
基于核函数的加权极限学习机污水处理在线故障诊断
2016-10-14 00:03:05许玉格邓文凯陈立定
化工学报 2016年9期
许玉格,邓文凯,陈立定
基于核函数的加权极限学习机污水处理在线故障诊断
许玉格,邓文凯,陈立定
(华南理工大学自动化科学与工程学院,广东 广州510640)
污水生化处理中的运行故障会引起出水水质不达标、运行费用增高和环境二次污染等严重问题,需要及时准确地对运行故障进行诊断。考虑到污水处理过程运行状态数据的不平衡性造成故障诊断准确率下降,提出了一种基于核函数的加权极限学习机污水处理过程实时在线故障诊断方法。该方法以极限学习机为基础,采用加权的方式处理数据的不平衡特性,通过核函数的非线性映射来提高数据线性可分的程度。仿真实验证明,本文建立的污水处理在线故障诊断模型在线测试精度高,泛化性能好,模型在线更新速度快,能够比较好地满足准确性和实时性,实现对污水处理过程的在线故障诊断。
加权极限学习机;核函数;在线建模;污水处理;故障诊断;仿真实验
引 言
污水处理是一个复杂的、影响因素非常多的生化过程,污水处理厂难以保持长期稳定的运行,发生故障容易引起出水水质不达标、运行费用增高和环境二次污染等严重问题[1],所以需要对污水处理厂运行状态进行在线监控,诊断出运行故障并及时处理。污水处理过程的故障诊断数据具有明显的分布不均衡特征,即正常运行状态的样本数量远远多于故障状态的样本数量。采用传统的机器学习方法建立故障诊断模型,往往容易使分类准确率偏向于多数类,使得少数类(故障类)的分类准确率偏低。然而在实际应用中,故障类的错分代价更高,因此针对具有不平衡性特征的污水处理系统,在保持正常运行状态识别率的同时,提高故障类的识别正确率显得尤为重要。
近年来,国内外学者在污水生化处理的故障诊断领域中取得了许多科研成果。例如,De La Fuente等[2]利用信号频率的信息以及反向传播神经网络用于污水处理的故障诊断;施汉昌等[3]开发了用于诊断城市污水处理厂日常运行的专家系统;陆林花[4]利用聚类算法制定污水故障规则,建立污水处理工艺故障诊断系统知识库;范昕炜等[5]采用基于粗糙集理论的支持向量机算法来实现污水处理过程的故障诊断。以上研究成果均未考虑污水诊断数据的不平衡性特征。到目前为止,针对污水的不平衡特征展开的研究还很少见到,钱云[6]提出一种基于神经网络和支持向量机相结合的方法,处理污水处理故障诊断中的不平衡特征,提高了故障类的识别率,但是故障诊断的性能,尤其是故障类的识别率,还有待进一步提升。
对于污水生化处理的故障诊断,现有技术存在一定的局限性,神经网络容易陷入局部最优,且有过拟合及收敛速度慢的缺点;专家系统存在知识获取瓶颈问题,若建立的专家知识库不完备,则有可能导致推理混乱;粗糙集理论在处理异常或噪声数据方面常常会显得无能为力,并且在建立模型时需要大量的数据样本[7-8];支持向量机受到核函数必须满足Mercer条件和惩罚参数及不敏感参数计算量过大等限制,并且随着训练样本数的增加,训练时间会变长[9];相关向量机(relevance vector machine,RVM)[9]虽然比SVM模型更为稀疏,核函数不需要满足 Mercer 条件,并且模型中的自由参数数量更少,但是其计算复杂度大,所需内存开销大,在此基础上,Tipping等[10]引入了快速边界似然算法(fast variable relevance vector machine,Fast RVM),虽然提高了其计算的速度,但是基本的Fast RVM能够直接处理的对象都是两类模式分类问题,在处理多分类问题时,必须采用多个Fast RVM分类器组合的分类方法,如“一对多”、“一对一”等多分类方法[11-12],随着待分类别的增加,其训练时间同样也会增加。
针对污水数据不平衡特征和污水处理在线故障诊断对于准确性与实时性要求,本文提出采用一种基于核函数的加权极限学习机(kernel-based weighted extreme learning machine,K-WELM)的方法对污水处理过程进行在线故障诊断建模。该方法通过对不同数量的样本类进行加权恢复样本类间的平衡性,结合核函数将线性不可分的模式进行非线性映射到高维特征空间,增加其线性可分的程度,进一步提高分类的准确率,利用极限学习机(extreme learning machine,ELM)[13]学习过程中无须反复调整参数,可将传统单隐层前馈神经网络参数训练问题转化为求解线性方程组,加快在线学习速度,从而实现对污水处理厂运行状态实时准确地监测,并通过仿真实验验证了其性能。
1 基于核函数的加权极限学习机污水处理在线故障诊断模型
图书馆馆服是职业装的一种,又称工作服,是为读者服务工作需要而特制的服装。馆服在设计时需根据图书馆性质的要求,从服装的色彩、面料、款式、造型、搭配等多方面考虑,提供最佳设计方案,为图书馆打造富有内涵及品位的全新馆员职业形象。高职院校图书馆馆员做为学校产学研的服务者,自身形象体现为行为举止、音容笑貌、仪容仪表等方面,随着时代的发展,他们不再是传统观念上的图书搬运工和勤杂工,而是集知识收集、分类、整理、加工和传播者,是服务于读者的公众人物,其仪表形象直接反响读者对图书馆形象直观印象。统一馆服使得馆员可以有全面的精神面貌,展示图书馆的良好形象,提升图书馆馆员的服务水平。
1.1 基于核函数的加权极限学习机
极限学习机采用单隐层前馈神经网络(single-hidden layer feedforward networks,SLFN)的框架,给定个污水处理故障诊断训练样本,,含有个节点的标准SLFN输出模型可以表示如下
可将式(2)表示为
其中

当激活函数无限可微时,SLFN参数不需要全部进行调整,输入链接权重和隐藏层偏置在网络参数初始化的过程中随机选定,并且在训练过程中保持不变,那么训练SLFN就等价于求解线性系统的最小二乘解。由隐藏层神经元输出的Moore-Penrose广义逆矩阵[14]可解得
采用正交投影法(KKT)[15]可以有效地对求解,当或为非奇异矩阵的情况时或。为了使所得到的模型获得更好的稳定性和泛化性能,在求解时需要对或对角线元素加上一个足够小的正值1/,可以得到
相应的输出函数为
或者当
相应的ELM的输出函数为
为了更好地处理不平衡数据,对每个样本进行加权,使得属于不同类的样本获得不同的权值,最终求解隐藏层输出权重可表示为
通常有两种加权方案,一种是自动加权方案
另一种加权方案的思想是将少数类和多数类的比例向着0.618:1的方向推进,实质上,这种方法是在通过牺牲多数类的分类精度来换取对少数类的识别准确率
这里核函数需要满足Mercer条件,那么根据式(10)可以将输出表达式(7)写成
其中,为单位矩阵,为正规化系数,为加权矩阵,为输出层矩阵,为核矩阵。
综上可知,基于核函数的加权极限学习机训练算法的流程为:
(1)根据加权方案赋予每个样本权值,计算加权矩阵;
1.2 污水处理在线故障诊断建模步骤
污水处理过程通过污水历史数据集建立的在线诊断模型对新的观测数据进行分类决策,然后更新历史数据集,重新训练模型,等待下一次分类决策。记污水历史数据集,新观测数据为,污水处理在线故障诊断建模步骤如下:
(2)选取核函数和加权方案,根据最优模型确定模型参数;
在线故障诊断建模总体流程如图1所示。

图1 基于核函数的加权极限学习机污水在线故障诊断建模流程
2 仿真实验与结果分析
2.1 性能指标
污水处理的故障诊断通常是一个多分类的问题,基于混淆矩阵分析的方法是评价一个分类器性能好坏的最直接的方法,多分类问题的混淆矩阵[6]如表1所示。

表1 多分类问题的混淆矩阵
在多分类问题上,G-mean定义为所有类的召回率的几何平均值,计算公式如下
每类的召回率表示的是每个类别的分类准确率。总分类准确率是全部类别分类正确的个数与总样本个数的比值。G-mean是在使每类的分类准确率都尽可能大的同时,保持每个类别之间的平衡,是用来评价不平衡数据集上分类器性能的一个重要指标,与总分类准确率相比,更加客观和科学。因此本文采用G-mean作为衡量污水不平衡数据故障诊断的主要性能指标,每类的召回率、总的分类准确率以及离线训练时间或整体在线测试时间作为仿真实验的辅助性能指标。
2.2 实验数据
实验仿真的数据来自加州大学数据库(UCI),是一个污水处理厂的日常监控数据,整个数据集包括不完整记录在内一共有527个记录,每个样本维数为38,全部属性值都完整记录的有380个,被监测的水体一共有13种状态,各个状态用数字代替。527个记录在13种状态下的分布情况见表2。

表2 13种监测状态的数据分布
为了简化分类的复杂度,根据样本类别的性质,将样本分为4大类,见表3。

表3 4种检测状态下的数据分布
表3中,类别1为正常情况,类别2为性能超过平均值的正常情况,类别3为进水流量低的正常情况,类别4为二沉池故障、暴雨引起的非正常状态和固体溶度过负荷等原因引起的故障情况。正常情况的类别1样本的个数比较多,属于多数类;而类别3和类别4由于样本个数比较少,故属于少数类,经过数据类别的化简,4类样本的分布比例为23.7:8.3:4.6:1,样本集具有典型的不平衡特征。
2.3 参数分析
对于K-WELM的离线建模和在线建模,其参数选择主要包括两方面,一是加权方案,二是核函数。对于加权方案的选取,首先选取径向基核函数,然后分别选取第1节中的1和2的两种加权方案进行离线建模测试,得到的测试结果如图2所示,其中“R X acc”表示的是类别X的分类正确率,“train acc”表示训练分类正确率,“test acc”表示测试分类正确率,“G-mean”表示所有类的召回率的几何平均值,“train time”表示训练时间,“test time”表示测试时间,1和2分别表示第1种和第2种加权方式。
从图2可知,对于第1节提出的1和2的两种加权方案来建立K-WELM的污水诊断的离线模型的效果实际上差不多,不管从分类准确率上还是训练或测试的时间上都相差不多,不过对于污水不平衡数据来说,1的加权方案的G-mean值更高,会更加适合污水故障诊断。

图2 两种加权方案离线建模的结果
对于核函数的选取,一般有下面几种常用的核函数。
(1)径向基(RBF)核函数
(2)线性核函数
(3)阶多项式核函数
(4)Sigmoid核函数
考虑到阶多项式核函数的参数为两个,要比RBF核函数多,且当多项式的阶数比较高时,核矩阵的元素值将趋于无穷大或无穷小,会增加数值的计算困难;而Sigmoid核函数必须在某些特定条件下才满足对称、半正定的核函数条件,并且有两个参数要选取,其应用上受到一定的限制。所以先选取1的加权方式,分别选取RBF核函数和线性核函数进行离线建模测试,得到的测试结果如图3所示,其中“RBF”表示径向基核函数,“linear”表示线性核函数。
从图3可知,对于分别采用RBF核函数和线性核函数来建立K-WELM的污水诊断的离线模型,RBF核函数的K-WELM模型分类准确率比线性核函数的要高,虽然训练时间和测试时间比线性核函数要多,但是均足够小,所以选用RBF核函数更适合。综上分析,本文基于核函数的加权极限学习机的污水故障诊断的建模采用1加权方案和RBF核函数。

图3 两种核函数离线建模的结果
2.4 污水故障诊断的离线仿真实验
故障诊断的目的就是对污水处理厂的运行状态进行准确监控,及时处理异常情况。仿真试验中,首先剔除掉527个污水数据中147个属性不完整的数据,得到380个属性完整数据,然后将数据按式归一化处理,将处理后的数据集按2:1的比例随机分层抽样,得到训练集和测试集。然后分别对反向传播神经网络(BPNN)、支持向量机(SVM)、相关向量机(RVM)、快速相关向量机(Fast RVM)、极限学习机(ELM)、核函数极限学习机(K-ELM)以及本文的基于核函数的加权极限学习机(K-WELM)模型分别进行离线的建模和分类测试。其中BPNN模型设计为3层结构,输入层有38个节点,输出层有4个节点,隐藏层的节点个数用点搜索来寻找,寻优范围为[1,30],采用5折交叉验证;SVM模型选用RBF函数作为核函数,惩罚因子和核函数参数使用网络搜索法在区间[200,300]和区间[0,1]内5折交叉验证获得;RVM和Fast RVM模型也采用RBF核函数,核宽度参数同样采用5折交叉验证的点搜索方法来确定,并同样建立“一对一”的多分类模型;ELM模型选择Sigmoid函数为激活函数,隐藏层的节点个数用点搜索在[10,300]内5折交叉验证选取;K-ELM模型和K-WELM模型均选用RBF核函数,模型的正规化系数和核函数参数采用5折交叉验证的网格搜索法,特别的K-WELM模型采用第1种加权方案。由此保证了模型参数的合理性、模型的分类测试结果的可靠性。
其中对BPNN模型和ELM模型的隐藏层节点取不同个数可以得到不同的训练集的交叉验证准确率,结果如图4、图5所示。

图4 BPNN模型不同隐藏层节点个数的验证准确率

图5 ELM模型不同隐藏层节点个数的验证准确率
从图4、图5可以得到,BPNN模型在隐藏层节点个数大于4附近之后,交叉验证准确率上升到92%附近波动,之后随着节点个数增大不再有很大变化;ELM模型在隐藏层节点个数为20~40交叉验证准确率最大,然而并不是隐藏层节点个数越多越好,反而训练数据的交叉验证准确率随着隐藏层节点个数增大而下降。
每个模型实验进行10次,取10次实验测试精度的平均值对各分类进行评估,7种模型的分类测试结果如表4所示,“training time”为离线模型训练时间。从表中可以看出,BPNN模型的第1、第2类准确率比较大,训练时间比较短,但是第3、第4类准确率却比较低,虽然总的准确率不是很差,但是其G-mean值最低,为6.75%;SVM模型将第4类准确率提高一点,使得总体准确率和G-mean值都有所提高;RVM模型提高了第2、第3、第4类的准确率,使得G-mean值提高;Fast RVM模型虽然将第1、第2类准确率提高,但是第3、第4类准确率却很低,使得G-mean值降低;ELM模型由于将传统单隐层前馈神经网络参数训练问题转化为直接求解线性方程组,使得训练时间大大地减少,G-mean也有所提高,达到36.87%;K-ELM模型继承了极限学习机的优点,同时通过核函数的非线性映射关系提高样本的线性可分程度,增加了各类的分类准确率,模型训练时间相对ELM也有所减少,G-mean值与ELM模型接近;K-WELM模型保持了第1、第2类的准确率,提升了第3、第4类的准确率,使得最终的G-mean的值达到57.26%,优于其他6种模型。在训练时间上,3种基于ELM的模型都体现了较大优势。
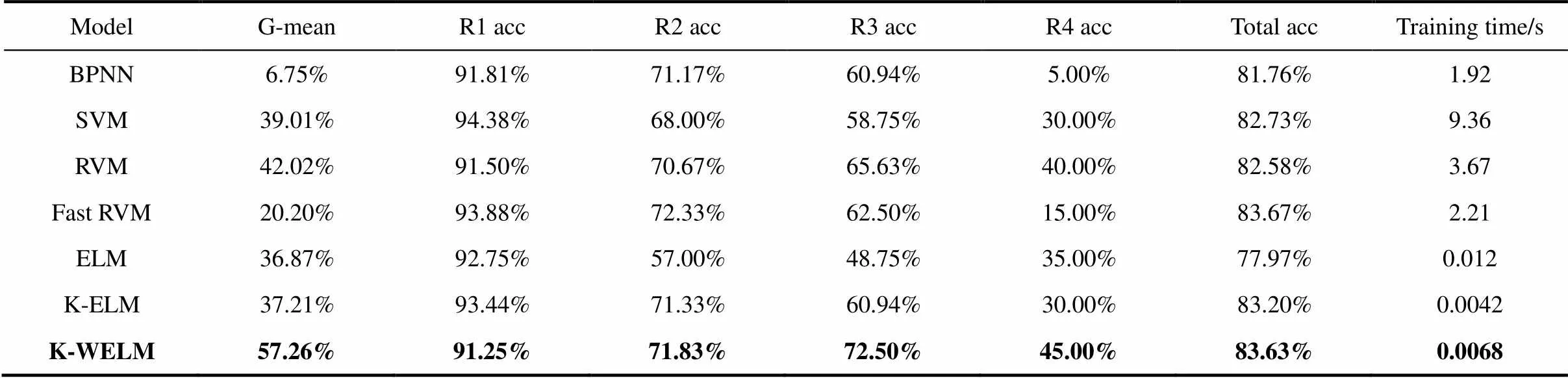
表4 7种模型的离线分类结果
综合以上分析,K-WELM的污水处理故障诊断模型性能比其他模型更好,为了对污水处理过程运行状态进行实时监测,并且考虑到状态监测的准确率,所以本文采用基于核函数的极限学习机的在线故障诊断模型。
2.5 污水故障诊断的在线仿真实验
2.5.1 一般更新模型方法的在线仿真实验
污水处理的故障诊断实际上是一个连续的过程,在线仿真实验时,需要对每一组新的数据进行测试并加入模型进行更新。历史数据集通过采取限定记忆的方式来保持其容量。限定记忆是指训练数据始终是有限组,每增加一组最新的观测数据,就随即丢弃一组最早的观测数据,从而保证模型中都包含新数据的信息,避免历史所含数据信息淹没新数据所包含的信息[16-17]。
同样首先将污水数据集做2.4节同样处理,将处理后的380组数据按2:1的比例进行随机分层抽样,得到历史数据集和在线更新测试集。然后根据网格搜索法或点搜索方法求取最优模型参数,进行10次实验,最终求取参数的一个平均值作为最优模型的参数。其中BPNN模型的隐藏层节点数;SVM模型中同样采用RBF核函数,惩罚因子,核函数参数;RVM和Fast RVM模型同样采用RBF核函数,其核函数参数都取;ELM模型隐藏层节点数;K-ELM模型以RBF为核函数,核函数参数,正规化系数;K-WELM模型选取RBF核函数和式(16)的加权方案,核函数参数,正规化系数。接着用历史数据集对上述模型分别建立初始的离线分类模型,然后分别建立在线故障诊断模型,每次从在线更新测试集中取个数据进行在线更新,同时去掉历史数据集中前个数据,实验进行10次,取10次实验测试精度的平均值对各分类进行评估,6种模型的在线分类测试结果如表5所示,“testing time”为在线测试时间。

表5 7种模型的在线分类结果
由表5可知,7种模型中,BPNN的第4类分类正确率和G-mean都是最低,表明BPNN对样本数据的依赖性最强。SVM、Fast RVM、ELM和K-ELM的G-mean比较接近,RVM和K-WELM的G-mean最高。K-WELM的训练时间比RVM更短。实验结果说明,本文提出的污水处理在线故障诊断K-WELM模型,与其他6种模型相比,具备更好的分类准确率和快速性。
2.5.2 经验更新模型方法的在线仿真对比实验
通常污水处理过程的故障类数据相对于正常类数据要少得多,为了避免每次更新历史数据集时,去掉前个数据后,会导致少数类样本的个数更少甚至没有,从而使得下一次少数类样本得不到训练,降低少数类的分类准确率,这里采用一种新的更新历史数据集的方法进行对比试验。同2.5.1节同样的步骤建立6种在线故障诊断模型,只是在每次历史数据集进行在线更新时,并不是直接去掉历史数据集中前个数据,而是去掉历史数据集中前个第1、第2类的数据,这里同样取,其他实验步骤与2.5.1节一样。7种模型的在线分类测试结果如表6所示。

表6 7种模型的在线分类结果
从表6可以看出,本文提出的K-WELM在线模型的综合性能仍然占优,虽然7种模型的运行时间相对于2.5.1节的实验结果都稍微有所增加,主要是因为增加了对历史数据更新计算步骤,但是少数类的分类准确率、总的分类准确率和G-mean值却都有所提高。因此,在对污水处理过程进行在线故障诊断建模时,可以根据污水数据的先验情况,选择具体的模型更新方式,更好地提高在线诊断的分类准确率。K-WELM在线模型在计算时间上的优势,为该方法在其他对实时性要求比较高的工业领域中进行应用提供了可能性。
3 结 论
污水生化处理过程复杂,一旦发生故障会引起出水水质不达标、运行费用增高和环境二次污染等严重问题,必须对污水处理厂运行状态进行实时监控。针对以上问题,根据污水处理过程运行状态数据的不平衡性特点,本文提出一种基于核函数的加权极限学习机的在线故障诊断方法,该方法采用加权的方式处理数据,通过核函数的非线性映射来提高数据线性可分的程度,并利用极限学习机的学习速度快的特点进行污水处理的在线建模。通过与其他模型仿真实验对比得知,该方法建立的污水处理在线故障诊断模型学习速度快,泛化性能好,有效避免了局部收敛,在线测试精度高,能够比较好地满足准确性和实时性,从而实现了对污水处理过程的在线故障诊断。
References
[1] 胡俊刚, 胡雪梅. 城镇污水处理厂运营现状及自动化控制的应用 [J]. 武汉理工大学学报, 2002, 11 (24): 66-69.
HU R G, HU X M. Management and automatically control in water treatment [J]. Journal of Wuhan University of Technology, 2002, 11 (24): 66-69.
[2] DE LA FUENTE M J, VEGA P. A Neural networks based approach for fault detection and diagnosis: application to a real process [C]// Proceedings of the 4th IEEE Conference on Control Applications (CCA 1995). 1995: 188-193.
[3] 施汉昌, 王玉珏. 污水处理厂故障诊断专家系统 [J]. 给水排水, 2001, 27 (8): 88-90.
SHI H C, WANG Y J. Diagnostic expert system for WTTP [J]. Water & Water Engineering, 2001, 27 (8): 88-90.
[4] 陆林花. 聚类算法及其在污水处理工艺故障诊断中的应用研究 [D]. 重庆: 重庆大学, 2007.
LU L H. Research on clustering algorithms and its application of the fault diagnosis of wastewater treatment process [D]. Chongqing: Chongqing University, 2007.
[5] 范昕炜, 杜树新, 吴铁军. 粗SVM分类方法及其在污水处理过程中的应用 [J]. 控制与决策, 2004, 19 (5): 573-576.
FAN X W, DU S X, WU T J. Rough support vector machine and its application to wastewater treatment processes [J]. Control and Decision. 2004, 19 (5): 573-576.
[6] 钱云. 非均衡数据分类算法若干应用研究 [D]. 长春: 吉林大学, 2014.
QIAN Y. Research on application of classification algorithms for imbalanced data [D]. Changchun: Jilin University, 2014.
[7] LEE H J, AHN B S, PARK Y M. A fault diagnosis expert system for distribution substations [J]. IEEE Trans. on Power Delivery, 2000, 15 (1): 92-97.
[8] 刘成忠, 韩俊英. 基于邻域粗糙集的支持向量机在污水处理故障诊断中的应用 [J]. 甘肃农业大学学报, 2013, 48 (3): 176-180.
LIU C Z, HAN J Y. Application of support vector machine based on neighborhood rough set to sewage treatment fault diagnoses [J]. Journal of Gansu Agricultural University, 2013, 48 (3): 176-180.
[9] TIPPING M E. The relevance vector machine [J]. Advances in Neural Information Processing Systems, 1999, 12 (3): 652-658.
[10] TIPPING M E, FAUL A C. Fast marginal likelihood maximization for sparse bayesian models [C]//Proc. 9thInternational Workshop on Artificial Intelligence and Statistics. Key West, 2003: 3-6.
[11] GALAR M, FERNANDEZ A, BARRENECHEA E,. An over view of ensemble methods for binary classifiers in multi-class problems: experimental study on one-vs-one and one-vs-all schemes [J]. Pattern Recognit, 2011, 44 (8): 1761-1776.
[12] HSU C W, LIN C J. A comparison of methods for multiclass support vector machines [J]. IEEE Trans. Neural Netw., 2002, 3 (2): 415-425.
[13] HUANG G B, ZHU Q Y, SIEW C K. Extreme learning machine: a new learning scheme of feedforward neural networks [C]//Proceedings of 2004 IEEE International Joint Conference on Neural Networks. 2004: 985-990.
[14] HUANG G B, CHEN L. Convex incremental extreme learning machine [J]. Neurocomputing, 2007, 70 (16/17/18): 3056-3062.
[15] HUANG G B, WANG D H, LAN Y. Extreme learning machines: a survey [J]. International Journal of Machine Learning and Cybernetics, 2011, 2 (2):107-122.
[16] 许继平, 陈晨, 刘载文, 等. 基于软测量理论的BOD在线检测仪研究 [J]. 控制工程, 2010, 17 (s1): 90-92.
XU J P, CHEN C, LIU Z W,. Research on BOD online detection instrument based on the theory of soft instrument [J]. Control Engineering of China, 2010, 17 (s1): 90-92.
[17] BUCHGRABER T, SHUTIN D, POOR H V. A sliding-window online fast variable sparse Bayesian learning algorithm [C]//2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 2011, 45 (1): 2128-2131.
Online fault diagnosis in wastewater treatment process by kernel-based weighted extreme learning machine
XU Yuge, DENG Wenkai, CHEN Liding
(School of Automation Science and Engineering, South China University of Technology, Guangzhou 510640, Guangdong, China)
Operation faults in biochemical wastewater treatment process often result in serious issues such as effluent water below quality specification, high operation cost, and secondary environmental pollution, therefore spontaneous and accurate diagnoses are required. Considered the poor accuracy of fault diagnosis induced by imbalanced characteristics of the process data in wastewater treatment, a novel online fault diagnostic model for wastewater treatment process was proposed,.., the kernel-based weighted extreme learning machine. Based on extreme learning machine (ELM) theory, weighting scheme was used to resolve the data imbalance and the non-linear mapping of kernel function was used to improve the extent of linear separation. Simulation experiments showed that this online fault diagnostic model has higher measuring precision, better generalization ability, and faster online updating speed, and meet the requirement of accuracy and spontaneity. Therefore, the proposed method can be applied in real-time on-line fault diagnosis in wastewater treatment process.
weighted extreme learning machine; kernel function; on-line modeling; wastewater treatment; fault diagnosis; simulation experiment
supported by the National Natural Science Foundation of China (61473121), Science and Technology Planning Project of Guangdong Province, China (2016A020221008) and Special Project on the Integration of Industry, Education and Research of Guangdong Province (201604010032).
date: 2016-01-27.
XU Yuge, xuyuge@scut.edu.cn
TP 18
A
0438—1157(2016)09—3817—09
10.11949/j.issn.0438-1157.20160118
国家自然科学基金项目(61473121);广东省科技计划项目(2016A020221008);2016年产学研重点项目(201604010032)。
2016-01-27收到初稿,2016-04-12收到修改稿。
联系人及第一作者:许玉格(1978—),女,博士,副教授。
猜你喜欢
中国应急管理科学(2022年2期)2022-05-23 18:49:25
今日农业(2021年20期)2021-11-26 01:23:56
测控技术(2018年10期)2018-11-25 09:35:26
自动化学报(2018年2期)2018-04-12 05:46:21
资源节约与环保(2018年1期)2018-02-08 02:18:31
制造技术与机床(2017年4期)2017-06-22 11:17:32
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58
郑州大学学报(理学版)(2014年2期)2014-03-01 04:20:53
振动、测试与诊断(2014年5期)2014-03-01 01:14:21
机械与电子(2014年1期)2014-02-28 02:07:31
