
云计算环境下的学习资源个性化推荐技术研究
2016-11-08 12:29张颖
现代电子技术 2016年19期
张颖
(长春职业技术学院 基础部,吉林 长春 130033)
云计算环境下的学习资源个性化推荐技术研究
张颖
(长春职业技术学院 基础部,吉林 长春130033)
针对学习资源的个性化推荐,提出了一种基于用户影响关系的协同过滤推荐方法,使用传统协同过滤推荐采用的用户项目评分信息,通过挖掘用户时序交互评论和回复行为数据发现用户之间的相互影响关系,从而优化用户兴趣矩阵,在此基础上改善基于用户的协同过滤方法进行推荐。在数据集上的实验结果表明,通过利用用户之间时序交互行为数据,挖掘隐藏的用户影响关系信息可以有效提高预测的准确度。
个性化推荐;协同过滤;学习资源推荐;用户影响关系;教育推荐
个性化推荐技术早已在电子商务、电影、音乐等领域得到了广泛应用,如今随着网络在线教育的发展,个性化推荐技术也逐渐引起了教育领域的重视及应用的需求。面对复杂多样的网络学习资源,根据用户的历史行为轨迹,分析用户兴趣,推荐能够反映用户学习兴趣的学习资源,实现“因材施教”变得越来越重要,研究学者们也纷纷开始探索个性化推荐技术在教育领域的应用[1]。面对着当前网络上的学习资源的特点是形式多样化,资源类型多媒体化,资源组织异构化,且变得海量的学习资源,网络教育的发展也使得个性化学习成为当今世界网络教育领域的发展趋势,那么个性化地给用户推荐学习资源也变得更加重要,具有应用价值和科研意义[2]。
1 基于用户影响关系的推荐方法概述
目前,获取用户关系的方式主要分为显示和隐式两类,显示的社交网络关系和隐式的标签信息往往在学习系统中是不一定都具备的,但是普遍都存在用户对资源的评论及回复的信息,而并没有研究者去挖掘这些数据中是否有有助于对用户进行个性化资源推荐的信息,这些信息是否能提炼出有助于用户个性化推荐的信息[3]。
本文基于该假设提出了基于用户影响关系的协同过滤推荐方法(简称CCR-UCF),该推荐方法通过挖掘用户评论和回复的时序行为数据信息,获得其中潜在的用户影响关系,然后借助该影响关系改善基于用户的协同过滤推荐算法。提出的CCR-UCF方法主要包括四个步骤:获取用户时序交互信息——评论和回复;挖掘用户之间的影响关系;重构用户兴趣矩阵;将新用户兴趣矩阵应用于User-basedCF推荐算法进行Top-N推荐。
2 具体步骤分析
2.1获取用户时序交互信息
在一般的推荐系统中,用户会浏览资源,进行评分,标注是否喜欢,在某些资源下留言评论。例如,用户A在看了某个资源后将其标注为喜欢或者在资源下面进行留言评论,用户B在用户A之后较短时间内也标注喜欢该资源或者留言评论。如果这种情况多次出现的话,那么很可能A对B存在潜在的影响关系,而且这种关系是双向不对称的,也就是说A对B的影响很大,但A受B的影响相对很小。如果A对B的影响较大,那么就可以将用户A感兴趣的资源推荐给B。在这里,用影响值Inf来表示这种影响关系的大小。
通过挖掘用户的时序评论和回复行为数据得到用户的影响关系[4]。先假设从这种时序行为数据中挖掘出的用户影响关系,依据得到的用户影响关系填充稀疏的用户项目兴趣矩阵,以期望提高推荐的准确率和召回率,之后将TED数据集上的实验对该假设进行论证[5]。对数据集进行预处理时,统计的是用户与用户之间的时序评论和回复次数。统计用户i在用户j评论之后对相同资源也进行评论的总次数,用Ci->j表示,统计用户i回复用户j的总次数,用Ri->j表示,用户集合为U,i∈U,j∈U。下一步使用Ci->j和Ri->j进行影响关系的挖掘。
2.2挖掘用户之间的影响关系
用户之间的影响关系用影响值Inf表示,影响包括评论和回复两方面[6]。InfC(i,j)表示用户i受到用户j在评论方面的影响值,InfR(i,j)表示用户i受到用户 j在回复方面的影响值,i∈U,j∈U,两者的计算如式(1)和式(2)所示:
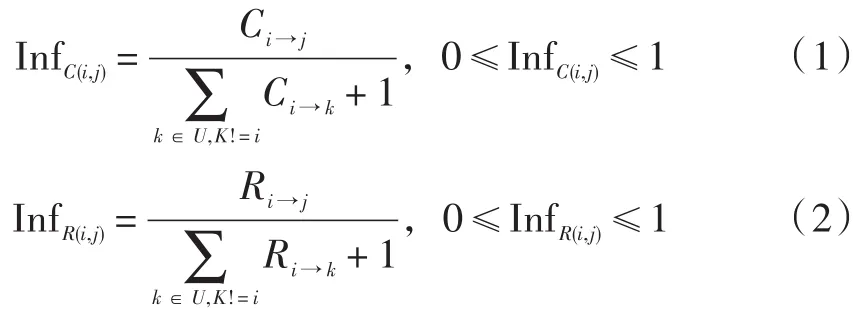
式中:用户i受到用户j在评论方面的影响是用户i在用户j评论之后进行评论的总次数占用户i评论过的总次数的百分比;同样地,用户i受到用户j在回复方面的影响是用户i回复用户j的总次数占用户i回复的总次数的百分比。
得到的InfC(i,j)和InfR(i,j)两部分构成了用户i受到用户j的影响大小,用Inf(ui,uj)表示,其计算方法如下:
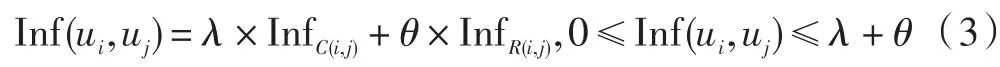
式中:参数λ和θ是分别调整评论影响和回复影响权重的参数值。用户影响关系用矩阵Inf(U)表示,横坐标为受影响用户,纵坐标为影响用户,U是数据中的所有用户集合,影响值由式(3)计算而得[7],如表1所示。由于用户之间的影响关系不是对等关系,所以用户影响关系矩阵Inf(U)是非对称矩阵。

表1 用户影响关系矩阵
此用户影响关系矩阵反映了用户两两之间存在的影响关系的大小。
2.3重构用户兴趣矩阵
在一些在线教育系统中,有的资源用户可以对其进行评分,如0~5,而有的学习系统中,只是提供给用户标注“喜欢”的功能[5]。由于在本实验的数据集中,仅有用户是否喜欢某个资源的数据,因此,在对用户兴趣矩阵的初始化时,将用户标注喜欢的资源的兴趣值为1,用户未标注喜欢的默认值为0。假设现有n个用户,资源数为m个。最初的用户项目兴趣矩阵是仅有0和1两个值的矩阵M(u,i)n×m。
将从上节得到的用户影响关系矩阵Inf(U)n*n考虑进最初的用户项目兴趣矩阵M(u,i)n×m之后,得到一个新兴趣矩阵M′(u,i)n×n,该矩阵是考虑用户影响关系后得到的新的用户项目兴趣矩阵。该矩阵将作为下一步基于用户协同过滤算法的输入。
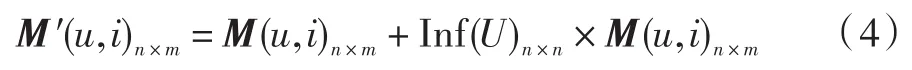
2.4结合User-based CF推荐
在该部分将新得到的用户项目兴趣度矩阵作为Userbased CF(基于用户的协同过滤)推荐算法的输入[8]。本文方法在原有的非评分数据的基础上,通过加入挖掘用户时序行为得到用户影响关系,从而得到一个基于用户影响关系的用户-项目兴趣矩阵。
用户-项目兴趣矩阵集合基于用户协同过滤推荐算法,其步骤如下:
(1)获取用户相似度:用余弦相似度计算方法计算两两用户之间的相似度,得到用户相似度关系:
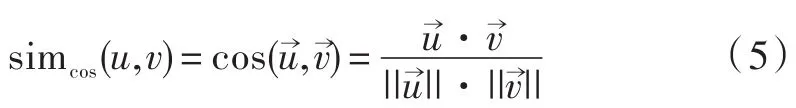
(2)寻找K个最近邻:选取与目标用户最相似的K个其他用户。该步骤选取最近邻是选取相似度最大的K个用户邻居。
(3)获取用户-项目兴趣值:如果目标用户u对项目i之前没有兴趣值,那么通过K个近邻的历史数据来计算目标用户对项目的兴趣值,公式如下:
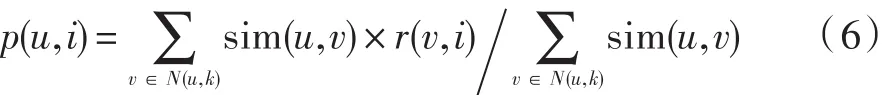
式中:N(u,K)代表用户u的K个最近邻居用户集合;sim(u,v)表示用户u和用户v之间的用户相似度;r(v,i)表示用户v对项目i的兴趣值。
(4)推荐排序靠前的N个项目:选取偏好值排序前N个,将用户未浏览过或评价的项目推荐给目标用户。至此,推荐结束。数据稀疏性是目前推荐系统面临的主要挑战之一,往往大量的用户只有少量的观测数据。
3 实验设计
3.1实验数据
相比于推荐系统在电子商务、电影、视频等领域的数据集,如MovieLens和Netflix等,在网络教育领域,因为学习系统的多样性,很少有开放的数据集。选取TED网站7的用户数据及TedTalks数据,并且开放给研究者用于研究网络教育领域的资源推荐。使用2014年9月10日的数据集,该数据集包括12 605个用户,1 203个talks资源。数据集主要分为两部分:一部分是TEDUsers,是用户行为数据,favorites是用户标注喜欢的TEDtalks的ID;另一部分是TEDTalks,是TED演讲视频的详细信息,其中comments部分有用户评论的时间、内容以及回复。
3.2实验设置
提出方法的实验通过在TED数据集上验证。选取数据集中至少对12个学习资源做过评价的所有用户,包括3 107个用户对1 203个学习资源的103 612个评价,同时有这些用户的112 571条评论,617条相互的回复。在该数据集中的评价是被标注为favorite,也就是说只有正反馈而没有具体评分。本文使用到的数据统计说明见表2。

表2 实验所用数据集的数据统计
数据的稀疏性为97%,有效数据仅有3%。
实验时将整个数据集随机地分为5份,分别是test1. txt,test2.txt,test3.txt,test4.txt和test5.txt,每次实验使用其中4份作为训练集,另外1份作为测试集。推荐算法使用训练数据生成推荐结果,用测试集验证推荐效果,实验共进行5次交叉验证。
为了评价本文推荐算法的有效性,将使用准确率和召回率评测指标对推荐算法的准确度进行评价,并与User-based CF推荐算法和Item-based CF(基于项目的协同过滤)推荐效果进行对比。
3.3参数分析
针对提出的CCR-UCF算法,首先通过实验分析参数λ和θ不同设置对推荐效果的影响。评测标准包括准确率和召回率两方面,图1和图2分别展示了参数λ和θ对准确率和召回率的影响。
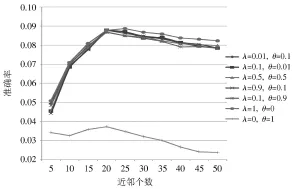
图1 参数λ和θ对推荐结果准确率的影响
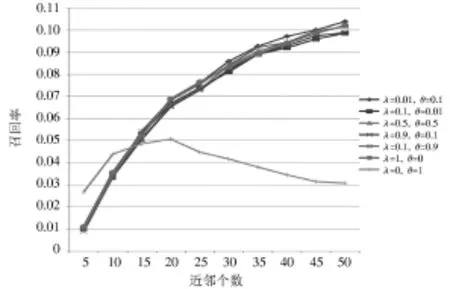
图2 参数λ和θ对推荐结果召回率的影响
实验中,近邻个数从10调整到50,步长为5。比较两个图在λ=0,θ=1时,可知准确率和召回率的效果都是最差的,也许这与该数据集中replies的数量仅有617个有关,在不计comments数据的前提下,构建用户影响关系的效果并不明显,从而推荐的准确度也并没有得到明显的提高。而当 λ=0.01,θ=0.1;λ=0.1,θ=0.01;λ=0.5,θ=0.5;λ=0.9,θ=0.1;λ=0.1,θ=0.9;λ=1,θ=0时,推荐的准确率和召回率效果差别均不明显,准确率在近邻个数为20时达到最大值。综合比较λ=0.01,θ=0.1时推荐效果最好,因此本文在部分的算法比较实验中参数设置λ=0.01,θ=0.1。
4 实验结果及分析
在Top-N推荐中,通常推荐列表的项目个数不超过20个,这也是符合实际应用场景的。实验在TED数据集上进行,将从推荐的准确率和召回率两方面对三种算法的推荐效果进行分析、比较。本文将分析两方面的影响:一方面是近邻个数对推荐效果的影响;另一方面是推荐个数的变化对推荐效果的影响。
4.1近邻个数的影响
在协同过滤推荐算法中,近邻个数的设定会对推荐效果产生影响。在实验近邻个数对推荐效果影响时,近邻个数从10调整到50,步长为5,在该部分实验时设置推荐项目的个数为5。
准确率和召回率的变化如图3和图4所示。从图中可以看出,在TED数据集中,User-based CF推荐算法和Item-based CF推荐算法两个相比,在准确率方面,Itembased CF推荐算法效果要稍微好于User-based CF推荐算法。而本文提出的基于用户影响关系的CCR-UCF在准确率和召回率方面是Item-based CF的5倍以上。Userbased CF推荐算法和CCR-UCF推荐方法在近邻数为20时都达到最高值,且都随着近邻个数的递增而减小。而Item-based CF推荐算法随近邻个数的变化不明显。

图3 Top-5推荐的准确率随近邻个数的变化
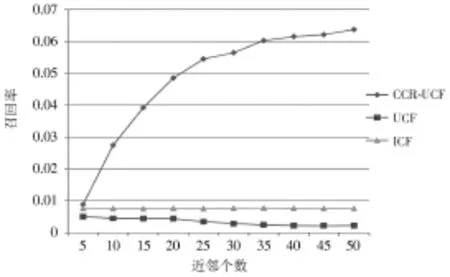
图4 Top-5推荐的召回率随近邻个数的变化
实验在召回率方面,随着近邻个数的增加,Itembased CF推荐算法的变化不大,而User-based CF推荐算法的准确率有所下降,本文提出的CCR-UCF方法随近邻个数的增加而递增,在近邻个数大于25后增速放缓。CCR-UCF方法很明显地提高了召回率。
4.2推荐个数的影响
在实验推荐个数对推荐效果影响时,Top-N推荐个数从1~10,步长为1,设置近邻个数为20。综合近邻个数对准确率和召回率的影响,在比较推荐个数的影响时,设置近邻个数为20。图5和图6是在TED数据集上三个算法的准确率和召回率随着推荐个数的增加的变化曲线。在准确率方面,随着推荐个数的增加,Userbased CF推荐算法的准确率在0.005附近,Item-based CF推荐算法在0.008附近,CCR-UCF推荐方法在0.09附近,提升了10倍以上。召回率方面,随着推荐个数的增加,CCR-UC的召回率效果远高于其他两种算法。
综合两方面的比较,CCR-UCF推荐方法在准确率方面远远好于两个基线算法User-based CF推荐算法和Item-based CF推荐算法。有效地证明了挖掘用户时序交互行为数据得到的用户影响关系能够在准确率方面有效地帮助提高推荐的效果。
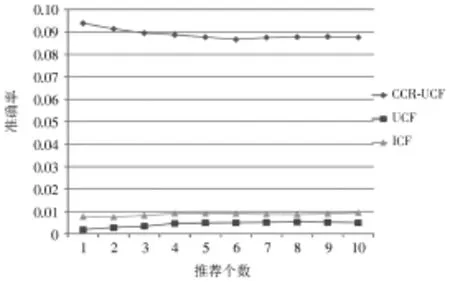
图5 准确率随推荐个数的变化
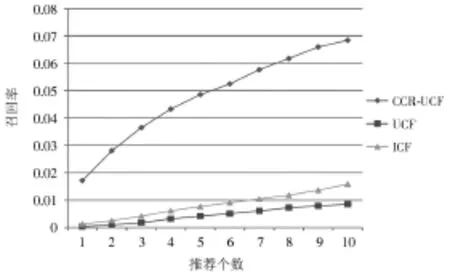
图6 召回率随推荐个数的变化
5 结 论
针对学习资源个性化推荐,提出基于用户影响关系的协同过滤推荐方法。该方法不需要用户标签、社交关系等复杂信息,借助用户间的影响关系改善传统的基于用户的过滤推荐算法,从而提高推荐效果。通过在TED数据集上的实验结果表明,本文提出的基于用户影响关系的学习资源个性化推荐方法与基于用户的协同过滤推荐和基于项目的协同过滤推荐相比,在准确率和召回率方面都得到了明显提高,验证了本文提出方法的有效性。
[1]PAPPAS N,POPESCU-BELIS A.Combining content with user preferences for TED lecture recommendation[C]//Proceedings of 2013 11th International Workshop on Content-Based Multimedia Indexing.Veszprem:IEEE,2013:47-52.
[2]赵向宇.Top-N协同过滤推荐技术研究[D].北京:北京理工大学,2014.
[3]刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[4]陈孝文.基于社交网络的协同过滤推荐算法研究[D].广州:华南理工大学,2013.
[5]KOREN Y.Collaborative filtering with temporal dynamics[C]// Proceedings of 2009 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York:ACM,2009:447-456.
[6]孙光福,吴乐,刘淇,等.基于时序行为的协同过滤推荐算法[J].软件学报,2013(11):2721-2733.
[7]文学志,马佳琳,李方军,等.SCORM学习资源搜索算法设计[J].沈阳师范大学学报(自然科学版),2006(2):181-184.
[8]VESIN B,IVANOVIĆ M,KLAŠNJA-MILIĆEVIĆ A,et al. Protus 2.0:ontology-based semantic recommendation in programming tutoring system[J].Expert systems with applications,2012,39(15):12229-12246.
Research on learning resources personalized recommendation technology in cloud computing environment
ZHANG Ying
(Basic Teaching Department,Changchun Vocational Institute of Technology,Changchun 130033,China)
A collaborative filtering recommendation method based on user influence relation is proposed in allusion to the personalized recommendation of learning resources.The user project grading information adopted by the traditional collaborative filtering recommendation is used to find out the interaction relation among the users by mining the users′time sequence interactive comments and recovery behavior data,so as to optimize the user′s interest matrix.On this basis,the collaborative filtering method based on users was improved for recommendation.The experimental results of dataset show that the hidden user influence relation mined with the time sequence interactive behavior data among users can improve the accuracy of prediction.
personalized recommendation;collaborative filtering;learning resource recommendation;user influence relation;learning recommendation
TN911-34;TM417
A
1004-373X(2016)19-0029-04
10.16652/j.issn.1004-373x.2016.19.007
2015-12-03
张颖(1982—),女,吉林长春人,讲师。从事计算机应用技术、电子信息技术专业领域的教学研究,以及现代高等职业教育的理论研究工作。
猜你喜欢
小学生学习指导(低年级)(2021年9期)2021-10-14
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中学生数理化·七年级数学人教版(2019年10期)2019-11-25
小学生学习指导(低年级)(2019年9期)2019-09-25
小学生学习指导(低年级)(2018年9期)2018-09-26
中国交通信息化(2018年5期)2018-08-21
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
