
面向大数据应用挑战的超级计算机设计
2016-09-21 08:30廖湘科谭郁松卢宇彤周恩强国防科学技术大学计算机学院长沙410073
上海大学学报(自然科学版) 2016年1期
廖湘科,谭郁松,卢宇彤,谢 旻,周恩强,黄 杰(国防科学技术大学计算机学院,长沙410073)
面向大数据应用挑战的超级计算机设计
廖湘科,谭郁松,卢宇彤,谢旻,周恩强,黄杰
(国防科学技术大学计算机学院,长沙410073)

在大数据时代,大数据处理给面向高性能计算设计的超级计算机带来计算、存储、通信、编程等软硬件体系结构方面的挑战.对此在分析目前主流学术界和工业界相关研究成果的基础上,介绍了天河二号超级计算机系统针对大数据处理应用所采用的新型异构多态体系结构、自主定制高速互连网络、混合层次式存储系统、混合计算框架等多种优化措施,为大数据时代的超级计算机设计提供有意义的参考.
大数据;超级计算机;天河二号
大数据已成为当前各界关注的焦点,泛指大规模、超大规模的数据集.维基百科对“大数据”[1]的定义是,所涉及的资料量规模巨大到无法通过目前主流软件工具,在合理时间内达到收集、管理、处理并整理成为帮助企业经营决策的资源.数据咨询公司IDC提出大数据呈现4V(volume,velocity,varity,value)特性[2].容量(volume)体现为在信息世界里,产生、收集和分析的数据量从TB级别向ZB级别发展;产生速率(velocity)是指数据产生和传播的速度极快,呈现流动性特征;多样性(varity)表现为数据来自不同数据源,在编码格式、存储格式、应用特征等多个方面呈现多层次、多方面的差异;价值(value)是指大数据价值密度低,而商业价值高的特点.大数据蕴含大信息,大信息将在更高更广的层面提升用户的观察力、决策力,为人类社会创造巨大价值.规模巨大、价值稀疏、结构复杂、时效性强的大数据处理需求是传统高性能科学与工程计算设计所不能满足的,存在计算复杂度高、任务周期长、数据实时性强、计算通用性差等方面的问题.因此,本研究认为大数据带来的问题对计算系统的系统架构、计算框架、处理方法等提出了新的挑战.
依靠超级计算机搭建大数据中心,是目前的主流发展趋势之一.超级计算机具有高性能的优势,能为大数据处理提供高效的计算能力.自20世纪70年代起,超级计算机便作为国家战略资源而存在,是解决国家经济建设、科学进步、社会发展、国防安全等一系列巨大挑战的重要技术手段,也是国家科技水平、国家竞争力的重要体现.由国防科学技术大学研制的天河二号超级计算机,以每秒3.39亿亿次的浮点运算速度连续五次摘得全球运行速度最快的超级计算机桂冠.但是,超级计算机所擅长的领域是以科学与工程计算为主的计算密集型任务,计算模式具有单一性的特点.而大数据处理通常包含批处理计算、流式计算、迭代计算、图计算等数据密集型计算模式,因此传统的超级计算机难以直接应用于大数据的计算.
为了解决这一问题,近几年所设计的超级计算机在体系结构、软件等方面逐渐进行了改进.本研究首先对面向大数据应用的超级计算机所面临的挑战从软硬件两个方面进行分析,并介绍了国内外学者对大数据的研究现状,最后阐述了天河二号超级计算机针对大数据处理所进行的改进,为大数据时代的超级计算机设计提供了有意义的参考.
1 大数据对超级计算机提出的挑战及研究现状
超级计算机能够为大数据应用提供强大的计算能力、海量的存储空间支持.但是,超级计算机是面向高性能计算设计的计算系统,高性能计算与大数据处理存在多方面差异. 表1是从应用领域、密集型、数据存储、软件平台等不同角度对高性能计算(high performance computing,HPC)应用和大数据应用特点的比较,可见超级计算机在处理大数据和高性能计算时所表现出的性能具有明显的差异性.相对于Top500排名,为了表征超级计算机面向大数据应用的计算能力,2011年美国圣地亚哥国家实验室与多家IT公司合作定义发布了Graph500排名[3].Graph500中使用的基准强调子系统之间的通信,是在一个无向图中进行广度优先搜索,而不是Top500中采用的双精度浮点计算.基准计算核心有两个:一是生成搜索图,二是压缩成稀疏结构CSR或CSC.
高性能计算十分注重节点的计算能力,而大数据应用的瓶颈在于数据通信.因而面向高性能计算设计的超级计算机服务于大数据应用存在一定的不足.接下来将从硬件体系结构和软件架构两个方面进行分析.

表1 大数据处理与高性能计算的比较Table 1 Comparison between big data processing and HPC
1.1硬件体系结构
1.1.1计算部件
大数据应用数据量大、计算简单,因而计算的指令级并行较低,数据访问开销较大.将大数据应用部署在超级计算机上存在明显的数据吞吐率与计算能力不匹配的问题.为了验证处理器面向大数据应用的不足,上海交通大学梁晓峣团队通过实验对CPU架构进行研究,结果表明大数据应用将大部分时间都浪费在了数据内存访问上[4].片上存储架构不能很好地为大数据应用提供必要的支持,导致计算和存储的失衡,浪费了计算能力.
面向大数据的处理器优化主要集中在两个方面:一是解决计算能力问题.由于大数据对实时性要求较高,采用通用处理器很难满足要求.为此,超级计算机采用异构并行处理器,即通用核与专业加速器相结合,利用加速器进行加速,增加各类计算任务中的数据级并行. Top500和Graph500的计算机大多采用CPU和协处理器混合的架构.协处理器具有很强的处理能力,但是从CPU到协处理器的数据延迟很严重.因此,通过软件的数据划分和硬件上将CPU与GPU放置在一个芯片等策略可以取得很好的优化效果.二是解决数据吞吐量与计算能力不匹配的问题,片上缓存的优化成为解决该问题的关键.大数据应用指令跳转频繁,且指令局部性差,因而可以适量减小指令缓存.同时大数据应用的数据很少被重复利用,而是在每次计算完之后就可以丢弃,因此应该注重对数据缓存的优化,建立处理器与二级缓存之间的数据通道,或者采用eDRAM代替缓存.
1.1.2存储架构
将大数据应用移植到超级计算机上,数据局部性访问特征变得尤其明显,而内存和外存之间的I/O性能不匹配问题并未得到有效解决.目前最常见的大数据处理模式MapReduce需要将计算中间结果写回磁盘中,导致系统的I/O开销极大,不能满足应用的实时性需求.针对这一问题,有以下3种解决途径.
一是采用新型存储器,建立新的存储结构,缩小计算速度和存储速度之间的差距.随着以电阻随机存储器(resistive random access memory,RRAM)、铁电随机存储器(ferroelectric random access memory,FeRAM)、相变存储器(phase change memory,PCM)等为代表的新兴非易失性存储器(non-volatile memory,NVM)技术的发展,使得传统的内存与存储分离的界限逐渐变得模糊,推进了存储技术的发展,为新型内存与存储体系结构的产生打下了良好的基础.基于新型存储级内存(storage class memory,SCM)[5]和传统动态随机存储器(dynamic random access memory,DRAM)设计的新型混合内存体系,能够在保持成本和能耗优势的前提下大幅提升内存容量,从而避免传统计算设施上内存磁盘访问模式中I/O能力受限的问题,大幅度提升大数据处理的时效性、吞吐量和性能.Dhiman等[6]和Ham等[7]分别提出了针对PCM的异构混合硬件架构,改进了架构的设计过程并降低了设计难度.非易失存储器增加了存储与计算之间的数据传输带宽,而固态存储减少了内存与存储之间数据传输的延迟. Fusion-IO,Intel,RamSAN,SDSC和国防科学技术大学等国内外企业和研究单位都在闪存上开展了相关工作,且目前已有多台超级计算机采用固态硬盘取代传统的硬盘存储,以提高访问速度.
二是采用先进的3D封装技术缓解存储带宽延迟问题.3D堆叠封装技术是指单个封装体内可以堆叠多个芯片,以实现存储容量的倍增且数据传输更快,同时所占芯片的面积减小.采用该技术可以通过高速网络接口访问外部三维叠片封装以消除读写瓶颈问题.从英特尔的3D三栅极晶体管,到三星3D垂直堆叠型结构NABND闪存芯片,再到类似多层堆叠的产品——HMC(hybrid memory cube)内存的出现,3D堆叠封装技术逐渐走向成熟,并应用于工业界芯片生产.AMD(ATI)发布了采用20 nm工艺的3D堆叠高带宽内存(high bandwidth memory,HBM);Nvidia也表示将在2016年引入3D封装工艺;三星已批量投产全球第一款采用3D TSV立体硅穿孔封装技术打造的DDR4内存条,其单条容量高达64 GB.
三是利用光互连技术取代传统的电互连,这也是解决处理器访问存储瓶颈的有效解决方案之一.哥伦比亚大学长期致力于硅基光互连的研究,已成功研制出光互连交换芯片,并提出通过光互连解决存储瓶颈的有效解决方案.研究结果表明,在相同功耗的前提下,10 Gbit/s调制速率的光互连访存带宽比目前最快的DRAM访存带宽提升了10倍以上.
1.1.3通信
大数据应用的一个显著特点是节点之间数据交互频繁,互连通信成为大数据应用的性能瓶颈.考虑到大数据的海量特性,一般采用多种存储模式来支持数据存储,如分布式共享存储、集中存储FC-SAN/IP-SAN等.而大数据应用数据通信量较大且数据通信较为频繁,节点之间及节点与存储设备之间的互连带宽成为数据处理的瓶颈.因此,展开新的互连通信技术的研究变得尤为迫切.
为了提高节点之间的通信带宽,可以采用以下两个策略:一是设计软硬件结合的多接口网络芯片,采用用户级别定义和零数据拷贝技术减少数据传输的延迟,该技术已被应用到多个超级计算机中;二是光互连技术为解决数据传输难题提供了新的契机.硅基光通信以波分多路复用的激光束为信息载体,通过控制电光调制器上的光学效应加载数字信号,经光波导管与光子开关的光速传输与路由,利用光电解调效应还原电信号,实现了片内高效数据传输.与传统金属互连介质相比,这种光互连方式具有天然的优势,主要体现在不受距离影响的信号速率、基于波分复用的高带宽通信以及接近零功耗的波导管传输等方面.英特尔与IBM科学家已经利用日渐成熟的硅基光子集成技术,在单颗芯片内成功集成了光波导管、电光调节器、光电解调器、光子开关等新型纳米器件.光互连技术将有望解决数据中心芯片之间的海量数据通信问题.
1.2软件架构
1.2.1数据存储
大数据包含大量的结构化数据、半结构化数据和非结构化数据.结构化数据可以采用数据库结构存储,而半结构化和非结构化数据需要多种文件系统协调配合来存储不同的大数据.超级计算机进行高性能计算和大数据分析是两个完全不同的过程.执行高性能计算过程时,数据加载完毕后,不需要频繁地与文件系统交互,因而单一分布式文件系统即可满足要求.而对于大数据应用,数据的处理过程多种多样,如批处理、流处理、图处理等多类不同的处理过程,都需要不同文件系统的支持.因而,基于超级计算机的大数据处理平台需要采用灵活多变的文件系统,以自适应的形式满足多类复杂大数据应用.
非结构化数据的存储方式一般为分布式文件系统.Google公司因业务需求提出GFS文件系统[8],通过应用层协助分离控制流和数据流以提升集群横向扩展能力,实现对海量数据的高效可靠存储.GFS由一个主控服务器、多个块服务器(chunk server)和客户端构成. 在GFS中文件被划分为64 MB大小的chunk,由唯一的chunk句柄标识,块服务器以普通的Linux文件形式将chunk存储在磁盘中,为了保证可靠性,chunk会在不同的节点中复制多份,默认为3份.通过主控服务器维护系统的元数据信息,包括文件及chunk命名空间、文件到chunk之间的映射、每个chunk副本的位置信息.所有元数据都保存在Master服务器的内存中.基于GFS文件系统的思想,已有研究者构建了多个改进的文件系统.Apache构建了类GFS系统的HDFS分布式文件系统[9],阿里巴巴公司自主开发了分支ADFS[10],主要解决的是HDFS NameNode在设计上存在的单点故障、内存瓶颈以及因集群重启时间过长而无法对集群进行写操作等问题.ADFS的原理是将非热点数据保存到外部数据库而非常驻于NameNode内存中.清华大学和阿姆斯特丹自由大学合作研发的CloudTPS系统[11]能够为分布式应用提供存储支持.
对于结构化数据和半结构化数据,存储方式主要为数据库和分布式表结构.对于简单的半结构化数据可以采用Key/Value分布式文件系统存储,Key/Value为分布式表格的一种.Amazon公司基于电子消费类应用行为特征构建高可用和高可伸缩的分布式存储系统Dynamo[12],该系统采用Key/Value方式存储数据,并采用数据分块最终一致性和一致性哈希等技术为上层应用提供Always-on体验,同时保持高可用和横向扩展能力.早期由Facebook开发的Cassandra系统[13]借鉴不同研究成果以Key/Value方式构建分布式存储平台,从而提供更好的扩展性和一致性.由于大数据应用的数据量大和实时处理的需求,使得传统数据库(如MySQL,PostgreSQL)已经无法满足用户对于结构化数据存储的系统需求. Google公司提出BigTable分布式类数据库系统[14],引领了NoSQL潮流,这种存储方案被用于Google公司内部多个项目中,如搜索系统的海量数据存储、用户请求的日志管理等,支持公司的大数据产品.之后在存储领域涌现了增量索引平台Percolator[15]和全球级分布式数据库Spannor[16]等.HBase数据库[17]基于BigTable的设计思想,在HDFS的基础上构建,能提供较为接近传统数据库的支持.OceanBase数据库[18]是阿里巴巴公司自主研发的可扩展的关系型数据库,实现了跨行和跨表的事务支持,能够在数千亿条记录、数百TB数据上进行传统SQL操作.
在分布式存储管理方面也出现了一些典型的系统.Memcached系统[19]是一种高性能的分布式内存缓存服务系统,最初由Danga Interactive为了LiveJournal所发展,目前已被mixi,hatena,Facebook,Vox,LiveJournal等公司广泛采用,用以提高Web应用扩展性.Redis数据库[20]是一种非关系型内存数据库,采用与Memcahed,Redis类似的键值存储,可以达到很好的存储性能.RAMCloud技术[21]是由斯坦福大学的John Ousterhout在2009年提出的基于内存的存储管理技术.鉴于面向磁盘的在线存储存在诸多问题,如扩展性、性能瓶颈,RAMCloud技术采用的解决方法是建立一个以DRAM为主的数据存储中心,将所有的信息都保存在DRAM中,利用商业服务器集群构成一个大规模存储系统.与磁盘的存储系统相比,该系统至少能提高100~1 000倍的带宽和100~1 000倍的低延迟.
1.2.2编程模型
大数据应用同样给编程模型带来了新的挑战.这些挑战主要来自编程简单性与性能优化之间的冲突.为了编程的简单性,编程模型应为开发人员提供一个简洁而强大的编程抽象,使开发人员可以轻松地编写能在成百上千台计算机上并行执行的程序,开发人员只需关注要解决的问题,不需要关心应用程序在大规模集群上运行的细节(如数据分布、调度任务和处理容错等).编程模型对开发人员隐藏这些细节,有助于应用程序清晰地表达对数据的处理过程,使代码更容易理解、重用和维护,从而最大程度地减轻了开发人员编程的负担.而对于编程模型的性能优化而言,编程模型通常管理整个集群的资源,除了要保证应用程序在大规模集群上能够高效率、高可靠和可扩展地运行,还要允许多个作业并发运行、共享集群资源,以提高整个集群的资源利用率和作业的吞吐量.在大规模集群系统上高效地实现一个编程抽象会面临很多挑战.例如,如何尽量利用数据本地性以减少网络传输,如何解决机器的异构性问题,如何保证作业之间的公平性等.在设计编程模型的任务调度和作业调度时,通常需要考虑多种因素并作出权衡折中.因此,针对大数据应用的需求,设计高效、简洁、可靠的并行编程模型也是一大挑战.
超级计算机一般采用OpenMP,MPI等并行编程模型.OpenMP采用共享存储模式,适用于对称多处理器(symmetrical multi-pocessing,SMP)、分布式共享内存(distributed shared memory,DSM)等架构的机器.MPI是基于消息传递的计算模型,编程模型较复杂,需要程序员自行分析及划分应用程序问题,并将问题映射到分布式进程集合.可见这两种编程模型并不适用于大数据应用.因此,若干互联网公司都各自研发了应用于大数据处理的编程模型,以解决上述各种挑战性问题.
MapReduce系统是Google公司面向PB规模级数据提出的基于数据进行并行计算的模型,它提供了简单的API接口,能够自动进行并行化、容错处理、数据切分等工作,简化了大数据并行程序的编写.MapReduce系统主要由两部分组成:Map和Reduce. MapReduce的核心思想在于“分而治之”,也就是说,先将数据源分为若干部分,每个部分对应一个初始的键值(Key/Value)对,并分别由不同的Map任务区处理,产生一系列中间结果键值(Key/Value)对,MapReduce的中间过程Shuffle将所有具有相同Key值的Value值组成一个集合传递给Reduce环节;Reduce接收这些中间结果,并将相同的Value值合并,形成最终的较小Value值的集合.而面向超级计算机的异构平台,MapReduce计算框架仍需要改进.Mars框架[22]是由香港科技大学研究人员提出的最早的基于单GPU节点实现的MapReduce计算框架.而后,MapCG[23],Grex[24],Mithra[25],GPMR[26]等对MapReduce进行了大量改进工作,充分发挥了大量的GPU集群节点的优势,同时利用共享内存等技术减少了CPU与GPU之间的I/O数据传输延迟.MrPhi[27]首先实现了在单MIC节点的MapReduce框架,而后扩展到了MIC集群中[28].
同时,在新型的内存计算体系结构中,现有的MapReduce并不能充分利用大规模的异构内存,从而难以控制和有效利用数据的局部性.为了将中间数据保存在内存而非外存中,以避免过多的内外存I/O,加州大学伯克利分校的研究人员提出了可恢复分布式数据集(resilient distributed datasets,RDDs)[29]来抽象分布式内存系统,并且利用RDDs实现了Spark内存计算系统.Phoenix[30]是斯坦福大学研究人员开发的基于多核/多处理器、共享内存的MapReduce实现,其目标是在多核平台上,使程序执行得更高效,而且使程序员不必关心并发的管理.在大数据处理应用中,不少场景存在依赖关系的作业,比如Pig[31]和Hive[32]产生的MapReduce作业.为优化依赖作业对磁盘和网络I/O操作效率,Hortonworks开发了DAG计算框架Tez[33].该框架的核心思想是将Map和Reduce两个操作分成更小的元操作,可以灵活组合产生新的操作,并经控制程序组装后形成大的DAG作业.
综上所述,大数据应用给超级计算机带来了软件、硬件结构等方面的挑战,而目前学术界和工业界针对这些挑战提出了各种各样的解决方案,并取得了一定的成果.
2 天河二号超级计算机的大数据求解之道
下面将以天河二号超级计算机(以下简称天河二号)为例,分析在大数据时代下超级计算机应采取哪些优化措施应对大数据处理带来的挑战.针对大数据处理,天河二号采用的优化措施包括互连通信优化、I/O增强及软件栈增强等技术.目前,天河二号计算机系统的互连通信已升级成TH-Express 2+高速网络技术,该通信网络能提供更高的通信性能和TCP/IP协议数据传输性能[34-35].在I/O系统中,通过部署混合的存储结构和层次式的文件系统来提高I/O吞吐能力.在天河二号上提供异构MapReduce并行处理框架,支持CPU和MIC的混合MapReduce处理能力.
天河二号超级计算机系统在国家高技术研究发展计划(863计划)的支持下,由国防科学技术大学研制,广东省及广州市政府提供了研制经费和配套设施支持.天河二号峰值计算速度达5.49亿亿次/s,持续计算速度达3.39亿亿次/s,能效比达到每瓦19亿次双精度浮点运算.天河二号的定位是同时满足高性能计算、高吞吐率信息服务和海量数据处理等多领域复杂应用需求,在系统设计过程中,专门针对大数据领域的应用特征进行了多项体系结构调优,包括I/O增强、软件栈增强、通信协议增强及并行处理模式优化等.
2.1计算节点优化——异构多态体系结构
天河二号的计算阵列共16 000个计算节点,每个计算节点包含2个Intel Xeon处理器和3个MIC众核协处理器.节点通过自主设计的网络接口芯片(network interface chip,NIC)连接到高速互连网络.节点包含4个高速PCIE总线,其中3个连接MIC,一个连接NIC. CPU和MIC众核协处理器都基于X86架构,具有相似的指令集架构,因此能够支持统一的编程模型,本研究将此混合架构设计为“微异构计算体系结构”.CPU和MIC众核协处理器协同计算,既可以提高系统的能效比,又能保证应用程序的兼容性、适用性和易用性.
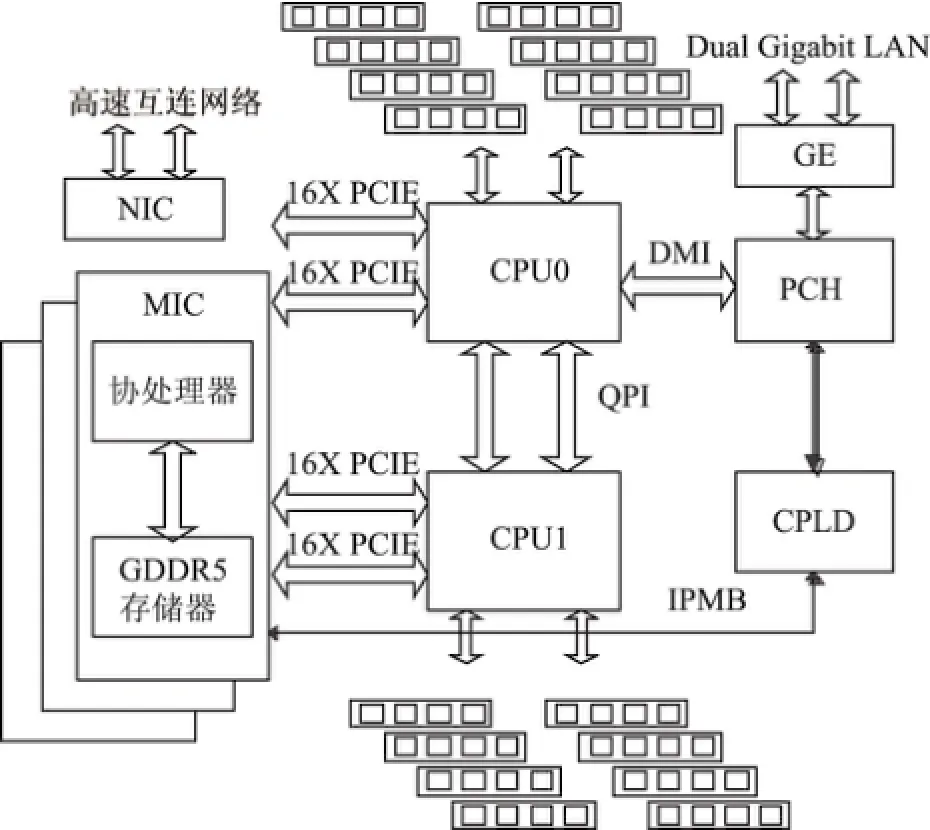
图1 计算节点逻辑结构Fig.1 Computing node structure
计算节点逻辑结构如图1所示,2个CPU通过两路QPI信号直接连接,每个CPU设计4个通道,共8个DIMM插座,如果采用16 GB内存条,最大可支持128 GB DDR3内存. CPU0通过PCH(platform controller hub)芯片进行外围扩展,引出一个PCIE 16X接口连接自主研发的高速互连网络接口芯片NIO,同时引出一个PCIE 16X接口连接MIC众核协处理器.CPU1引出2个PCIE 16X接口连接2个MIC众核协处理器.每个节点连接3个MIC众核协处理器.
基于商用CPU的计算节点采用主频2.2 GHz的Ivy Bridge CPU,集成12个处理器核,单核支持256位宽的SIMD操作(4个双精度浮点操作),直接在CPU内部集成PCIE控制器,集成4通道DDR3存储控制器,提供2个传输率为8 GT/s的QPI接口,支持2路处理器直连构成SMP系统,同时采用高级向量扩展(advanced vector extensions,AVX)指令集,在性能得到大幅提升的同时保持了更高的访存、通信和I/O带宽.
MIC协处理器包含57个物理核,运行频率为1.1 GHz,单核支持512位宽的SIMD操作(8个双精度浮点操作),同时支持FMA三元乘加操作,双精度浮点峰值性能达到了1.003 TFlops.
2.2网络通信优化——TH-Express 2+
TH-Express 2+互连通信网络主要由两种芯片组成:一种是网络接口芯片(NIC),NIC提供了主机系统软硬件编程接口.相对于上一代互连,NIC的端口速率提高到了14 Gbit/s,并且在功能上进行了扩展,进一步提高了消息速率和数据传输的可靠性,为提高并行应用的性能和运行稳定性提供了良好的支持.另一种是网络路由芯片(network router chip,NRC),NRC采用高阶路由设计技术,内部集成了24个端口,吞吐率达到5.376 Tbit/s.NRC支持两种路由协议,即显式路由和基于胖树的多路径自适应路由,可以在大规模部署条件下,减少网络拥塞冲突,提高互连网络的吞吐率.
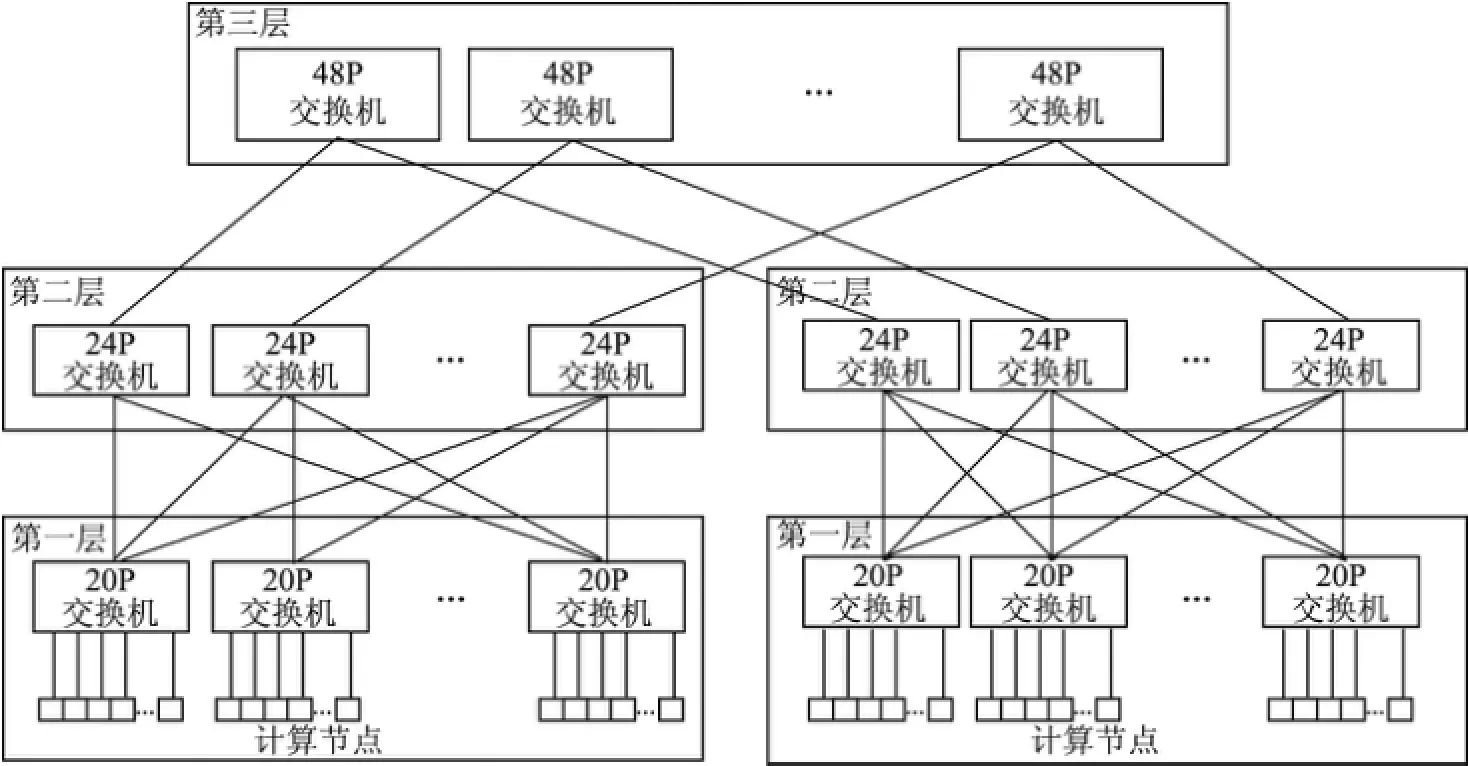
图2 TH-Express 2+网络互连拓扑图Fig.2 TH-Express 2+network topology
TH-Express 2+互连网络实现为三层胖树拓扑结构(见图2).采用这种拓扑结构的原因是,胖树能获得很高的双向带宽,使每个节点的双向带宽等于节点的注入带宽.在第一层中,以32个计算节点作为计算框,接入一块被称为NRM的交换板上,形成一级子树,NRM板上行方向通过20个端口连接叶交换机;在第二层中,叶交换机由一个24口交换板构成,其中下行12个光模块接口接入12个计算框,上行12个光模块接口接入根交换机.从叶交换机角度来看,上行链路和下行链路带宽相等,构成带宽均衡的层次结构;在第三层中,根交换机由两个24口交换板构成48端口交换机,每个根交换机连接到48个不同的叶交换机上.叶交换机和根交换机通过一个独立的路由机柜连接在一起.
在TH-Express 2+互连网络的硬件协议层次中集成了多种通信协议,使得并行应用、网络服务、云平台服务和大数据应用能够同时运行在天河二号之上.天河二号上的MPI并行编程环境符合MPI 3.0标准.通过系统实现中采用的一些协议优化技术,有效提高了并行应用的可扩展性.在实际性能测试中,MPI的点到点通信延迟少于1µs,带宽达到12 Gbit/s,而双向带宽则达到23 Gbit/s,这为提高大数据并行应用的运行效率提供了良好的支持.
在TH-Express 2+网络体系结构中,底层为基于RDMA[36-37]的物理网络结构.为了满足大部分企业应用,尤其是大数据应用,TH-Express 2+专门设计了针对TCP/IP协议的支持机制,以实现在物理节点或虚拟节点之间提供基于TCP/IP的高带宽通信机制.TH-Express 2+ 在RDMA物理网络基础设施之上虚拟了一套层叠的网络通信机制,采用mixed-up和poll packets接收方法高效处理报文.同时,通过地址主动注册/地址单播查询机制替代ARP广播,从而在很大程度上提高了大规模二层网络环境下的网络整体性能.另外,在进行TCP/IP传输过程中,将TSO[38]数据作为一个整体通过底层的RDMA机制进行传输,进一步提高了单播通信的处理能力.因此,对于单个通信流,可获得高达42 Gbit/s的TCP/IP实测带宽.

图3 基于TH-Express 2+的TCP/IP协议Fig.3 TH-Express 2+TCP/IP protocol
RDMA物理层承载多个层叠的虚拟网络,不同的层叠虚拟网络可用于不同目的,如用于虚拟节点的资源管理和控制、虚拟节点间的业务通信等.最上层通过虚拟化技术和层叠的虚拟网络承载了大量的虚拟机,而大数据应用和企业应用运行于虚拟机内.层叠虚拟网络可以使单个物理节点获得高达42 Gbit/s的TCP/IP实测带宽,而单个虚拟节点可获得高达10 Gbit/s的TCP/IP实测带宽,也就是说,即使是虚拟节点间的通信也获得了万兆网络的通信能力.在第二层互连网络中,可管理的节点规模超过了8 000个,可很好地满足云计算大二层网络[39]的要求,更有利于资源的弹性分配和调度.
基于TH-Express 2+的TCP/IP协议具有以下特征:①高性能.如前文所述,所采用的广播消除技术使得ARP地址查询对大规模网络的影响尽可能小.采用RDMA直接承载TSO数据,将一次TSO数据作为整体发送,这大大提高了TCP的传输能力,使得物理节点间可获得42 Gbit/s的单流TCP性能,虚拟节点间可获得10 Gbit/s的单流TCP性能.②高可用性.尽管从用户角度来看,承载网络的基础设施非常类似于互联网,但是其内部却采用了不同的工作机制.为了获得高可用性,对虚拟化设备如虚拟交换机,采用主备的方式进行容错.当出现失效时,计算节点将重新向备用虚拟交换机注册单播地址和多播成员关系,以恢复网络基础信息.③灵活性.通过虚拟网络分区技术,不同的层叠网络可独立地按需创建,并根据应用选择满足自身需求的层叠网络参数,灵活的网络创建机制可满足多种应用的承载需求.
2.3存储结构优化——混合层次式文件系统
大数据和超级计算应用都驱动着I/O的发展,使得I/O瓶颈变得尤为突出.传统基于对象存储架构的Lustre文件系统是一款被广泛采用并部署的开源并行文件系统,其特点突出,但无法完全满足各类科学计算应用和大数据应用的多样性I/O需求.在大数据时代,需要增强超算系统现有的存储架构,并采用新的并行I/O技术.因此,其他一些新颖的存储机制也已部署到天河二号上,如Flash,NVM等.很明显,用一种并行的文件系统满足所有的应用并不现实,要采用更多灵活的I/O存储文件系统来满足不同的大数据应用需求.
如图4所示,天河二号系统部署了一种混合的、层次式存储结构,将6.4 PB的本地磁盘用于大数据应用,由512 TB的SSD盘组成过渡存储层.该存储结构用于数据密集型的应用,读写速度达到了1 Tbit/s;而128个集中存储服务器负责I/O输出,读写速度达到了100 Gbit/s. SSD快速存储能提供相当高的I/O性能,能很好地平衡计算和存储服务器的I/O需求.

图4 混合存储结构Fig.4 Hybrid storage structure
基于混合存储结构,在天河二号系统中设计实现了混合层次式文件系统(hybrid storage structure,H2FS),该文件系统融合分布的局部存储资源和基于对象存储架构的共享全局存储资源,充分利用ION(I/O服务节点)的本地存储,能满足应用程序瞬时I/O操作的性能需求,并将其和全局存储系统构建成一个统一的命名空间,使用户获得多类型存储介质的好处,并同时保持使用方式的兼容性.
图5给出了H2FS结构的关键组件,其中最基本的组件是一个用户级RDMA通信协议,用于I/O数据传输.在TH-Express 2+网络上,该组件具有较好的RPC率,使得SSD的性能优势得以充分利用.另外一个组件是混合虚拟命名空间模块(HVN),它能够在任务运行时动态构建轻量化的I/O软件栈,针对不同应用场景的I/O特点,例如写密集型、读密集型、元数据密集型、小文件或者大文件等特定需求,分别使用相应的优化方法,有效地加速不同应用的I/O过程,这种方法有利于解决在大规模并发条件下复杂I/O栈开销过大、扩展性受限等问题.
2.4混合计算框架优化—-异构Map/Reduce框架
随着高性能协处理器的迅速发展,针对异构硬件平台的MapReduce框架在学术界和工业界被广泛研究和使用.针对天河二号的异构结构,本研究优化设计了MapReduce框架——MicMR[40](见图6),使其成为目前第一个支持MIC的大规模数据并行处理框架.考虑系统的缩放性和效率,设计了能管理不同资源的CPU worker和MIC worker.MIC worker承担着以下两部分工作:①负责分发新任务到MIC上;②接收来自MIC的计算结果.由于CPU和MIC具有不同的计算效能,因此所有计算单元动态获取任务,以达到负载均衡.
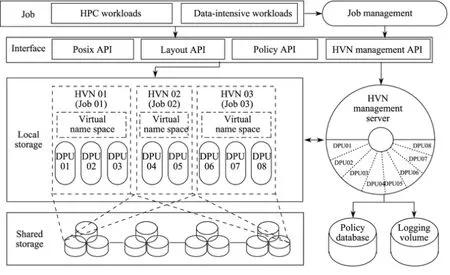
图5 H2FS结构Fig.5 H2FS structure

图6 异构的Map/Reduce框架Fig.6 Heterogeneous Map/Reduce framework
Reduce worker以并行模式工作,故能够支持map和reduce同时工作.另外,本研究设计了一种MIC令牌机制,令牌能随着MIC协处理器的状态而动态改变.若MIC协处理器出现失效,相对应的令牌也会删除,以此有效管理MIC协处理器.
为了更有效率地利用MIC,本研究设计了友好的SIMD映射模型,该模型能更充分地利用MIC上的VPUs.模型中的每个数据块被划分成一个向量,该向量能被VPUs以SIMD的处理模式进行处理.在这个过程中,采用两种存储缓存方式来存储MIC计算后的中间结果:一种是阵列缓存,这种缓存模式采用独立的存储区域,线程同步没有线程锁,也不支持原子操作;另一种是组合缓存(combine buffer),对于计算结果的存储,所有数据块共享相同的存储区域.实验结果显示,reduce过程能得到1.1~1.4倍的加速,而SIMD友好映射过程能得到1.0~8.2倍的加速.与常规的Hadoop相比,不同应用在天河二号上能获得2.4~8.1倍的加速.
3 结束语
目前,天河二号超级计算机在高性能计算领域已经取得了很好的效果,随着海量应用在天河二号上聚集,不可避免地会有大量大数据应用要部署在超级计算机中,构成一个大的数据中心.首先,通过对应用的深入了解,可以更好地利用已有的系统,如空气动力学、生物工程、大数据等,都已经取得了很好的效果;其次,为了满足大数据应用,大数据时代的超级计算机可能融入更多新兴的体系结构,如众核/多核、快速存储/NVM等;再次,更高性能的互连网络能有效解决超级计算机部署大数据应用时的网络带宽瓶颈,包括可重构网络拓扑技术和最优网络互连技术等.此外,为了满足更多大数据应用,层次式的I/O结构也将成为超级计算机的另一个新的技术储备.总之,在大数据时代,超级计算机的计算类型将由计算密集型逐渐转向数据密集型,对其上数据及数据生命周期的管理变得尤为重要.
[1]Big data and big data analytics:significance for the hardcopy industry[EB/OL].[2015-10-19]. http://www.idc.com/getdoc.jsp?containerId=246831.
[2]IDC's worldwide big data taxonomy[EB/OL].[2015-10-19].http://www.idc.com/getdoc. jsp?containerId=254052.
[3]Graph500[EB/OL].[2015-10-19].http://www.graph500.org.
[4]JING N F,SHEN Y,LU Y,et al.An energy-efficient and scalable eDRAM-based register file architecture for GPGPU[C]//Processing of International Symposiumon Computer Architecture. 2013:344-355.
[5]LAM C H.Storage class memory[C]//Processing of 2010 10th IEEE International Conference on Solid-State and Integrated Circuit Technology(ICSICT).2010:1080-1083.
[6]DHIMAN G,AYOUB R,ROSING T.PDRAM:a hybrid PRAM and DRAM main memory system[C]//Processing of Design Automation Conference.2009:664-669.
[7]HAM T J,CHELEPALLI B K,NENG X,et al.Disintegrated control for energy-efficient and heterogeneous memory systems[C]//Processing of IEEE International Symposium on High Performance Computer Architecture.2013:424-435.
[8]GHEMAWAT S,GOBIOFF H,LEUNG S T.The google file system[C]//Processing of ACM SIGOPS Operating Systems Review.2003:29-43.
[9]HDFS[EB/OL].[2015-10-19].http://hadoop.apache.org/hdfs/docs/current/hdfs design.html.
[10]ADFS[EB/OL].[2015-10-19].http://github.com/taobao/ADFS.
[11]ZHOU W,PIERRE G,CHI C H.Scalable transactions for web applications in the cloud[J].Lecture Notes in Computer Science,2009,5(4):525-539.
[12]DECANDIA G,HASTORUN D,JAMPANI M,et al.Dynamo:amazon's highly available key-value store[J].Proc Sosp,2007,41(6):205-220.
[13]Cassandra[EB/OL].[2015-10-19].http://cassandra.apache.rog.
[14]CHEN C,HSIAO M.Bigtable:a distributed storage system for structured data[C]//Proceedings of OSDI.2006:205-218.
[15]PENG D,DABEK F.Large-scale incremental processing using distributed transactions and notifications[C]//Usenix Symposium on Operating Systems Design and Implementation.2010:4-6.
[16]COOPER B F.Spanner:Google's globally-distributed database[C]//Proceedings of the 6th International Systems and Storage Conference.2013:1-10.
[17]Hbase[EB/OL].[2015-10-19].http://hbase.apache.org/.
[18]OceanBase[EB/OL].[2015-10-19].http://alibaba.github.io/oceanbase.
[19]Memcached[EB/OL].[2015-10-19].http://www.memcached.org/.
[20]Redis[EB/OL].2013-03-25[2015-10-19].http://www.redis.io/.
[21]OUSTERHOUT J,AGRAWAL P,ERICKSON D,et al.The case for RAMCloud[J].Communications of the Acm,2011,54(7):121-130.
[22]HE B S,FANG W B,LUO Q,et al.Mars:a MapReduce framework on graphics processors [C]//Processing of 17th International Conference on Parallel Architectures and Compilation Techniques(PACT).2008:260-269.
[23]HONG C T,CHEN D H,CHEN W G,et al.MapCG:writing parallel program portable between CPU and GPU[C]//PACT.2010:217-226.
[24]BASARAN C,KANG K D.Grex:an e cient Map/Reduce framework for graphics processing units[J].Journal of Parallel and Distributed Computing,2013,73(4):522-533.
[25]FARIVAR R,VERMA A,CHAN E M,et al.MITHRA:multiple data independent tasks on a heterogeneous resource architecture[C]//Processing of IEEE Conference on Cluster Computing. 2009:1-10.
[26]STUART J A,OWENS J D.Multi-GPU MapReduce on GPU clusters[C]//IPDPS.2011:1068-1079.
[27]LU M,ZHANG L,HUYNH H P,et al.Optimizing the Map/Reduce framework on intel xeon phi coprocessor[C]//2013 IEEE International Conference on Big Data.2013:125-130.
[28]LU M,LIANG Y,HUYNH H,et al.Mrphi:an optimized Map/Reduce framework on intel xeon phi coprocessors[J].IEEE Transactions on Parallel and Distributed Systems,2015,26(11):3066-3078.
[29]ZAHARIA M,CHOWDHURY M,DAS T,et al.Resilient distributed datasets:a fault-tolerant abstraction for in-memory cluster computing[C]//Proceedings of the 9th USENIX Conference on Networked Systems Design and Implementation.2012:141-146.
[30]YOO R M,ROMANO A,KOZYRAKIS C.Phoenix rebirth:scalable Map/Reduce on a largescale shared-memory system[C]//Proceedings of IEEE International Symposium on Workload Characterization.2009:198-207.
[31]GATES A F,NATKOVICH O,CHOPRA S,et al.Building a high-level dataflow system on top of Map-Reduce:the Pig experience[C]//Proceedings of the VLDB Endowment 2.2.2009:1414-1425.
[32]THUSOO A,SARMA J S,JAIN N,et al.Hive:a warehousing solution over a map-reduce framework[C]//Proceedings of the VLDB Endowment 2.2.2009:1626-1629.
[33]Taz[EB/OL].[2015-10-19].http://hortonworks.com/blog/introducing-tez-faster-hadoopprocessing/.
[34]PANG Z B,XIE M,ZHANG J,et al.The TH Express high performance interconnect networks[J].Frontiers of Computer Science,2014,8(3):357-366.
[35]LIAO X K,PANG Z B,WANG K F,et al.High performance interconnect network for Tianhe system[J].Journal of Computer Science and Technology,2015,30(2):259-272.
[36]HUANG W,GAO Q,LIU J,et al.High performance virtual machine migration with RDMA over modern interconnects[C]//2007 IEEE International Conference on Cluster Computing.2007:11-20.
[37]GAVRILOVSKA A,KUMAR S,SUNDARAGOPALAN S,et al.Platform overlays:enabling in-network stream processing in large-scale distributed applications[C]//Proceedings of the International Workshop on Network and Operating Systems Support for Digital Audio and Video.2005:171-176.
[38]REGNIER G,MAKINENI S,ILLIKKAL R,et al.TCP onloading for data center servers[J].Computer,2004(11):48-58.
[39]ZHANGQ,CHENGL,BOUTABAR.Cloudcomputing: state-of-the-artandresearch challenges[J].Journal of Internet Services and Applications,2010,1(1):7-18.
[40]WANG W Z,WU Q B,TAN Y S,et al.Optimizing the MapReduce framework for CPU-MIC heterogeneous cluster[C]//2015 International Conference on Advanced Parallel Processing Technology.2015:33-44.
On the challenge for supercomputer design in the big data era
LIAO Xiangke,TAN Yusong,LU Yutong,XIE Min,
ZHOU Enqiang,HUANG Jie
(School of Computer,National University of Defense Technology,Changsha 410073,China)
Because traditional supercomputer is designed for high-performance computing,big data processing applications brings some software and hardware challenges including compute,storage,communication and programming.This paper introduces optimization methods of Tianhe-2 supercomputer system to process big data,such as a new heterogeneous polymorphic architecture,custom high-speed TH-Express 2+interconnection network,hybrid hierarchical storage system and hybrid computing pattern framework.These efforts maybe make help for how to design supercomputers in the age of big data.
big data;supercomputer;Tianhe-2
TP 338
A
1007-2861(2016)01-0003-14
10.3969/j.issn.1007-2861.2015.03.014
2015-12-23
国家高技术研究发展计划(863计划)资助项目(2013AA01A212)
廖湘科(1963—),男,教授,中国工程院院士,博士生导师,研究方向为超级计算机. E-mail:xkliao@nudt.edu.cn
猜你喜欢
凤凰动漫(军事大王)(2022年9期)2022-11-05
中国水利(2022年1期)2022-02-13
科技传播(2019年22期)2020-01-14
北方音乐(2019年13期)2019-08-21
当代陕西(2019年13期)2019-08-20
中国教育网络(2018年7期)2018-08-10
中国计算机报(2018年42期)2018-01-31
空中之家(2017年11期)2017-11-28
电脑爱好者(2015年21期)2015-09-10
湖南水利水电(2015年4期)2015-02-27
