
电特大天线增益的高效求解
2016-11-25 05:48:11孙旭敏潘小敏盛新庆
北京理工大学学报 2016年7期
孙旭敏,潘小敏,盛新庆
(北京理工大学 信息与电子学院,电磁仿真中心,北京 100081)
电特大天线增益的高效求解
孙旭敏,潘小敏,盛新庆
(北京理工大学 信息与电子学院,电磁仿真中心,北京 100081)
为解决电特大天线辐射特性计算效率低的问题,提出并实现了一种基于多极子的聚集思想快速求解远场信息的高效并行算法. 根据目标在并行多层快速多极子中几何树的特征,提出高层远场模式直接聚集,并且按行并行插值的混合MPI-OpenMP并行计算方案. 将该算法应用于大射电天文望远镜FAST(five-hundred-meter aperture spherical telescope)的远场方向图和增益的计算,通过与等效电流直接积分法计算对比展示其计算精度与效率. 结果验证该算法的远场辐射特性计算精度,且同等远场计算任务量下,平均单方向计算效率提高近万倍.
并行多层快速多极子;MPI并行;OpenMP并行;电特大;增益
随着计算机并行技术的发展,为了满足大目标尤其是电特大目标特性的精确计算对高效算法的要求,基于集群系统的消息传递(message passage interface,MPI)模型的多进程并行技术以及多核处理器的共享内存(OpenMP)多线程并行技术的应用[1-5],并行MLFMA对目标散射特性的计算能力已达到未知数为十亿数量级.
文献[6]中利用并行MLFMA来分析500 m口径射电天文望远镜(five-hundred-meter aperture spherical telescope,FAST)的辐射特性,此天线主瓣电平高波束窄,为了保证其计算精度,该文献的做法是在最大增益附近处dθ=±10°内计算更密的远场信息,这样需要较大远场信息量的耗时计算,而且方向数量的多少直接影响其精度,如此人为的因素就需要考虑,在精度和效率之间需要找到一个平衡点,对于程序的使用者来说这无疑是比较繁琐的.
对于上述问题,文献[7]中已实现其计算目标散射的MPI并行算法的研究,该方法与电流直接积分求解相比,计算电大目标效率提高很客观. 为解决应用目前的MPI-OpenMP并行架构MLFMA计算电特大辐射目标效率低的问题,采用该远场计算方法,其实现过程中平面波聚集方案的选取与实现则直接影响算法的计算精度与效率. 多极子几何树结构最高层(盒子尺寸最大的层)具有特殊性,计算辐射问题时需要重新考虑负载平衡的实现,经分析高层远场模式不同的聚集方案所需的计算资源,包括按分层逐次/单层直接聚集以及改进型的按行/按列并行插值方案,选取最优的MPI并行方案,并重点致力于对OpenMP并行的研究,最终实现高效匹配的MPI-OpenMP并行方案,将其应用于求解电特大辐射问题,在保证所需内存最小化的情况下,实现了对其辐射特性的精确高效计算.
1 基于并行MLFMA高效求解辐射问题
与并行MFLMA计算散射问题相比,应用其计算辐射问题的主要区别就是馈源和计算指标不同. 馈源部分选用简化的电压源模型,该模型采用δ函数源,馈源端口处的RWG边作为激励边来初始化矩阵方程的右端项;在计算天线辐射特性时,以方向性系数近似作为天线轴向增益,其数值计算公式如下:
(1)
(2)
此外,并行MLFMA中应用多极子思想处理远相互作用中,通过各基函数聚集而得的远场模式公式为
(3)
对比上述两式,可知计算天线方向性增益时所需的全向远场模值可通过计算多极子中结合所有基函数贡献的远场模式,通过乘以常数因子可得,来提高计算效率.
2 基于多极子快速求解增益的并行
基于并行MLFMA的多极子思想计算辐射问题,实现重点就是应用多极子的聚集思想,根据等效电流并行求解天线的远场信息. 基于MPI-OpenMP并行架构的远相互作用处理的聚集、转移操作高效所得的第2层远场模式,已包含所有未知数的贡献,因此需适当选择实现高层(第2层到第0层即目标本身)远场模式的聚集方案,并通过适当选取零层截断系数以保证高斯面积分方法所对应的远场模式方向数可满足精度要求. 并对聚集过程所需计算资源进行分析验证以确定最优方案,其中插值系数矩阵的计算资源由父层和子层远场模式数量决定,平移系数由父层与子层盒子空间关系及父层远场模式决定,其实现中涉及的主要问题:高层聚集方式选取——分层逐次聚集与单层直接聚集;聚集过程的MPI并行方案——按盒子并行与按平面波并行;不同MPI并行方案下OpenMP并行实现的负载均衡问题.
目标总体远场模式的计算,可以由第二层远场模式通过分层逐次聚集与单层直接聚集两种方式来实现(图1中2D结构树). 而对于电大辐射问题高层的远场模式数较多,单层聚集在构造插值系数与平移系数及聚集过程中节省大量的计算资源,主要考察其与分层聚集的计算精度. 通过以sph-0242与sph-10(金属球半径电长度分别为2.42,10.00)的散射问题为例,比较两种方案相对于电流直接积分法和解析所得的RCS结果,这两种方案相对于解析解的相对误差基本<5%,而误差较大的方向均由于RCS接近于0 dB,并且直接聚集和电流积分的误差相差不大,而对于其他数值算例以及电大目标的散射计算也验证单层直接聚集方案可以保证计算精度要求,故选取该方案,并在此基础上讨论并行方案的选取与实现.
2.1 基于多极子快速求解增益的MPI并行方案
基于并行MLFMA采用的是高层平均分配平面波,低层平均分配盒子的混合MPI并行方案,由过渡层(iTrsLev)与第2层关系决定高层聚集过程的MPI并行方案. 当iTrsLev<2,高层按盒子并行,除了进程间盒子相互依赖关系外,其插值和平移过程与原盒子并行类似,每层的全部远场模式方向数同样作用于所有进程;当iTrsLev≥2,高层按平面波并行,针对大部分目标尤其是电大目标,其高层远场模式数量较多均为平面波并行,且这些层盒子尺寸大数量少,当以盒子并行时随着线程数增加其效率下降. 并行MLFMA的层间插值系数存储方式,按盒子并行时以父层平面波作为负载,其关于子层平面波的插值系数共享,采用按所有父层平面波即按行存储方式;按平面波并行则以该进程父层平面波作为负载,分别保存其关于所有对其有贡献的所有子层平面波的插值系数,采用按这些子层平面波即按列存储方式,以此方案来节省计算资源. 而高层结构树的特殊性(父层即第0层只有一个盒子,子层即第2层所有盒子均是其子盒子)使得在采用相应并行方案的同时,需要对其聚集过程中计算资源进行估计并改进算法,包括构造相应插值以及平移矩阵的内存及时间,以及聚集过程中循环次序的调整,以实现线程并行的负载均衡及并行效率的提高.
按盒子并行方案的插值系数依旧采用原始按行插值形式,其总平面波方向数较少,聚集后采用归约操作(MPI_Reduce)对完整的远场再进行数据后处理部分;按平面波并行方案是本文重点,由于高层结构树的特殊性以及此时父层远场模式数较多,需要改进其并行聚集方案,其中对于插值系数矩阵、聚集过程以及数据通信部分的并行实现进行探讨及验证.
其中分块插值系数矩阵均为稀疏矩阵,改进型按行插值与按列插值的并行插值系数矩阵选取及存储方案如图2(a)所示,改进的按行方案先以父层所有平面波进行搜索,若对其插值有贡献的子层平面波(数目≤16)有在本地的则进行保存,否则将不保存,则本进程所有被贡献的父层平面波都将被保存,其中包含与之左右相邻进程的部分平面波,以这些局部父层平面波为一维索引,得到对应的子层平面波与插值系数,相对于原按行方案,于父层平面波的局部性以节省内存需求;图2(b)所示,改进的按列方案为减少通信开销,以本地子层平面波为贡献项,即以本进程子层平面波为一维索引,得到其所有有贡献的父层平面波与插值系数. 相对于改进型的插值方案,平移过程均以父层局部平面波作为整体负载,按子层全部盒子进行循环,平移之后按盒子贡献叠加得到局部平面波. 从本质来看,两种插值方式的信息一致,子层都无需进行通信,父层均得到局部平面波信息,不过其相对应的聚集过程中插值方案选取将直接影响并行计算资源,于线程并行中详细讨论.
对于电特大辐射问题,远场模式聚集方法的零层方向由截断系数决定,该方向数很大,区别于散射问题对于远场信息的归约处理,为实现节省计算资源,需要对聚集得到的局部平面波进行通信(MPI_Sendrecv)得到按进程并行的平面波信息,即将局部平面波不属于本进程的部分平面波发送给对应进程,该进程对应叠加接收到的平面波来进行处理. 最终将各进程的远场模式通过数据收集(MPI_Gatherv)操作将主极化和交叉极化的场值均集中于主进程(0号进程),此时得到整个三维空间的全向远场,通过天线增益计算公式即可得增益.
2.2 基于多极子快速求解增益的OpenMP加速技术
高层聚集应用基于共享内存的指导性调度线程并行OpenMP来加快计算,为了充分实现其最佳并行效率,需先确定计算密集区,并保证达到负载均衡的任务量来实现线程同步. 高层聚集包括插值系数矩阵填充、方向向量填充、平面波聚集、远场模式数据处理这四部分,其中平面波聚集最耗时,在数据后处理总时间中占60%多,且其远场方向数足够大可保证并行的任务量,因此对按行与按列两种聚集方案的OpenMP并行实现均进行分析和讨论.
按行插值聚集中,单线程方案中以子层盒子作为循环对象,插值系数以父层平面波作为一维索引,插值过程以父层局部平面波作为整体进行. 线程并行化的实现,首先需要确定负载任务的并行分配:由于父层为单盒子,子层盒子间为独立计算,子层盒子数(3D最大为64)数目有限,而且根据插值系数的特征,父层平面波可作为独立计算负载,此时需要调整循环次序,以父层局部平面波为一阶循环来进行负载匹配,子层盒子为二阶循环,再应用已独立保存的平面波方向和盒子位置信息来进行平移操作. 因此应用按行插值聚集方案通过循环次序的调整不仅可按最大任务量实现最佳并行,而且减少了平移的计算时间.
按列插值聚集中,区别在于其插值系数的一维索引是子层平面波,故无法通过循环次序的变换将父层平面波负载作为线程匹配对象,因此考虑到线程并行共享内存的模式与子层盒子的独立性,只能仍以子层盒子数作为并行的循环对象,且需要对将写入的父层局部平面波分配与线程数一致的内存空间,独立存储,聚集完成后再以各线程结果求和来实现子层贡献的叠加,该方案由于并行对象有限以及求和计算增加,并行效率明显随着线程数增加而下降,且对内存的要求增大.
由于父层平面波数目较大,为了节省内存,采用了原远相互作用中的内存循环技术,若结构体中远场模式除目前子层平面波后内存足够则无需另开内存,而按列插值聚集并行过程中该内存需求与线程数成正比,无法保证在提高并行计算效率的同时不提高内存的消耗. 因此基于并行效率和内存需求的多方面分析,最优的并行方案为结合MPI-OpenMP并行技术的改进型按行插值聚集方案.
3 算例的数值分析
计算飞机散射问题来测试其远场计算的线程并行效率,电尺寸为240λ,未知数为450万,根据节点资源,线程数从2~12变化,其高层按平面波并行时线程并行效率如图3,当线程到达12时,并行效率仍高于83%,该并行策略较成功实现了并行加速.
计算反射面天线FAST-300(反射面光滑,口径为300 m)的辐射特性,与电流直接积分法计算结果比较来验证本文并行算法的精度和效率. 该反射面天线于焦点以天文台提供的阶梯喇叭作为馈源,分析频率为300 MHz,天线电尺寸为300λ,结构树层数为10层,平均剖分尺寸为0.13λ,总未知数为1 737万,用64个进程6个线程并行计算,E-plane远场方向图结果如图4,计算增益为58.19 dBi,与电流直接积分法和商业软件FEKO(PO法)所得的58.28 dBi和58.22 dBi相比,其误差均小于1‰,辐射特性结果吻合较好.
其中两种方法所需的计算资源如表1,快速的远场聚集方案在远场计算中应用了远场模式的内存循环技术,不过保存高层插值与平移系数需要额外的内存,其中电流直接积分法为保证最大辐射方向的精度,仍计算两次远场信息,表中统计一次计算时间,方向选取(θ,φ)步进为1°,快速远场计算中方向以高斯取点决定,其平均远场计算时间提高约为1.6万倍,总时间亦如预期提高,因此若计算结构更复杂或精度要求更高的辐射问题时,同等计算任务量下该算法更具优势.
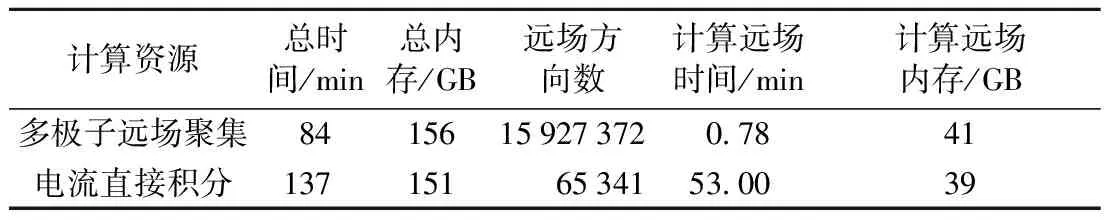
表1 FAST-300天线计算资源
4 结 论
为实现应用并行MLFMA高效准确地计算电特大辐射问题,采用了快速的多极子远场聚集求解方案. 基于并行结构树的高层特殊性,对于高层不同聚集方案的资源需求进行分析,并通过算例验证,确定以改进型按行插值的单层直接聚集作为最优方案,为进一步提高计算效率,于计算密集区通过循环次序调整结合线程并行,并应用了内存循环技术来节省额外内存.
通过计算理想金属目标的散射问题,验证其远场聚集的线程并行效率,在线程数为12时依然高达83%的并行效率;以电特大反射面天线FAST的计算,验证了其对于多方向远场需求计算的高效性,与电流直接积分法相比,辐射特性精度和效率均得到显著提高,数据后处理部分将同等计算任务量条件下,效率提高近万倍.
[1] Song J M,Chew W C. Multilevel fast-multipole algorithm for solving combined field integral equations of electromagnetic scattering [J].Microwave and Optical Technology Letter,1995,10(1):14-19.
[2] 潘小敏,盛新庆.一种多层快速多极子的高效并行方案[J].电子学报,2007,35(3):567-571.
Pan Xiaomin,Sheng Xinqing. A highly efficient parallel approach of multi-level fast multipole algorithm[J]. Acta Electronica Sinica,2007,35(3):567-571. (in Chinese)
[3] 潘小敏,盛新庆. 一种高性能并行多层快速多极子算法[J].电子学报,2010,38(3):580-584.
Pan Xiaomin,Sheng Xinqing. A high-performance parallel multi-level fast multipole algorithm[J]. Acta Electronica Sinica,2010,38(3):580-584. (in Chinese)
[4] 潘小敏,皮维超,盛新庆.基于共享内存的高效OpenMP并行多层快速多极子算法[J].北京理工大学学报,2012,32(2):164-169.
Pan Xiaomin,Pi Weichao,Sheng Xinqing. Efficient parallelization of multi-level fast multipole algorithm based on OpenMP[J]. Transactions of Beijing Institute of Technology,2012,32(2):164-169. (in Chinese)
[5] Pan Xiaomin,Pi Weichao,Yang Minglin,et al. Solving problems with over one billion unknowns by the MLFMA[J]. IEEE Transactions on Antennas and Propagation,2012,60(5):2571-2574.
[6] 段猛,李斌,盛新庆,等.基于并行多层快速多极子的大射电天文望远镜FAST的计算[C]∥2011年全国天线年会.南京:[s.n.],2011:666-669.
Duan Meng,Li Bin,Sheng Xinqing,et al. The computation of large spherical radio telescope FAST antenna based on the parallel MLFMA[C]∥Proceedings of The 2011 National Conference on Antennas. Nanjing: [s.n.], 2011:666-669. (in Chinese)
[7] Velamparambil S,Chew W C,Song J. 10 million unknowns: is it that big?[J]. IEEE Antennas and Propagation Magazine,2003,45(2):43-58.
(责任编辑:刘芳)
Efficient Solution for Extremely Electric Large Antenna Gain
SUN Xu-min,PAN Xiao-min,SHENG Xin-qing
(Center for Electromagnetic Simulation,School of Information and Electronics,Beijing Institute of Technology,Beijing 100081,China)
An efficient parallel algorithm to accelerate the calculation of the far-fields was proposed and implemented for solving the electric large antenna radiation problem,based on the upward pass or the aggregation phase of the parallel multilevel fast multipole algorithm(MLFMA). According to the geometry tree structure of the parallel MLFMA,an efficient hybrid MPI-OpenMP parallelization algorithm was designed with the direct aggregation of coarser level far-field radiation pattern and parallel in-row interpolation. The computation of far-field radiation pattern and antenna gain of the extremely large parabolic reflector of FAST by this algorithm shows the accuracy and efficiency of the parallel program,compared with the computation by the equivalent current direct integration method. The numerical results demonstrate that the presented approach has good accuracy for the radiation characteristics,and the computational efficiency has improved about ten thousand times for single direction under same far-field calculation task compared to the equivalent current direct integration method.
parallel multi-level fast multi-pole algorithm (parallel MLFMA);MPI parallel;OpenMP parallel;extremely electric large;gain
2014-03-17
国家“九七三”计划项目(2012CB720702)
孙旭敏(1989—),女,博士生,E-mail: sunxm1989@foxmail.com.
盛新庆(1968—),男,教授,博士生导师,E-mail: xsheng@bit.edu.cn.
O 441.4
A
1001-0645(2016)07-0718-05
10.15918/j.tbit1001-0645.2016.07.011
猜你喜欢
数学物理学报(2021年3期)2021-07-19 06:02:26
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09 08:43:02
机械制造与自动化(2018年4期)2018-08-21 06:59:00
电子制作(2016年11期)2016-11-07 08:43:45
电子设计工程(2015年22期)2015-08-10 10:30:48
中国舰船研究(2015年2期)2015-02-10 06:45:47
中国煤层气(2014年3期)2014-08-07 03:07:39
机械管理开发(2013年3期)2013-12-13 04:05:40
中国工程咨询(2013年3期)2013-02-13 02:50:24
科技资讯(2012年19期)2012-04-29 08:23:50
