
基于Java的多线程快速排序设计与优化
2016-11-09 02:30:46黄志波孙少乙
网络安全与数据管理 2016年16期
黄志波,赵 晴,孙少乙
(华北计算机系统工程研究所,北京 100083)
基于Java的多线程快速排序设计与优化
黄志波,赵晴,孙少乙
(华北计算机系统工程研究所,北京 100083)
为实现多线程快速排序,提出基于Fork/Join框架的多线程快速排序,同时对排序算法进行优化。该算法主要用于大量数据需要进行排序处理的应用。
Fork/Join;多线程;快速排序;算法优化
引用格式:黄志波,赵晴,孙少乙. 基于Java的多线程快速排序设计与优化[J].微型机与应用,2016,35(16):23-25,28.
0 引言
排序一直是程序开发中的一个重点,尤其在一些应用开发中经常用到,在搜索开发中也是重点研究对象。所以人们对排序的研究一直坚持不懈。在众多排序算法中,快速排序是一个表现极其优秀的算法。该算法于1962年由Tony Hoare首次提出[1],它基于分治思想,使得排序性能得到极大的提升[2]。如今的电脑或者手机一般都是多核处理器,为了提高用户体验,应该充分利用其所拥有的硬件设备。本文主要讲述多线程下快速排序的设计与优化过程,对普通快速排序[3]、基于多线程的快速排序以及基于Fork/Join的多线程排序进行了比较。
1 单线程快速排序
快速排序是基于比较的一种排序算法,而基于比较的排序算法的最佳性能为O(nlgn)。快速排序的运行时间与数据划分是否对称有关,且与选择了哪一个元素作为划分基准有关[4]。在信息论里面,N个未排序的数字,共有N!种排法,但是只有一种是想要的(譬如递增或者递减)。也就是说,排序问题的可能性有N!种,而任何基于比较的排序基本操作单元都是“比较a和b”,而这个比较一般是有两个结果,这样恰好可将剩下来的排序减少为N!/2种。因此当选定某个位置的元素作为pivot(基准)时,若能恰好将原序列平均分为两个子序列,那么递归的次数将会显著地减少,从而排序的效率将有所提高。因此均衡地分割序列一直是一个重点研究方向,如随机选取基准、三数选中等策略。此外还有两种情况是研究排序算法时必须考虑的[5],第一种情况就是当序列中大部分数据甚至全部数据相等,也就是大量数据重复时;第二种情况是当序列中大部分数据甚至整个序列已经是有序的[6]。这两种情况都会使得快速排序的性能变得最坏,也就是O(n2)。针对第一种情况研究者们已经提出了三分序列的解决方案;第二种情况就是如何恰当地选取比较基准,固定地选取首部或者尾部元素作为基准显然不是最佳的,人们提出了随机选取元素与三数选中两种方法加以改进。本文中分别采用随机选取元素和以尾端数据作为基准来实现的算法,目的是使算法设计更简练,其次是为了使单线程与多线程在核心算法上保持一致性。由于快速排序算法核心算法是一致的,故只在本节展开描述,接下来的章节中就不赘述了。
快速排序伪代码[6]如下。
QuickSort(a, l, r)
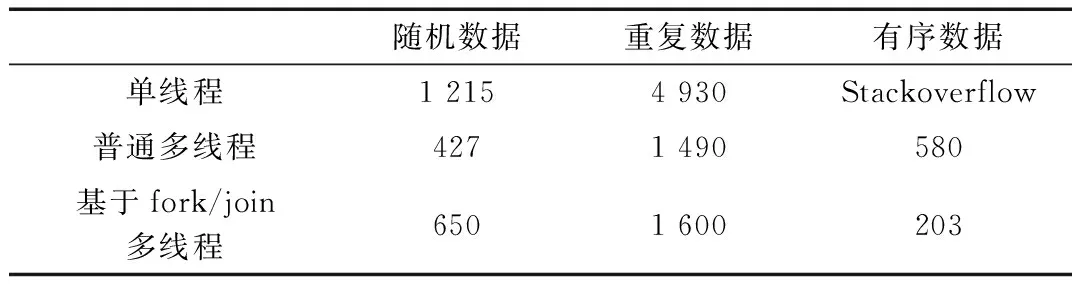
if l QuickSort(a, l, k-1) QuickSort(a, k+1, r) 其中Partition函数是核心函数,在测试时根据测试数据类型的不同采用相应的最优实现算法。 针对有序数据Partition函数代码设计如下: int index =new Random().nextInt(right -left)+left; swap(arr[left] , arr[index]); long pivot = arr[left]; while (left < right) { while (left < right && arr[right] >= pivot) right--; if (left < right) arr[left++] = arr[right]; while (left < right && arr[left] <= pivot) left++; if (left < right) arr[right--]= arr[left]; } arr[left] = pivot; return left; 针对随机数据和重复数据Partition函数设计如下: long x = arr[right]; int i = left - 1; for (int j = left; j < right; j++) { if (arr[j] <= x) { i++; swap(arr, i, j);}} swap(arr, i + 1, right); return i + 1; 为了防止因为数字比较大,超出int类型最大值,均用long类型,该类型基本上完全适用于实际应用当中。 由于快速排序是采用分治策略,并且基准左右序列的递归排序是互不影响的,因此完全可以考虑采用多线程来做并行处理,每次基于基准产生左右分块序列的时候,可以分别用一条线程来执行左右序列的排序工作,这样能在充分利用计算机性能的条件下,使排序算法表现更优,从而增大排序速度。一种实现是将需要排序的数组分成多组,然后对每组实现一个线程来快速排序,最后用归并排序算法的思想合并这些数组,最终实现原序列的排序过程。这种实现方式在合并时需要额外时间,并且还需要额外的空间进行交换。因为快速排序是内排序,因此各自子序列排好序后,原序列就已经是排好序的了。在多线程里面进行排序,线程的建立以及切换调用才是需要考虑的问题[7-8]。因为电脑资源毕竟有限,不能无限地创建线程。在Java中主要是用runnable和callable接口来实现多线程,区别在于是否有返回值。而快速排序是内排序,可以不用返回值,这样可以使得程序更加清晰明了。故此,通过实现runnable接口来创建线程。为了能最大化测试机器的性能,采用线程池来管理线程。 线程之间切换也是极为耗时间的,因此常常需要根据当前机器的处理器数目来创建线程数。获取测试机器的cpu数目: private static final int N=Runtime.getRuntime().availableProcessors(); 执行排序线程的线程池: private static Executor pool= Executors. newFixedThreadPool(N); 为了防止竞争条件的产生,队列中的线程是有顺序的,必须是某些线程执行完后等待在队列中的剩余线程才能继续进行,这也是结合算法来设计的。由此可以看到此方案存在不足之处,即线程之间存在锁,而锁会极大地影响多线程的性能。 下面是排序时首先调用的方法,参数count记录当前正在执行的线程数,因为在Java中++i和i++(--操作同理)操作不是线程安全的,在使用的时候需要加synchronized关键字。这里采用AtomicInteger线程安全接口来实现加减操作。 public static void sortFunction(long[] arr) { final AtomicInteger count = new AtomicInteger(1); pool.execute(new QuicksortRunnable(input,0,arr.length-1, count)); try {synchronized (count) { count.wait();} } catch (InterruptedException e) { e.printStackTrace();}} 实现runnable接口时,必须重写run方法。 @Override public void run() { quicksort(left, right); synchronized (count) { if (count.getAndDecrement() == 1) count.notify();}} 这是真正进行排序的方法,当队列中还有尚未执行的任务时,就继续递归调用该方法。 private void quicksort(int pLeft, int pRight) { if (pLeft < pRight) { int storeIndex=partition(pLeft, pRight); if(count.get()>=FALLBACK*N{ quicksort(pLeft, storeIndex - 1); quicksort(storeIndex+1, pRight);} else {count.getAndAdd(2); pool.execute(new QuicksortRunnable( values,pLeft,storeIndex-1, count)); pool.execute(new QuicksortRunnable( values,storeIndex+1,pRight, count)); }}} 当创建的线程到一个特定的阈值时,即执行回滚,继续递归地创建线程,以避免恒定的上下文切换的开销。 Fork/Join框架是Java7提供的一个用于并行执行任务的框架,即把大任务分割成若干个小任务,最终汇总每个小任务的结果后得到之前大任务的结果。其中Fork用来做分割任务操作,而Join则是将分割后的小任务执行结果进行合并的操作。该框架之所以能在多线程编程表现优异,是因为它基于一个叫作Work-stealing的核心算法。该算法是指线程从其他线程队列里获取任务来执行。也就是说当需要做一个比较大的任务时,可以把这个任务分割为若干互不依赖的子任务。为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,这样就实现了线程和队列一一对应。比如某线程T负责处理T队列里的任务,但是有的线程先执行完了自己队列里的任务,而其他线程对应的队列里还有任务在等待处理。与其让已经执行完队列中任务的线程等着,不如让它去帮其他线程执行任务,于是它就去其他线程的队列里窃取一个任务来执行。但是这当中其实也存在一个问题,就是当它与被窃取任务的线程同时访问同一个队列时,仍会有窃取任务线程与被窃取任务线程之间的竞争,为了减少这种现象的出现,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。 Work-stealing算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时,并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。 Fork/Join框架工作步骤如下: (1)分割任务。首先需要有一个fork类来把大任务分割成子任务,当子任务还是很大时,就需要不停地分割,直到分割出的子任务足够小[9]。在算法实现时以数据量大小为依据来分割任务。 (2)执行任务并合并结果。被分割的子任务分别放在双端队列里,启动后的线程分别从双端队列里获取任务执行。在同一个进程中的线程可以共享数据,各子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。但是在快速排序时,因为它是内排序,所以可以不用进行最后的数据合并过程,实际上,原序列排序后就是所要的结果。如此一来,只要专注于分割任务和排序就行了。 当创建一个ForkJoin任务时,通常情况下不需要直接继承ForkJoinTask类,而只需要继承它的子类,Fork/Join框架提供了两个子类:RecursiveAction:没有返回结果的任务;RecursiveTask:有返回结果的任务。 因为不需要任务有返回结果,因此采用子类RecursiveAction。ForkJoinTask需要通过ForkJoinPool来执行,主任务被分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当某个工作线程的队列里暂时没有任务可执行时,它就会随机地从其他工作线程所维护的队列的尾部获取一个任务。 需要设定子任务分割限制条件,即数据量的大小,这里将其设定为286,因为这个数字是快速排序最佳实现的阈值,可以参考JDK源码。 private int THRESHOLD = 286; ForkJoinTask需要实现compute方法,在该方法中首先需要判断当前任务是否足够小,如果足够小就直接执行任务,即调用排序方法排序,否则就需要分割成两个子任务,通过invokeAll方法将两个子任务分别进行fork,被fork后的子任务会再次调用compute方法,检查当前子任务是否需要继续分割成孙任务,倘若不需要继续分割,则执行当前子任务。compute方法代码如下: protected void compute() { if (hi - lo < THRESHOLD) sequentiallySort(array,lo, hi); else { int pivot = partition(array, lo, hi); FastSort left=new FastSort(array, lo, pivot-1); FastSort right=new FastSort( array,pivot+1, hi); invokeAll(left, right);}} 为了更直观以及更全面地进行比较,测试时生成了三组数据,均为1 000万个,但分别为随机的生成不同数字,大量重复数字以及有序数字。同时为了使测试顺利进行,算法会稍作调整。当数据为随机数据和重复数据时,partition方法以尾端数字作为基准排序;当数据为有序数据时,采用随机获取基准来进行排序。此外由于数据量比较大,故保存在txt文本文档里。排序完成后写到新建文档里,可便于检查排序是否正确以及是否完整。本测试只比较排序时间。因为文档的读写不是本文讨论的问题,所以就不展开叙述了。测试机器为MacBook Pro841,CPU数目为4,运行内存为16 GB。测试过程中为了使结果更具有一般性,采用多次测试取平均值。测试数据如表1所示。 表1 测试数据比较 (ms) 上表数据显示,对于随机数据,由于数据分布均匀,多线程显然比单线程排序更快速。同时对于重复数据,由于数据中有大量重复数字,因此递归次数显著地增加了,也就是数据交换次数也增加了,排序所需时间也成倍递增了,但是因为数据中存在大量重复数字,因此有些数字交换显然是多余的[10]。因为普通多线程排序的线程是由线程池控制的,而Fork/Join多线程设计是由数据量进行线程控制,所以相比较来看普通多线程排序表现更加出色。对于有序数据,因为数据本身是有序的,采用单线程排序时,递归次数大幅增加而导致堆栈溢出。多线程排序时,Fork/Join多线程明显优异于普通多线程,这跟什么时候进行真正排序相关,普通排序过早地进行排序因而比较次数以及交换次数要多于Fork/Join多线程排序。综上所述,在设计多线程排序时,建议基于Fork/Join框架思想来实现。 本文总结了单线程下快速排序不断优化的历程,并设计了多线程下排序的优化方法。从实验测试结果看出,随着时代的进步,机器不断更替,重新思考以前一些算法问题时有了另一层面的思维方式,往往在新的思维方式下会取得不一样的成就[11]。排序问题一直是研究的热点,而快速又更是备受关注[12]。此外关于多线程还有一种处理方案就是基于actor模型的多线程框架,这也是一种多线程处理策略。在实验中也尝试过,不过并未取得理想效果,因此就不展开叙述了,若读者有兴趣,可以试着去实现并优化算法。 [1] CORMEN T H, LEISERSON C E, RIVEST R L, et al.算法导论原书(第二版)[M].北京:高等教育出版社,2006. [2] HOARE C A R. Quicksort[J]. The Computer Journal, 1962(5):10-15. [3] 胡云.几种快速排序算法实现的比较[J].安庆师范学院学报,2008,14(3):100-103. [4] 霍红卫,许进.快速排序算法研究[J].微电子学与计算机,2002(6):6-9. [5] 汤亚玲,秦锋.高效快速排序算法研究[J].计算机工程,2011,37(6):77-78,87. [6] 石壬息,张锦雄,王钧,等.快速排序异步并行算法的多线程实现[J].广西科学院学报,2005,18(1):53-54,64. [7] 周玉林,郑建秀.快速排序的改进算法[J].上饶师范学院学报,2001,21(6):12-15. [8] 邵顺增.稳定快速排序算法研究[J].计算机应用与软件,2014,31(7):263-266. [9] 宋鸿陟,傅熠,张丽霞,等.分割方式的多线程快速排序算法[J].计算机应用,2010,30(9):2374-2378. [10] 潘思.充分利用局部有序的快速排序[J].计算机研究与发展,1986,23(9):51-56. [11] 梁佳.一种改进的堆排序算法[J].微型机与应用,2015,34(6):10-12. [12] 张旭,王春明,刘洪,等. 基于双向链表排序的系统误差稳健配准方法[J].电子技术应用,2015,41(9):74-77,81. The design and optimization for multi-thread quicksort based on Java Huang Zhibo,Zhao Qing,Sun Shaoyi (National Computer System Engineering Research Institute of China, Beijing 100083, China) In order to implement multithreaded quicksort,we propose a quicksort algorithm which is based on Fork/Join framework, and try to optimize the quicksort algorithm.This algorithm mostly is used for large amounts of data required for sorting process. Fork/Join; multi-thread; quicksort; algorithm optimization TP31 A 10.19358/j.issn.1674- 7720.2016.16.006 2016-03-29) 黄志波(1992-),通信作者,男,在读研究生,主要研究方向:分布计算与并行处理。E-mail:bobo492295520@163.com。 赵晴(1964-),男,本科,高级工程师,主要研究方向:信息的获取与处理。 孙少乙(1990-),男,在读研究生,主要研究方向:智能制造与应用。2 多线程快速排序
3 基于Fork/Join框架多线程快速排序
4 测试
5 结论
猜你喜欢
小学生学习指导(低年级)(2020年4期)2020-06-02 09:09:26
软件(2020年3期)2020-04-20 00:58:44
军营文化天地(2018年2期)2018-12-15 17:39:08
产品可靠性报告(2017年7期)2017-09-05 09:49:12
环球市场(2017年36期)2017-03-09 15:48:21
山东工业技术(2016年15期)2016-12-01 05:31:19
核科学与工程(2015年2期)2015-09-26 11:57:14
湖州师范学院学报(2015年4期)2015-03-11 16:39:43
电源技术(2014年9期)2014-02-27 09:03:40
吉林建筑大学学报(2012年3期)2012-08-15 00:54:52
