
K-L变换语音波形编码算法研究
2016-09-13 07:25李小航姜占才
电子设计工程 2016年3期
李小航,姜占才
(青海师范大学 物理系,青海 西宁 810008)
K-L变换语音波形编码算法研究
李小航,姜占才
(青海师范大学 物理系,青海 西宁810008)
为了有效改善解码语音的质量,提出了一种K-L变换语音波形编码算法。由语音帧构造协方差矩阵,并对其进行特征值分解,得到特征值及其对应的特征向量,由特征向量构造正交矩阵;用正交矩阵对语音帧作正交变换得到变换系数向量;选取适当特征值对应的特征向量构造重构矩阵;用重构矩阵对变换系数向量作逆变换得到增强后的语音信号;对增强后的语音抽取并传输至解码端;通过插值技术重构语音信号。在不同信噪比下对不同语音样本进行仿真实验,并同离散余弦变换编码比较,实验表明,该算法不仅数据压缩率高、解码语音清晰和自然,而且同时实现语音良好的自适应增强。
语音;K-L变换;离散余弦变换;波形编码;自适应增强
随着数字通信技术、多媒体技术和数字信号处理技术的飞速发展,高音质、低码率的语音编码方法显得尤为重要。近几十年来,人们对数字化语音压缩编码做了大量研究工作,取得了显著的成果。经研究发现,直接对线性PCM码流存储和传输存在很大程度的信息冗余,至少可以对数字语音进行4倍的压缩[1]。为了更有效利用信道资源,人们提出许多数字语音压缩编码算法。
语音编码大致分为波形编码、参数编码和混合编码三类。波形编码技术以尽可能重构语音波形为原则进行数据压缩,即在编码端以波形逼近为原则对语音信号进行压缩编码,解码端根据这些编码数据恢复出语音信号的波形。它具有语音质量好、抗噪声性能强等优点,所需的码率一般在64~16kbps之间。在 8 kHz采样、8 bit量化时,PCM、ADM和ADPCM等编码器分别在64~16 kbps的速率上获得了高的编码质量[2-3]。语音信号的频域非线性波形编码采用的是分段离散傅里叶变换,在获得大压缩比的情况下,仍能保留原始语音信号的细节特征[4]。语音信号经过小波分解后低频分量和高频分量的语音自适应压缩编码,也取得了一定的成效[5-6]。利用离散余弦变换后的语音信号能量主要集中在低频段的特点,对语音进行压缩编码,其算法原理简单,且有快速算法,被广泛采用[7],但它不能实现帧间自适应。本文提出的KL变换语音波形编码算法,不仅算法简单、压缩率高、解码语音清晰、自然,而且由于具备帧间自适应性,能方便、有效地实现语音的自适应去噪。
1 K-L变换及其编码原理
1.1K-L变换
信号 x=[x(1),x(2),…,x(N)]T,其协方差矩阵 Cx定义为:

由λ的N阶多项式:|λI-Cx|=0求协方差阵Cx的特征值λ1,λ2,…,λN再由式
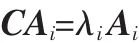
求协方差矩阵Cx的N个特征向量A1,A2,…AN,并将其归一化。构造正交矩阵A,即

计算y=Ax实现对信号x的K-L变换。
重构信号就是解逆变换,由下式完成

对x(n)去除噪声,直接对x的变换y截取即可,即

1.2K-L变换语音编解码算法原理
将语音信号分成长度为160点的语音帧x(n),去直流后按(1)式构造协方差矩阵Cx,作特征值分解,构造正交变换矩阵A;用A对x(n)作K-L变换得到变换后的信号y,将y按(3)式进行截取得到信号y’;将y’按式(2)进行K-L逆变换重构语音信号x;将重构语音x抽取为N点并对其编码传输到解码端;在解码段通过插值技术恢复为160点的语音帧,通过帧间拼接技术,合成出语音。
2 离散余弦变换及其编码原理
2.1离散余弦变换(DCT)
Ahmed和Rao于1974年首次给出了离散余弦变换的定义。给定序列x(n),n=0,1,…,N-1,其离散余弦变换的定义为:
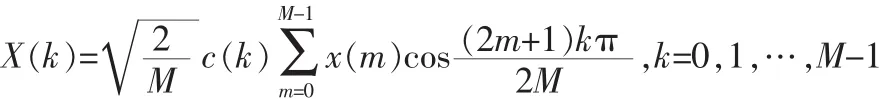
逆变换定义为:

DCT的各行各列基向量均是正交归一化的。语音信号经过DCT变换后较大的系数集中在低频区域,较小的系数则集中在高频区域,具有很好的能量压缩性能,如图1所示。因此用部分DCT系数表示全部语音信号,可对数字化的语音信号进行压缩编码。
2.2离散余弦变换编码原理
语音信号属于非平稳随机信号,大量研究结果表明,语音信号具有短时平稳性。语音的特征参数在短时内基本保持不变,如短时过零率、短时能量及基音周期等。利用语音信号的短时平稳性的特点,将语音信号分成160点(20 ms)的语音帧,每次仅对一帧语音信号进行离散余弦变换,再利用离散余弦变换后语音信号的能量主要集中在低频段的特点,去掉高频段的变换系数而只传输低频段的变换系数。

图1 一帧语音信号的DCTFig.1 DCT of a frame speech signal
具体实现步骤:对一帧语音信号进行离散余弦变换后,根据语音信号能量在频域的集中性,取低频区域较大的变换系数值,舍去高频区域较小的变换系数值,只对较大的变换系数值进行编码;解码端通过离散余弦逆变换恢复原始语音信号。
3 算法仿真实验
3.1实验方案
实验分五组进行:1)对同一语音样本在一定的信噪比(13 dB)下,分别用离散余弦变换和K-L变换两种算法进行2倍压缩编码仿真实验;2)对同一语音样本在不同信噪比(13 dB和10 dB)下,分别用离散余弦变换和K-L变换两种算法进行2倍压缩编码实验仿真;3)对同一语音样本在一定的信噪比(13 dB)下,分别用离散余弦变换和K-L变换两种算法进行4倍压缩编码仿真实验;4)对同一语音样本在不同信噪比(13 dB和10 dB)下,分别用离散余弦变换和K-L变换两种算法进行4倍压缩编码实验仿真;5)在同一信噪比(10 dB)下,对同一语音样本分别对离散余弦变换和K-L变换4倍压缩编码的解码语音进行基音周期轨迹分析。
3.2实验材料(语音样本)
实验用的语音取自笔者的导师建立的语音样本库。其语料为诗词、短句和文章,录制转换后的数字语音均为8 kHz采样、8 bit量化、线性PCM码。语音样本库的容量是186 MB。实验时用的语音是从样本库中挑选的诗词和短句,加入高斯白噪声后形成带噪的语音。实验用的语音样本帧长、帧移均取160点,帧间无重叠。
3.3实验程序
文中提出的算法按图1的算法原理用matlab语言编程,以文件名klt_encode.m存储;同时,对离散余弦变换编码算法编程,以文件名dct_encode.m存储;在计算机上仿真实验。通过解码语音的波形显示,判定其算法的有效性。
3.4实验结果及分析
3.4.1解码语音波形显示
部分实验结果如图2~5所示。图2是同一语音样本在信噪比为13 dB时,离散余弦变换和K-L变换两种算法进行4倍压缩编码的实验结果。结果显示,对信噪比为13 dB时,KL变换的解码语音波形几乎逼近原始语音波形,而离散余弦变换的解码语音波形稍带有噪声的影响。图3是同一语音样本在信噪比为10 dB时,离散余弦变换和K-L变换两种算法进行4倍压缩编码的实验结果。结果显示,对信噪比为10dB的带噪语音样本,K-L变换解码语音效果明显优于离散余弦变换解码语音的质量。
3.4.2解码语音基音周期轨迹分析
图4是10dB下对语音的特征(基音周期)进行比较,因为基音周期是语音的重要特征,是辨别语义和语者的主要特征之一,也是判定解码语音效果的重要依据,许多语音处理系统都要依赖于基音周期。结果显示,利用K-L变换法解码语音的基音周期轨迹与原始语音基音周期轨迹的走势几乎一致,而DCT解码语音的基音周期轨迹没有K-L变换法解码语音的基音周期轨迹那么平滑,甚至部分帧的周期有减小或消失现象。这是由于DCT处理过程中不能实现帧间自适应导致编码器抗噪能力较差[8]。

图2 13 dB下KLT和DCT解码语音波形Fig.2 Decoding speech waveform with KLT and DCT under 13 dB SNR

图3 10 dB下KLT和DCT解码语音波形Fig.3 Decoding speech waveform with KLT and DCT under 10 dB SNR

图4 10 dB下KLT和DCT解码语音基音周期轨迹Fig.4 Track pitch of decoding speech with KLT and DCT under 10 dB SNR
4 结束语
基于K-L变换的语音波形编码算法,在8 kHz采样、8 bit量化的情况下,比特率为16 kbps,该算法不仅数据压缩率高、解码语音清晰和自然,而且同时实现语音良好的自适应增强。
[1]韩纪庆,张磊,郑铁然.语音信号处理[M].北京:清华大学出版社,2010.
[2]陈溯.ADPCM语音压缩编码的分析与仿真[J].中国西部科技,2008,7(32):52-54.
[3]廖广锐,刘萍.基于ADPCM的语音压缩算法研究[J].计算机与数字工程,2007,35(7):39-41.
[4]戴宪华,黄继武.语音信号的频域非线性波形编码[J].通信学报,1998,19(2):1-6.
[5]刘杰平,余英林.小波域多描述变换编码算法的研究[J].计算机应用,2005,25(2):317-319.
[6]唐力.基于小波分解的语音自适应压缩感知[J].南京邮电大学学报(自然科学版),2012,32(2):64-68.
[7]鲁业频,李凤亭,陈兆龙,等.离散余弦变换编码的现状与发展研究[J].通信学报,2004,25(2):106-118.
[8]朱学涛,张志伟.一种快速DCT变换方法的优化[J].电子科技,2004(9):31-33.
Speech waveform encoding algorithm research based on K-L transform
LI Xiao-hang,JIANG Zhan-cai
(Physics Department of Qinghai Normal University,Xining 810008,China)
In order to effectively improve the quality of the decoded speech,a kind of speech self-adaption enhancement algorithm based on K-L transform is put forward.Covariance matrix is constructed by speech frame vectors;eigenvalues and corresponding to eigenvectors are got by decomposing eigenvalues of covariance matrix,orthogonal matrix is constructed by the eigenvectors;the transform coefficient vector is got by orthogonal transform of frame vectors with orthogonal matrix;through the analysis,selecting the appropriate eigenvalues and corresponding to eigenvectors reconstruct the new matrix;the transform coefficient vector is used as the inverse transformation to get the enhancement speech signal with reconstruction matrix.The enhanced speech extracted and transmitted to the decoder;reconstruction speech signal with interpolation technique.Under different SNR simulation experiments on different speech,and compared with the DCT encoding,The results show that the algorithm has high data compression rate,decoding speech is clear and natural,what's more,good selfadaption enhancement of speech is realized.
speech;K-L transform;DCT;waveform encoding;self-adaption enhancement
TN391
A
1674-6236(2016)03-0008-03
2015-03-24稿件编号:201503324
李小航(1990—),男,陕西宝鸡人,硕士研究生。研究方向:语音信号处理、语音编码。
猜你喜欢
中国石油石化(2022年12期)2022-07-16
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
雷达学报(2018年5期)2018-12-05
中学数学杂志(高中版)(2016年6期)2017-03-01
福建中学数学(2016年7期)2016-12-03
系统工程与电子技术(2016年7期)2016-08-21
通信电源技术(2016年3期)2016-03-26
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
