
基于规则的维吾尔语、哈萨克语机器翻译∗
2016-11-28 06:26:36如克燕木吾斯曼江买热哈巴艾力吐尔根依布拉音
新疆大学学报(自然科学版)(中英文) 2016年3期
如克燕木吾斯曼江,买热哈巴艾力,吐尔根依布拉音
(1.新疆大学信息科学与工程学院,新疆乌鲁木齐830046;2.新疆大学新疆多语种信息技术重点实验室,新疆乌鲁木齐830046)
0 引言
机器翻译又称为自动翻译,是利用计算机将一种自然语言转换成另一种自然目标语言的过程.机器翻译的实现将克服使用不同语言者之间的语言障碍.机器翻译的研究是建立在计算机科学、语言学、数学这三门学科的基础上.自然语言的复杂性使得机器翻译的实现极为困难,至今机器翻译是一项非常具有挑战性的课题.机器翻译主要方法包括基于规则的方法、基于语料库的方法、基于统计的方法与基于实例的方法.
维吾尔语和哈萨克语都属于阿尔泰语系突厥语族,属于接近语言.维吾尔语使用人口约有1 200万.哈萨克语使用人口约1 740万,在中国约150万左右.由于维吾尔语、哈萨克语在词结构、构形、语法、句法等方面有很多相同或相似之处,因此,实现维吾尔语、哈萨克语机器翻译相对比较简单.我们的目的是建立基于规则的维吾尔语、哈萨克语机器翻译系统.
1 相关工作
机器翻译的研究不仅包括非接近(non-closed)语言之间的翻译(如:英语和俄语之间),还包括接近(closed)语言之间的翻译(如:土耳其语和克里米亚鞑靼语之间).接近语言之间的机器翻译研究从上世纪80年代开始.1987年Jan Haji开发了捷克俄罗斯机器翻译系统RUSLAN,他们采用了基于规则的方法,翻译准确率达到了80%[1].2000年Jan Haji开发了两个斯拉夫语之间语言:捷克语斯洛伐克语机器翻译系统,采用了基于规则的方法,准确率达到了90%[2].2001年Kemal Altınta开发了土耳其语克里米亚鞑靼语机器翻译系统,也是采用基于规则的方法,翻译准确率达到了80%[3].2003年Garrido Alenda开发了基于开源的浅转移葡萄牙语西班牙语机器翻译Apertium,并提出改进系统架构来提高翻译质量的方法[4].以后将机器翻译工作广大到其他一些斯拉夫语言,如波兰、塞尔维亚和立陶宛(Jan Haji)[5].2005年M.Corbi开发的基于开源的浅转移西班牙拉丁语机器翻译系统已经实现,并提供给公众使用[6].根据以上的研究,接近语言之间的翻译采用规则的方法比较简单和容易实现.维吾尔语和哈萨克语属于接近语言.由于维吾尔语、哈萨克语在词结构、构形、句法等方面有很多相同或相似之处,因此,本文用基于规则的方法来实现维吾尔语、哈萨克语机器翻译.
2 维吾尔语和哈萨克语的比较
维吾尔语(uyghur)属于阿尔泰语系突厥语族葛逻禄分支,哈萨克语(kazak)属于阿尔泰语系突厥语族钦察分支,都属于黏着型语言[7].黏着型语言的特点体现在强大的派生能力及丰富的构形上.粘着性语言的一个词可连接不同的词尾构成不同的形态,在句子中有不同的语法意义.维吾尔、哈萨克语两种语言都具有黏着性语言的以上特性,但在语法方面有一定的差别.这两种语言之间的主要的异同点可归纳为如下几种:
1.字母方面:维吾尔语共有32个字母即8个元音和24个辅音,而哈萨克语有33个字母即9个元音和24个辅音.
2.音节方面:维吾尔语和哈萨克语一样,每个词都是由一个或一个以上的音节组成.音节由一个元音或一个元音和一个或多个辅音组成.维吾尔语和哈萨克语音节结构大致上一样,形式包括:A、AB、BA、BAB、ABB、BABB等,其中A表示元音,B表示辅音.
3.词法方面:维吾尔、哈萨克两种语言都有名词的人称、数、格范畴;动词的否定、人称、数、时、式、态、体范畴;形容词的级范畴等.维吾尔、哈萨克语言都有丰富的词尾,但属于同一个范畴的词尾数量互不相同.比如:维吾尔语名词的复数词尾有两种“-ler/-lar”,而哈萨克语名词的复数词尾有“-lar/-ler/-tar/-ter/-dar/-der”.不管是哪一种语言,对于某个词干缀接其中哪个复数词尾完全取决于语音和谐规则[8].如表1所示.

表1 维吾尔语、哈萨克语词尾缀接对比表
从表中可以看出,维吾尔语词干需接复数词尾只从“-lar或-ler”中选一即可,哈萨克语词干需要从6个表示复数的词尾中选一.同时,维吾尔语名词复数词尾“lar”的连接规则与哈萨克语名词复数词尾“-lar,-tar,-der”相似;维吾尔语词尾“-ler”的连接规则与哈萨克语词尾“ler,-ter,-dar”相似.两种语言词尾之间的这种一对多或者多对多的映射情况非常普遍.
4.句法方面:维吾尔语和哈萨克语的句子结构相同,都属于SOV结构,并且句子中的词序也相同.如图1所示.
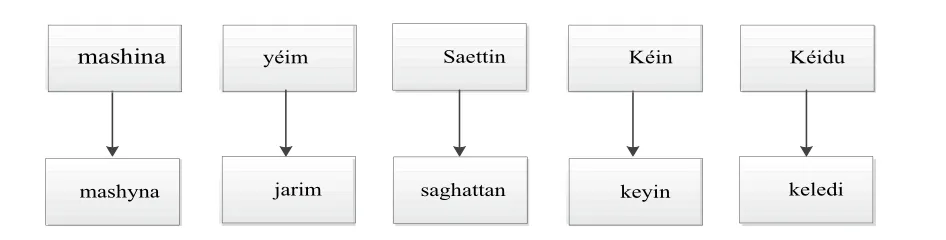
图1 维吾尔、哈萨克语句子结构
图中上一行是一条维吾尔语句子,表示“车半小时后到”,下面是对应的哈萨克语句子,可看出两者句子中对应词在句子中的词序几乎是相同的.
根据以上分析可知,维吾尔、哈萨克语之间的机器翻译利用规则的方法实现是完全可行的.从某种角度讲,维吾尔、哈萨克语机器翻译可以看成是对应词替换的结果,但实际上远比词替换复杂得多,因为还得考虑以下几点:(1)词的不同形态问题.维吾尔语中一个词有多种形态,如:kitab(书),kitabim(我的书),kitabimizdin(从我们的书中),kitabning(书的),kitabi(她的书),kitablarim(我的几本书),kitabingni(把你的书)等等.显然给词替换带来困难,也会导致数据稀疏问题.为克服此问题,应对维吾尔语词进行词法分析并分出词干和各词尾;(2)维吾尔、哈萨克语词干之间的对应关系可利用维吾尔、哈萨克语词典获得,但需要处理维吾尔、哈萨克语词尾之间的映射问题;(3)得到哈萨克语词干和词尾后需要根据哈萨克语的语音和谐规则,重新生成正确的哈萨克语词.
根据以上分析,我们设计了维吾尔、哈萨克语机器翻译系统:首先对维吾尔语词进行词法分析得到词干和词尾;其次,根据维吾尔、哈萨克语词典以及维吾尔、哈萨克语词尾映射表将维吾尔语词尾转换成哈萨克语词尾;最后,将上步取得的哈萨克语词干和词尾结合生成哈萨克语词.
3 维吾尔、哈萨克语机器翻译系统的架构
基于规则的维吾尔语、哈萨克语机器翻译系统的架构如图2所示.
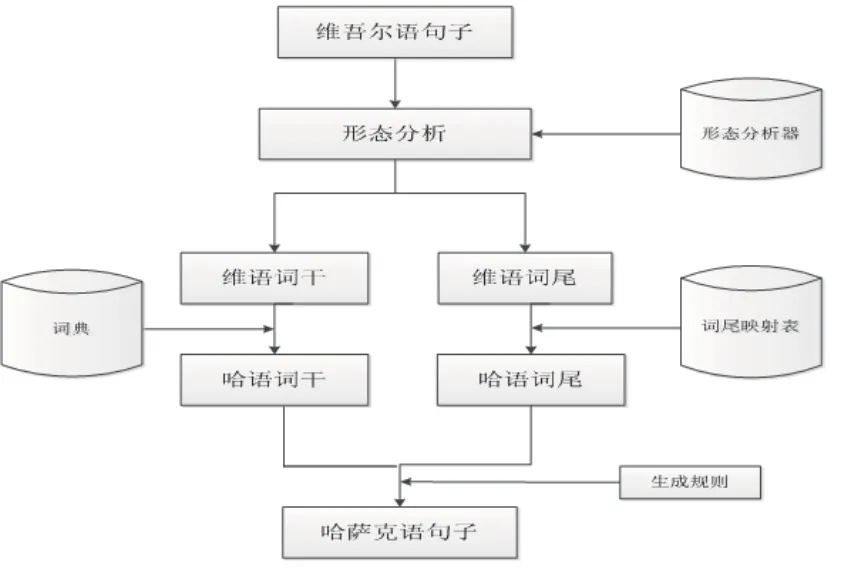
图2 维吾尔、哈萨克语机器翻译架构图
3.1 维吾尔语形态分析
维吾尔语形态分析是维吾尔、哈萨克语机器翻译中需要完成的第一步且是最重要的部分[9],其目的是得到维吾尔语词的词干和词尾,以便使用词典找到维吾尔语词对应的哈萨克语词.维吾尔、哈萨克语词典收录的词项都是词干,查找未经过词法分析的词容易导致未登录词的出现.以下面给出的维吾尔文句子以及相应的形态结构例句.
维吾尔文原句:men ingiliz tiliüginishni yaxshi k´orimen(我喜欢学英语).
形态分析后:men ingiliz til+i uginish+ni yaxshi k´or+I+men.
通过词法分析后得到的词干可从维吾尔、哈萨克语词典中查找.为此,我们需要一部维吾尔、哈萨克语词典.
3.2 维吾尔、哈萨克语词典及维吾尔、哈萨克语词尾映射表的构建
维吾尔、哈萨克语机器翻译中,词典占据极其重要的地位.整个翻译过程中,维吾尔语词干是利用维吾尔、哈萨克语词典将当前维吾尔语词干翻译成相应的哈萨克语词干.词典的覆盖面直接影响翻译质量,也与未登录词的数量正相关.目前,还未发现公开发布的维吾尔、哈萨克语机读词典.为提高翻译质量,我们构建了一定规模的维吾尔、哈萨克语对应词典,目前词典词条数量达到了7 000个,主要以新闻领域词条为主.同时构建了维吾尔语词尾和哈萨克语词尾之间的映射表.维吾尔语与哈萨克语的词尾数量虽不一样,但它们所属的范畴一样,它们之间的映射是多对多的关系.根据此特性,我们构建了分类的维吾尔、哈萨克语词尾映射表,用于将当前词尾转换成相应的哈萨克语词尾.由于资源的匮乏,我们只对动词、名词和形容词的词法范畴构建词尾映射表,见表2.

表2 维吾尔、哈萨克语词尾映射表
3.3 哈萨克语词干、词尾结合规则库的建立
建立结合规则库的主要目的就是将以上步骤得到的哈萨克语词干与词尾重新组合成哈萨克语的自然词.前面已分析,维吾尔、哈萨克语词尾之间存在着多对多的关系,当前哈萨克语词干应与同一类词尾中哪个词尾结合是根据结合规则库来完成.为此,我们根据哈萨克语的语音和谐规律以及词尾的连接规则,构建了哈萨克语词干、词尾结合规则库.下面以缀接名词复数词尾为例,介绍了规则库的基本内容.
哈萨克语名词复数词尾有{lar,ler,dar,der,tar,ter}对当前词干接其中哪个词尾是通过以下规则来完成:
if(词以元音“a,u,i,o”结尾或浊辅音“r,w,y”结尾词的最后音节包括“a,u,i,o”);
then 词干=词干+ “lar”;
else if(词以元音“e,´u,´o,´ı”结尾或清辅音“p,f,t,s,ch,sh,k,q,x,xh”结尾词的最后音节包括“e,´u,´o,´ı”);then 词干=词干+ “ter”;
else if(词以元音“a,u,i,o”结尾或浊辅音“z,n,j,l,m,ng” 结尾词的最后音节包括“a,u,i,o”);
then 词干=词干+ “dar”;
..................
3.4 目标语言的生成
目标语言生成,是维吾尔、哈萨克语机器翻译系统的最后步骤.根据以上步骤得到相应的哈萨克语词,构建当前维吾尔语句子的哈萨克语译文.如下图3描述维吾尔语句子“xizmetke chiqidighan waqit boldi.”(上班时间到了)的翻译过程:
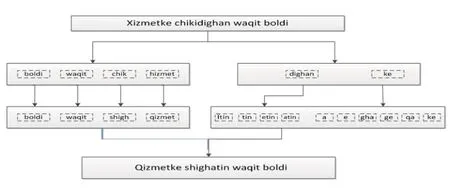
图3 维吾尔、哈萨克语机器翻译过程图
4 实验
机器翻译评价方法有两种形式:自动评测和人工评测.本实验中人工评测标准从“可懂度”和“忠实度”两个方面进行.首先从新疆大学自然语言处理实验室构建的维吾尔语语料库中选500条句子,邀请5个即会维吾尔语、也会哈萨克语的评测人员.要求参加评测人员根据参考文对每一句子给出1到4之间的值.自动评测主要用的是BLEU方法.
先对动词和名词的词法范畴构建词尾结合规则库进行实验(词典词条数量5 000),实验结果见表3.

表3 系统翻译评价结果
然后对形容词的词法范畴构建词尾结合规则库进行实验(词典词条数量7 000),实验结果见表4.

表4 系统翻译评价结果
实验结果表明我们制定的维吾尔、哈萨克语机器翻译方案可行,但翻译质量不够理想.究其原因:第一,未能得到大规模维吾尔、哈萨克语词典,需要我们自己建立.而我们为此次实验准备的词典规模非常小,导致翻译结果出现很多未登录词.第二,维吾尔语中多词表达及命名实体无法用词典替换的方式获得对应的译文.第三,因为词典问题,只对维吾尔语中动词、名词与形容词的词法范畴构建词尾结合规则库,所以在实验中有些词尾翻译不出来词,源语言中除了名词和动词之外其它词性的都呈现为未登录词.
针对以上问题,首先需要增加词典规模,以及构建维吾尔、哈萨克语命名实体对应表.同时抓紧构建其它词性之间的对应规则库来提高翻译质量.这也是我们今后工作的重要点.
5 总结
目前为止,本系统作为基于规则的机器翻译方法首次设计并实现了维吾尔、哈萨克语之间的翻译系统,是维吾尔、哈萨克语机器翻译系统的首例.我们开发的系统尚缺乏形态消除歧义器.因为维吾尔语、哈萨克语的有些词表示不同的几个意思.如:维吾尔语词“at”可以是名词,也可以是动词.名词时表示“马”和“名字”的意思,动词时表示“抛”的意思.哈萨克语也有相同的情况.另一个问题是,虽然语言是非常相似的,还有一些问题不能单用词法分析来解决.维吾尔语和哈萨克语具有相同的词序,句子组织在许多不同的方式有相同的含义.虽然系统还不完整,但我们提出的方案已经证明是可行的,值得进一步研究及完善.
猜你喜欢
考试与评价·八年级版(2020年5期)2020-10-29 05:42:35
现代职业教育·高职高专(2020年22期)2020-03-24 22:46:34
鸭绿江·下半月(2019年7期)2019-11-05 05:32:22
中文信息学报(2018年11期)2018-12-20 06:08:44
小学生时代·大嘴英语(2016年6期)2016-07-02 20:13:31
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12 01:16:14
中文信息学报(2015年5期)2015-04-21 10:41:55
中文信息学报(2015年3期)2015-04-21 08:33:49
语言与翻译(2014年2期)2014-07-12 15:49:28
语言与翻译(2014年2期)2014-07-12 15:49:13
