
基于大数据的制造业企业信息化数据分析及应用技术研究
2016-10-18 07:48石慧芳陈阳
现代计算机 2016年16期
石慧芳,陈阳
(广东省科技基础条件平台中心,广州510033)
基于大数据的制造业企业信息化数据分析及应用技术研究
石慧芳,陈阳
(广东省科技基础条件平台中心,广州510033)
分析制造业企业对数据处理的需求,提出采用NoSQL数据库实现生产参数数据的存取,从现有生产系统中分流、缓解数据处理压力;结合数据挖掘技术和Hadoop计算框架,从海量的生产数据中挖掘出有价值的信息,研究产品最终特性、良品率等指标与产品制造过程参数之间的关系,建立相关模型,指导企业快速解决产品品质和生产管理等问题,提高企业竞争力。
NoSQL数据库;Hadoop;制造执行系统
0 引言
制造业是国民经济的主体,制造业强则实体经济强。目前,制造业在不断的变革,数字化、网络化、智能化、服务化已逐渐成为制造业发展的主流。广东是国内制造大省和全球重要制造基地,但在新经济形势下,我省制造业发展也面临严峻挑战,迫使制造业必须加快转型升级,由“制造”向“智造”改变。本研究以“广东制造”向“广东智造”转型为契机,重点关注制造业企业信息化升级中的数据价值分析,解决制造业生产环境“数据丰富,信息匮乏”的问题。
1 大数据与制造业大数据
大数据(Big Data)是一个综合性概念,它包括因具备规模性(volume)、多样性(variety)、高速性(velocity)和价值性(value)四个典型特征且难以进行管理的数据,具有对这些数据进行存储、处理、分析的技术,以及能够通过分析这些数据获得实用意义和观点的人才和组织[1]。
制造业中的电子半导体生产、精密仪器制造、生物制药等高端制造业,往往具有严密的工程设计、复杂的装配生产线、大量的控制加工设备与工艺参数、精确的过程控制和材料的严格规范[4]。随着工业4.0技术的发展,制造业的工艺、装备和信息技术也不断发展,现代制造业在生产过程中产生和积累了大量历史数据。这些数据中蕴含对生产和管理有很高价值的知识和信息,但企业工作人员通过人工分析很难察觉到参数间的关联模式和影响品质的重要生产要素等信息。制造业中产生的这些数据完全符合大数据的特征,因此,本文提出利用基于NoSQL、Hadoop和数据挖掘的大数据技术解决制造业海量信息数据处理,以提升产品性能和生产效率。
2 基于MES系统的数据分析
作为制造业企业信息化重要组成部分的制造执行系统(MES)中包含了大量的生产管理一线的数据,本文从这些海量数据入手,研究如何从中过滤、提取有价值的信息,利用数据挖掘技术研究企业产品的最终特性与制造过程中参数之间的关系,建立针对制造企业生产领域的数据挖掘模型,帮助企业快速解决产品品质和技术等问题。
本文以质量管理理论中的“人机料法环”五个影响产品质量的主要因素中的四个:“机料法环”为基础,通过收集这四个因素的数据,挖掘出有价值的信息,分析这四个因素的调整对产品质量的影响。
(1)机:是指生产中所使用的设备、工具等辅助生产用具。本文通过收集、记录生产设备的日常运行数据,监测设备健康状态,研究设备负载,分析设备在满负荷工作、均衡负荷工作等状态下,对产品数量、质量的影响,为设备调度和更新升级等提供指导。
(2)料:指物料,半成品、配件、原料等产品用料。产品用料的来源和管理是影响产品质量的一个重要因素。本文通过收集、记录产品用料的构成、使用量等数据,分析用料成分,用量等因素与产品特性的关联关系。
(3)法:指生产过程中所需遵循的规章制度、工艺等。本研究重点关注制造业企业的生产工序的管理,分析生产线各个工序之间安排是否合理,工序间对接的时间安排等数据,研究各个工序的最佳参数组合,指导生产工序的改进。
(4)环:指生产环境。本文根据产品生产所要求的环境条件,分析生产环境中温度、湿度等环境因素对产品的影响。
3 关键技术研究
本文通过分析制造业企业对数据处理的需求,采用NoSQL数据库实现生产参数数据的存取,从现有生产系统中分流、缓解数据处理压力;结合数据挖掘技术和Hadoop计算框架,从海量的生产数据中挖掘出有价值的信息,研究产品最终特性、良品率等指标与产品制造过程参数之间的关系,建立相关模型,指导企业快速解决产品品质和生产管理等问题,提高企业竞争力。
3.1基于NoSQL的生产实时数据存取
在生产系统如MES等产生的大量监控数据、设备运行记录、作业状态数据等,需要进行实时的处理,这类数据往往具有数据量大,呈现非结构化、半结构化等特点,而且随着生产计划和生产管理的变更,数据的模式可能需要进行相应调整。如果采用传统的关系型数据库对这类数据进行存取,效率相对较低。NoSQL是近年来快速发展起来的数据库技术,主要用于解决互联网应用大规模和高并发量的数据存取需求[3]。NoSQL适用于存储非结构化数据,对数据模式约束较少,其通过多节点部署等方式达到数据高可用性,避免数据单点丢失。随着企业对生产等环节的数据监控、数据处理等实时性要求的提高,NoSQL数据库也逐步在生产制造企业中得到应用。因此,基于数据实时处理和模式变更等方面考虑,本研究将采用NoSQL以满足生产系统的数据处理需求,发挥NoSQL技术优势,提高生产实时数据的存取效率。

图1 总体研究路线图
从传统的关系模式到NoSQL的转换可以采用反模式化的分解方法,用JSON格式来表示NoSQL数据。例如生产系统在关系型数据库中存在以下2个关系模式:

表1 生产线信息表
上述2张表根据外键<所属生产线>进行关联。将上述的关系模式转换为NoSQL数据模式时,我们可以采用JSON内嵌对象表示它们的关系,存储在NoSQL数据库中,如下所示:

采用NoSQL数据库存储生产一线的实时数据和非结构化数据,利用NoSQL灵活的数据模式应对生产数据模型的不断更新,增强系统灵活度。分析提取现有生产系统中对数据实时性要求高、数据模型更新快的数据,采用NoSQL数据库进行存取,缓解现有系统的数据处理压力。对数据实时性要求不高的模块,仍保留原有系统功能接口,降低系统改造成本。
3.2采用Hadoop实现并行计算任务
Hadoop是一种分布式系统基础框架,包括HDFS(分布式文件系统)和MapReduce(分布式计算),利用该平台可以轻松地对海量数据进行分布式处理。本研究将搭建基于Hadoop的计算平台,把数据挖掘算法中可以并行计算的任务交给Hadoop的MapReduce计算框架完成。MapReduce计算的核心就是将问题分而治之。本研究将所需处理的数据划分为多个独立的子数据块,将它们传递给Map节点。这些Map节点根据系统定义的map函数对各个数据块进行处理,并存储中间结果。然后,再把中间结果传递给Reduce节点,调用系统定义的reduce函数做进一步处理,合并最终结果,作为输出传递给系统的下一个模块。通过基于Hadoop的并行计算,解决海量数据的处理问题,提高数据处理和信息挖掘的效率,为数据挖掘提供基础数据保障。
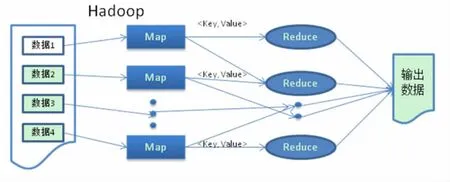
图2 MapReduce框架图
3.3采用数据挖掘提取有价值的信息
本研究的最终目标是在大量生产数据中挖掘有价值的信息,研究最终产品特性、良品率等指标与生产参数之间的关系。根据系统产生的数据类型和产品指标等特征,采用相应的数据挖掘方法。例如运用单个工序,全线工序过程参数值与产品最终特性的关系数据,收集某个季度的历史数据,进行数据挖掘算法的研究。随着数据的不断累积,数据挖掘算法的不断迭代,逐步优化产品特性与生产参数数据的关联模型。

图3 数据挖掘流程图
以某一以生物制药为主的高端制造企业为例,根据系统产生的数据类型和产品指标,采用回归分析和特征组合挖掘的方法,具体如图4所示,工作流1先集成多种特征选择的方法,来选出影响生产制造的重要工艺参数,然后通过回归分析方法建立回归模型,从而建立参数与产品质量的关系。工作流2是通过特征组合挖掘的方法,利用频繁模式分析来挖掘重要工艺参数的关联关系,从而挖掘出可行的参数配方。通过数据挖掘技术的应用,来提高生产制造的良品率和综合效率。
4 结语
当前NoSQL主要应用于互联网行业,在生产制造行业的应用较少,本文基于企业数据模型的分析,采用NoSQL满足企业对部分实时数据,模式变动频繁的数据处理需求。本文提出数据挖掘与Hadoop的结合,将数据挖掘中需要并行计算的任务,采用Hadoop计算平台完成,实现基于制造业MES系统的海量数据挖掘。

图4 数据挖掘工作流示意图
[1]赵国栋,易欢欢,糜万军,鄂维南.大数据时代的历史机遇——产业变革与数据科学[M].清华大学出版社,2013.7.
[2]孙彦超,王兴芬.基于Hadoop框架的MapReduce计算模式的优化设计[J].计算机科学,2014(11):333-336.
[3]申德荣,于戈,王习特,聂铁铮,寇月.支持大数据管理的NoSQL系统研究综述[J].软件学报,2013,24(8):1786-1803.
[4]李涛,曾春秋,周武柏等.大数据时代的数据挖掘——从应用的角度看大数据挖掘[J].大数据,2015,041:1-24.
Research on Data Analysis and Application Technology of Manufacturing Enterprise Informatization Based on Big Data
SHI Hui-fang,CHEN Yang
(Guangdong Science&Technology Infrastructure Center,Guangzhou 510033)
Based on the analysis of the demand for data processing in manufacturing enterprises,proposes the use of NoSQL database to realize the access to the data of production parameters,which can ease the pressure of data processing from the current production system.Uses data mining and Hadoop framework technology to dig out valuable information from the mass production data,studies the relationship between the characteristics of the final product,yield and other indicators and product manufacturing process parameters,and establishes related model which can guide enterprises to quickly solve product quality and production management and enhance the competitiveness of enterprises.
NoSQL Database;Hadoop;MES
1007-1423(2016)16-0050-04DOI:10.3969/j.issn.1007-1423.2016.16.015
石慧芳(1984-),女,福建龙岩人,研究生硕士,信息系统项目管理师,研究方向为电子信息技术应用
2016-05-25
2016-06-01
广东省省级科技计划项目(No.2016B080802002、No.2016A010106003)
陈阳(1984-),男,广东潮州人,本科,信息系统项目管理师,研究方向为计算机、电子信息技术应用
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
走向世界(2022年3期)2022-04-19
心理学报(2022年4期)2022-04-12
能源工程(2021年6期)2022-01-06
建材发展导向(2021年12期)2021-07-22
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
华人时刊(2019年15期)2019-11-26
电子制作(2017年20期)2017-04-26
电子技术与软件工程(2016年24期)2017-02-23
