
微博中的开放域事件抽取
2016-09-08 10:30:39陈箫箫
计算机应用与软件 2016年8期
陈箫箫 刘 波
(北京工业大学计算机学院 北京 100124)
微博中的开放域事件抽取
陈箫箫刘波
(北京工业大学计算机学院北京 100124)
随着互联网的快速发展,网络信息的事件抽取已然成为研究热点。针对微博中的开放域事件抽取问题进行深入研究,实现一个事件抽取和分类系统。主要通过序列标记方法提取微博语句中的命名实体和事件短语表征相应事件,利用非监督分类方法对事件进行分类,将每个日期下各类别的事件根据重要性排序之后,以日历的形式展现出来。其中,运用条件随机场模型完成事件抽取中的序列标记任务,非监督分类方法选用了LDA主题模型。实验证明方法有效可行,命名实体识别和事件短语抽取均取得较高的准确率和召回率。
事件抽取条件随机场文本分类LDA模型
0 引 言
随着互联网和通信产业的快速发展,微博、微信等以短文本为主的网络平台已成为实时信息的重要来源。以微博为例,它是一个基于关系的信息分享、传播以及获取的平台,用户可以随时随地发布信息,实现即时分享。近年来,微博平台发展迅猛,在热点事件的报导和传播方面占据主导地位,针对微博文本的事件抽取研究受到越来越多的关注。
早期对于事件抽取的研究[1]主要侧重于在新闻文本中提取结构化的事件。新闻文本用词较为规范,具有清晰的语法结构,针对这类文本的事件抽取具有较高的准确率。微博与新闻等正式文体相比,语言趋于口语化、文本内容多而杂,含于其中的事件涉及生活的各个领域。传统的事件抽取研究大多集中在某一特定领域,对于领域多样化、事件类别不可预先定义的微博文本来说是不够完备的。上述原因导致对微博进行事件抽取时,采用针对普通文本的方法难以奏效。
近年来,针对微博的开放域事件抽取吸引了国内外学者的目光。Benson[2]使用远程监督的方法训练了一个关系提取器,可根据微博用户发布的信息检测出公众人物举办的活动和场地。Morgan等人[3]提出了一种基于最大熵的主题分类方法用于跟踪、检测微博中的话题信息。路荣等人[1]针对中文微博,通过主题模型和文本聚类的方法检测出微博中的新闻话题。
本文根据微博文本的特点,对中文微博中的事件抽取问题进行了深入研究,并实现了一个开放域事件抽取和分类系统,即微博-日历系统。该系统可在海量微博数据中提取出每个日期下具有新闻价值的热点事件,并以日历的形式展示出来。本文主要工作是提取表征事件的四元组(命名实体,事件短语,时间,事件类型),工作流程如图1所示,大致如下:首先获取微博文本进行预处理,用序列标记方法抽取出微博中的命名实体、事件短语,同时基于微博的发布时间计算出事件的发生时间,然后利用非监督学习方法对事件进行分类,最后量化命名实体和日期之间的关联程度,将每个日期下的事件按照重要性排序。本文针对开放域的事件抽取和分类方法突破了传统方法只能针对特定领域的局限性。运用序列标记方法对微博这类新兴文本进行热点事件抽取的研究具有一定创新性和参考性。通过对微博文本的时间处理,将热点事件按照它们的发生时间以日历形式展现具有创新性。此外,本文实现的微博-日历系统具有一定实用价值。

图1 微博-日历系统流程图
1 事件抽取
事件抽取之前需要对获取的微博文本进行简单的预处理工作。文本预处理主要包括两个方面:过滤无效信息、分词及词性标注。其中,过滤无效信息是指去除微博中无意义的文字内容或符号,例如字数极少的微博和一些URL、特殊字符、表情符号等。这些内容通常不涉及热点事件,且会增加文本噪声,因此,在预处理过程中先将这部分信息去除。由于中文文本没有空格之类的字符来标志一个词语的结束,所以需要进行分词和词性标注工作,便于下一步的语义分析。本文借用了ICTCLAS系统[5]实现分词,该系统是由中国科学院计算技术研究所研制出的汉语词法分析系统,具有良好的分词效果且支持词性标注。
本文中事件抽取是指在微博文本中提取结构化的事件信息。根据汉语的语言特点,许多词语往往不涉及事件相关信息,我们可以用几个比较关键的词语来概括相应事件,即对任意一条微博文本,提取出语句中的命名实体和事件短语来表征所述事件。为此,我们需要进行命名实体识别和事件短语抽取两个步骤。
1.1命名实体识别
命名实体识别是指识别出文本中具有特定意义的专有名词,在本文的研究中,识别范围主要包括人名、地名和机构名。目前,英文微博的命名实体识别研究[6]已取得一定成果,与英文相比,中文命名实体识别更加繁琐复杂。主要体现在以下几个方面:
(1)缺乏区别于非命名实体的特征标志。单词首字母大写是识别英文命名实体的一个重要依据,而中文命名实体不具有类似特征。(2)命名实体之间可能存在相互包含的现象。某些社会机构名称中可能含有人名、地名,这种现象也会降低识别效果。(3)英语单词之间存在空格将其分开,而中文词语并没有类似的边界标志,所以中文命名实体识别还会受到分词效果的影响。即中文分词系统的分词结果是否可靠,会直接影响系统识别的准确率。(4)在中文命名实体识别中,有些词语首次出现后会采用缩写形式,例如“中国科学院”的缩写形式为“中科院”。缩写中大多省略了指示实体词类型的关键信息,这给中文命名实体识别工作带来了较大困难。
虽然具有一定难度,但在中文命名实体识别领域也找到了较为有效的方法。目前常用的识别方法包括基于规则的识别方法和基于统计的识别方法。基于规则的命名实体识别方法,主要是将词法规则、语法规则甚至语义规则通过人工添加的方式加入到识别过程中以提高命名实体识别的质量。一般来说,基于规则的方法实现比较简单,能够达到一个比较高的准确率。但是这种方法的识别效果在很大程度上取决于规则的完备性和合理性,对规则制定者的要求比较高,通常需要经验丰富的专家才能完成,而且设计规则需要耗费大量的人力和物力。
随着语料库内容的不断丰富,基于统计的命名实体识别方法受到更多的关注。该方法可以通过训练标注语料获取对命名实体识别有帮助的相关知识,利用这些知识对未标注的数据进行结果预测,识别出其中的人名、地名和机构名。与基于规则的方法相比,基于统计的方法需要对语料进行标注训练,这个过程不要求精深的语言学知识,并且可以在较短时间内完成,因而得到广泛应用。基于上述原因,本文采用了基于统计的方法来完成命名实体识别任务。
1.2提取事件短语
微博语句中的关键性词语可以高度概括所述事件的主要内容,搭起了事件框架。命名实体可以充当事件的主语部分,除此之外还需要提取补充事件具体内容的词语,这类词语就是本文所述的事件短语。现有事件短语的提取方法同样包括基于规则的方法和基于统计的方法。在命名实体识别部分,我们已就这两种方法进行了比较,再加上微博文本往往包含一些网络用语,词语具有非正式性,已有的基于规则方法难以奏效,因此,我们统一使用基于统计的方法进行事件短语提取和命名实体识别的工作。
目前,基于统计方法的模型主要包括支持向量机、隐马尔可夫模型、最大熵马尔可夫模型和条件随机场模型等。支持向量机主要针对两类分类问题,在高维空间中寻找一个超平面把类别分割开来,以保证最小的分类错误率。隐马尔可夫模型是一种产生式模型,常被应用于序列标记任务中。但该模型假设观察值之间是严格独立的,这一假设前提使得模型无法使用较为复杂的特征,在事件抽取问题上是不够完善的。最大熵马尔可夫模型克服了隐马尔可夫模型严格的独立假设,允许状态转移概率依赖于序列中非独立的特征,从而将上下文信息引入到模型的学习和识别过程中,提高了识别效果。不过,由于该模型是在每个观察结点上判断输出标记,有可能陷入局部最优,易导致标记偏置问题。
相比之下,条件随机场模型同样不需要隐马尔可夫模型所要求的严格独立假设,且该模型对状态序列进行全局计算的特点避免了最大熵马尔可夫模型的标记偏置问题,在信息抽取领域表现出较好性能。提取命名实体和事件短语本身是比较典型的序列标记问题,再加上微博文本的特殊性,综合考虑,本文采取了序列标记的方法[7]提取命名实体和事件短语,使用的训练和推理模型为条件随机场模型。
1.3条件随机场
条件随机场CRFs(Conditional Random Fields)模型是由Lafferty等人在最大熵模型和隐马尔可夫模型的基础上提出的一种判别式模型。该模型在给定观察序列的情况下,对整个序列的联合概率统一建模,重点解决序列化标记的问题。
如图2所示,随机变量X代表数据序列,变量Y是与之对应的标记序列,p(Y|X)表示在给定数据序列X的条件下,标记序列为Y的条件概率。设G=(V,E)是一个无向图,Y={Yv|v∈V}是以G中节点v为索引的随机变量构成的集合。在给定X的条件下,如果每个随机变量Yv服从马尔可夫属性,即在给定X和Yv以外的所有随机变量Yw的条件下,随机变量Yv满足条件概率p(Yv|X,Yw,w≠v)=p(Yv|X,Yw,w~v),(w~v表示w和v是图G中的相邻节点),则(X,Y)构成一个条件随机场[8]。CRFs是无向图模型,其最简单的形式是链式CRFs,即模型中各个节点之间构成线性结构。
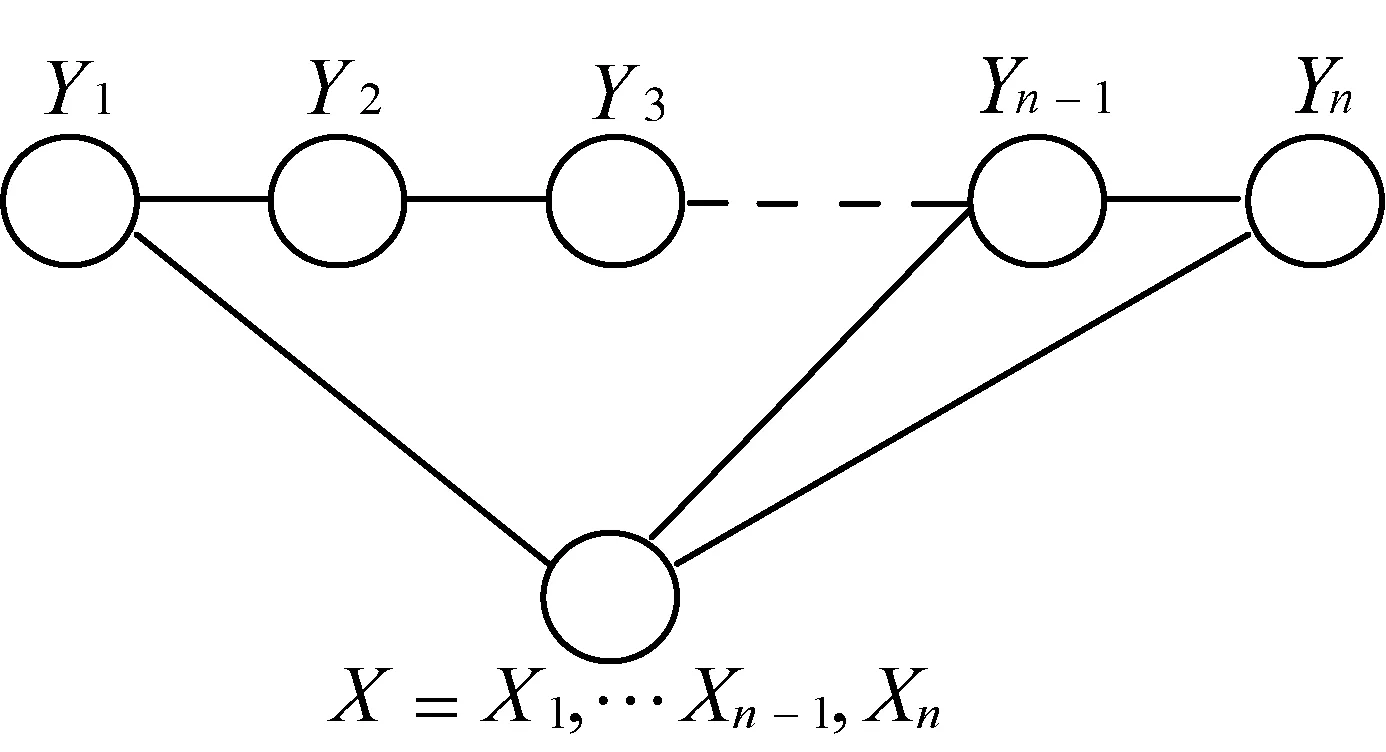
图2 链式CRFs模型图
对于本文的事件抽取问题,可以用链式条件随机场进行训练和推理,标记出属于命名实体和事件短语的词语来表征文本事件。假设X={X1,X2,…,Xn}是微博文本词语构成的观察序列,设与之对应的标记序列为Y={Y1,Y2,…,Yn}。集合Y中的元素为实体类型的标注符号。根据条件随机场的基本理论,标记序列的条件概率与模型的势函数成正比,即:
p(Y|X,λ)∝
(1)
其中,tj(Yi-1,Yi,X)是观察序列和标记序列在i-1到i时刻的特征转移函数;Sk(Yi,X)是整个观察序列和标记序列在i时刻的状态特征函数。两个特征函数可以统一为二值函数fj(Yi-1,Yi,X),函数值可以通过i时刻所有观察值的特征结合其对应的标记结果来获得。统一特征函数并将势函数的乘积归一化,可得标记序列Y的条件概率:
(2)
其中Z(X)为归一化因子;参数λ的取值可在模型训练中采用极大似然估计获得。
本文中,链式条件随机场的推理过程就是对于微博语料库中各微博文本组成的观测序列X和训练产生的模型参数λ,找到一个与之对应的最优标记序列Y,使得Y能够准确标注其中的命名实体和事件短语。求得最优标记序列的过程可以转化为求取概率函数p(Y|X,λ)的最大值问题。我们可以利用维特比算法递归求得Y*=argmaxp(Y|X),此时Y*即为后验概率最大的序列标记Y。至此,可以得出微博文本中的命名实体和事件短语,完成事件抽取任务。
1.4特征选择
确定模型的训练和推理过程之后,我们需要选择与之对应的文本特征。特征的选取具有至关重要的作用,它们决定着模型的特征函数,对结果的正确率和召回率都有很大影响。如果选取的特征集过大,不仅会影响模型训练和预测的效率,还可能发生过拟合现象;如果选取的特征集过小,会降低模型识别的准确率和召回率。本文利用条件随机场的特点,在进行事件抽取时不仅利用当前词的特征,还充分利用了上下文的统计信息作为特征,达到了良好的效果。
当前词的特征包括词形特征、词性特征和所处的位置特征等。词形特征主要是指构成该词的字符串及其长度,是词的基本特征。例如,命名实体大多包含两个以上字符,很少出现一个字的人名、地名和机构名,显然,字符串的长度在一定程度上影响实体和短语的识别。词性是信息抽取中一个常用且有效的特征信息。命名实体和事件短语大多为名词和动词,极少含有形容词、量词和代词等其他词性的词语,这在很大程度上缩小了标记任务的求解空间。同时词性特征也能够涵盖一定的语法信息,有助于提高实体和短语识别的准确度。位置特征是指该词相对句子而言所处的位置,一般来说,命名实体位于句首的概率大于在句中或句尾的概率,这一特征对于命名实体识别也具有极为重要的作用。
仅凭当前词自身的特征不足以准确识别命名实体和事件短语,还需加入词语的上下文特征。该特征指的是包括当前词和其前后若干个词在内的一个观察窗口(W-n,…,W0,…,Wn)。理论上来说,窗口范围越大,可利用的上下文信息越多。但如果窗口过大,除了严重降低运行效率、浪费大量资源之外,还会产生过拟合现象;而如果窗口过小,就不能获取足够多的有用信息。本文将观察窗口的大小设置为5,实验证明该值对于实体词识别任务能够获得较好效果。
为利于条件随机场模型的训练和推理,本文为当前词特征和上下文特征定义了一个的特征模板,具体含义如表1所示。

表1 CRFs模型特征模板
考虑到分词的原因,人名、地名、机构名和事件短语这四类实体词可能被切分为多个部分,例如当前词可能位于实体的开始(B)、内部(I)和实体外(O)三个位置。所以本文定义了一个基于实体位置的标记集合来标识当前词的实体类型,具体标记及其含义如表2所示。
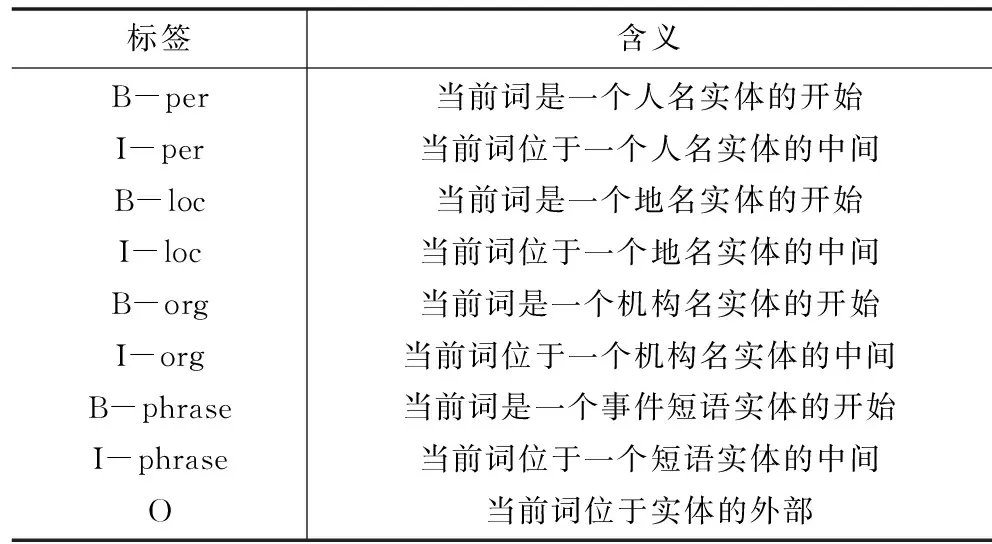
表2 实体类型标注集合
条件随机场模型可对文本特征进行线性组合,构成较为复杂的特征来表示非线性的上下文信息。同时,问题的特征空间会随之增大,但并非所有的特征都是有用的,选择出冗余少、代表性高的特征对模型的训练和应用来说是非常有必要的。本文使用了基于计数的特征选择方法,即在样本训练的过程中统计各个特征的出现次数,选择次数较高的特征作为模型特征集。
2 事件分类
传统的文本分类方法主要是利用向量空间模型表示文本,根据相似性计算的量化结果决定文本类别。但由于微博这类短文本包含的词语较少,具有严重的数据稀疏性问题,使得对微博文本进行分类学习的复杂性加大。此外,对于微博中的事件分类来说,有监督的或半监督的分类方法存在很多问题:微博是包含多个领域的开放性文本,对于涉及的事件类别是很难明确界定的;监督或半监督的分类方法,大多需要人工标注事件类别,这会带来较大的工作量,再加上某些类别出现的频率较低,即使标注了很大的数据集也不可能把所有的类别都包含进来;对于一篇新闻文本来说,它的内容大多是围绕一个主题叙述的,但微博文本较之更为随意,往往融合多个事件类别。基于上述原因,本文采用了一种针对开放域文本的无监督分类方法,即基于潜在狄利克雷分布的LDA(Latent Dirichlet Allocation)主题模型,通过聚类的方法实现微博文本中主要事件的类别划分。下面简单介绍一下LDA主题模型的原理以及本文中的微博文本聚类算法。
2.1LDA模型
LDA模型是由Blei等人在概率潜在语义分析模型(PLSA)的基础上,运用超参数和隐变量来模拟文档生成过程的产生式模型[9]。PLSA模型在较大程度上依赖于模型训练时所使用的数据集,特别是模型在文档层面上没有描述概率,先验概率的求解只建立在已有训练集,易导致过拟合现象。相比之下,LDA模型采用了一个服从狄利克雷分布的K维隐含随机变量来描述文档的主题概率,模拟文档集的产生过程,克服了PLSA模型的缺点,在文本分类、情感分析等方面具有广泛应用。

图3 LDA主题模型
根据LDA主题模型的原理,我们把包含于微博语句中的事件信息看作是若干类别的混合分布,每一个事件类别对应事件实体词的概率分布。例如“加油”一词可能出现在体育类别的文本中,也可能出现在“汶川加油”这样的社会事件中。我们把两个类别type看作潜变量,有type~Mult(θ),相应的词语word也对应一个多项分布,即word~Mult(φ)。对于一个由M篇微博文本组成的语料库,假设它所包含的事件类别个数为K,LDA模型假设该语料库的生成过程概括为以下步骤:
(2) 对于第m篇微博文本,确定它所包含的词语个数,即文本的长度N,N~Poiss(ζ);
(4) 对第m篇微博文本中的第n个词语:

(5) 将步骤(4)重复N次,就生成微博文本m;
(6) 对于语料库中的每一篇微博文本,重复步骤(2)-(5),完成整个微博语料库的生成。


(3)



(4)

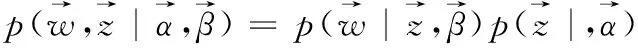
(5)

2.2微博文本聚类
由LDA模型的原理和产生过程可看出,该模型完全适用于本文针对开放域的微博文本分类任务。利用LDA模型对微博语料库进行训练和推理,可完成事件类别的划分。模型的训练过程主要是求解模型参数θ和φ的取值。对于本文的微博语料库,LDA模型的训练流程如下:
(1) 随机初始化:对每条微博语句中的每个词语word,随机赋予一个类别编号type;
(2) 重新扫描语料库,对每个词语word重新采样它的类别,在语料中进行更新;
(3) 重复步骤(2)直到吉布斯采样收敛;
(4) 统计语料库信息,得到type-word共现频率矩阵。根据该矩阵,可得出参数θ和φ的值。

(1) 随机初始化:对当前文本中的每个词语word,随机赋予一个类别编号type;
(2) 重新扫描当前文本,对每个词语word重新采样它的类别;
(3) 重复步骤(2)直到吉布斯采样收敛;
3 时间处理和事件排序
通常,微博中许多关于时间的描述均指向同一日期[10],比如对于同一时间的描述有“下周二”“2月3日”等表达方式,基于微博的发布时间,它们可能都是指2015年2月3日这一天。为了解决时间表达式的一致性,本文采用了构建正则表达式的方法匹配字符串中的时间信息。识别文本中的时间表达式之后,再将它们在基准时间的基础上转化为标准日期格式。例如对于在2014年12月15日发布的微博信息“后天下午我们将要召开会议”,处理之后的形式为:2014年12月17日下午,我们将要召开会议。这样就把微博中的事件更加准确的划分到具体的时间下,避免了将其他日期下的热点事件误认为是今天发生主要事件。
事件抽取和时间处理之后,需要根据事件的重要性进行排序。在之前的事件排序研究中,通常根据词频来量化事件的重要程度,但是微博中的高频词汇往往是涉及人们日常生活的词语,与之相对应的事件大多不是我们想要的。针对此问题,我们采用的方法是量化类别下命名实体和日期之间的关联强度来决定事件的排名顺序[12]。本文认为,每天都发生的、涉及人们日常生活的事件重要性较低,比如事件信息“北京市晚间晴”,可能每天都会出现在微博中,但它不属于热点事件;相反,其他日期下很少或没有出现过的事件重要性较高,例如“昌都发生地震”,这是比较罕见、突发性高的事件,相比之下具有更高的重要性。根据以上原则,本文使用了基于似然比统计量的函数来量化事件的重要程度。对于任一给定的命名实体e和日期d,统计函数值的计算公式如下:
(6)
其中,Oe,d表示命名实体为e且发生日期为d的事件总数;Oe,d表示命名实体为e,但发生日期不为d的事件总数。相似的,Ee,d表示在e和d相互独立的条件下,包含命名实体e或发生日期为d的事件总数,以此类推其他符号的含义。值得注意的是,在统计包含同一命名实体的事件数量时,本文加入了类别信息的判断,即对于同一命名实体,如果聚类产生的类别标签相同,则该实体的统计比重会增大,标志着与之相对应的事件具有更高的重要性。例如对于两条微博文本:a)北京市于今天召开国际会议,多位领导人出席;b)北京市天气多云,晚间会有雷阵雨。以上两个语句的命名实体均为“北京市”,但是事件所属的类别大不相同,由此可见,事件类别对于事件重要程度的判断具有极大影响。
4 实验与评估
本文所用的文本数据主要来源于新浪微博,通过该平台提供的开放接口分时段获取了2013年8月11日至2013年8月13日的公共微博。由于微博开放平台规定了每次获取微博的条数和抓取频率,本文数据集的大小受到了一定程度的限制。去除数据集中的无效微博之后,保留了24 257条微博文本作为本文实验的语料库。
在时间抽取阶段,笔者在语料库中选取了800条微博文本作为条件随机场模型的训练集。首先根据本文1.4节所述的特征选择方法,统计训练集的各类文本特征,然后手工标记每个微博词语的实体类型,具体标记符号参照表2所列的标记集合。利用上述统计信息和标记数据完成条件随机场的训练,然后推理得出所有文本的事件信息。笔者在模型训练集之外的数据中,随机选用了500条微博文本作为模型的测试集。对于测试集中的数据同样进行了手工标注命名实体和事件短语的工作,然后将系统的处理结果与手工标注集合相比较得到事件抽取的准确率和召回率,具体数据如表3所示。实验证明,本文所用方法对于命名实体识别和事件短语抽取均取得较好效果。

表3 事件抽取的准确率和召回率
在对微博文本进行事件聚类的过程中, LDA主题模型的训练和推理过程是在一个假设条件下完成的,即假定事件类别个数K及Dirichlet先验分布参数α和β这三个变量值已知。实际上,上述参数值是需要人为设定的。经交叉验证发现,当K=50、α=1、β=0.1时,模型能够达到较好的聚类效果。一般意义上,事件的类别标签应该是诸如运动、政治、经济等类型的文本词语,但是通过LDA主题模型得出的是类别的数字化表示。实际上,我们可根据主题模型的统计结果把类别编号转化为系统所需的文本类别标签。即通过观察每个类别下的高频词汇判断它的所属领域。通过对实验数据的观察,本文赋予数据集的文本类别有科技、体育、政治、教育等15个类别标签。对于不易区分所属领域的类别,统一划至“其他”类别中。
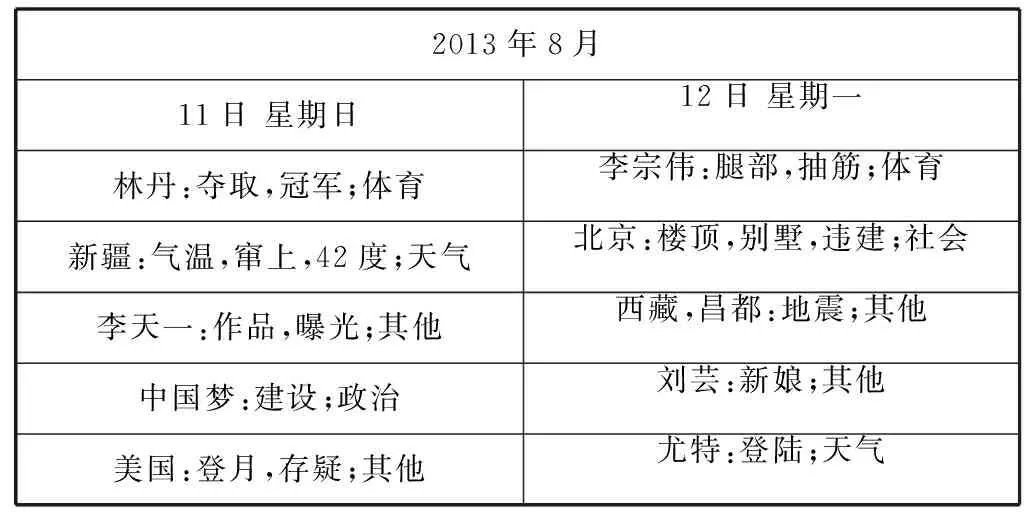
表4 微博-日历系统结果展示
注:日历中事件的展示次序为命名实体:事件短语;事件类别;受分词影响,事件短语包含多个词语
表4为本文微博-日历系统基于现有语料库的部分处理结果,主要展示了2013年8月11日、12日的主要事件及其类别信息。每个日期下,我们根据式(6)所定义的统计函数来对事件进行排序,选取函数值最高的事件以日历的形式展示,展示内容包括事件的命名实体、事件短语和事件类别。对于每条微博文本,它的处理过程如下:假设某微博用户在2013年8月12日发布了一条微博:昨晚林丹赢了,他又一次夺取了世锦赛冠军!该文本经条件随机场训练和推理之后,得出的命名实体为“林丹”,事件短语为“夺取,冠军”。因为微博中包含时间相关的词语“昨晚”,基于时间处理规则,在微博发布时间的基础上对日期减1,得出事件的发生时间为2013年8月11日。通过LDA模型聚类发现其所属类别下主题词大多涉及体育,因此将其划分为“体育”类别。最后用统计函数计算该事件的重要性并排序。虽然本系统存在数据集较小、时间处理有误差等缺陷,但处理结果大体呈现出各个日期下的主要事件,证明了本文所述方法的可行性。此外,本系统也可应用于大规模微博数据集的事件提取工作,具有一定的实用价值。
5 结 语
本文主要通过序列标记的方法提取出微博文本中的主要事件,并采用针对开放域文本的非监督机器学习方法进行了事件分类,实验结果基本令人满意。在识别命名实体和抽取事件短语的过程中,虽然处理结果达到了较高的准确率和召回率,但是对于某些地名和部分机构名称的识别效果不太理想,在进一步研究中会对该部分进行改进工作。此外,在使用主题模型进行文本聚类工作之后,本实验得出的最终事件类别标签是在人工干预的情况下完成的,这一方法同样具有不足之处。在未来的研究工作中会对此问题进行更加深入的研究,希望能找到一种自动标注文本类别标签的机器学习方法来改善系统。
[1] Allan J, Papka R, Lavrenko V. On-line new event detection and tracking[C]//Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, 1998:37-45.
[2] Benson E, Haghighi A, Barzilay R. Event discovery in social media feeds[C]//Annual Meeting of the Association for Computational Linguistics, 2011:389-398.
[3] Lin J, Snow R, Morgan W. Smoothing Techniques for Adaptive Online Language Models: Topic Tracking in Tweet Streams[C]//Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, 2011:422-429.
[4] 路荣,项亮,刘明荣.基于隐主题分析和文本聚类的微博客新闻话题发现[J].模式识别与人工智能, 2012, 25(3): 382-387.
[5] Zhang Huaping, Yu Hongkui,Xiong Deyi, et al. HMM-based Chinese Lexical Analyzer ICTCLAS[C]//Proceeding 2nd SIGHAN workshop affiliated with 41th ACL, Sapporo Japan, July 2003:184-187.
[6] Ritter A, Clark S, Etzioni O, Named entity recognition in tweets: An experimental study[C]//Conference on Empirical Methods in Natural Language Processing,2011:45-51.
[7] Gimpel K, Schneider N,O’Connor B,et al.Part-of-speech tagging for twitter: Annotation, features, and experiments[C]//Annual Meeting of the Association for Computational Linguistics,2011:42-47.
[8] Lafferty J D, McCallum A, Pereira F C N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C]//International Conference on Machine Learning, 2001:282-289.
[9] Blei D, Ng A, Jordan M. Latent Dirichlet allocation[J]. Journal of Machine Learning Research, 2003: 3,993-1022.
[10] Finkel J R, Grenager T, Manning C. Incorporating non-local information into information extraction systems by gibbs sampling[C]//Annual Meeting of the Association for Computational Linguistics, 2005.
[11] Mani I, Wilson G. Robust temporal processing of news[C]//Annual Meeting of the Association for Computational Linguistics, 2000.
[12] Ritter A, Mausam, Etzioni O, et al. Open domain event extraction from twitter[C]//Proceedings of the 18th ACM SIGKDD international conference on Knowledge discovery and data mining,2012:1104-1112.
EXTRACTING OPEN DOMAIN EVENTS IN MICROBLOGS
Chen XiaoxiaoLiu Bo
(CollegeofComputerScience,BeijingUniversityofTechnology,Beijing100124,China)
With the rapid development of Internet, the extraction of network information events has been the focus of the study. We thoroughly studied the extraction issue of open domain events in microblogs, and implemented a system of event extraction and categorisation. We characterised the corresponding events by the named entities and event-referring phrases in microblogging sentences mainly extracted with sequence-labelling method, and used the unsupervised categorisation method to classify events. After sorting the events of various categories in every date according to their significances, we displayed them in the form of calendar. In it, we used the conditional random fields to complete the sequence labelling tasks of the event extraction, for unsupervised method we chose the LDA topic model. Experiments prove that the method is effective and feasible. Both the named entity recognition and event-referring phrases extraction achieve high accuracy and recall rates.
Event extractionConditional random fieldsText categorisationLatent Dirichlet allocation (LDA) model
2015-03-26。国家自然科学基金项目(61005001)。陈箫箫,硕士生,主研领域:自然语言处理,机器学习。刘波,副教授。
TP3
A
10.3969/j.issn.1000-386x.2016.08.004
猜你喜欢
作文大王·低年级(2022年3期)2022-03-19 18:09:52
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19 08:52:46
东方女性(2018年3期)2018-04-16 15:30:02
小学生作文·小学低年级适用(2018年12期)2018-04-11 03:10:42
散文诗(2017年17期)2018-01-31 02:34:08
校园英语·下旬(2016年2期)2016-03-18 10:23:20
新校长(2016年8期)2016-01-10 06:43:59
快乐作文·低年级(2014年10期)2015-01-14 23:43:55
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
