为刚性全局模板检测模型、基于视觉词典的检测模型、基于部件的检测模型和深度学习模型,其他模型中有语法模型以及生物启发特征模型等。其中刚性全局模板检测模型中的梯度方向直方图特征,成为近年以来最有影响力和最为成功的特征之一,而基于深度学习的目标检测模型正在成为研究的热点。

目标跟踪
公安警务领域的目标跟踪主要是跟踪感兴趣的行人、车辆、物品等目标,获得目标的前景动态信息,如时间、位置、运动轨迹、方向等等,本质上是在连续视频之间建立基于位置、速度、形状等特征的对应匹配,目的是在连续视频图像的帧之间建立目标的对应关系,便于后续对目标进行辨认。目标跟踪是视频图像侦查中最关键的过程,是后续分类、识别、压缩及分析的重要前提。公安警务领域目标跟踪多为单场景单目标或单场景多目标跟踪,单场景单目标跟踪是指对同一个摄像机拍摄的单一视频场景中指定的某一个目标进行连续跟踪,单场景多目标跟踪相对复杂,是指对同一个摄像机拍摄的单一视频场景中多个目标进行跟踪。
单目标跟踪主要有基于点的跟踪、基于核或面的跟踪、基于主动轮廓的跟踪以及基于模型的跟踪,其中比较常用的方法是预测运动体下一帧可能出现的位置,在其相关区域内寻找最优点。诸多研究成果集中在均值漂移算法,卡尔曼滤波,粒子滤波,粒子滤波改进算法。另外也有研究提出基于检测的跟踪,代表性方法有基于在线特征提升的跟踪算法,基于多示例学习的跟踪方法,利用在线的空时上下文结构信息来辅助跟踪等。
多目标跟踪问题更加复杂,有研究将其描述为一个候选区域和已有目标轨迹之间的数据关联问题,代表性方法如多假设跟踪器和联合概率数据关联滤波,也有一些研究将跟踪问题看成是贝叶斯状态空间推断问题,如贝叶斯多目标跟踪器。目前的多目标跟踪算法普遍计算效率不高,如何考虑目标间的交互,并且提高多目标跟踪的效率是一个值得研究的问题。
目标分类与识别
公安警务领域的目标分类与识别目的是对跟踪到的目标进行辨识,比如识别到车辆的颜色、车牌号、车型车款、车饰物等特征,便于车辆布控、车辆违规检测等工作的进一步执行。目标分类与识别技术首先利用大量的目标样本对系统进行模型训练,学习出不同目标的特征,然后在这些模型上验证新的样本是否匹配。
一般将视频图像中的目标特征分为底层特征和高层语义特征,底层特征包括全局特征、局部特征、结构特征等,其中全局特征又细分为颜色特征、形状特征、纹理特征等,局部特征包括SIFT特征、SURF特征等;高层语义特征是指以底层特征为基础,在语义模型上识别出的更高层次的特征,比如行为特征即为语义特征。本节重点阐述面向目标底层特征的分类与识别,在公安警务领域,目标底层特征包括行人衣着颜色、头发颜色、车辆颜色、车牌号等等。
目标分类与识别是视频图像侦查技术应用的重要环节,也是最具有挑战性的环节。好的目标分类与识别算法对模型的要求非常高,目前研究和应用较多的是相似度模型和深度学习模型。
(1)相似度模型
相似度模型首先将目标对象进行特征表示,即特征编码,然后根据一定的相似度计算方法计算特征集合之间的相似关系。其中,特征编码密集提取的底层特征中包含了大量的冗余与噪声,为提高特征表达的鲁棒性,需要使用一种特征变换算法对底层特征进行编码,从而获得更具区分性、更加鲁棒的特征表达,这一步对目标识别的性能具有至关重要的作用。因而,大量的研究工作都集中在寻找更加强大的特征编码方法上,重要的特征编码算法包括向量量化编码、核词典编码、稀疏编码、局部线性约束编码、显著性编码、Fisher向量编码、超向量编码等;相似度度计算主要包括向量空间模型、基于哈希的相似度计算以及基于主题的相似度计算。
(2)深度学习模型
经研究,人脑之所以能迅速看懂输入的视频图像,是视网膜上的图像映射经过层层神经元的提取和计算,每个层次都降低前一个层次处理的数据量,并且保留物体有用的结构信息。为了让计算机也具有类似人类感知系统能够更深入理解视频图像的能力,需要构建多层非线性处理组成的模型,即深度结构。从最早提出的含多个隐藏层的多层神经网络以及向后传播训练算法,对深度学习模型的研究从未间断,应用较好的有卷积神经网络,Sigmoid信度网,深度信度网,以及深度信度网的变种,比如深度玻尔兹曼机、深度自动编码机以及深度神经网络等等。其中,深度卷积神经网络在图像识别应用上取得了较好的效果,尽管用监督学习的方式直接训练深度神经网络非常困难,但是卷积神经网络却成为了一个例外,相比传统的多层神经网络和相应的向后传播学习算法,卷积神经网络可以更容易的从非线性空间找到最优点。深度学习模型是目前目标分类与识别中最准确的方法。
浓缩摘要
公安人员在办案过程中往往需要观看与案发时间、地点等相关的所有视频,传统方式下,24小时的视频要花费同样24小时才能查阅完毕,而且可能发生遗漏,视频浓缩摘要大大改善了这种工作模式,提高了视频查证的效率和全面性。视频浓缩摘要是指从原始视频中提取有用的前景目标的活动信息,然后和背景视频合成剪辑而成较短的视频片断,其中包含了原始视频中所有重要的活动目标和快照,视频浓缩摘要通常分为基于静态关键帧的方法和动态的视频缩略方法。
(1)基于静态关键帧的方法
关键帧是能够反映视频主要信息的图像帧,关键帧序列可组成故事板,它以简洁的形式反映了视频的主要内容。目前视频关键帧的提取方法主要有基于颜色直方图的方法,基于颜色熵的方法,基于运动活动性的方法,基于宏块统计特性的方法等等。由于视频图像序列的相似性很强,存在很多冗余,因此现有的关键帧算法大多是基于镜头来进行的。
(2)动态视频缩略方法
动态的视频缩略可以看作是原始视频的一种特殊编辑,它保留了视频的主要内容和时间推进线索。目前研究者提出了很多视频缩略算法,有基于聚类的方法,比如基于镜头序列或图像色彩的相似性分析,光流法,拟合法等等;还有基于模型的方法,比如EDU模型,CPR模型,时空运动模型,马尔科夫模型等等;基于语义的方法是根据高层语义概念特征对视频进行切分和提取。
行为识别
行为分析技术可以实时发现视频流中的异常行为,比如闯入电子围栏、打架斗殴、闯红灯等等,并及时处置,极大的改善了公安监控人员的日常监控工作,将公安监控人员从“死盯屏幕”的工作状态中解脱出来。行为分析技术分为模板匹配法和状态空间法。
(1)模板匹配法
模板匹配法将从输入视频图像序列提取的特征与在训练阶段预先保存好的模板进行相似度对比,行为分析的结果即为与测试序列距离最小的已知模板的类别。常用描述行为的模板有运动能量图像,运动历史图像等,后续的相似度匹配常采用最近邻方法、马氏距离计算法等等,另外,也有研究提出基于动态时间规整的模板匹配法。模板匹配法计算复杂度低、实现简单,但对噪声和运动时间间隔的变化比较敏感。
(2)状态空间法
状态空间法,又叫概率转移法,该方法将行为的每一个姿态或运动状态作为状态图的一个节点,通过某种概率将对应于各个姿势或状态节点之间的依存关系联系起来,这样任何人体行为运动序列可以看作在图中若干节点或状态之间的一次遍历过程。应用较为广泛的状态空间模型为隐马尔可夫模型和动态贝叶斯网络,多为这两类模型的改进版,比如耦合隐马尔可夫模型,可变长马尔可夫模型;抽象隐马尔可夫模型;基于典型样本的隐马尔可夫模型;此外,熵隐马尔可夫模型、分层隐马尔可夫模型、最大熵马尔可夫模型等也被用于复杂行为识别。贝叶斯网络模型有基元动态贝叶斯网络,分级贝叶斯网络,含有多层状态的分层且带驻留时间状态的动态贝叶斯网络,此外还用神经网络、条件随机场、有限状态机、置信网络等方法来识别人体行为。
总结与展望
随着视频图像分析在公安警务领域的普遍应用,视频图像侦查已成为继刑侦、技侦、网侦之后的第四大侦查技术,所以提高视频图像侦查技术的准确度和速度已成为公安部门的迫切需求。本文总结描述了公安警务领域视频图像侦查关键技术的架构以及具体技术的相关算法,如运动目标检测、目标跟踪、目标分类和识别、浓缩摘要和行为分析。值得一提的是,深度学习模型在视频图像侦查中的应用非常值得期待,如何在大数据等高新技术的帮助下,使得深度复杂模型在保证准确率的前提下,提高计算效率成为新的研究方向。
作者单位:中国电子进出口总公司
猜你喜欢
现代世界警察(2022年8期)2022-08-19
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
Traditional Medicine Research(2020年1期)2020-01-15
电子制作(2018年17期)2018-09-28
通信电源技术(2018年5期)2018-08-23
现代世界警察(2017年12期)2017-12-19
领导决策信息(2017年16期)2017-06-21
中国交通信息化(2016年10期)2016-06-08
中国市场(2016年44期)2016-05-17
军事体育学报(2015年2期)2015-02-27
