
基于联合字典的3D图像去块效应方法
2016-09-09 07:04袁其政蒋刚毅
光电工程 2016年8期
袁其政,邵 枫,郁 梅,蒋刚毅
基于联合字典的3D图像去块效应方法
袁其政,邵 枫,郁 梅,蒋刚毅
( 宁波大学 信息科学与工程系,浙江 宁波 315211 )
本文针对3D图像压缩过程产生的块效应,提出了一种基于联合字典的3D图像去块效应方法。该方法主要包括字典训练、字典联合和去块效应三个阶段。在字典训练阶段,采用字典学习方法分别训练得到过完备的彩色字典和深度字典;在字典联合阶段,根据测试图像的稀疏特性和构造的彩色和深度字典,求出对应的彩色与深度联合字典;在去块效应阶段,通过估计重构误差阈值,并根据联合字典对图像进行去块效应处理。实验结果表明,本文提出的方法能够有效地去除编码图像的块效应,且得到较高的虚拟视点绘制质量。
信号处理;3D图像;字典训练;字典联合;去块效应
0 引 言
随着通信技术和视频技术的不断成熟,高质量的视频成为发展的主流,而3D(Three Dimension)视频能够提供深度信息,满足人们对立体感和真实感的视觉需求。但3D视频的数据量非常庞大,需要进行编码以适应传输或存储的要求。近年来,基于块的离散余弦变换 (Block-based Discrete Cosine Transform, BDCT)已经广泛的应用于图像和视频压缩之中,并被一些重要的国际编码标准所采纳,如:JPEG(Joint Photographic Experts Group)、MPEG(Moving Pictures Experts Group)、H.264/AVC[1-2]。然而,3D视频经过编码后会产生块效应,严重影响观看和绘制效果,因此有效的去块效应方法成为研究的热点。
去块效应方法根据是否嵌入到编码框架中,可分为两大类:环路处理方法和后处理方法。环路处理方法是H.264/AVC中的一部分,在编码的同时去除块效应,能够有效地避免块效应在帧间的传播。后处理方法是指对解码的每帧图像进行去块效应处理,具体的方法有滤波方法[3-5]和基于凸集投影方法 (Projection Onto Convex Sets, POCS)[6-9]。在滤波方法中,Luo等提出了一种基于DCT的平滑区域去块效应的方法[3],该方法只处理平滑区域,对非平滑区域不处理,使得边缘的块效应无法去除,因此处理后图像质量不高;Wang等人提出了一种基于信号分解的去块效应方法[4],后由Lim等人进行了改进[5],该方法在DCT域进行滤波,但去块效应时仍去除了部分高频分量,无法有效地保存边缘,并增加了算法复杂度。Youla和Webb提出了基于迭代的后处理方法[6],首先定义了闭合凸约束集来表示未编码图像的原数据,然后用迭代计算方法交替投影到凸约束集上,从而在编码数据中恢复出原图像。该方法的优势是可以灵活的设定约束条件,获得不同的重建图像。Yang等在此基础上,提出了一种基于凸函数集投影的空间不变恢复算法[7],该方法考虑到图像的局部特性和人类视觉系统,使用了空间适应平滑约束集。然而,以上两种约束集的数据较少,使得去块效应的效果较差。Zou等提出一种基于自适应投影的去块效应方法[8],首先根据局部像素特性调整像素强度,然后使用三种局部自适应约束集提升去块效应结果。因为约束集的扩展,此方法有很好的性能,但计算复杂度较高,无法满足实际应用。近年来,稀疏表示在图像去噪、修复以及超分辨率重建等方面应用广泛[9-10]。文献[9]提出了一种以加噪图像为训练样本学习字典对图像去噪的算法,该算法可以达到较好的去噪性能,然而其训练字典包含的信息量较少。文献[10]提出一种在图像绘制过程中用字典对3D图像(彩色加深度)去块效应的方法,此方法训练出的彩色字典和深度字典相互独立,没有学习到它们之间的几何对应关系。
本文提出一种基于彩色与深度联合字典的3D图像去块效应方法。充分利用彩色与深度信息的相关性,构造彩色与深度联合字典,从而更好地表征彩色与深度信息以及两者之间的相互影响。本方法的创新点在于:1) 对于压缩后的3D图像,根据其彩色和深度特征空间的稀疏特性建立联合矩阵,从而构建彩色与深度联合字典;2) 根据图像的失真程度估计重构误差阈值,并结合联合字典稀疏表示获得重建图像。实验结果表明,本方法能有效地去除彩色和深度图像的块效应,提高虚拟视点绘制图像质量。
1 基于联合字典的去块效应方法
本文提出的基于联合字典的去3D图像块效应方法如图1所示,主要包括三个部分:字典训练、字典联合和去块效应。在字典训练阶段,选取多幅原始彩色和深度图像作为训练集,从中随机选取训练块来训练字典;在字典联合阶段,根据训练的字典,分别求取彩色和深度图像的稀疏系数,然后根据稀疏系数构造联合彩色和深度字典的矩阵,从而获得3D字典;在去块效应阶段,根据彩色和深度图像的块效应程度,自适应地估计重构误差阈值,然后根据阈值和3D字典,分别重建彩色和深度图像。
在图1中,c和d分别为彩色图像和深度图像的训练集;c和d分别为训练得到的彩色字典和深度字典;c和d分别是为测试彩色图像和深度图像;c为c的稀疏系数,d为d的稀疏系数;为字典c和d的联合矩阵;3d为联合字典;p为估计重构误差阈值;¢c和¢d分别为联合字典中的彩色字典和深度字典;¢c为c去块效应后的彩色图像,¢d为d去块效应后的深度图像;r为绘制图像。
1.1 字典训练

图1 基于联合字典的3D图像去块效应框图
为了训练字典更加准确,训练样本应具有多样性和普遍性。本文从标准的3D视频序列[11]中选取9对纹理丰富的彩色和深度视频图像,构造训练样本。从每幅彩色图像中随机选取8×8的重叠块1 000个,则共选取9 000个块作为训练样本,=64,=9 000。

其中:||·||0是0范数,表示矩阵中非零元素的个数,||·||2是2范数。本文采用K均值奇异值分解(K-means Singular Value Decomposition, K-SVD)算法[9]学习彩色字典c。K-SVD主要分为稀疏编码和字典更新两部分,在稀疏编码阶段,将字典固定,采用基于贪婪学习的正交匹配追踪(Orthogonal Matching Pursuit, OMP)算法[12]计算稀疏系数;在字典更新阶段,对每次重建得到的误差矩阵进行奇异值分解(Singular Value Decomposition,SVD)完成字典更新。同理,可以训练得到深度字典d。
1.2 字典联合
简单拼接彩色和深度字典作为3D字典,不能得到较高质量的3D重建图像,这是因为单独训练出的彩色和深度字典忽略了彩色特征空间和深度特征空间之间的几何对应关系。为了解决这个问题,本文充分利用彩色和深度信息的相关性,根据对应特征空间在字典下稀疏系数的对应关系建立联合字典[13]。
根据1.1节中训练的字典c,可以对任意彩色图像进行稀疏表示,对于每次输入的块效应彩色图像c,固定式(1)中的彩色字典,用OMP算法求解得到彩色图像稀疏系数c,同理,可得到对应的深度图像稀疏系数d。由文献[13],可得联合矩阵c和d:
根据以上联合矩阵c和d,对彩色字典c和深度字典d进行联合,得到对应的联合彩色字典¢c和联合深度字典¢d:
则3D字典表示为
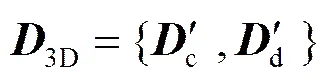
1.3 去块效应
BDCT压缩产生的块效应可近似为加性噪声[14],块效应图像可表示为原始图像和块效应噪声的和:
其中:是块效应图像,是原始图像,为噪声。对于彩色图像c,结合已求出的联合字典¢c,其去块效应的目标函数表示为
其中:p为重建阈值。采用OMP算法求得重建稀疏系数,即能得到去块效应后的重建彩色图像¢c:
同理,可得到去块效应后的重建深度图像¢d。
由式(7)可知,重建阈值p的选取会直接影响去块效应效果。为有效地去除图像块效应,本文提出了一种自适应预测重建阈值方法。块效应类似于加性高斯白噪声,同一图像中的块效应有相同的噪声级,则重建阈值p可表示为

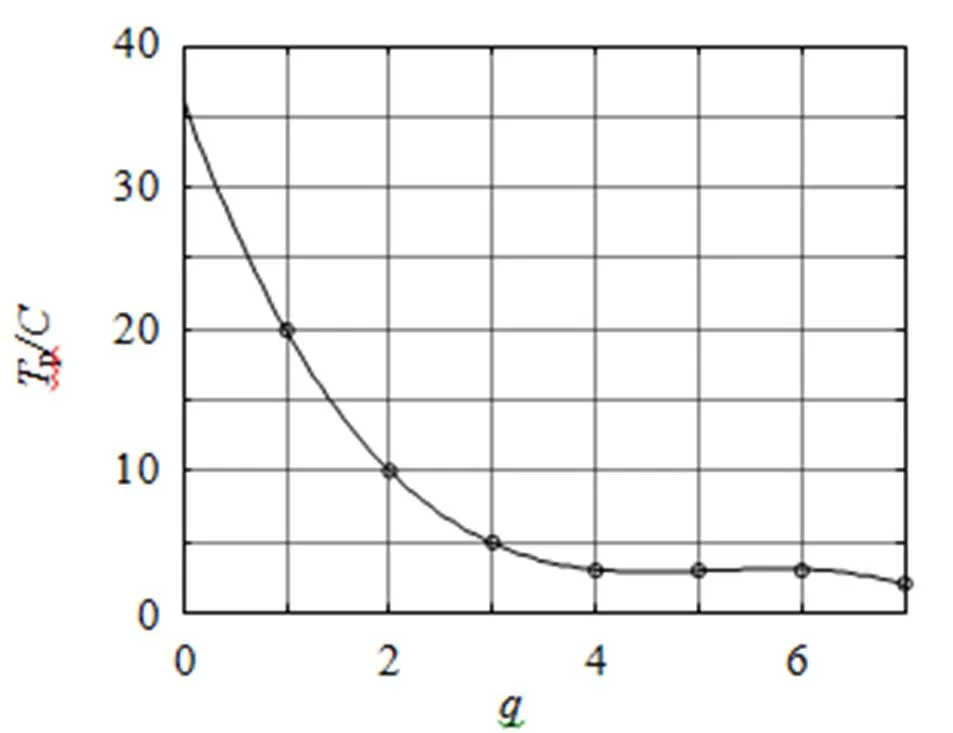
图2 s 随压缩变量q值变化的关系曲线
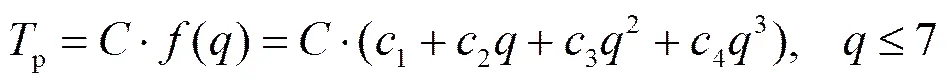
其中:()是压缩变量的多项式函数,1、2、3、4的值分别为36.143、-19.789、3.881、-0.250。
2 实验结果与分析
为了证明本文方法的有效性,对Nokia提供的Undo Dancer序列和日本Nagoya大学提供的Balloons序列进行实验[11]。图3和图4分别是用不同方法对Undo Dancer序列和Balloons序列的去块效应结果,其中(a)~(c)依次是经JPEG压缩后彩色图像、深度图像和压缩后彩色和深度图像的绘制图像,压缩变量值为1;(d)~(f)依次是采用文献[17]方法进行去块效应处理后的彩色图像、深度图像和处理后彩色和深度图像的绘制图像;(g)~(i)依次是用文献[18]方法进行去块效应处理后的彩色图像、深度图像和处理后彩色和深度图像的绘制图像;(j)~(l)依次是用本方法去块效应之后的彩色图像、深度图像和处理后彩色和深度图像的绘制图像。从图中可以看出,经本方法处理后的图像块效应明显减少,图像整体质量有明显的提高。

图3 Undo Dancer图像序列的去块效应结果

图4 Balloons图像序列的去块效应结果
为了更好地说明本文方法的有效性,将本方法与其他三种方法的广义块边缘损伤度量值(Generalized Block-edge Impairment Metric, GBIM)[15-16]进行比较,其结果如表1和表2所示。

表1 不同的方法对彩色图像序列和深度图像序列处理之后的GBIM结果

表2 不同的方法对压缩彩色图像和压缩深度图像处理之后的绘制结果的GBIM结果
GBIM是一种有效的块效应度量,其值越小越好。从表中可以看出,本方法处理后彩色图像、深度图像和绘制图像的GBIM有很大的提升。在值比较小的时候,GBIM值提升更大。相比于其他两种方法,本文方法的去块效应效果最优。本方法可以明显减少压缩图像的块效应,压缩程度大时效果更好。
3 结 论
本文考虑了彩色图像和深度图像特征空间的几何对应关系,提出了一种基于联合字典的3D图像去块效应的方法,本方法以能够更好的重建图像的多幅原始3D图像为字典训练集,同时考虑了彩色和深度特征空间的几何对应关系,并根据测试图像在字典下的稀疏特性实现联合,然后通过一个三阶多项式预测测试图像的阈值,再结合联合字典去除3D图像的块效应。实验结果表明,本文方法能够有效的去除图像块效应,在主观和客观方面都有很好的性能。在本文的基础上,将考虑实现字典的自适应联合,从而完善本方法的整体性能。
[1] Wiegand T,Sullivan G J,Bjntegaard G,. Overview of the H.264/AVC Video Coding Standard [J]. IEEE Transactions on Circuits and Systems for Video Technology(S1051-8215),2003,13(7):560–576.
[2] ITU-T Rec. H.264–ISO/IEC 14496-10 AVC,JVT G050,Draft ITU-T Recommendation and Final Draft International Standard of Joint Video Specification [S]. 2003.
[3] LUO Ying,Rabab K Ward. Removing the Blocking Artifacts of Block-based DCT Compressed Images [J]. IEEE Transactions on Image Processing(S1057-7149),2003,12(7):838–842.
[4] WANG Ci,XUE Ping,LIN Weisi,. Fast Edge-preserved Post Processing For Compressed Image [J]. IEEE Transactions on Circuits and Systems for Video Technology(S1051-8215),2006,16(9):1142–1147.
[5] Lim T,Ryu J,Kim J,. Adaptive Deblocking Method using a Transform Table of Different Dimension DCT [J]. IEEE Transactions on Consumer Electronics(S0098-3063),2008,54(4):1988–1995.
[6] Youla D,Webb H. Image Restoration by the Method of Convex Projections:Part 1—Theory [J]. IEEE Transactions on Medical Imaging(S0278-0062),1982,1(2):81–94.
[7] YANG Yongyi,Galatsanos N P,Katsaggelos A K. Projection-based Spatially Adaptive Reconstruction of Block–transform Compressed Image [J]. IEEE Transactions on Image Processing(S1059-7149),1995,4(7):896–908.
[8] ZOU Jujia,YAN Hong. A Deblocking Method for BDCT Compressed Images Based on Adaptive Projections [J]. IEEE Transactions on Circuits and Systems for Video Technology(S1051-8215),2005,15(3):430–435.
[9] 秦振涛,杨武年,潘佩芬. 基于稀疏表示和自适应字典学习的“高分一号”遥感图像去噪 [J]. 光电工程,2013,40(9):16–21.
[9]QIN Zhentao,YANG Wunian,PAN Peifen. The Remote Sensing Image Denoising of “The First Satellite of High Resolution” Based on Sparse Representation and Dictionary Learning [J]. Opto-Electronic Engineering,2013,40(9):16–21.
[10] JUNG Cheolkon,JIAO Licheng,QI Hongtao. Blocking Artifact Reduction in DIBR using an Overcomplete 3D Dictionary [J]. Advances in Multimedia Modeling,Springer Berlin Heidelberg(S0302-9743),2013,7732:283–294.
[11] ISO/IEC JTC1/SC29/WG11. “Call for Proposals on 3D Video Coding Technology,” in MPEG Output Document N12036,MPEG Output Document N12036 [S]. 2011.
[12] Pati Y C,Rezaiifar R,Krishnaprasad P S. Orthogonal Matching Pursuit:Recursive Function Approximation with Applications to Wavelet Decomposition [C]// Conference Record of The Twenty Seventh Asilomar Conference on Signals,Systems and Computers,Pacific Grove,Nov 1-3,1993,1:40–44.
[13] LI He,QI Hairong,Zaretzki Russell. Beta Process Joint Dictionary Learning for Coupled Feature Spaces with Application to Single Image Super-Resolution [C]// Computer Vision and Pattern Recognition,Portland,June 23-28,2013:345–352.
[14] Meier T,Ngan K. Crebbin G. Reduction of Blocking Artifacts in Image and Video Coding [J]. IEEE Transactions on Circuits and Systems for Video Technology(S1051-8215),1999,9(3):490–500.
[15] WU Hongren,Yuen Micheal. A Generalized Block-edge Impairment Metric for Video Coding [J]. IEEE Signal Processing Letters(S1070-9908),1997,4(11):317–320.
[16] YIM Changhoon,Bovik Alan C. Quality Assessment of Deblocked Images [J]. IEEE Transactions on Image Processing(S1057-7149),2011,20(1):88–98.
[17] JUNG Cheolkon,QI Hongtao,SUN Zengzeng,. Three-dimensional Dictionary-based Deblocking for High-quality Stereoscopic View Generation [J]. Journal of Electronic Imaging(S1017-9909),2013,22(4):451–459.
[18] YUAN Hui,LIU Ju,XU Hongji,. Coding Distortion Elimination of Virtual View Synthesis for 3D Video System:Theoretical Analyses and Implementation [J]. IEEE Transactions on Broadcasting(S0018-9316),2012,58(4):558–568.
3D Images Deblocking Based on Joint Dictionary
YUAN Qizheng,SHAO Feng,YU Mei,JIANG Gangyi
( Faculty of Information Science and Engineering, Ningbo University, Ningbo 315211, Zhejiang, China )
To eliminate the blocking artifacts caused by three-dimensional (3D) image compression, a deblocking method is proposed based on joint dictionary. The proposed method mainly includes three stages: dictionary training, dictionary jointing and deblocking. At the dictionary training stage, an over-complete color dictionary and depth dictionary are trained respectively with state-of-the-art dictionary learning method. At the dictionary jointing stage, for a testing sample, its corresponding color-depth joint dictionary is constructed based on the sparse coefficients with respect to the learnt color and depth dictionaries. At the deblocking stage, by estimating the reconstruction error threshold, a deblocking operation is performed to get the reconstructed 3D images with respect to the learnt joint dictionary. Experimental results demonstrate that the proposed method can effectively reduce the blocking artifacts of the compressed 3D images and generate high-quality synthesized images.
information processing; three-dimensional (3-D) image; dictionary training; dictionary jointing; blocking artifact reduction
1003-501X(2016)08-0064-06
TN256
A
10.3969/j.issn.1003-501X.2016.08.011
2015-09-01;
2015-09-29
国家自然科学基金(61271021)资助
袁其政(1991-),男(汉族),河南开封人。硕士研究生,主要研究工作是3D图像处理。E-mail:15724251045@163.com。
猜你喜欢
小主人报(2022年24期)2023-01-24
儿童时代·快乐苗苗(2022年6期)2022-08-06
电子制作(2019年16期)2019-09-27
学生天地(2019年33期)2019-08-25
小学阅读指南·低年级版(2019年11期)2019-07-01
小天使·二年级语数英综合(2018年7期)2018-09-11
智能城市(2018年7期)2018-07-10
小天使·一年级语数英综合(2017年11期)2017-12-05
计算机测量与控制(2017年6期)2017-07-01
自动化学报(2017年5期)2017-05-14
