
同行评议中的异常数据检测方法研究
——以科研项目评审为例
2016-09-05 06:50杨晓秋李旭彦
中国软科学 2016年5期
杨晓秋,李旭彦
(科学技术部 基础研究管理中心,北京 100862)
同行评议中的异常数据检测方法研究
——以科研项目评审为例
杨晓秋,李旭彦
(科学技术部基础研究管理中心,北京100862)
同行评议是对科学技术活动及其产出进行科学评价的主要方式之一,然而评议过程中存在的异常评审数据可能会对科研项目评审结果的公平、公正性产生影响。为此,本文提出了一种用于识别专家评议异常数据的检测方法,该方法首先利用云模型中的逆向云算法计算专家评审数据的异常程度,并进行检测;然后,根据检测结果,采用基于协同过滤的异常评议数据修正算法,对专家异常评议数据进行修正;最后,设计了一种专家评议能力计算算法,为后续科研项目评审中的专家选择提供决策依据。基于同行评议真实数据的实验结果表明,本文提出的检测方法能够有效识别出专家评议的异常数据。
科研项目评审;同行评议;云模型;协同过滤;异常检测;信誉计算
一、引言
随着我国各类科技计划项目(如973计划、863计划、国家自然科学基金等)、科技成果(如国家科学技术奖励等)、科研基地(如国家重点实验室评估等[1])的评审评价越来越多,如何保证这些评审客观、公平、公正的进行,是科技评价研究中的重要课题之一。同行评议是科技管理工作的重要组成部分,也是对科学技术活动及其产出进行科学评价的重要方式,是推动国家科技事业持续健康发展,促进科技资源优化配置,提高科技管理水平的重要手段和保障。然而,在同行评议中,个别专家对评审对象的恶意评议,偏好评议,评议中的“马太效应”、利益冲突、受随机因素干扰等[2-3]现象导致当前科研项目评审中常用的方法失效(如去除最高、最低分,求平均值,加权平均、校正补偿等),不仅干扰了评审工作的客观性与公正性,也严重影响了评价结果的科学性和客观性。
为了防止同行评审中出现的问题影响科研项目评审的公平公正,许多研究者提出了初步的解决方案。文献[2-3]讨论了评审制度的固有缺陷,如专家遴选和监督制度的缺位、学术评审制度缺乏公正合理的程序、学术评审指标存在缺陷等,并提出了相应的改革措施,具有长远意义,但是对于眼下亟待解决的问题并不能起到立竿见影的效果,也没有可具体操作的方法。文献[4-5]提出了评审专家的评审信誉的概念,提出引入专家评审信誉评估机制来反映专家在同行评议过程中的公正性情况,并据此建立评审专家的评审信誉机制,以对评审专家的评审过程进行监督,但是并没有给出具体的执行办法,不具有实用性。文献[6]发现同行评议专家和普通人一样,受到偏见、歧视及其友谊关系的影响,并提出要开发一个新的同行评议系统,目的是在这个新系统中植入人类本性弱点的抗体,但是该系统没有解决女性研究者在同行评议中受到严厉评价是否由女性同行评议人不足引起的。文献[7]分析了人文社会科学评议中同行评议专家容易出现的问题,提出了一个新的方法——“读者系统”,用来提高同行评议的可靠性和公正性,但是该系统没有完全合适的标准来验证同行评议的结果。文献[8]对比了传统同行评议和开放同行评议的异同,指出传统同行评议的可信度较低,而且存在可靠性问题,提出了新的评估方法ACP系统,但是在该系统中同行评议过程的质量不高。文献[9]提出了评分偏差模型,计算异常评分偏差、科研项目争议性和专家评分惯性,对异常评分进行预测,模型过于复杂,其提出的“争议临界度”范围难以确定,导致其可操作性较差。文献[10]从项目的争议性和专家评审的偏移性两个角度,通过小样本稳健性异常数据检测,来进行专家评审异常数据的处理,但其采用的熵值并不能准确反映出异常数据稳定程度,难以保证修正结果的客观性。另外,也有一些用于异常数据检测的数理统计方法如属性相关分析、基于混沌的异常数据的动态识别、基于知识粒度的挖掘等方法被提出[11],其主要面向大规模海量数据,对小样本数据的处理效率较低,且具体操作对于科技管理人员较为复杂,可用性较差。
云模型[12]作为一种不确定性转换模型能够综合考虑模糊性和随机性,可以应用到异常数据检测中,提高检测结果的质量。如文献[13]提出利用云模型检测谐波电流的异常阈值,确定出的异常阈值数据更加符合客观实际。文献[14]提出利用云模型检测网络异常数据,降低了入侵检测算法的误报率。文献[15]提出利用云模型处理图像阈值,提高了图像变换的性能。文献[16]提出利用云模型计算服务质量的不确定值,可以为用户提供可靠有效的最佳服务选择。文献[17]利用云模型改进果蝇优化算法,提高了算法的全局搜索能力和解的精度。现行的科技项目评审多数是采用同行专家打分的方式确定评审结果,所以要保证评审的客观公正,首要前提就是要能够准确的找出评审中存在的异常数据。同时科学研究是对未知世界的探索,评审专家对科学问题的评判是一个基于自身知识背景的独立判断过程,所以专家打分(评审数据)就具有了模糊性和随机性等不确定性特征。本文利用云模型在表达定性概念与定量数据转换关系上的优势,提出了一种基于云模型的专家评审异常数据的检测方法,通过熵和超熵来评估专家评审数据的异常程度,然后通过协同过滤对异常数据进行修正,最后通过构建专家评审能力计算模型,为后续评审的专家的选择提供参考依据。为了验证本文方法的有效性,本文采用某科研项目评审中真实专家评审数据对该方法进行了验证,结果表明,该方法不仅能够有效识别出评审专家的异常数据,而且还能对异常数据进行有效修正,从而为保证科研项目评审的科学性和公平性提供技术支撑。
本文第2节介绍提出的异常数据检测方法,包括异常数据检测,异常数据修正,专家评审能力计算等;第3节通过真实的数据验证了本文方法的有效性;第4节总结全文提出下一步研究方向。
二、专家评审中异常数据的检测方法
如图1所示,我们提出的专家评审中异常数据的检测方法主要包含三个模块(部分)。模块1即异常数据检测,其目的是发现专家评审数据中的异常数据,其原理是采用云模型对所有专家的评审数据进行熵和超熵计算,然后根据管理人员设置的评审可信度进行检测。模块2即异常数据修正,其目的是屏蔽异常评审数据对评审公平性的负面影响,其原理是依据专家评审相似性,采用协同过滤中的余弦相似度,对该专家的异常评审数据进行合理修正。模块3即专家评审能力计算,其目的是为后续评审中的专家选择提供参考,其原理是根据评审专家在历次评审过程中的表现,采用加权平均对专家评审能力进行计算。
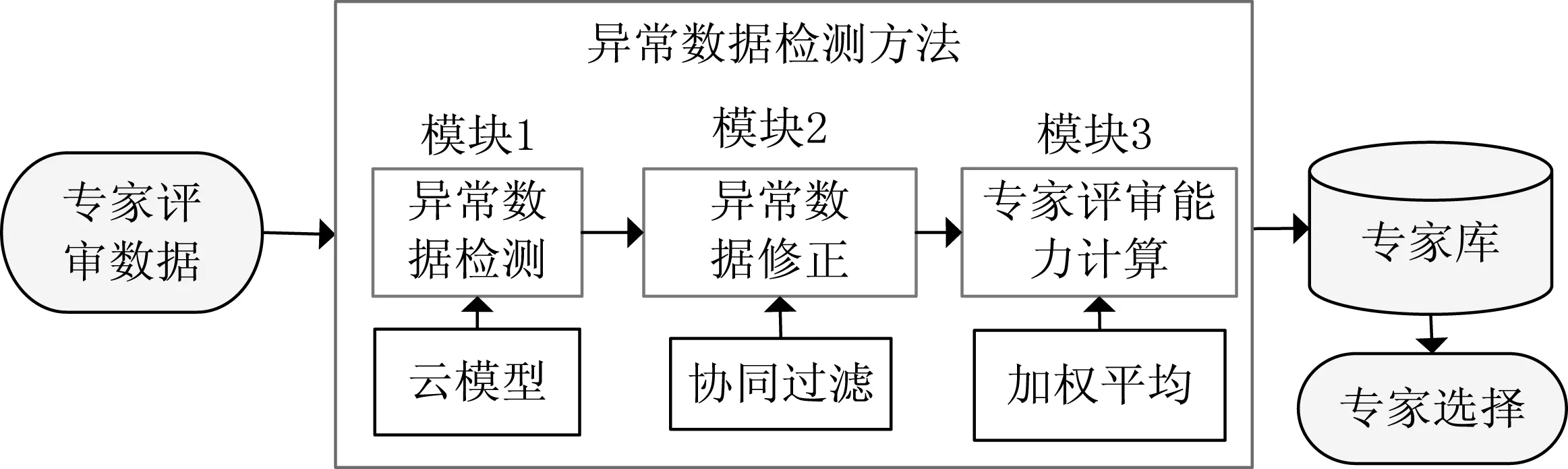
图1 异常数据检测方法框架
(一)异常数据检测
本文采用云模型对专家评审数据进行检测,通过对专家评审数据定量到定性概念的转换,确定评审数据的异常性。首先有针对性的给出云模型的部分相关概念和定义。
1.云模型
云模型[12]是我国学者李德毅院士在概率理论和模糊集合理论基础上,重点考虑随机性和模糊性的关联性而发展起来的定性知识描述和定性概念与其定量数值表示之间的不确定性转换模型,已经在智能控制、模糊评测、进化计算等多个领域得到应用[18-20]。
如图2所示,云模型所表达的概念的整体特性可以用云的数字特征来反映。云用期望Ex(expected value)、熵En(entropy)、超熵He(hyper entropy)这3个数字特征来整体表征一个概念。
期望(expected value):云滴在论域空间分布的期望,记为Ex。
熵(entropy):不确定性程度,由概念的模糊性和随机性共同决定,记为En。
超熵(hyper entropy):熵的不确定性度量,即熵的熵,由熵的模糊性和随机性共同决定,记为He。

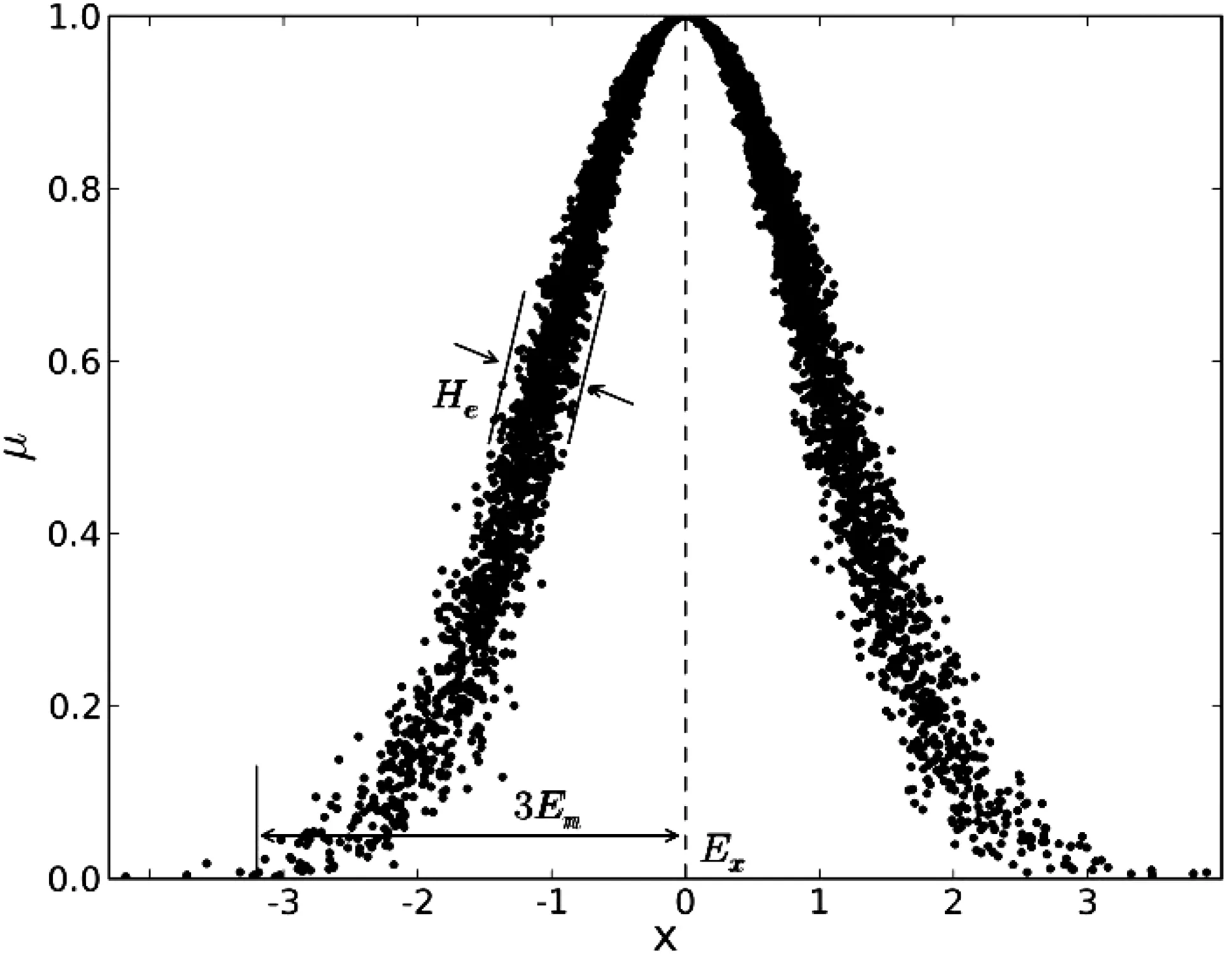
图2 云模型数字特征[12]
图2中,横坐标x是数据的取值,纵坐标μ是该数据对云模型的隶属度。图中Ex为期望,En为熵,度量样本不确定程度,He为超熵,指熵的熵。
算法1:逆向云算法[12]:

输入:某个专家对n个科研项目的评审数据,即n个云滴x1,x2,…,xn{};输出:这n个云滴表示该专家的期望值Ex、熵En和超熵He; 1.根据xi计算该组评分的样本均值X-=1n∑ni=1xi,样本方差S2=1n-1xi-X-()2;2.Ex的估计值为Ex^=X-;3.En的估计值为Ee^=π/2N∑Ni=1xi-Ex^;4.He的估计值为He^=S2-Ee^2。
2.基于云模型的异常数据检测
云模型中,当超熵He=0时,此时所有的云滴都分布在正态曲线上;随着超熵He逐渐增大,云滴开始分散。如图3所示,当He在一定范围内变化时,几乎全部的云滴落在内、外隶属曲线μ1,μ2内,呈现图中所示的正态云[12]。其中μ1,μ2的表达式依次为
(1)
(2)
图3中,横坐标x是数据的取值,纵坐标μ是该数据对云模型的隶属度。μ1,μ2分别为其内、外隶属曲线,大约99.74%的云滴分布在二者之间的区域。

图3 正态云的内、外隶属曲线及其3S边界
当选取m个专家对n个科研项目进行评审时,易知可以得到m×n个评审数据。科技管理人员可以设置评审的可信度为Δ(由于专家评审数据基本都是可信的,因此Δ取值一般不小于90%),此时,通过K=(1-Δ)×m×n可以得到需要检测出的异常数据的个数。对上面所得到的异常程度值进行排名,选取取值最大的K个,即获得topK个异常评审数据。在此基础上可以计算某位专家所有评分的异常程度值的均值,或者topK个异常评审数据中该专家所占的个数等等。计算评审数据的异常程度值的具体实现如算法2所示。
算法2:基于异常程度排序的topK算法

输入:m个专家,n个科研项目的评审数据矩阵;输出:K个异常程度最高的评审数据;

1.对评审数据矩阵进行归一化处理,并运用云模型,计算每个科研项目的云模型特征值,分别是期望Ex,熵En和超熵He;2.对每个科研项目,计算其外边界L=3(En+3He);3.计算所有科研项目的外边界的均值LM=mean(L);4.对每个评审数据d,计算其异常程度|d-Ex|LM,其中Ex是该d所属科研项目的评分期望值,由此得到异常程度矩阵(该矩阵和评审数据矩阵的元素是一一对应);5.求解出异常程度矩阵中的K个最大元素对应的评审数据即为异常评审数据。
(二)基于协同过滤的异常数据修正

算法3中计算向量相似度的方法有欧氏距离、皮尔逊相似度、余弦相似度等。通过大量验证,使用这几种计算相似度的方法对异常数据检测的最终结果没有明显的影响,因此,本文采用余弦相似度即两个向量夹角的余弦值来进行修正。
算法3:基于协同过滤的异常数据修正算法

输入:m个专家对n个科研项目的评审数据矩阵;输出:第i个专家对第j个科研项目的评审数据的修正值scoreij。

1.由评审数据矩阵得到专家m对科研项目n的评分组成的向量,表示为Vmn;2.由评审数据矩阵得到专家m对科研项目j的评分score1j,score2j,…,scoremj;3.计算向量Vi与其他剩余向量的相似度,标记为Si1,Si2,…,Sin-1;4.计算修正值scoreij=1m-1∑nj=1Sij·scoreij。
(三)专家评审能力计算模型
本文提出的专家评审能力计算模型,能够根据评审专家在历次评审过程中的表现,基于logsig函数,实现对专家评审能力值的准确计算。
logsig函数是关于原点中央对称的单调递增函数,其一阶导数图像为倒挂的钟形曲线,对于任意输入,logsig函数都能将其转换成(0,1)区间的输出值。由于其优异的函数性能,logsig函数作为传输函数在神经网络算法中发挥了重要作用。
在logsig函数的基础上,本文提出了专家评审能力计算模型,其中λ是可调参数,用于调整函数曲线的陡峭程度,n 是输入参数,函数曲线及可调参数λ的作用如图4所示。
(3)
由图4可知,当输入n值为负数且绝对值较大时,函数值接近于0;当n值为正数且绝对值较大时,函数值接近于1;n在0附近时函数值变化剧烈。
函数表达式中n为自变量,λ为可调参数,用于控制函数值的变化强度和作用区域。从图4可以看出,当可调参数λ值较大时,函数曲线比较陡,有效的变化区间较小;当λ值较小时,函数曲线较为平缓,有效的变化区间较大。用于专家评审能力计算动态模型的logsig函数需要设置合适的λ参数值。

图4 经修改的logsig函数示意图
本文对每一个评审专家Oi,给其附加一个变量ni,初始值设置为0,由图4可以看出,所有评审专家的初始评审能力值相等,其评分可信度相同。以后每次评审后,如果该专家表现良好,将ni值增加1,所以其评审能力值增加;如果该专家有不合理评审的嫌疑,则将ni值减1,所以其评审能力值降低,具体实现见算法4所示。
算法4:专家评审能力计算

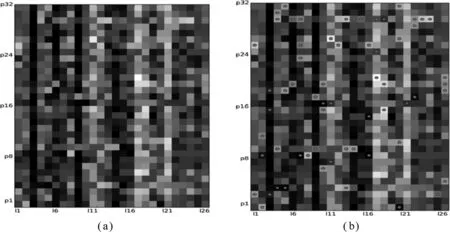
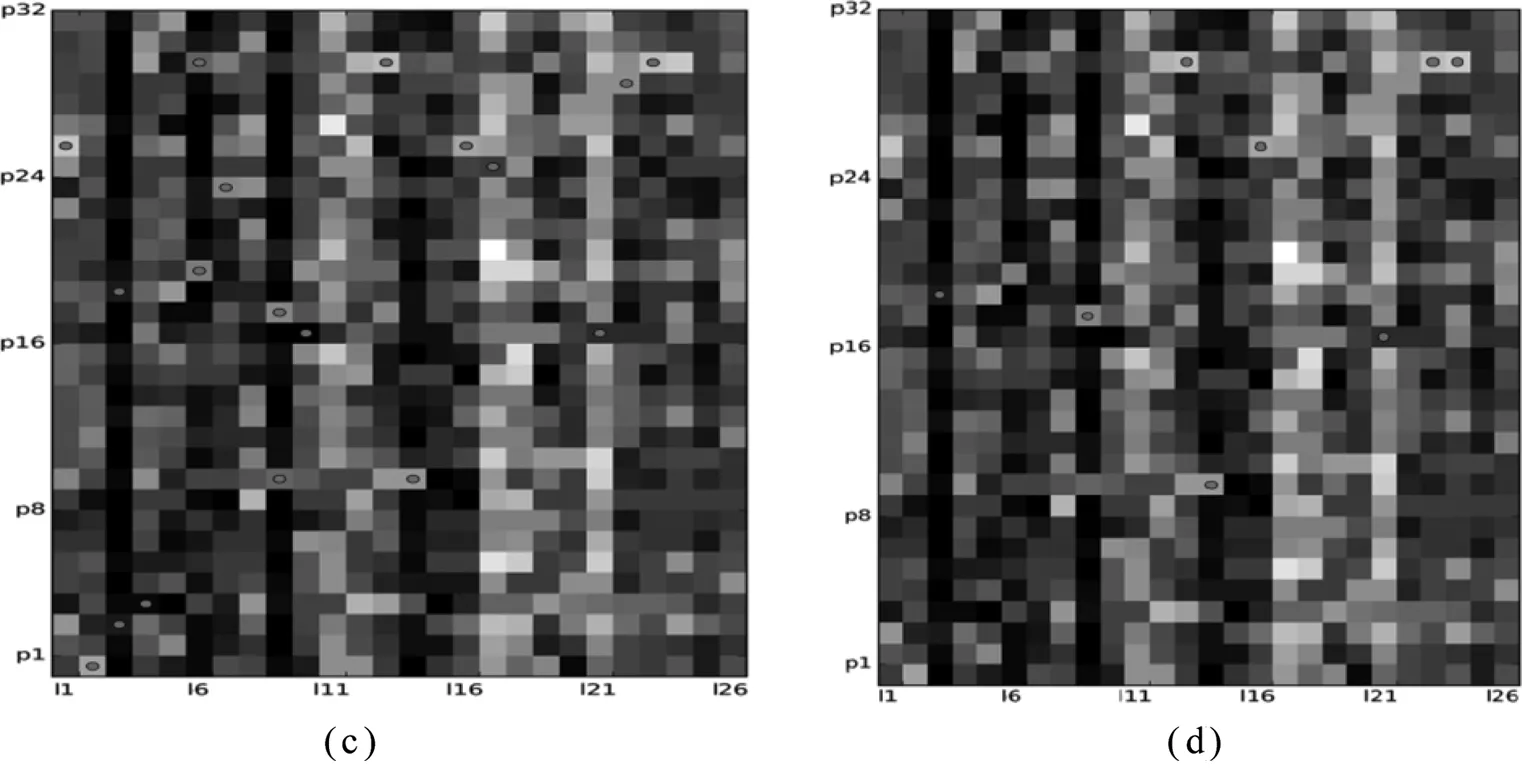
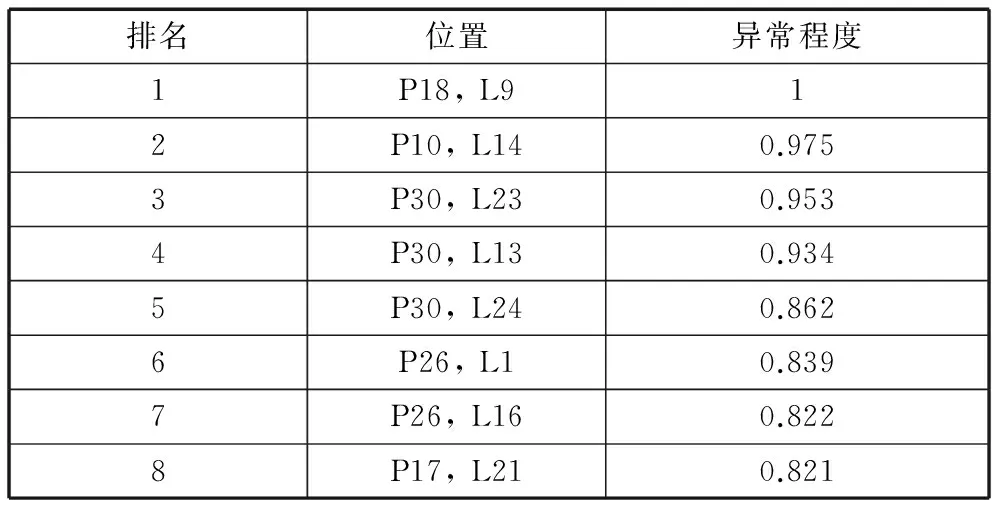
输入:专家的历史评审数据的列表LC及计数值n的上界Nmax和下界Nmin;输出:专家当前的评审能力R。 1.初始化n=0;2.对LC每一个元素,也就是该评审专家在对应的评审中的表现值,如果表现正常,n值加1,否则n值减1。如果n>Nmax或者n 计算出该专家的评审能力后,将专家的评审能力作为权重对评审数据进行加权求和求均值,将所得到的结果作为最终评分,将更加科学和公平。通过这种方式,评审能力高的专家评分的影响力大,评审能力低的专家评分的影响力小,符合公正性的基本要求。假设某个科研项目由n个专家评审,第i个专家的评审能力值为Ri,评分为Scorei,则其最终得分Score可由如下公式获得: (4) 对评审专家进行评审能力的计算还可以用于专家评审能力的排名。根据每次的评审数据,可以更新专家的评审能力,基于该值,可以对评审专家进行评审能力排名,并为后续科研项目评审过程中的专家选择提供参考。 本实验基于某类科研项目评审时的真实专家评审数据对本文提出的异常数据检测、异常数据修正及专家评审能力计算等方法进行验证分析,根据科研项目管理要求,我们对数据进行了归一化处理。 (一)异常数据检测结果 如表1所示,本实验所采用的数据源于真实的(归一化处理后)科研项目的评审数据,表格中的列表示26个科研项目,分别用符号L1,L2…L26表示;行表示32个评审专家,分别用符号P1,P2…P32表示;表格中的数据表示某评审专家对某科研项目的评分。 图5给出了基于云模型的异常数据检测结果。图5(a)是用归一化后的评审数据做出的灰度图,横轴表示26个科研项目,纵轴表示32个评审专家,每个格子表示某评审专家对某科研项目的评分,格子的灰度表示评分的大小,灰度越深,评分越高,灰度越浅,评分越低。图5(b)、图5(c)和图5(d)在图5(a)的灰度图上分别标出了不同的topK所检测出的异常值,并在异常值的位置标上圆点。通过选取不同的Δ值,被判为异常数据的数目也将不同。例如,图5(d)给出了topK=8情况下的异常数据。表2是对应的异常程度最大的8个评审数据,每个数据有其排名、位置和异常程度量化值。图5和表2表明本文提出的方法能够有效地进行异常数据检测。 表1归一化后的原始评审数据 图5 基于云模型的异常检测模型测试示意图 排名位置异常程度1P18,L912P10,L140.9753P30,L230.9534P30,L130.9345P30,L240.8626P26,L10.8397P26,L160.8228P17,L210.821 基于上述实验结果可以看出,在未对异常数据检测之前,科研项目评审排序为:3, 9, 6, 14, 15, 25, 7, 16, 23, 13, 22, 5, 19, 2, 10, 20, 24, 4, 1, 26, 8, 12, 18, 11, 21, 17。采用本文提出的方法后,删除异常数据P18后,科研项目的排序变为:3, 9, 6, 14, 15, 25, 7, 16, 13, 23, 22, 5, 19, 2, 10, 24, 4, 20, 26, 1, 8, 12, 11, 18, 21, 17。 (二)数据修正 本实验将对异常程度最高的评审数据进行修正,即将异常值位置(P18,L9)中第18号评审专家对第9号科研项目的评分进行修正,首先依次计算评审专家P18与其他31位评审专家的相似度,即 0.99890.99920.99870.99820.99900.99910.99940.99880.99820.99860.99870.99920.99930.99920.99860.99850.99870.99880.99850.99900.99920.99910.99880.99900.99790.99890.99860.99810.99860.99880.9983 然后,从表1中得到其他31位评审专家对9号科研项目的评分是 0.98951.00001.00000.97950.98961.00000.98951.00001.00000.86590.97930.97891.00001.00000.98960.97891.00001.00000.98960.95911.00001.00000.95831.00001.00001.00001.00001.00000.93871.00000.9896 最后,对31位评审专家的评分关于相似度求加权平均值得0.9852,即用该值替换异常数据0.82。 (三)专家评审能力计算结果 实验结果如图6所示,显示了某个评审专家在50次评审过程中的表现及其评审能力值变化情况。图6(a)中横轴为评审次数,纵轴为该专家在历次评审中的表现情况,有“1/-1”两个取值,取值“1”表示该专家表现正常,提高其评审能力值;取值“-1”表示该专家有不合理评分嫌疑,要降低其评审能力值。图6(b)与图6(a)对应,表示其评审能力值随其在历次评审中的表现情况的动态变化,横轴也为评审次数,纵轴为其评审能力值。 由图6可以看出,依据本文提出的专家评审能力值计算模型计算出的评审能力值能够反映评审专家在评审历史中的表现情况,具有较好的效果。 图6 某评审专家评审能力值的动态计算 本文提出了一种基于云模型的异常数据检测方法,并通过软件编程实现了异常数据检测、数据修正及专家评审能力计算等一系列功能,为科研管理人员高效、准确地找出并修正不合理评审数据提供了方法和技术的支撑,为评审专家的遴选提供参考,从而提高科研项目评审的科学性和公正性。该方法也适用于其他具有同行评议性质的项目评审,具有较好的普适性和可扩展性,不但可以用来处理定量的评分数据(如本文实验部分所采用的数据类型),还能够处理定性的评分数据(在预处理过程中将定性数据进行量化)。但是需要说明的是,并不是本文方法检测出所有的异常数据都是影响科研项目评审公正性的不合理数据,科研管理人员需要结合评审实际情况对异常数据进行具体分析判断。比如某位专家由于自身的学科或专业背景所限,导致其评审意见和大部分专家不一致,可能说明该专家对所参加评审的领域不熟悉,不适合此类科研项目评审;再比如某位评审专家的看法很独特,而事实又证明这位专家恰恰是“掌握真理的少数”,则说明这位专家对相关学科有前瞻性的认识,科研管理部门应对其观点应该予以尊重和重点采纳。本文构建的模型可以作为对同行评议过程再评估的一种方法,为科研管理部门的决策和监督提供参考。 就本文方法的适用范围而言,如果评审专家和项目数量较少时,该方法的性能优势并不明显,因此本文方法更适合于评审专家数量较多的重点或重大科研项目的评审。另外,由于算法中涉及到某些参数的设置,因此如何基于大量的历史评审数据和管理反馈数据,运用大数据技术(如神经网络、数据挖掘等)获得准确的参数设置或参数的自适应动态设置将是本文未来的研究重点。 致谢 感谢北京邮电大学的许金良博士,王尚广副教授对本文的技术支持。 [1] 彭以祺,杨晓秋.实验室评估的现状作用和若干建议[J].中国基础科学,2000 (7) :29-32. [2]龚旭.同行评议公正性的影响因素分析[J].科学学研究,2005,22(6) :613-618. [3]江新华.论我国学术评审制度的缺陷与创新[J].科学学研究,2006,23(5) :618-622. [4] 程梅珍.建立科技咨询机构信誉评审体系的原则及实施步骤[J].科学学与科学技术管理,2000,21(5):54-55. [5] 黄进.科学基金项目评审专家科研信誉综合评价体系研究: 基于 “能力-行为-绩效” 的视角[J].中国科学基金,2012,(1):57-60. [6]Wenneras C, Wold A.Nepotism and sexism in peer-review [J].Nature, 1997,(387) :341-343. [7]Marsh H,Jayasinghe U,Bond N.Improving the peer-review process for grant applications:Reliability, validity, bias, and generalizability [J].American Psychologist,2008,63(3) :160-168. [8]Bornmann L,Daniel, H.Reliability of reviewers’ ratings when using public peer review:A case study [J].Learned Publishing,2010,23(2) :124-131. [9] 唐光杰.科技评审中评分偏差模型的研究与应用[D].中南大学,2012. [10] 张金焕.科技评价中专家评审粗差数据的处理及仿真[J].计算机仿真,2013,30(7) :214-217. [11] Li D,Meng H,Shi X.Membership clouds and membership cloud generators [J].Journal of Computer Research and Development,1995,32(6) :15-20. [12]王国胤,李德毅,姚一豫,等.云模型与粒计算[M].科学出版社,2012. [13]余南华,李兰芳,王玲,等.基于云模型的谐波电流异常检测[J].中国电机工程学报,2014,25:4395-4401. [14]党倩,骆嘉伟,王东.一种基于云理论的异常检测算法研究[J].计算机应用研究,2009,10:3724-3726. [15]Wu T,Xiao J,Qin K,Chen Y.Cloud model-based method for range-constrained thresholding [J]. Computers and Electrical Engineering,2015,42:33-48. [16] Wang S,Zheng Z,Sun Q,Zou H,Yang F. Cloud model for service selection.Proceedings of the 30th IEEE Conference on Computer Communications Workshops, 2011.pp.666-671. [17]Wu L,Zuo C,Zhang H.A cloud model based fruit fly optimization algorithm [J].Knowledge-Based Systems,2015,89:603-617. [18]李德毅,刘常昱,杜鹢,等.不确定性人工智能[J].软件学报,2004,15(11):1583-1594. [19] Zhang G, He R,Liu Y,Li D.An evolutionary algorithm based on cloud model [J].Chinese Journal of Computers,2008,07:1082-1091. [20]王尚广,孙其博,张光卫,杨放春.基于云模型的不确定性QoS感知的Skyline服务选择[J].软件学报,2012,06:1397-1412. (本文责编:海洋) Research on Abnormal Data Detection in Peer Review——An Example of Scientific Project Evaluation YANG Xiao-qiu, LI Xu-yan (BasicResearchServiceMinistryofScienceandTechnologyofthePeople’sRepublicofChina,Beijing,100862,China) Currently peer review is one of the main effective methods to evaluate the scientific projects.However, existing abnormal data seriously affects the fairness and justice of the final evaluation results. In this paper, we propose a detection method for identifying experts’ abnormal review data. Firstly, based on backward cloud algorithm we compute the scalar quantity representing the abnormal level of every review data; then, according to detection result, we adjust the abnormal data with a new one given by the collaborative filtering algorithm; and finally, we designed an algorithm to quantize the review ability of every expert concerned, which will serve well in the next peer review process.Experiments using real dataset show the effectiveness of the proposed methods. scientific project evaluation; peer review; cloudmodel; collaborative filtering; abnormal detection; reputation calculation. 2015-10-14 2016-04-10 国家软科学研究计划项目“科技计划管理改革实施效果与优化策略研究”(2013GXS6K206)。 杨晓秋(1964-),女,河北遵化人,高级工程师,硕士研究生,主要研究方向为科技政策与科研管理等。 G311,N031,TP18 A 1002-9753(2016)05-0133-10三、实验分析




四、总结
猜你喜欢
江苏安全生产(2022年9期)2022-11-02
江科学术研究(2022年3期)2022-09-26
计算机应用(2022年2期)2022-03-01
航天工业管理(2020年11期)2021-01-04
航天工业管理(2020年1期)2020-04-20
人大建设(2017年2期)2017-07-21
中华诗词(2017年10期)2017-04-18
宠物世界·猫迷(2016年3期)2016-04-23
中国科技期刊研究(2016年11期)2016-04-17
少儿科学周刊·少年版(2015年3期)2015-07-07
