
搭建Hadoop实验平台
2016-11-26 05:19:18
网络安全和信息化 2016年5期
引言:网上有很多介绍如何搭建Hadoop的文章,有的步骤不甚详细,有的按其方法搭建会出现莫名其妙的问题。本文尽量细化步骤、简化配置,并已将容易导致错误的部分提前修改,为初学者学习搭建Hadoop完全分布式集群环境提供方便。
实验材料
1、VMware Workstation;
2、ubuntu14.04.3桌面版64位操作系统
3、jdk8u 65 64位4、hadoop2.7.1
实验过程
用VMware Workstation创建4台ubuntu虚拟机
Windows平台下安装好VMware Workstation虚拟机软件。从ubuntu官方网站www.ubuntu.com下 载ubuntu14.04.3桌面版64位操作系统,通过VMware Workstation创建一台ubuntu虚拟机。用户名 hadoop,口令 hadoop,如图1所示。
安装 jdk和 hadoop,并配置环境变量
1、安装jdk和hadoop:


图1 创建ubuntu虚拟机
图2 安装jdk和ubuntu

图3 测试jdk安装是否成功


2、配置 jdk的环境变量

3、配置hadoop的环境量


如果显示如图4所示,则表示hadoop安装成功。
以该虚拟机为模板,克隆出3台虚拟机
Hadoop集群各节点信息如下:


图4 测试hadoop安装是否成功

图5 hosts文件内容

修改4台ubuntu虚拟机的主机名:sudo vim /etc/hostname,hostname均为hadoop。
修改hosts文件,解析主机名:sudo vim /etc/hosts
hosts文件内容如图5所示。
重启虚拟机后主机名和hosts解析生效。
配置SSH无密钥登录
在4台虚拟机上,安装openssh-server安全连接软件

4台上均生成密钥对:ssh-keygen t rsa,其位于家目录下的隐藏目录~/.ssh


修改 core-site.xml、hdfssite.xml、mapred-site.xml、yarn-site.xml及 slaves,为 4台虚拟机分配不同角色,以组成hadoop完全分布式集群
4个文件位于/usr/soft/hadoop-2.7.1/etc/hadoop/目录下
由于每4台主机的xml文件配置必须相同,所以只需在master主机上修改这4个xml文件,然后远程拷贝到其余3台主机即可。
特别说明:默认的hadoop集群启动临时文件存放在/tmp/目录下,每次重新开机就会被清空,与此同时namenode的格式化信息就会丢失。为避免hadoop集群启动时出现namenode进程丢失故障,需在master主机上建立一个永久的临时文件存放目录:mkdir /home/hadoop/hadoop_tmp。
同时打开所有的xml文件:gedit *-site.xml。
1、core-site.xml用于配置namenode节点,修改后内容为


3、mapred-site.xml需 从mapred-site.xml.template模板复制而来,修改后内容为

4、yarn-site.xml用于配置resourcemanager,本实验中resourcemanager由namenode节点兼任,修改后内容为





将上述4个xml文件从master上copy到其它3个节点,或者直接拷贝hadoop目录,使4台主机的xml文件相同。

另 外,需 在master和slave3节点上配置slaves文件,用于指定集群中的datanode节点是哪几个。slaves文件内容如图6所示。
至此,已完成hadoop集群的所有必需的配置工作。
格式化hdfs文件系统,启动 hadoop集群
格式化hdfs文件系统:hadoop namenode format

图6 slaves文件内容
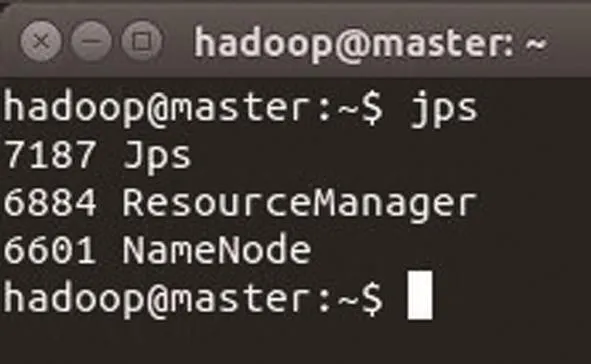
图7 master节点进程信息
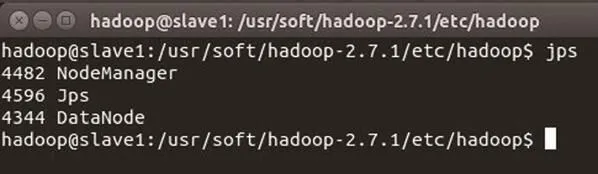
图8 slave1 节点进程信息

图9 slave1 节点进程信息
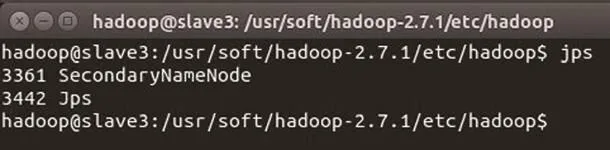
图10 slave3 节点进程信息
提示Storage directory/home/hadoop/hadoop_tmp /dfs/name has been successfully formatted.
表示hdfs格式化成功。
启 动hadoop集 群:start-all.sh
查看各节点的hadoop进程信息,使用命令:jps
master节点进程信息如图7所示。slave1节点进程信息如 图8所示。
slave2节点进程信息如图9所示。
slave3节点进程信息如图10所示。
如果以上显示都正常,则表示hadoop集群启动成功。
测试java程序以验证hadoop是否能进行数据分析
本实验将测试jdk自带的wordcount程序。
先在master节点本地创建测试用例:vim test.txt
文本内容:

在hdfs文件系统下新建 input目 录:hadoop fs-mkdir /input
查看新建目录是否成功:hadoop fs ls /
显示有input目录了
将test.txt从本机上传到hdfs文件系统:hadoop fs put test.txt /input
启动java的wordcount程序


上述语句是一条完整的命令。
启动了mapreduce,统计文本中单词出现的次数,将结果输出至output目录。
查看结果:用浏览器打开 http://master:50070,有 了output目 录,内 有2个文件_SUCCESS和part-r-00000。
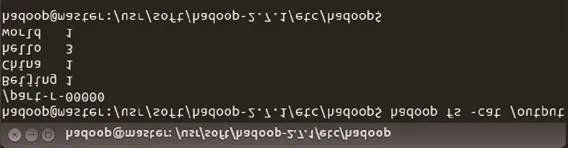
图11 查看wordcount统计结果
查看wordcount统计结果:hadoop fs cat/output/part-r-00000,如果显示结果如图11所示,则表示mapreduce运算正常。
经验总结
Hadoop集群的resource manager、namenode、secondary namenode、datanode、nodemanager等角色搭配比较灵活,也是经常困扰初学者的地方。
几种角色要依赖4个xml文件和slaves来配置,弄清楚这个问题将对进一步学习Hadoop至关重要。
猜你喜欢
中国新闻周刊(2022年2期)2022-01-17 20:37:30
中国外汇(2019年20期)2019-11-25 09:54:58
军事运筹与系统工程(2019年4期)2019-09-11 06:39:58
电子制作(2018年11期)2018-08-04 03:25:40
中国交通信息化(2017年3期)2017-06-08 06:09:28
知识就是力量(2017年2期)2017-01-21 18:29:36
读者·校园版(2016年21期)2016-11-18 17:22:18
诗林(2016年5期)2016-10-25 07:51:39
民主与科学(2014年3期)2014-02-28 11:23:03
教育与职业(2014年7期)2014-01-21 02:35:04
