
基于改进的SVM方法的异常检测研究
2016-11-07 09:44:20张辉刘成
网络与信息安全学报 2016年8期
张辉,刘成
(1. 新疆公安厅特别侦察队,新疆 乌鲁木齐 830000;2. 国家计算机网络应急技术处理协调中心,北京 100029)
基于改进的SVM方法的异常检测研究
张辉1,刘成2
(1. 新疆公安厅特别侦察队,新疆 乌鲁木齐 830000;2. 国家计算机网络应急技术处理协调中心,北京 100029)
利用非参数检验的方法提取出对分类结果影响显著的特征变量,提出一种改进的SVM多分类方法(D-SVM),其融合了判别分析,可以解决样本不均衡导致的分类不准确和误报率高的问题。将多分类问题处理成一个个二分类问题,D-SVM既可以保持SVM较好的分类准确性,同时又可以不受样本不均衡的影响,具有较低的误报率。将D-SVM应用到KDD99数据集,结果表明,该方法具有较高的分类准确性和较低的误报率。
异常检测;非参数检验;SVM分类;样本不均衡;判别分析
1 引言
计算机技术和互联网的发展极大地促进了网络与企业、个人生活的融合。据中国互联网信息中心《第37次中国互联网络发展状况统计报告》显示,截至2015年12月,全国使用计算机办公的企业比例为95.2%,涉及供应链、营销、财务和人力资源等方面;与此同时,网络购物和网络社交等已成为人们生活必不可少的一部分。随着“互联网+”的逐渐深入,网络的作用会更加突出,网络安全问题也将会变得十分严峻,并成为制约网络发展的因素。入侵检测在网络安全中有重要的作用,它可以实时地监测、阻止来自网络外部和内部的入侵,保护网络免受攻击,造成损失。入侵检测方法可以分为2类[1]:误用检测(misuse detection)和异常检测(anomaly detection)。误用检测只能检测已知的攻击,而异常检测却可以检测新的、未知的攻击。异常检测已成为入侵检测领域的主要研究对象[2,3],因此,本文以异常检测为主要研究内容。
异常检测的实质是分类问题,即如何将数据分为正常和异常2类。相关研究领域已有很多研究成果。异常检测的研究方法主要有基于统计的方法、基于数据挖掘的方法和基于机器学习的方法这几类[4]。基于统计的方法其核心内容就是利用统计方法设定阈值[5,6]或概率[7,8],对于未知的连接或数据分组,检验其是否在设定的阈值或概率范围内,从而判定是否为入侵或攻击。基于数据挖掘的方法是以数据为中心,利用数据挖掘的相关技术和算法,找出审计数据或流量数据中存在的规律,从而发现入侵行为[9]。基于数据挖掘的检测方法主要有基于离群点的挖掘方法、基于分类的检测方法、基于聚类的检测方法和基于关联分析的检测方法[10,11]。基于机器学习的方法主要有神经网络、遗传算法、隐马尔可夫模型和支持向量机(SVM)等[12]。
在这些方法中,SVM具有比较好的检测效果[13,14]。SVM是在统计学习理论的基础上,充分考虑了结构风险最小化,通过学习得到一个使分类间隔最大化的超平面,从而将不同的类分别开来。同时,SVM具有良好的泛化能力,已经被广泛应用到人脸识别、数据挖掘、入侵检测等领域,并取得良好的分类效果。本文选取SVM作为入侵检测方法,可以达到比较好的检测效果。但SVM方法对训练样本有一定的要求,如果训练不足,可能会导致SVM分类效果和进度达不到要求。因此,本文在SVM方法的基础上引进判别分析的思想,提出一种改进的SVM多分类方法(D-SVM),该方法不仅能够保留SVM较好的分类效果,还能解决由于训练样本较少而对SVM产生的影响。同时,本文还提出一种非参数变量筛选的方法,选出对分类结果有显著作用的特征或变量,从而达到降维和提高分类效果的作用。将本文提出的方法应用到KDD99数据集,结果表明,本文提出的方法具有高的分类精度。
2 方法介绍
2.1 SVM方法介绍
SVM的核心思想就是将样本映射到一个高维空间,并在高维空间中线性可分。再通过在高维空间构造一个超平面来达到分类的目的。SVM一般用在解决二分类问题上,具有良好的效果;对于多分类问题,SVM分类效果较差。为了使SVM在处理多分类问题时也能达到较好的分类效果,本文采用二叉树分类思想,首先将多分类问题处理成二分类问题,再进行逐步迭代,直至将所有的类都分开。
2.2 距离判别法
判别分析可以不受样本不均衡问题的影响,分类效果比较理想且稳健。距离判别的核心思想就是通过计算待判样本到已知类中心的距离,再比较距离的大小,样本到哪个类中心的距离最小,则该样本就判定属于哪一类。距离判别法具有简单高效的特点,它通过计算距离,直观地将样本归类。在某些方法失效的情况下,距离判别仍具有比较稳健的分类效果。距离判别的定义可以表示为
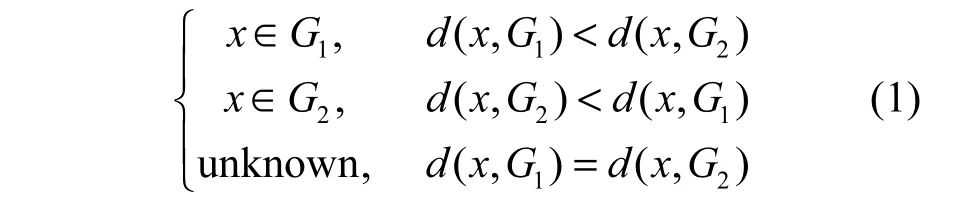
其中,G1,G2表示类1和类2;d(x,G1)和d(x,G2)表示x 到类1和类2的距离。在计算距离时一般选用马氏距离。相比于欧氏距离,马氏距离不仅能够消除变量间量纲的影响,还能消除多维变量间多重相关性的影响。
3 数据处理
3.1 KDD99数据集介绍
KDD99数据集是1998年美国国防部高级规划署在MIT林肯实验室进行的一项入侵检测评估项目。通过模拟真实网络环境,仿真各种用户类型、各种不同的网络流量和攻击手段。收集了9周时间的TCPdump数据。随后来自哥伦比亚大学的Sal Stolfo 教授和来自北卡罗莱纳州立大学的 Wenke Lee 教授对以上数据进行特征分析和数据预处理,形成了一个新的数据集,使其只包含网络流量数据。该数据集被用于1999年举行的KDD CUP竞赛中,成为著名的KDD99数据集。KDD99数据集是公认的入侵检测的Benchmark数据集。
KDD数据集分为全部数据集(kddcup.data.gz,18M)和10%数据集(kddcup.data_10_percent.gz,2.1M)。本文以10%数据集为分析对象。
10%数据集包含494 021条记录,每条记录由41个特征变量和类别标签表示,其中,34个是连续型变量,7个是名义型变量;包含5类数据:Normal(97 278条)、DoS攻击(391 458条)、Probe攻击(4 107条)、U2R攻击(52)和R2L攻击(1 126条)。本文主要使用34个连续型数值变量作为研究的特征变量。
3.2 非参数检验变量筛选
变量筛选的目的是选出对分类结果有显著影响的特征变量,从而可以达到降维,提高效率的作用。不同于已有的变量综合的方法,如PCA,本文提出一种利用非参数检验筛选变量的方法。
Kolmogorov-Smirnov两样本分布检验,从样本经验分布出发,利用大样本性质检验2个样本是否来自于同一个总体。假定样本来自F(x)分布,样本来自)分布,则Kolmogorov-Smirnov检验如式(2)所示。
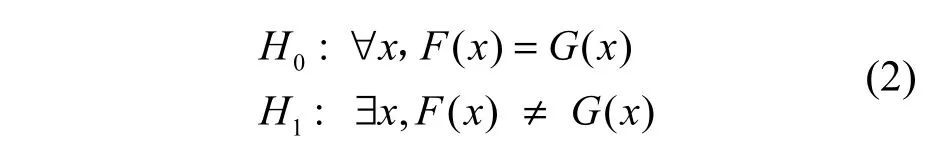

Kolmogorov-Smirnov检验已经运用到许多方面[15~17],在本文中,利用Kolmogorov-Smirnov检验方法检验正常样本与入侵或攻击样本在哪些特征变量上分布具有显著的差异,选出检验显著的特征变量作为研究的变量。与PCA等变量综合的方法不同,本文提出的非参数检验变量筛选的方法可以直接选出正常样本与入侵或攻击样本在统计上有显著差异的变量,删除不显著的变量,消除冗余信息和不显著变量信息对分类的干扰,比变量综合的方法更简便、有效。
4 实验结果及分析
4.1 Kolmogorov-Smirnov检验变量选择
为了研究的简便,本文以KDD99数据集的10%数据集为研究对象,且只选取34个连续型变量和标签变量作为研究的特征变量。因此,得到了一个494 021×35的数据表,其中表的每一行表示一条记录,前34列表示选取的34个特征变量(数值型),第35列是标签,表示每一条记录所属的类别(Normal,DoS,Probe,R2L,U2R)。将10%数据集分为正常、入侵或攻击2类,分别记为类N和类A,其中,类N中样本数为97 278,占19.6%;类A中样本数为396 743,占80.4%。运用Kolmogorov-Smirnov方法检验类N和类A在哪些变量上的分布不存在显著差异,结果如表1所示。

表1 KS检验不显著特征变量
从表1中可以看出这14个特征变量在类N和类A上表现并无显著差异。因此,可以认为这些特征变量对分类结果没有显著影响。最终得到了一个494 021×21的数据表。
4.2 正常与异常行为分类
对于入侵检测,首先关心的是将正常行为和异常行为分开,这是评价研究方法的关键指标。首先利用SVM分类方法构建第一级分类器将正常行为样本与异常行为样本分开。
在数据集中按比例随机选取5 000个正常样本,20 000个异常样本作为训练集。按照同样的方式选取10 000个正常样本和40 000个异常样本作为测试集。独立重复进行5次实验,结果如表2所示。

表2 5次独立实验平均结果
从表2中可以看出,SVM可以有效地将正常和异常样本分隔开,分类效果比较理想。正常行为和异常行为的分类准确率分别达到99.92%和98.32%,整体分类正确率达到99.59%。说明第一级分类可以以较高准确率(99.92%)识别入侵或攻击行为,为入侵行为的进一步分类奠定了基础。
4.3 异常行为具体攻击类别分类
4.3.1 R2L、U2R与DoS、Probe分类
使用KDD99数据集研究多分类文献中,关于R2L和U2R的分类效果都不理想,原因在于这2类攻击样本太少,导致训练不足。考虑到数据集中R2L和U2R样本数较少,将这2类攻击合为一类攻击,记作R&U;DoS和Probe当作一类,记作D or P。利用SVM分类,结果如表3所示。

表3 R&U和D or P的平均误报率(5次独立实验)
从表3中可以看出,即使使用二分类SVM方法,R&U的误报率仍然很高,达到44%,SVM方法对于R&U的分类效果很差。
为了解决R&U误报率高的问题,随机选取5 000个正常样本,求出样本中心。按比例分别随机选取40 400个D or P样本和100个R&U样本,分别计算这2类样本到正常样本中心的马氏距离。这2类的马氏距离分布如图1所示。
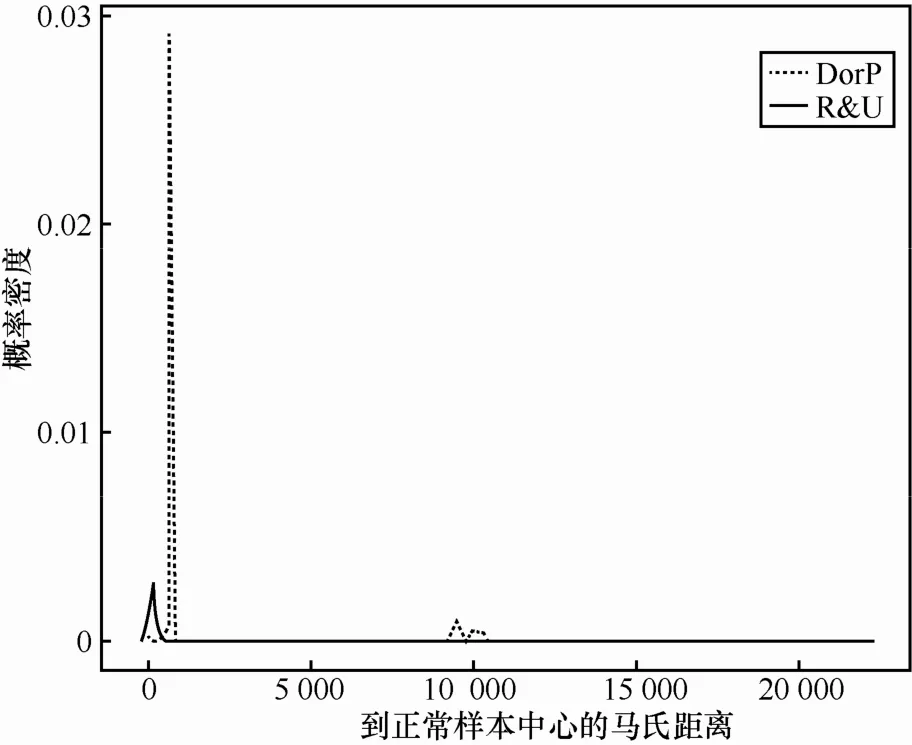
图1 R&U和D or P到正常样本类中心马氏距离分布
从图1中可以清楚地看到R&U和D or P这2类到正常样本中心的马氏距离具有明显的位置差异,说明这2类到正常样本中心的马氏距离显著不同。因此,可以用距离判别方法构建第二级分类器将这2类分开。
随机选取5 000正常样本,计算每一个样本到中心的马氏距离的均值和方差,分别用MN和VN表示。随机选取40 400个D or P样本和100个R&U样本,组成待分类样本记作Test,分别计算Test中每一个样本到正常样本中心的马氏距离,用集合MdTest表示。计算MdTest中每个元素到正常样本中心的偏差程度,用w表示,如式(4)所示。

为了确定w的最优取值,令w从0到4依次取值。每次增加0.1,得到R&U的误报率如图2所示。
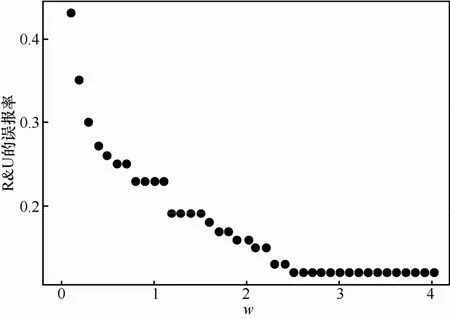
图2 R&U误报率与w变化关系
如图2所示,R&U的误报率随着w的增加,呈现逐步下降的趋势,两者之间表现出负相关关系。此外,随着w的增加,D or P的误报率逐渐上升,R&U与D or P整体分类准确率呈下降趋势,为了平衡R&U误报率和整体分类准确率,本文选取图2中R&U的第3个平稳点作为w的最优取值(w=1.2)。
为了测试距离判别方法的分类效果,按照上文方法进行5次独立重复实验,结果如表4所示。
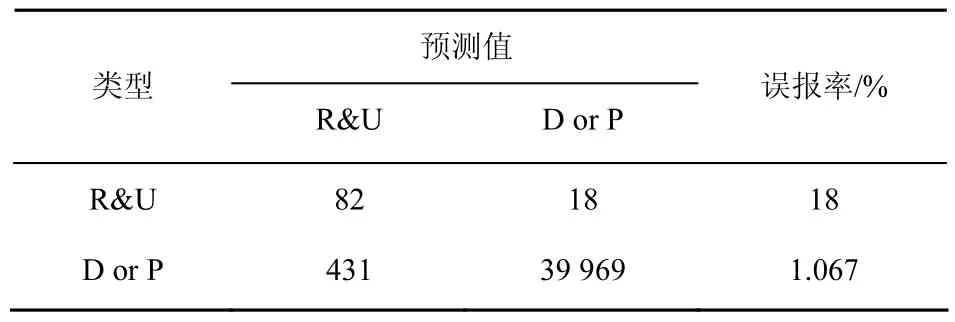
表4 R&U与D or P平均误报率
对比表3和表4可以看出,相比于SVM方法,距离判别不仅能够大幅度降低R&U的误报率,同时,分类正确率较SVM降低得也比较小(R&U的误报率降低59.09%,而检测正确率才只下降0.97%),可以认为两者的分类正确性没有显著差别。由此可见,距离判别方法较SVM方法在R&U与D or P分类问题上表现更好。
4.3.2 DoS与Probe分类
类R&U和类D or P充分分开后,再使用SVM构建第三级分类器,对DoS和Probe判别分类,分类结果如表5所示。

表5 DoS和Probe分类结果(5次平均结果)
表5的分类结果表明,SVM方法可以有效地将DoS和Probe分开,具有较高的分类准确率(DoS为99.95%,Probe为98.96%)和正确率(99.94%)。
以上结果表明,采用三级分类器构建的SVM多分类方法,即D-SVM方法,既能保持SVM分类的优势,同时又能解决由于训练样本不足导致分类效果不理想的问题。
4.4 结果比较
为了比较D-SVM方法与其他方法的分类效果,选取了PCA-Logit[18]、CANN[19],结果如表6所示。。
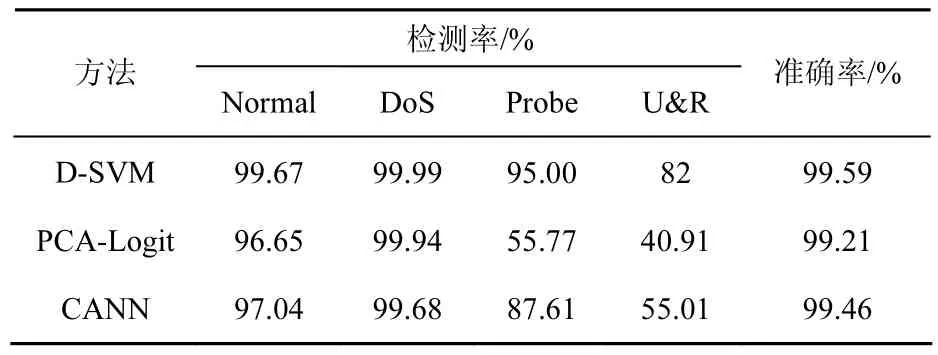
表6 D-SVM与PCA-Logit、CANN分类结果比较
通过表6可以看出,本文提出的D-SVM方法相比于其他2种方法具有一定的优势,具有较高的整体分类准确率(accuracy)和检测率(DR)。在整体分类准确率指标上,D-SVM略高于其他2种方法;但在检测率指标上,D-SVM具有显著的优势,尤其体现在U2R和R2L的检测率上,D-SVM方法的U&R检测率达到82%,远远高于其他2种方法,从而说明,即使在样本不均衡的情况下,D-SVM较其他2种方法仍然能够更加准确地识别出U2R和R2L 2类攻击。因此,与其他2种方法相比,D-SVM具有较高的分类准确率和检测率;同时还可以较少地受到来自不均衡问题的影响,具有稳健性。
5 结束语
本文基于SVM方法,提出一种综合判别分析的多分类方法—— D-SVM。通过构建一个三级分类器,实现了正常行为与入侵行为的准确分类以及入侵行为所属类别分类的功能。第一级分类器利用SVM方法将正常和异常行为分开;第二级分类器利用距离判别分析方法将类R&U和类D or P分开;第三级分类器再利用SVM方法将DoS和Probe分开。并用非参数检验的方法选取对分类结果具有显著影响的特征变量,从而实现降维和提高检测效率的作用。KDD99数据集的实验结果表明,本文提出的方法具有较高的分类准确率和较低的误报率,并克服了由于样本不均衡导致的训练不足、分类结果不理想的缺点。
[1] LEE W, STOLFO S J, MOK K W. A data mining framework for building intrusion detection models[C]//The IEEE Symposium on Security and Privacy. c1999: 120-132.
[2] VERWOERD T, HUNT R. Intrusion detection techniques and approaches[J]. Computer Communications, 2002, 25(15): 1356- 1365.
[3] ENDORF C F, SCHULTZ E, MELLANDER J. Intrusion detection & prevention[M]. McGraw-Hill Osborne Media, 2004.
[4] LIAO H J, LIN C H R, LIN Y C, et al. Intrusion detection system: a comprehensive review[J]. Journal of Network and Computer Applications, 2013, 36(1): 16-24.
[5] SHYU M L, CHEN S C, SARINNAPAKORN K, et al. A novel anomaly detection scheme based on principal component classifier[R]. Coral Gables Department of Electrical and Computer Engineering of Miami University, 2003.
[6] JAMDAGNI A, TAN Z, HE X, et al. Repids: a multi tier real-time payload-based intrusion detection system[J]. Computer Networks,2013, 57(3): 811-824.
[7] 胡志鹏, 魏立线, 申军伟, 等. 基于核Fisher判别分析的无线传感器网络入侵检测算法[J]. 传感技术学报, 2012(2): 246-250. HU Z P, WEI L X, SHEN J W, et al. An intrusion detection algorithm for wsn based on kernel Fisher discriminant[J]. Chinese Journal of Sensors and Actuators, 2012(2): 246-250.
[8] MOK M S, SOHN S Y, JU Y H. Random effects logistic regression model for anomaly detection[J]. Expert Systems with Applications,2010, 37(10): 7162-7166.
[9] 郭春. 基于数据挖掘的网络入侵检测关键技术研究[D]. 北京:北京邮电大学, 2014. GUO C. Research on key technologies of network intrusion detection based on data mining[D]. Beijing: Beijing University of Posts and Telecommunications, 2014.
[10] LEE W, STOLFO S J, MOK K W. Adaptive intrusion detection: a data mining approach[J]. Artificial Intelligence Review, 2000, 14(6):533-567.
[11] HWANG T S, LEE T J, LEE Y J. A three-tier IDS via data mining approach[C]//The 3rd Annual ACM Workshop on Mining Network Data. c2007: 1-6.
[12] AN W, LIANG M. A new intrusion detection method based on SVM with minimum within class scatter[J]. Security and Communication Networks, 2013, 6(9): 1064-1074.
[13] MUKKAMALA S, JANOSKI G, SUNG A. Intrusion detection using neural networks and support vector machines[C]//The 2002 International Joint Conference on Neural Networks(IJCNN'02)c2002: 1702-1707.
[14] GAN X S, DUANMU J S, WANG J F, et al. Anomaly intrusion detection based on PLS feature extraction and core vector machine[J]. Knowledge-Based Systems, 2013, (40): 1-6.
[15] 叶钢, 余丹, 李重文, 等. 一种基于Kolmogorov-Smirnov检验的缺陷定位方法[J]. 计算机研究与发展, 2013(4): 686-699. YE G, YU D, LI C W, et al. Fault localization based on Kolmogorov-Smirnov testing model[J]. Journal of Computer Research and Development, 2013(4): 686-699.
[16] 从飞云, 陈进, 董广明. 基于AR模型的Kolmogorov-Smirnov检验性能退化及预测研究[J]. 振动与冲击, 2012(10): 79-82. CONG F Y, CHEN J, DONG G M. Performance degradation assessment by Kolmogorov-Smirnov test and prognosis based on AR model[J]. Journal of Vibration and Shock, 2012(10): 79-82.
[17] 陈敏. 门限自回归模型条件异方差的Kolmogorov-Smirnov检验[J]. 应用数学学报, 2002(4): 577-590. CHEN M. A Kolmogorov-Smirnov test of conditional heteroscedasticity for threshold autoregressive models[J]. Acta Mathematicae Applicatae Sinica, 2002(4): 577-590.
[18] 李蕊. 基于PCA和LOGIT模型的网络入侵检测方法[J]. 成都信息工程学院学报, 2014(3): 261-267. LI R. A network intrusion detection method based on PCA and LOGIT model[J]. Journal of Chengdu University of Information Technology, 2014(3): 261-267.
[19] LIN W C, KE S W, TSAI C F. CANN: an intrusion detection system based on combining cluster centers and nearest neighbors[J]. Knowledge-based systems, 2015, 7(8): 13-21.

张辉(1979-),女,河南镇平人,硕士,新疆公安厅特别侦察队技术八级工程师,主要研究方向为网络与信息安全、网络侦察技术。

刘成(1985-),男,湖南邵阳人,博士,国家计算机网络应急技术处理协调中心高级工程师,主要研究方向为网络与信息安全、网络攻防技术。
Anomaly intrusion detection based on modified SVM
ZHANG Hui1, LIU Cheng2
(1. Special Reconnaissance Team of Xinjiang Public Security Bureau, Urumpi 830000, China;2. National Computer Network Emergency Response Technical Team/Coordination Center of China, Beijing 100029, China)
A modified SVM multi-classification algorithm integrated with discriminant analysis (D-SVM) was proposed, which could solve the problem of low detection accuracy and high false alarm rate caused by unbalanced datasets. For a multi-classification problem could be divided into several binary classification problems, D-SVM could not only have the virtue of high detection accuracy, but also have a low false alarm rate even confronted with unbalanced datasets. Experiments based on KDD99 dataset verify the feasibility and validity of the integrated approach. Results show that when confronted with multi-classification problems, D-SVM could achieve a high detection accuracy and low false alarm rate even when SVM alone fails because of the unbalanced datasets.
anomaly detection, non-parametric test, SVM classifier, unbalanced datasets, discriminant analysis
TP309/TP274
A
10.11959/j.issn.2096-109x.2016.00092
2016-06-11;
2016-07-23。通信作者:刘成,lc@cert.org.cn
猜你喜欢
电子产品世界(2023年10期)2023-12-21 11:59:21
计算技术与自动化(2023年3期)2023-10-16 19:12:26
煤气与热力(2021年6期)2021-07-28 07:21:40
小学生导刊(2018年34期)2018-12-18 01:53:14
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
山东青年(2016年3期)2016-02-28 14:25:55
现代电子技术(2015年21期)2015-11-09 21:46:26
母子健康(2015年1期)2015-02-28 11:21:33
