
基于Spark平台的热点话题发现算法并行化研究
2016-11-07 18:06王新星
软件导刊 2016年9期
王新星


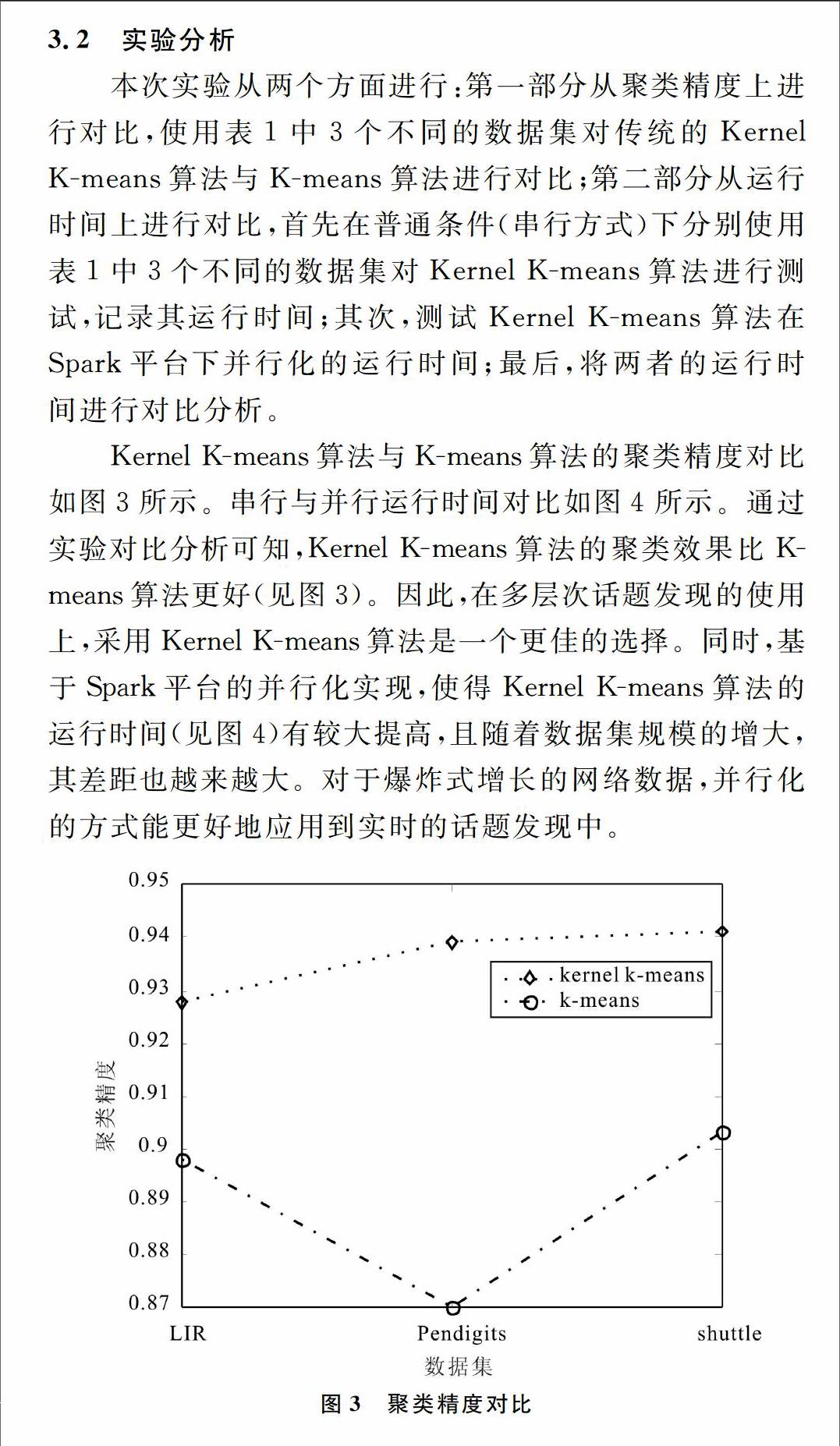
摘要:话题发现中最常用的方法是基于增量式的SinglePass聚类算法,但是其依赖于文档的输入顺序且效率低下。针对这两个问题,提出在多层次话题发现基础上,基于Spark平台的算法并行化,将传统的Kernel Kmeans算法进行并行化处理,以并行化的方式对数据进行初步聚类,并对后续数据进行增量式聚类。实验表明,多层次处理提高了话题的准确性;同时,并行化方式相比传统的话题发现方法,其效率有较大提高。
关键词:话题发现;SinglePass;Spark平台;Kernel Kmeans算法
DOIDOI:10.11907/rjdk.161712
中图分类号:TP312
文献标识码:A文章编号文
章编号:16727800(2016)009005104
基金项目基金项目:
作者简介作者简介:王新星(1991-),男,陕西渭南人,西安工程大学计算机科学学院硕士研究生,研究方向为大数据、云计算。
0引言
随着各种网络社交媒体的普及,网络平台已成为人们了解社会动态、掌握社会热点新闻的主要渠道,话题发现(Topic Detection,TD)成为当前研究的热点。卡内基梅隆大学采用经典的SinglePass算法识别新闻中的事件[1],但是其过于依赖新闻报道的输入顺序。Forestiero等[2]提出了一种基于MultiAgent思想的SinglePass聚类,使用分散的自底向上和自组织策略对相似的数据点进行分类。贾自艳等[3]提出了一种基于动态进化模型的新闻事件话题发现算法,应用基于时间距离的相似度计算模型自动对新闻资料进行组织,生成新闻专题。税仪冬等[4] 针对增量式聚类初始时话题模型不够充分和准确的问题,提出周期分类和SinglePass相结合的话题识别与跟踪方法,提高了话题的精度。格桑多吉等[5]结合网络事件的时间距离,提出了改进的SinglePass算法,提高了文档的相似度计算能力。
然而,上述研究都是通过算法自身来提高数据的处理能力与话题的聚类精度,并没有考虑话题发现的效率。面对网络信息的爆炸式增长,对于大规模且需要实时更新的数据处理,传统方式已经显得力不从心。因此,结合大数据处理平台将会是后续发展的必然趋势。
目前,在处理海量数据方面,Hadoop是一个应用比较广的大数据处理平台,基于Hadoop中的MapReduce并行化计算模型,可以高效地对海量数据进行挖掘处理。其中,Kmeans算法在Hadoop中的并行化已经成为研究的热点[68]。然而,Hadoop也存在一些不足,它需要不断操作磁盘文件系统,将中间运行结果写回文件系统,这样在面对需要不断迭代的操作过程时,其效率和性能会受到严重影响。为此,Apache开发了一种基于内存的快速处理框架Spark[9],其能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce算法,使得在交互式数据分析和数据挖掘工作负载中表现得更加优秀。因此,本文提出基于大数据处理平台Spark的话题发现,以并行化的方式提高数据处理效率。
4结语
本文在结合多层次话题发现的基础上,采用基于Kernel函数的Kmeans算法,借助Kernel函数在高维特征空间的转换,提高了话题发现的精确度;同时实现了KernelKmeans算法在Spark平台上的并行化,借助大数据处理平台,改变了传统话题发现算法的运行方式,从而解决了传统方式对于大规模数据处理效率低下的问题,使得计算效率得到极大提高。实验证明,其聚类结果更加准确,且计算效率相比传统方式有很大提高。
参考文献参考文献:
[1]BAEZAYATES R,RIBEIRONETO B.Modern information retrieval[M].Boston:Addison Wesley,2000.
[2]FORESTIERO A,PIZZUTI C,SPEZZANO G.A single pass algorithm for clustering evolving data streams based on swarm intelligence[J].Data Mining & Knowledge Discovery,2013,26(1):126.
[3]贾自艳,何清,张海俊,等.一种基于动态进化模型的事件探测和追踪算法[J].计算机研究与发展,2004,41(7):12731280.
[4]税仪冬,瞿有利,黄厚宽.周期分类和SinglePass聚类相结合的话题识别与跟踪方法[J].北京交通大学学报:自然科学版, 2009,33(5):8589.
[5]格桑多吉,乔少杰,韩楠,等.基于SinglePass的网络舆情热点发现算法[J].电子科技大学学报,2015(4):599604.
[6]周婷,张君瑛,罗成.基于Hadoop的Kmeans聚类算法的实现[J].计算机技术与发展,2013,23(7):1821.
[7]赵卫中,马慧芳,傅燕翔,等.基于云计算平台Hadoop的并行Kmeans聚类算法设计研究[J].计算机科学,2011,38(10):166168.
[8]江小平,李成华,向文,等.Kmeans聚类算法的MapReduce并行化实现[J].华中科技大学学报:自然科学版,2011,39(S1):120124.
[9]ZAHARIA M,CHOWDHURY M,FRANKLIN M J,et al.Spark:cluster computing with working sets[J].Book of Extremes,2010,15(1): 17651773.
[10]GIROLAMI MARK.Mercer kernelbased clustering in feature space[J].IEEE Transactions on Neural Networks,2002,13(3):780784.
责任编辑(责任编辑:孙娟)
