
基于Heritrix与Lucene的地震专业搜索引擎设计
2016-11-26 04:50李亚龙
地震地磁观测与研究 2016年5期
孙 静 李亚龙 万 杰
(中国合肥230031安徽省地震局)
基于Heritrix与Lucene的地震专业搜索引擎设计
孙 静 李亚龙 万 杰
(中国合肥230031安徽省地震局)
随着网络科技的发展,用户对搜索引擎提出更高要求,专业搜索引擎应运而生并不断发展壮大。对地震专业搜索引擎进行系统研究,提出一种基于网络爬虫Heritrix和开源全文信息检索包Lucene的专业检索解决方案,完成信息资源抓取、镜像文件建立及索引、搜索等关键操作的建立。
地震;Heritrix;Lucene;索引;搜索
0 引言
当今世界是信息的世界,网络信息资源飞速膨胀,如何在浩瀚如海的信息空间里快速查找并获取所需信息已成为信息时代的根本问题之一。网络搜索引擎在网络信息资源查找中起到重要作用,可以帮助人们在繁多的网络信息中查找所需内容。然而现有搜索引擎,如Google、百度等,均非为特定领域设计,面向某一特定领域某一特定专业、某一特定用户的专业搜索引擎,即垂直搜索引擎(又被称为专业搜索引擎),应运而生。专业搜索引擎可以更好地面向特定领域特定专业进行深入信息搜索,从而满足特定用户需求。
本文提出的地震专业搜索引擎即为一种专业搜索引擎,该引擎基于Lucene和Heritrix两个核心技术,实现信息资源的抓取和索引、搜索功能的建立,提供在线查询接口和友好的用户界面。
1 Heritrix和Lucene技术
1.1 网络爬虫Heritrix
Heritrix是一款基于Java语言开发的开源的爬虫框架,被用来获取完整的、精确的、站点内容的深度复制,包括获取图像及其他非文本内容、抓取并存储相关内容,具有良好的可扩展性,开发者可以扩展插件模块,来实现自己的抓取逻辑(邱哲,2010)。Heritrix包含以下主要组件:①CrawlOrder,为整个抓取任务的起点;②CrawlController,是一次抓取任务中的核心组件;③Frontier,为ToeThread提供URI工具;④ToeThread和ToePool,提供一个标准线程池,用于管理抓取线程ToeThread;⑤Heritrix提供一系列Processor,负责对URI进行不同处理。
1.2 开源式全文检索工具包Lucene
Lucene是一个开发源代码的全文检索引擎工具包,可以提供完整的查询检索和索引检索引擎功能,支持英文与德文两种语言进行逻辑设计。Lucene是基于javayuan框架,针对完成本搜索引擎系统的索引和查询功能设计的核心工具,程序设计员通过对Lucene的调用,轻松高效地完成全文索引引擎设计(邱哲,2010)。Lucene能对文档进行预处理、过滤、分析、索引和检索排序,应用程序编程接口和调用函数系统丰富,具有高效、简单的特点。
2 地震专业搜索引擎设计
2.1 总体设计
地震专业搜索引擎是服务于地震行业,是以地震为专业内容的搜索引擎系统。本搜索引擎包含3大模块:基于Heritrix技术的排序抓取设计模块、基于Lucene技术的索引排序模块、基于网页技术的用户界面及结果显示模块。地震专业搜索引擎具体流程如下:基于Heritrix技术,爬行抓取相关网页HTML格式和TXT格式的文本;基于Lucene技术设计索引排序模块,对抓取的本地磁盘文本内容进行排序和索引;使用基于网页技术的用户界面及结果显示模块,对用户的搜索要求进行相应接收,变成相应搜索指令,依据指令,将搜索结果按照相关网页链接时间进行排序,以关键字提亮后显示给用户,用户点击相关链接浏览(图1)。
地震专业搜索引擎分为前端程序和后端程序两部分(图2)。在前端流程中,用户在搜索引擎提供的界面(用户界面一般是一个带有输入框的 Web 页面)中输入搜索关键词,应用程序将关键词解析成搜索引擎可以理解的形式,在索引文件上进行搜索操作,排序后,搜索引擎将搜索结果返给用户。在后端流程中,网络爬虫从因特网上获取 Web 页面,索引子系统进行解析并存入索引文件(杨颂,2010)。
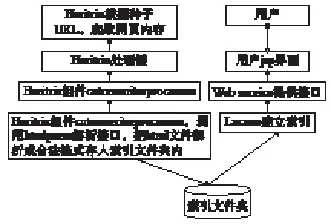
图1 专业搜索引擎系统流程Fig.1 Specialty search engine system flow chart
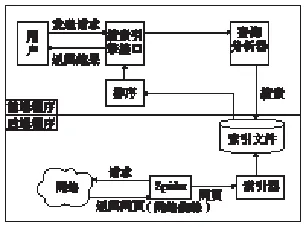
图2 专业搜索引擎整体架构Fig.2 Specialty search engine architecture
2.2 实现基于Heritrix的抓取模块
2.2.1 Heritrix安装配置。本项目下载使用Heritrix1.14.4源代码版本。在Eclipse中新建Java工程,将所需类库和源代码导入工程,需注意文件放置路径。在Heritrix目录下的conf文件中Heritrix.Properties设置两行: Heritrix.mdline.admin=admin:admin,
“admin:admin”分别为用户名和密码;heritrix.cmdline.port=8081,默认的8080被Tomcat占用,需要修改。配置后的Heritrix项目运行结果见图3。在浏览器中输入http://localhost:8081,以Web方式配置Heritrix(具体配置细节可以参考相关文档),即可进行网页抓取。
图3 Heritrix运行成功Fig.3 Heritrix successful operation diagram
2.2.2 网页过滤。Heritrix抓取网站内部URI及包括的所有文件,一般只需搜索纯文本,可以通过重写FrontierScheduler内部的schedule达到过滤目的。实现代码如下

为了提高抓取效率,可设置函数considerRobotsPreconditions(CrawlURI curi)的返回值为false,取消robots.txt的限制,抓取速度将提高至少一半 (罗刚,2009)。
2.3 设计与实现基于Lucene的排序和索引
抓取结束后,将搜索的结果数据进行索引、分词,并对外提供接口展示给用户。
2.3.1 网页解析。抓取的网页源码包含大量HTML标签,需经网页过滤提取有用信息。在此使用Lucene提供的HTML解析器和htmlparser,改造或提取HTML,从中获取节点的各项属性和信息(黄颖,2008)。
地震专业搜索引擎使用Eclipse开发,新建Java工程,导入htmlparser.jar包和luceneHtmlParser包。新建一个类initHtmlParser,解析原始网页,提取有用信息,并被其他控制类调用,部分核心代码如下


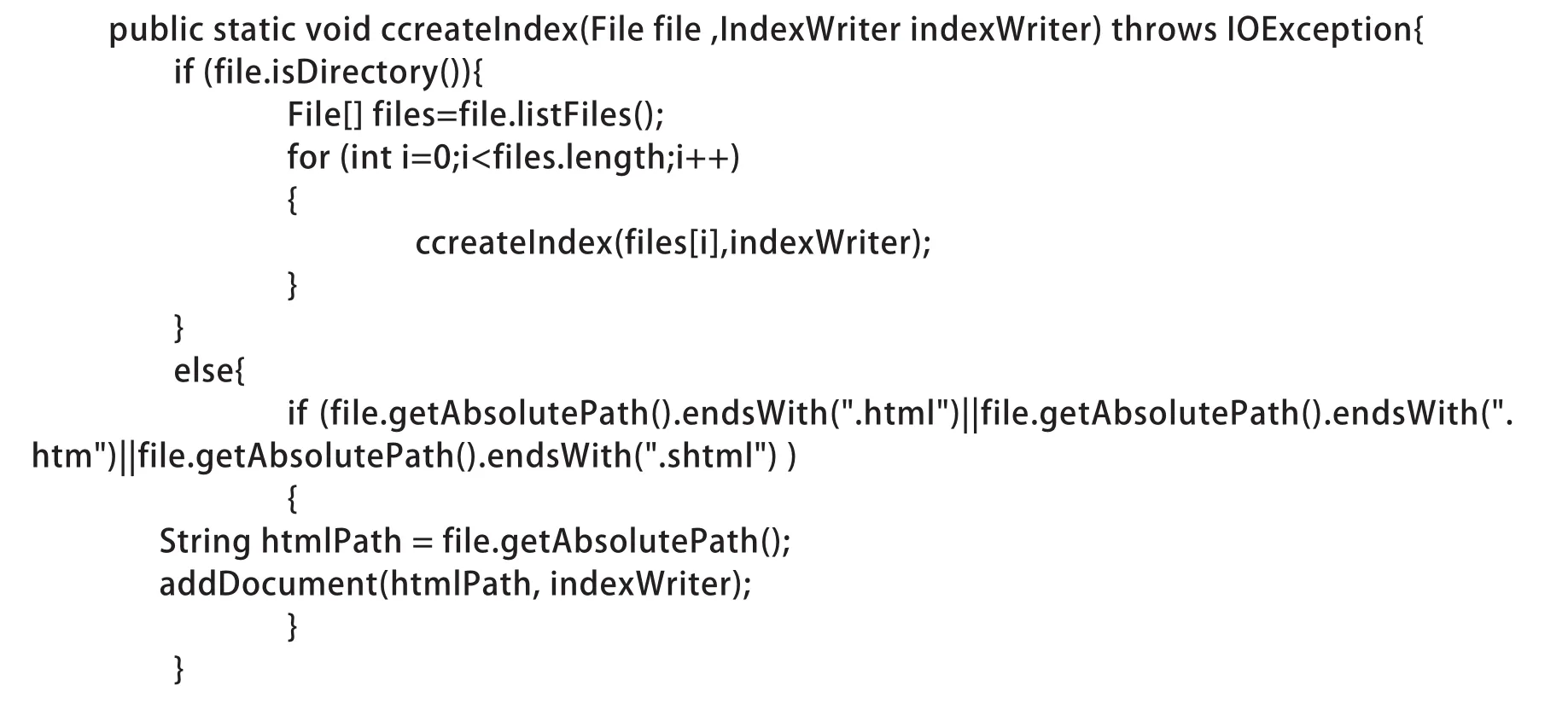
2.3.2 索引建立。新建 “test.dw.paper.lucene.index”包,添加indextest类,用来建立索引。indextest类包含两个私有属性,分别是dataDir和indexDir。dataDir代表存放等待进行索引的 HTML页面的路径,indexDir代表存放Lucene索引文件的路径。类indextest提供3个方法,分别是createIndex、addDocument和ifIndexExist。可以使用方法createIndex创建索引,采用方法 addDocument向一个索引上添加文档,即添加一个HTML页面。addDocument调用HTMLDocParser提供的方法,对HTML文档进行解析,使用ifIndexExist判断Lucene的索引是否存在。ccreateIndex是一个递归遍历文件目录来建立索引的函数。核心代码如下
2.4 实现搜索功能
为了实现搜索功能,定义SearchManager类和SearchResultBean类。SearchManager用来实现搜索功能,SearchResultBean是个JavaBean,用来描述搜索结果的结构。SearchManager类有3个私有属性:①searchWord,代表来自客户端的搜索词;②indexManager,代表在索引子系统中定义的类IndexManager的一个实例;③analyzer,代表用来解析搜索词的解析器。
search方法首先检查索引文件是否存在,如果存在,则在索引上进行检索;如果不存在,调用类IndexManager提供的方法创建索引,然后进行检索。搜索结果返回后,提取需要的属性并为每个搜索结果生成类SearchResultBean的一个实例,放入一个列表并返回请求管理器。搜索结果包含两个属性:htmlPath和htmlTitle,其中htmlPath代表HTML文件路径,htmlTitle代表HTML文件标题。核心代码如下

3 用户接口
使用search.jsp页面实现用户接口子系统,提供用户界面,使用户可以向 Web 应用程序服务器提交搜索请求,显示搜索结果。
(1)提供一个用户接口,向Web应用程序服务器提交搜索请求。搜索请求发送到名为SearchController类的Servlet。Servlet的名字和具体实现类的对应关系在Web.xml里指定。 即


4 搜索引擎在地震行业中的应用
系统采用Java语言实现,实验从网络中选取100篇与地震相关的网页作为种子url集,并依此选取2 000篇地震相关文件进行测试。搜索引擎查询结果界面见图4。主要采集指标为查找精度、召回率,结果见表1。由实验结果可知,地震专业搜索引擎在采集精度上效果较好。故将基于Heritrix和Lucence的地震专业搜索引擎应用到地震舆情预警系统中是可行的。
图4 舆情监控系统Fig.4 Public opinion monitoring system

表1 结果统计Table 1 Result statistics
5 结束语
将Heritrix和Lucence进行有效结合,构建完整的搜索引擎,通过对源码的修改和
封装,实现以地震为专题搜索引擎的自动运行,用户只需配置相应专题信息即可使用检索功能,无需进行繁琐配置,且不必关心搜索引擎的运行。地震专业搜索引擎的自动运行,易于普通用户使用,提高了易用性,摈弃Heritrix的传统用法,避免了繁琐的配置过程;进行网页过滤,避免爬取大量无用和冗余的网页信息,节省磁盘空间,可在地震行业推广使用。
黄颖,黄治平.HtmlParser提取网页信息的设计与实现[J].江西理工大学学报,2008,28(6):26-28.
罗刚.自己动手写搜索引擎[M].北京:电子工业出版社,2009.
邱哲,符滔滔,王雪松.开发自己的搜索引擎——Lucene+Heritrix[M].北京:人民邮电出版社,2010.
杨颂,欧阳柳波.基于Heritrix的面向电子商务网站增量爬虫研究[J].软件导刊,2010,9(7):38-39.
Design and implementation of the search engine for earthquake based on Heritrix and Lucene
Sun Jing,Li Yalong and Wan Jie
(Earthquake Administration of Anhui Province,Hefei 230031,China)
With the development of the internet technology,it is demanding to have enhanced search engine with great precision.Enterprise search engine is then proposed and advanced for such purpose.We systematically studied the search engine for seismology and implemented an enterprise search solution based on Web-based crawler Heritrix and Lucene which is an open source full-featured text search engine.The key functions in our system include acquiring information,creating image fi les,building indices and searching.
earthquake,Heritrix,Lucene,index,search
10.3969/j.issn.1003-3246.2016.05.030
孙静(1978—),女,安徽合肥人,工程师,2005年毕业于中国科学技术大学软件工程专业,获硕士学位,主要从事网络技术方面的研究工作
安徽省地震局青年基金课题
本文收到日期:2016-03-25
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
成都信息工程大学学报(2021年6期)2021-02-12
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
中国卫生(2015年12期)2015-11-10
新疆大学学报(自然科学版)(中英文)(2014年2期)2014-11-06
科学导报·学术论坛(2013年5期)2013-06-26
