
恶意URL多层过滤检测模型策略研究
2016-11-18 07:55郑运鹏
信息安全研究 2016年1期
刘 健 赵 刚 郑运鹏
(北京信息科技大学信息管理学院信息安全系 北京 100192) (liujianspace999126@126.com)
恶意URL多层过滤检测模型策略研究
刘 健 赵 刚 郑运鹏
(北京信息科技大学信息管理学院信息安全系 北京 100192) (liujianspace999126@126.com)
恶意URL检测始终是Web安全领域的研究热点.提出了恶意URL多级检测过滤模型,共分成4层过滤器:黑白名单过滤器、朴素贝叶斯过滤器、CART决策树过滤器和支持向量机过滤器.对多层过滤模型的几个关键策略进行了讨论,包括过滤器层的投票策略、过滤器顺序策略以及过滤阈值的调优策略.过滤器投票策略中讨论了单独投票、并行投票和加权并行投票3种投票方法,过滤器顺序策略讨论了4种过滤器的先后顺序,过滤器阈值策略讨论了过滤阈值的确定方法.通过实验验证了多层过滤检测模型中以上策略讨论结果的有效性,根据实验结果实现了Web应用.
恶意URL;投票策略;机器学习;分类算法;多层过滤模型
恶意网站[1]通常在用户浏览网站时引导用户将恶意程序安装到用户电脑,而用户对此没有察觉,甚至恶意软件在被发现之前可能已经盗走用户一些重要资料.国内外对恶意网址检测的最初研究方法是基于URL黑白名单的检测技术,其主要思想是检索黑白名单是否保存了所检测的URL地址来判定该URL是否指向恶意网站.其中黑名单存储被确定为恶意网站的URL地址,白名单存储被确定为合法网站的URL地址.目前大多数浏览器具有黑名单相关插件,如 Microsoft IE,Google Safe Browser等.Ludl等人[2]先后收集了3周内共10 000条恶意网站的URL 地址,用这些URL分别测试了IE浏览器以及谷歌安全浏览器的检测正确率,分析表明这些插件能够检测约90%的恶意URL.Sheng等人[3]测试了8种常用钓鱼防御工具中黑名单更新及识别的速度,结果表明只有不到20% 的防御工具能够在较短的时间内识别出钓鱼网站的URL.目前除黑白名单技术外,机器学习分类算法[4-9]是一种比较主流的恶意网址检测技术,国内外将机器学习分类算法应用到恶意网址检测技术的研究非常多.
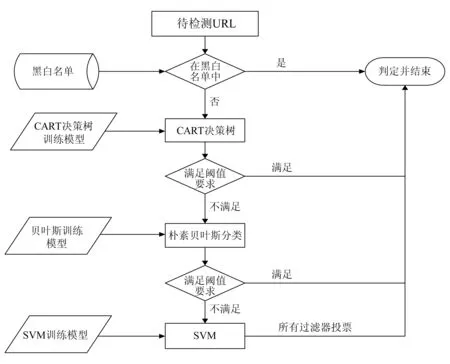
图1 多层过滤模型流程图
恶意URL的检测至关重要,而目前对恶意URL的检测方法虽多,但是表现却不尽如人意.恶意网站URL的检测是一种典型的分类场景,分为“恶意URL”和“正常URL”2个类.机器学习中的分类算法[10-12]是实现其分类的一种优秀工具,但是分类器各有千秋,单独使用一种分类器往往不能达到全能的效果.因此,本文在目前机器学习检测恶意网址相关研究的基础上,提出一种将若干种分类器串行起来的恶意网址多层过滤检测模型,着重研究多过滤器中单独投票、并行投票和加权并行投票等共同判定URL的投票策略.在深入分析投票策略特点的基础上,确定了加权投票策略及相应的调优策略,利用相关参数的控制,将几种分类器的优势都发挥出来,更加有效地实现恶意网址检测.
1 多层过滤模型概述
本文提出的多层过滤模型流程我们称之为BW-NCS,如图1所示.
依据多层过滤模型,进一步设计功能应用流程:用户在Web页面中输入要检测的URL,服务器经过匹配和计算返回该URL的判定结果,如图2所示.
图2中BW-NCS模型对URL的处理方法如下:
步骤1. 判断该URL是否在黑白名单中,如果在直接返回判定结果给用户;否则,执行下一步;
步骤2. 提取该URL特征向量;
步骤3. 将特征向量代入朴素贝叶斯过滤器,如果达到阈值,直接返回判定结果给用户;否则记录判定结果,执行下一步;
步骤4. 将特征向量代入CART决策树过滤器中,如果达到阈值,直接返回判定结果给用户;否则记录判定结果,执行下一步;
步骤5. 将特征向量代入SVM过滤器中,记录判定结果后和上层2个过滤器判定结果共同投票,并返回判定结果给用户.

图2 URL多层过滤检测模型应用流程图
2 投票策略研究
如果待检测URL在BW-NCS模型的前3层没有被判定,则说明该URL既不在黑白名单中,也不是朴素贝叶斯和CART树的擅长数据.很可能是因为该URL的特征向量没有明显的类型偏向,属于恶意URL和正常URL的概率相差不大.这种URL需要在最后一层进行判定.本文着重讨论单独投票、并行投票和加权并行投票3种投票策略.因为黑白名单过滤器已经没有判定的能力,所以以下投票策略不考虑黑白名单过滤器.
2.1 单独投票
单独投票策略是指当URL过滤到最后一层时,只有SVM过滤器进行投票,即SVM过滤器对URL的判定结果即作为最终的判定结果.选取这种投票策略的原因主要有以下2点:
1) 待判定URL既然已经过滤到SVM层,说明该URL不是朴素贝叶斯过滤器和CART决策树过滤器的擅长数据,这2个过滤器的分类结果不可信;
2) SVM过滤器并没有设定擅长阈值,所以该URL有可能是SVM过滤器的擅长数据,尤其是单独的SVM分类器要比其他2类单独分类器的分类效果好的情况下.
单独投票策略是对SVM过滤器充分信任的一种投票策略.
2.2 并行投票
并行投票策略是指当URL过滤到最后一层时,由朴素贝叶斯、CART决策树和SVM 3种过滤器一起投票,每个过滤器投一票,根据投票结果判定URL类别.例如,当待检测URL过滤到最后一层时,朴素贝叶斯、CART决策树和SVM 3种过滤器分别将它判定成恶意URL、恶意URL和正常URL,即有2票投给了恶意URL、1票投给了正常URL.这样对该URL的最终判定结果为恶意URL.选取这种投票策略的原因主要有以下2点:
1) 待判定URL既不是朴素贝叶斯过滤器擅长的数据,也不是CART决策树过滤器擅长的数据,说明该URL的特征向量没有明显的趋向哪个类,则SVM过滤器也有很大概率不擅长处理该URL,3种过滤器综合决定能够更好地分担风险;
2) 当单独的SVM分类器要比其他2种单独分类器的分类效果都要差时,要更加信任前2种过滤器.
并行投票策略是对SVM过滤器不太信任的一种投票策略.
2.3 加权并行投票
加权并行投票策略是指当URL过滤到最后一层时,和并行投票策略一样,由朴素贝叶斯、CART决策树和SVM 3种过滤器共同投票,但每个过滤器都投加权票,根据投票结果判定URL类别.各层过滤器的投票值计算方法如下:
1) 在朴素贝叶斯过滤器层中,αnbayes=max{P1P2,P2P1},阈值为,令朴素贝叶斯的加权投票值为αnbayes,因为该URL已经过滤到最后一层,说明αnbayes肯定没有达到阈值,该投票值小于1;
2) 在CART决策树过滤器层中,αcart=max{nm,mn},阈值为,令CART决策树的加权投票值为αcart,同样因为该URL已经过滤到最后一层,说明αcart没有达到阈值,该投票值也小于1;
3) SVM过滤器的投票值为1.
例如,当待检测URL过滤到最后一层时,朴素贝叶斯、CART决策树和SVM 3种过滤器分别将它判定成恶意URL、恶意URL和正常URL,而αnbayes=0.6,αcart=0.35,因为将URL判定恶意URL的加权投票值为0.95,小于将URL判定成正常URL的加权投票值1,所以该URL会被判定为正常URL.
选取这种投票策略的原因主要有以下2点:
1) 既然待判定URL既不是朴素贝叶斯过滤器擅长的数据,也不是CART决策树过滤器擅长的数据,还不确定SVM的判定效果如何,那么朴素贝叶斯和CART决策树这2个过滤器就不能和SVM过滤器拥有一样的投票权重;
2) 朴素贝叶斯过滤器和CART决策树过滤器的阈值也只是训练出来的一个界限,而这个界限往往是模糊的,可能有些URL在过滤器中计算出的α已经接近这个阈值α*,但是仍然被过滤到下一层,这显然不合理.所以用αα*作为这2个过滤器的加权投票值.
加权并行投票策略是一种介于单独投票策略和并行投票策略中间的一种平衡策略,在给SVM过滤器一定投票优势的同时也不完全依赖SVM过滤器.
3 过滤器顺序策略
本文提出的URL多层过滤检测模型的过滤器顺序为:黑白名单过滤器,朴素贝叶斯过滤器,CART决策树过滤器和SVM过滤器.过滤器中黑白名单过滤器具有绝对权威,待检测URL如果能被它判定,这个判定结果是被绝对信任的,也就不需要别的过滤器再去进行判定,所以将它放到第1层.SVM过滤器没有擅长阈值的计算方法,没办法设定过滤条件,所以将它作为最后一层过滤器.而朴素贝叶斯和CART决策树既不是绝对权威,也都有相似的擅长阈值计算方法,所以这2种过滤器是可以互换位置的.下面讨论这2种顺序策略.
我们称朴素贝叶斯在上一层的策略为NBAYES-CART策略,CART决策树在上一层的策略称作CART-NBAYE策略.无论哪种策略,目标都是为了整个多层过滤检测模型更准确地判定URL.这2层作为中间层能够以尽可能高的准确率去处理尽可能多的URL,能够帮助多层过滤检测模型实现更好的URL判定效果.所以这里提出应用2个标准:一个是判定URL的数量,另一个是判定URL的准确率.
对于本文收集的URL数据集的检测,在下述实验中验证了单独的CART决策树分类器效果要比单独的朴素贝叶斯分类器效果好得多,因为这2个过滤器的准确率是可以通过阈值来调节的,也就是说在保证同样的准确率的情况下,CART决策树过滤器能够直接判定的URL数目要比朴素贝叶斯过滤器多很多.在多层过滤检测模型中,一般是越高层级的判定准确率要越高,所以如果选择CART-NBAYES策略,在CART决策树过滤器层为了保证准确率可能只处理小部分URL,这些URL可能判定准确率很高,但是过滤到朴素贝叶斯过滤器层的那些URL的判定准确率就会偏低;如果选择NBAYES-CART策略,在朴素贝叶斯过滤器层也能以较高准确率处理小部分URL,过滤到CART决策树过滤器层的URL也能以不错的准确率被判定.因此,本文选取了NBAYES-CART策略,并且本文的模型为BW-NCS模型.
4 过滤阈值的调优策略
BW-NCS模型中共有2个过滤阈值:朴素贝叶斯过滤器的过滤阈值和CART决策树的过滤阈值.这2个过滤阈值是BW-NCS模型中最重要的参数之一,它们的选取好坏直接影响模型的判定效果.这2个阈值的选取依赖于数据本身特点,并且没有可以参考的相关的专家经验.本文直接搜索多种阈值对组合,并用另一组样本进行测试,最后选取效果最好的阈值对.本文在对BW-NCS多层过滤器模型的过滤阈值主要调优步骤如下:

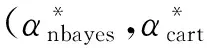
5 实验分析与应用
5.1 实验结果与分析
本文的恶意URL数据集通过恶意网站实验室获取,正常URL数据集通过爬虫程序从第1分类目录网爬取.从恶意URL数据集和正常URL数据集各取10 000条数据作为本文的实验数据.
本文作如下假设:有10%的URL在黑白名单过滤器中,并且这10%的URL是随机选取的,对于不在这10%范围内的URL,单独的黑白名单分类器会进行随机判断.
实验结果如表1所示:
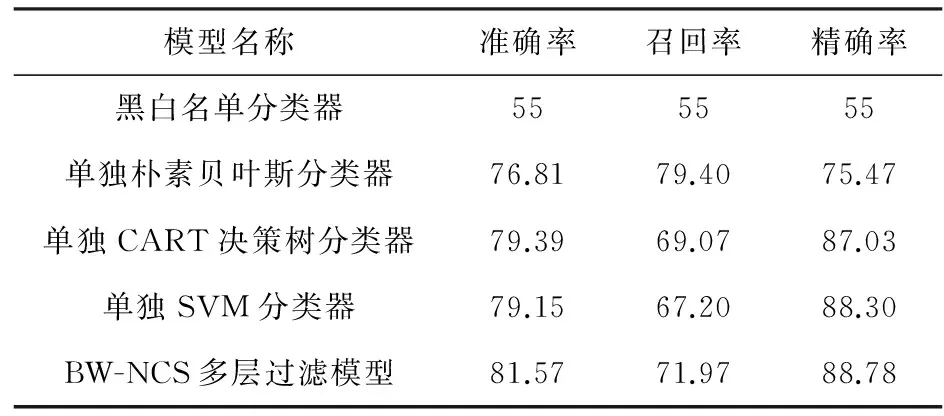
表1 实验测试结果 %
从表1中可以看出完整的BW-NCS模型表现优秀,明显地超过4个单独分类器模型表现,这也达到了本文的研究目的,使得多层过滤模型能够处理各个分类器自己擅长的数据,充分发挥了每一层分类器的优势,最终达到提高检测恶意URL准确率的效果.具体来说,在BW-NCS模型中黑白名单过滤器判定在黑白名单之内的URL,朴素贝叶斯过滤器判定了那些计算出的2类概率差比较悬殊的URL,CART决策树过滤器判定了那些计算出的叶子节点中2类数目比较悬殊的URL,SVM可以在拥有比较大投票权重的情况下和前2层过滤器共同投票判定前2层都不擅长的URL.而其他单独模型必须处理所有URL,不管是否为自己的擅长数据,所以才出现表1的结果.
5.2 实验结果应用
本文设计并实现了BW-NCS模型的Web应用,并在应用中将实验测试结果作为证据支持.其中的判定结果的内容包括:
1) 该URL是恶意URL还是正常URL;
2) 该结果是由哪一层过滤器对它进行判定的;
3) 这次判定的准确率、召回率和精确率.
这些内容既给出URL判定结果,又详细地给出了判定的相关参数.用户在了解判定结果的同时,可以根据参数来指导自己是否相信这次判定.如一个用户对安全性要求很高,而这次的返回结果虽然判定用户输入的URL是正常URL,但是这次判定的准确率比较低,那么该用户就可能选择不再访问这个URL,本文称这种用户为谨慎型用户;相反,如果一个用户想浏览更多的网页并对安全性要求较低,那么即使返回结果是恶意URL但是这次判定的准确率较低,该用户也很有可能会继续访问,本文称这种用户为包容型用户.
根据以上应用需求,在设计应用时需要提前做的工作有:黑白名单的收集和存储;BW-NCS模型的建立和存储;模型测试实验结果的记录和存储.这些准备工作中,黑白名单和BW-NCS模型是为了方便Web应用直接调用,加快效率.而模型测试实验结果的记录是为了给用户更多的参数:准确率、召回率和精确率.
在SVM过滤器层被判定的URL检测场景如图3所示.
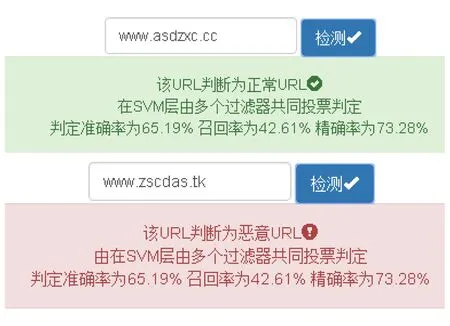
图3 SVM过滤器判定的URL截图
其中,网址www.asdzxc.cc在SVM过滤器层中被判定成正常URL,而网址www.zscdas.tk在SVM过滤器层中被判定成恶意URL,所以在返回的指标中,准确率、召回率和精确率分别为65.19%,42.61%和73.28%,这3个指标的值同样是依据上文实验结果得出的.召回率为42.61%,说明仍有57.39%的恶意URL被判定成正常URL,那么谨慎型用户会不信任网址www.asdzxc.cc是正常URL,包容型用户可能会信任这次判定.准确率为73.28%,说明被判定成恶意的URL有26.72%的概率是正常URL,谨慎型用户应该信任www.zscdas.tk是恶意URL的判定结果,而包容型用户在比较信任这个URL的情况下会认为这次判定有误,相信该URL为正常URL.
6 结 论
本文在提出URL多层过滤模型的基础上,讨论了多层过滤模型中关键策略的主要原理,重点分析了在SVM层中多个过滤器共同判定URL的投票策略,包括单独投票策略、并行投票策略和加权并行投票策略,以及各投票策略的出发点和特点,进一步讨论了过滤器顺序策略.在深入分析的基础上,确定了加权投票策略和从CART决策树到朴素贝叶斯的策略顺序,进一步讨论CART决策树和朴素贝叶斯过滤阈值的调优策略,并用一对衰减函数来生成2个候选阈值集,通过交叉这2个阈值集来测试,选取最优状态下的阈值对作为模型的过滤阈值.通过实验验证了URL多层过滤检测模型的有效性.
[1]何公道, 王江民. 我国恶意网站现状及防治对策研究[J]. 中国人民公安大学学报:自然科学版, 2008, 14(3): 1-4
[2]Ludl C, Mcallister S, Kirda E, et al. On the effectiveness of techniques to detect phishing sites[C] //Proc of the 4th Int Conf on Detection of Intrusions and Malware, and Vulnerability Assessment. Berlin: Springer, 2007: 20-39
[3]Sheng S, Wardman B, Warner G, et al. An empirical analysis of phishing blacklists[C] //Proc of the 6th Conf on Email & Anti-spam. 2009: 59-78
[4]Witten I H, Frank E, Hall M A. Data Mining: Practical Machine Learning Tools and Techniques[M]. San Francisco: Morgan Kaufmann Publishers, 2005: 95-97
[5]郭亚宁, 冯莎莎. 机器学习理论研究[J]. 中国科技信息, 2010 (14): 208-209[6]何清, 李宁, 罗文娟,等. 大数据下的机器学习算法综述[J]. 模式识别与人工智能, 2013, 27(4): 327-336
[7]王珏, 石纯一. 机器学习研究[J]. 广西师范大学学报: 自然科学版, 2004, 21(2): 1-15
[8]李运. 机器学习算法在数据挖掘中的应用[D]. 北京: 北京邮电大学, 2015
[9]米哈尔斯基. 机器学习与数据挖掘[M]. 北京: 电子工业出版社, 2004
[10]罗可, 林睦纲, 郗东妹. 数据挖掘中分类算法综述[J]. 计算机工程, 2005, 31(1): 3-5, 11
[11]刘刚. 数据挖掘技术与分类算法研究[D]. 郑州: 中国人民解放军信息工程大学, 2004
[12]谈恒贵, 王文杰, 李游华. 数据挖掘分类算法综述[J]. 微型机与应用, 2005, 24(2): 4-6

刘 健
硕士研究生,主要研究方向为机器学习与信息安全.
liujianspace999126@126.com

赵 刚
副教授,博士,主要研究方向为人工智能与信息安全.
zhaogang@bistu.edu.cn

郑运鹏
硕士研究生,主要研究方向为大数据与物流规划.
zhengpeng911001@126.com
Research on Strategy of Malicious URL Multi-Layer Filtering Detection Model
Liu Jian, Zhao Gang, and Zheng Yunpeng
(InformationSecurityFaculty&SchoolofInformationManagement&BeijingInformationScienceandTechnologyUniversity,Beijing100192)
Malicious URL detection is always a hot research topic in the field of Web security. This paper proposes a malicious URL multi-level filtering detection model. This model contains 4 layers of filter: black and white list filter, Naive Bayesian filter, CART decision tree filter and Support Vector Machine filter. In this paper several key strategies of multilayer filtering model are discussed, including support vector machine filter layer voting strategy; filter order strategy and filtering threshold tuning strategy. Filter voting strategies are discussed in separate voting, parallel voting and weighted parallel voting three voting methods. The filter order strategy discusses the order of the four filters. Filter threshold strategy discusses the method of determining the threshold of the filter. The validity of the above methods is verified by experiments. According to the experimental results, this paper implements a Web application.
malicious URL; voting strategy; machine learning; classification algorithm; multi layer filtering model
2015-12-30
国家自然科学基金项目(61272513);北京市科委重大项目子课题(D151100004215003)
赵刚(zhaogang@bistu.edu.cn)
TP309
猜你喜欢
小资CHIC!ELEGANCE(2021年36期)2021-10-15
法律方法(2021年4期)2021-03-16
四川文学(2020年11期)2020-02-06
当代陕西(2019年23期)2020-01-06
成都信息工程大学学报(2019年3期)2019-09-25
当代陕西(2019年9期)2019-05-20
电子制作(2018年16期)2018-09-26
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
铁道通信信号(2016年6期)2016-06-01
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
