
基于Drupal的图书馆知识交流共享平台构建
2016-08-23 09:58:23魏太亮廖思琴
现代情报 2016年3期
周 宇 魏太亮 廖思琴
(1.南京大学信息管理学院,江苏 南京 210023;2.西南科技大学图书馆,四川 绵阳 621010;
3.中共四川省委党校图书馆,四川 成都 610071)
·应用研究·
基于Drupal的图书馆知识交流共享平台构建
周 宇1,2魏太亮3廖思琴2
(1.南京大学信息管理学院,江苏 南京 210023;2.西南科技大学图书馆,四川 绵阳 621010;
3.中共四川省委党校图书馆,四川 成都 610071)
当前国内图书馆知识交流共享平台少有针对读者提交资源(如科研数据、读者使用和生成内容)的存储、监管和服务,也没有将上述数据与开放数据云进行整合。研究利用社会开源内容管理系统Drupal构建图书馆知识交流共享平台的方法,用以提供读者学术信息交流、科研数据监管、读者生成和使用内容管理和服务。研究过程包括:(1)分析图书馆和读者对平台的需求;(2)平台功能和体系结构设计;(3)介绍用Drupal来构建平台的方法;(4)探讨利用平台进行科研数据监管和数据语义描述和关联的方法。针对图书馆知识交流平台在大数据和开放数据云环境下的未来发展提出一系列对策和建议。
Drupal;知识共享;知识服务;信息系统开发
Web2.0环境下,图书馆不仅要提供各种海量的经过有效集成的数字化信息资源,还要积极考虑针对科研数据、读者生成内容、读者使用内容等读者提交内容的管理和服务,同时让读者基于上述数据进行有效的读者与馆员、读者与专家、读者与读者之间的信息和知识交流。科研数据指科学研究中通过测算、计量、观察、访谈、调查、设计、建模等方法获得的,并能以现代信息技术保存和获取的记录[1],譬如在线问卷调查的原始记录、新型材料性能测试的中间记录等。 英国联合信息系统委员会JISC列举了对科研数据进行管理的7个原因,包括(1)为新研究重用数据;(2)从大量数据集中发现新的科学知识;(3)保护独一无二的不可重现的观察数据;(4)保留通过昂贵手段获取的数据;(5)加强当前数据对科研项目的可用性;(6)保管法律要求保护的重要数据;(7)验证公开发布的研究结论[2]。读者生成内容指以任何形式在网络上发表的由读者创作的文字、图片、音频、视频等内容[3]。读者使用内容指读者在学习和科研活动中利用的各种图书馆尚未保存的参考资料和软件。根据长尾理论,当读者具有独特信息资源需求并且可以创建和交流这些信息资源的时候,虽然单个读者所创建和交流的信息资源量并不多,但所有读者所创建和使用的信息资源总量所占据的份额,可以和主流信息资源市场份额相当,甚至更大[4]。这些信息资源,再加上读者的解读、描述、评价和建议,变成了可资利用的知识。因此,如何管理和传播读者创建和使用的信息或知识是图书馆的一项重要工作。随着网络传播技术的发展,读者对知识共享的要求日益提升,读者只有通过知识的交流才能实现知识创新,知识也只有通过共享才能实现其价值。美国科学社会学家罗伯特·默顿(Robert K.Merton) 指出,任何科研成果都是社会协作的产物,并且应该分配给全体社会成员,发现者和发明者不应据为私有[5]。图书馆是国家和政府为满足人们知识共享的需要而提供的一种制度性公共产品[6],为了营造一种高效率的知识共享空间,知识交流共享平台的建设就被提上了议程。知识交流共享平台是指图书馆提供的以现代信息技术为基础,集合信息资源的加载、审核、发布、查阅、检索、管理、交流等功能为一体的信息资源共享系统,是用户存储和交流知识的重要工具[7]。知识交流共享平台也可以理解为知识共享空间,是基于知识整合,以知识为共享对象,以人为中心,以泛在知识服务为特征,以知识管理为目的交互式网络虚拟空间[8]。广大的图书馆,尤其是中小型图书馆,面临着经费、设备和技术方面的压力,在构建知识交流共享平台的时候,各种开源内容管理系统是一种重要的备选技术方案,而Drupal是其中比较优秀的一种。Drupal允许用户在后台主界面发布、编辑、修改内容,支持协作环境中工作流的创建,对内容结构的定义有着完善的支持。Drupal经初始安装后,仅提供基本的功能框架,需要进行个性化定制,万维网上有大量的模块应用于网站的个性化定制,截至2015年4月,全球有3万多名Web专家在更新Drupal并贡献超过31 000个模块,大量知名机构采用Drupal构建网站,支持RSS、BLOG、Wiki、语义网等Web2.0关键技术[9]。
本研究的目的:(1)从图书馆员和读者两个维度对知识交流共享平台进行需求分析;(2)对图书馆知识交流共享平台进行功能设计和结构设计;(3)制定一套科研数据监管元数据描述建议,探讨利用Drupal语义支持模块,把科研数据发布为关联数据的方法;(4)针对大数据和关联数据云环境下的知识交流共享平台建设,提出对策和建议。
1 相关研究综述
在知识交流共享平台设计理念方面,曾群提出了泛在网络环境下高校知识共享平台资源建设系统架构和遵循整体化、系统化、特色化、实用化的信息资源建设思想[7]。熊回香提出一个基于Web3.0的虚拟团队知识共享平台架构模型,包括多平台跨语言知识交互、个性化知识服务、知识存储3个模块。并认为Web3.0的特征(如跨平台多终端信息交互、个性化信息聚合、跨语言服务等)可以为知识共享平台建设提供技术支撑[10]。张曾昱和于秀芬构建了高校教师隐性知识交流的掌上虚拟社区,核心是针对专业前沿、交叉学科和教育技能,按照隐性知识交流主题确立、建立交流关系、隐形知识存储流程来构建平台[11]。
在知识交流共享平台设计实践方面,刘会婷等人基于Drupal构建了护理学学科信息服务平台,整合医院图书馆馆藏资源,为护理人员提供文献资源推送、标签云揭示、个性化定制等Web2.0信息服务[12]。赵乃瑄和王海燕运用Drupal和第三方模块构建了图书馆“学海拾贝”专栏,实现了新闻、娱乐和信息素质教育视听资源的内容管理[13]。李丹等人利用Drupal及其扩展模块,实现了一个混搭(Mashup)平台,及时发布来自异构数据源(如OPAC、RSS新闻、Google图书)的数据[14]。当前少有知识交流共享平台用于语义扩展研究实践,夏翠娟等人利用Drupal和3组关联数据支持模块,将“中国历史纪年和公元纪年对照表”发布成关联数据[15]。任瑞娟等人使用Drupal7工具,利用各种语义网模块,实现了学位论文、书目信息等多类型学术资源的语义层面的集成[16]。
从国内的研究进展可以看出,当前图书馆重视知识交流共享系统的构建,有意识地建立读者和各领域专家之间的交流,建立读者和图书馆信息资源之间的连接,但国内图书馆知识交流共享平台少有针对科研数据、读者使用和生成内容的存储、监管和服务,也没有将上述数据进行语义化扩展并与开放数据云进行整合。Drupal内容管理系统在图书馆中的应用是当前研究热点,遵循着从各种模块安装到通过混搭(Mashup)平台集成异构数据源,再到利用语义网模块实现多类型学术资源的语义关联的发展路径,从封闭发展到开放,从数据集成发展到语义集成。本文研究利用Drupal开源内容管理系统来构建一个主要针对科研数据、读者使用和生成内容的存储、监管和服务的图书馆知识交流共享平台。
2 需求分析
2.1 读者的需求
知识交流共享平台对读者的价值主要体现在:(1)随着万维网上的免费信息资源越来越少,大量参考资料、工具性软件、在线交流记录和科研活动过程中产生的数据需要存储并重复使用;(2)不少科研项目资助机构要求所有实验数据和研究成果必须呈缴到图书馆并被他人共享;(3)为读者提供一个知识交流和协作创新的环境。
读者对知识交流平台的需求包括:(1)能够存取日常学习中用到的学习资料(如课件、视频、音频、图形图像、软件);(2)能够存取科研过程中产生的研究数据和实验数据;(3)能够上传自己的创意(如论文、算法、模型、模拟等)并能和有相同兴趣爱好的同学分享,通过协作开发,集合多人智力进行完善;(4)能在线交流,交流内容可以保存。
2.2 图书馆的需求
作为数字图书馆资源检索平台的辅助系统,图书馆在构建知识交流共享平台时考虑的因素有:(1)操作维护简便、可扩展性强、节约经费和人力、面向Web2.0技术、存储安全和长期保存;(2)能够对读者上传的数据进行审核、编辑和发布;(3)能够以此为契机,进一步对读者创建内容中最具价值的部分—科研过程中产生的研究数据和实验数据进行数据管理;(4)能够提供对系统和数据的安全保障;(5)随着资源数量的激增,引入分布式云存储以及能够提供对大数据的分析;(6)能够将科研数据以关联数据的形式发布。另外,图书馆有意愿保存和监管的数据包括读者生成内容中的学术兴趣型数据(不包括娱乐型、社交型、商业型和舆论型数据)、准确、完整、非拷贝的科研数据、无知识产权纠纷的参考资料和软件。
3 平台设计
3.1 平台目标
本文设计的图书馆知识交流共享平台的目标是提供读者在学习和科研活动中产生和使用数据的存储、审核、发布、检索、下载,提供支持读者知识交流的环境以及多人协作创新环境,支持知识的有效集成以及在此基础上的知识创新,此外,还包括对读者创建内容生命周期的数据监管。平台的使用者和资源建设者是读者,平台的管理者和数据的集成者是图书馆员。
3.2 功能和结构设计
根据图书馆和读者的需求,交流共享平台根据功能被划分为服务层、数据管理层和数据存储层,见图1。在服务层,软件管理模块提供读者上传和下载各种软件或者自己开发的信息系统,“系统仿真”是一个衍生功能,用于在服务器上真实安装读者开发的信息系统,可在线进行运行和演示;经典文献模块提供读者上传和下载各种参考文献,这些文献可能与图书馆文献资源重复;科研数据模块提供读者上传和下载科研数据,由数据提供者通过接口进行语义描述,确保科研数据可被其他读者进行运行、验证和使用;检索模块提供读者一站式检索平台中的所有内容;论坛模块发布重点热点问题提供读者讨论;博客/文章模块提供读者创建自己的博客或者发布一些自创的文章;在线交流模块提供读者利用PC端或者移动终端进行在线交流,所有交流记录被保存在知识库中。在数据管理层,平台提供一系列功能用于读者创建内容、科研数据、读者使用内容的管理,包括审核、创建索引、数据集成、数据监管等。在数据存储层,系统针对潜在有价值的记录进行保存,除了读者上传的数据,还包括读者交流记录和论坛留言,这些数据经过整合并链接至关联数据云。
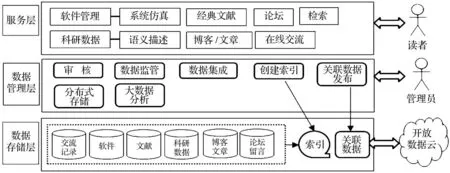
图1 平台功能设计图
在平台的系统架构方面,如果基于传统的集中式访问模式,所有的读者都集中访问一个站点,势必造成主站点不堪重负,而且各学科知识交叉混合,不方便管理。图2为本文设计的主分式图书馆知识交流共享平台体系结构,该结构的特点是建立多个子站点,每个子站点只针对某个读者群进行服务,使用单独的存储空间,每个子站点安装在单独的子站点或虚拟机上。最后,所有子站点的访问接口都集中在一台服务器,即知识交流共享门户,统一对外提供服务。知识交流共享门户会定期从各子站点采集元数据和建立索引,提供针对各子站点的统一检索界面。
每个子站点面对单独的读者群提供服务,对子站点的划分也就是对读者群进行划分,有多种划分方法,如高校图书馆的读者群可按照学院和专业划分,公共图书馆的读者群可按照学科领域进行划分,划分的时候应大致保持子站点的负载均衡。
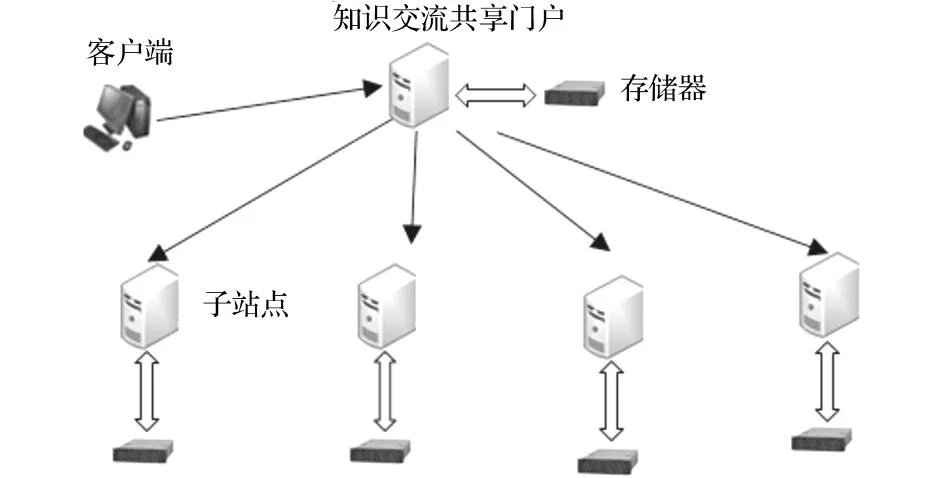
图2 体系结构设计图
4 平台构建
4.1 初始系统安装
(1)配置服务器环境。下载和安装Apache+PHP+MySQL服务器环境,启动Apache和MySQL服务。
(2)安装Drupal。到官网下载最新版Drupal,将其解压缩到Apache的dtdocs文件夹中;进入MySQL管理端,新建一个数据库;打开浏览器,输入“http:∥服务器IP/drupal7/”进入drupal的安装界面进行安装。
4.2 模块选择
刚安装好的Drupal系统功能简单,需要进行个性化定制。功能模块有两个来源:一是Drupal系统内置的模块;二是互联网上WEB开发专家编写的第三方模块。第三方模块是为了弥补Drupal内置的模块功能欠缺,由Web专家开发的具有特定功能的模块。KCSP平台需要用到的模块及功能说明见表1。
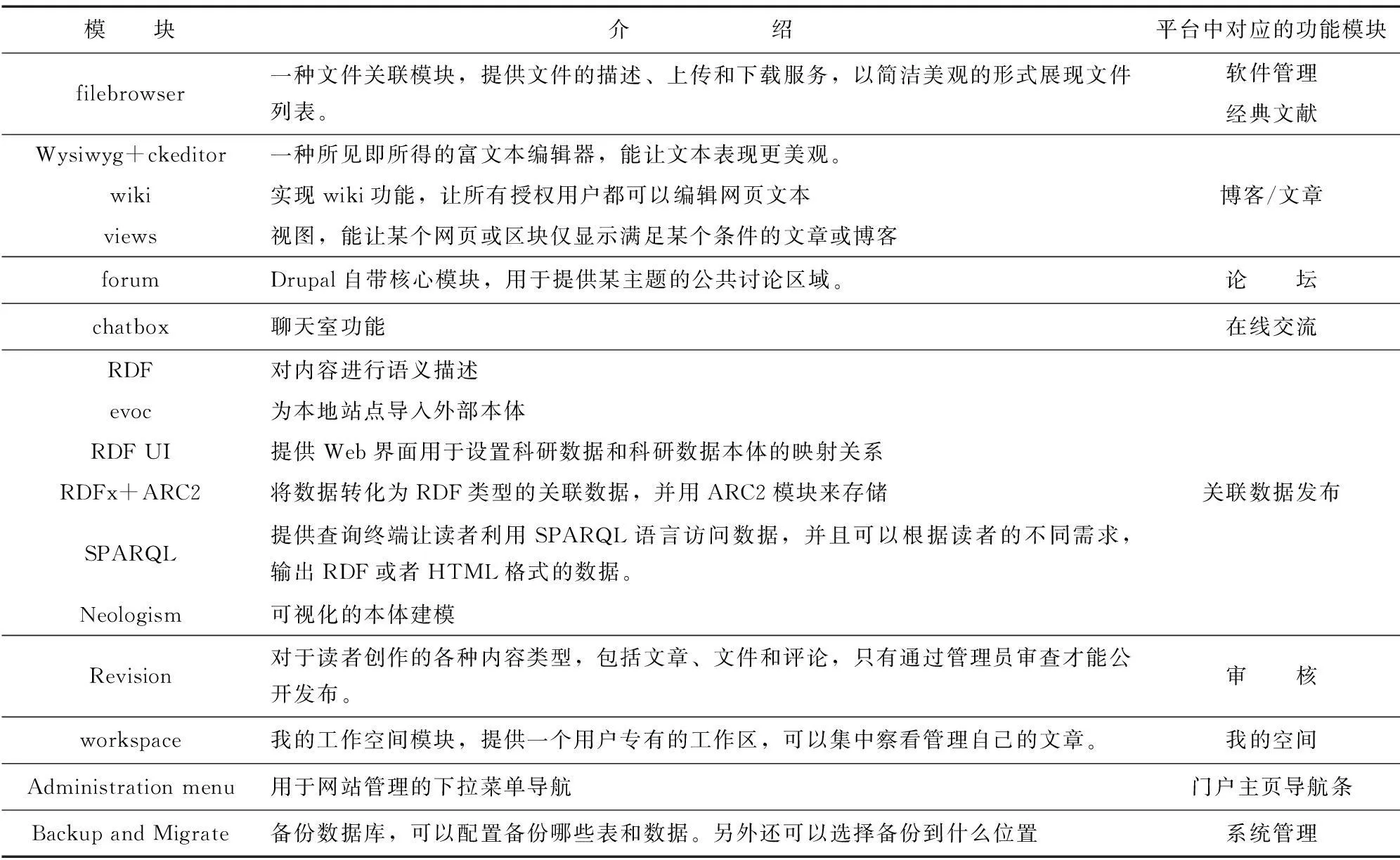
表1 知识交流共享平台所需模块及对应功能(部分)
4.3 模块配置
4.3.1 自带核心模块的配置
以管理员身份登录后,选择“Modules”,在核心模块的列表中选择需要的模块并保存,回到管理控制台,选择“内容”,再选择“添加内容”的时候,就能够选择和使用新添加的模块了,模块创建好之后,可以将其访问入口放置在首页的导航条或任意级别的目录中。
4.3.2 第三方模块的配置
在安装模块的界面,选择“下载其他用户贡献的模块”,输入模块的名称进行检索,检索到模块后有两条路径进行安装:①直接下载模块,将文件解压后拷贝到站点的“sitesallmodules”路径中,然后在后台“模块”界面,启用新安装的模块;②将模块下载地址复制到“安装新模块”界面,点击“安装”即可,见图3。
4.3.3 个性化配置
在一些特殊情况下,对于安装好的模块需要一些个性化配置。比如对于读者撰写的文章以及上传的经典文献,数量太多,需要进行分类目录管理。以“文章”目录管理为例,需要按照如下4个步骤进行配置:
①到“结构”——“分类”里创建需要的文章分类列表;
②到“结构”——“内容类型”——“字段管理”里为所需要的内容类型(Article)添加字段,字段包括想要设立的
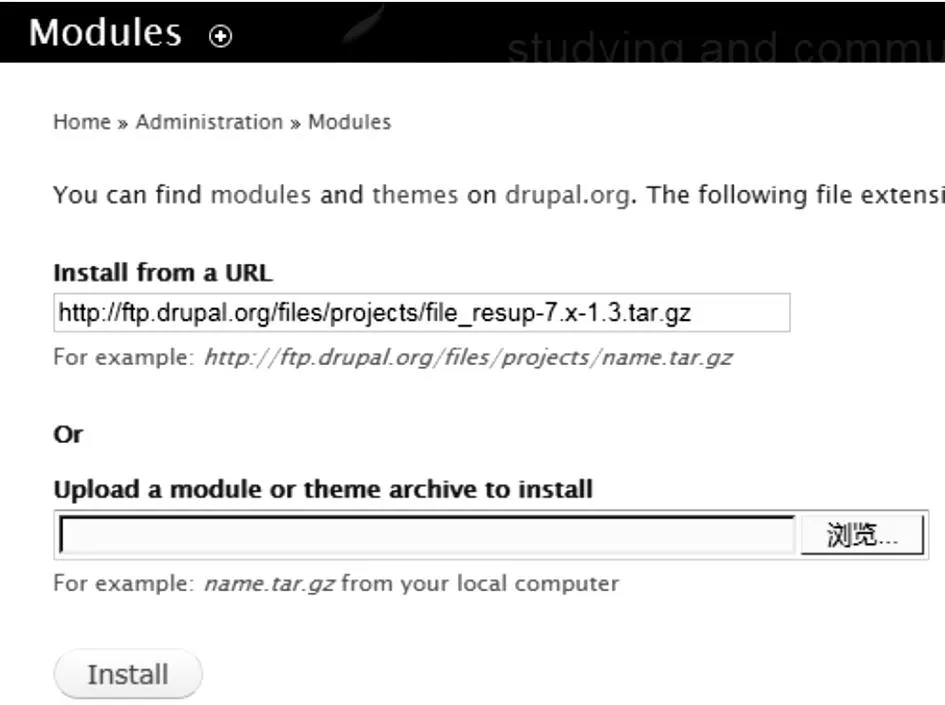
图3 第三方模块下载界面
分类,字段类型选“术语来源”;
③建立多个视图(views),每个视图包含一个术语类目下的所有文章,每个视图对应一个网页,有单独的访问地址;
④建立一个page,里面建立各类目链接,链接到各个视图。
图4展示了文章分类列表界面,用于发表读者的原创性文章,作者可以为文章添加标签,上传附件和指定类别,标签以标签云的形式可视化,点击标签打开包含该标签的文章列表。按照同样的操作,结合图1的功能设计和表1中对应的第三方程序模块,可以很容易开发出论坛、经典文献、软件管理、在线交流等核心功能模块。
图4 利用视图构建的文章分类列表
5 科研数据管理
科研数据图书馆知识交流共享平台中最有价值的知识资产,针对科研数据的管理又叫数据监管、数据策管、数据监护或者Data Curation。VanHorik认为应认真对待具有长期利用价值的科研数据:(1)科研数据必须可以分类查找,体现关联性;(2)必须是可获取的;(3)必须以可使用的数据格式存在,让常用软件可以处理;(4)数据必须是权威可靠的,未经过变动的;(5)数据必须可持久地信赖,数据要有一个唯一标识符,并且保存在可信任数据仓储中[17],即要考虑科研数据的可用性、准确性、完整性、可追溯性和关联性。要达到以上目标,首先需要对科研数据进行完善地描述,表2是本文设计的科研数据监管元数据描述建议,重点揭示科研数据的起源、数据关联、利用方式、修订细节、资源字符集、存储位置、适用软硬件等。

表2 科研数据监管元数据描述建议

表2(续)
注:@prefix dc=http:∥purl.org/dc/elements/1.1 @prefix dcterms=http:∥purl.org/dc/terms/ @prefix rdc=http:∥rdc.example.org/
其次,需要对读者提供提交元数据的接口界面,元数据以RDF格式描述,方便后续语义检索并发布为关联数据。从表2可以看出,对科研数据的语义描述是比较复杂的,读者没有动力来完成所有的描述,描述工作主要由图书馆员承担。而对科研人员提供的是相对简单的接口(如图7所示),屏蔽语义标注的细节[18]。在语义标注时,针对表2中对象属性(譬如BaseSet、RelSet、RelSet等),需要列举其他数据集的URI,从而关联到外部数据集。科研数据可以以文本、电子表格、图形图像、动画、音频视频的格式上传。
对科研数据进行语义化描述并支持语义检索和语义关联,需要用到一些语义支持模块(见表1)。安装好这些模块之后,需要做的工作还包括构建科研数据监管本体、利用evoc导入本体、定义科研数据描述字段与本体属性的对应关系(见图5)、对科研数据进行语义标注(见图6)。
当读者利用知识交流平台获得一份科研数据的时候,可以通过资源属性列表跳转到外部数据集,也可以获取一份RDF文档,读者可以利用该文档的详细描述短时间内就能够应用于科研实验,进行验证、测试和模拟。RDF文档如果被计算机通过网络获取,那么文档信息可以被自动化处理。平台同时提供对外的SPARQL查询终端,为本地站点的RDF数据向互联网开放提供支持。

图5 定义科研数据描述字段与本体属性的对应关系
6 对策和建议
6.1 加强数据的搜集和整理工作,提高数据质量监管水平
图书馆需要设计一套激励机制鼓励读者上传资源。在读者上传的资源当中,有一部份是不成熟、不完整甚至错

图6 科研数据语义标注界面
误的实验方法和数据,有一部份是受版权保护的文献和软件,那么需要经过专业人员鉴别,当有新的研究成果时需要对老旧数据进行更新、防止错误数据随着大范围使用和数据关联蔓延开来[19],最终目标是实现数据必须持久地可信赖[20]。重复提交数据的现象时有发生,如何发现重复性资料,是直接删除还是维持一定的冗余,这也是值得考虑的问题。在所有读者上传的资料中,有一部份资料是常规资料,如网上下载的软件或引用别人的资料,而另外一部份是独有的原始资料,对于后者,要进行深入的揭示和长时间的积累,如针对读者上传的研究数据,系统要求读者进行详细的描述,以确保这些科学研究数据能被他人有效利用,另外,独有的原始资料需要经过长时间的积累才能产生一定的效用和价值。
6.2 加强与开放数据云的关联和集成
2007年W3C发起的Linking Open Data(关联开放数据运动)项目已经实现了将各种开放数据源(如DBpedia、GeoNames、MusicBrainz、WordNet、DBLP等)在Web上发布并进行语义关联,用户可以无缝跳转到关联开放数据云(LOD Cloud)中的任意数据,而不用关心这些数据来自于哪个数据集。截止2014年8月,互联网上已经有1 000余个开放数据集合[21]。读者生成内容和科研数据集中的知识单元如果能和开放数据云中相关的知识单元进行关联,让知识交流共享平台成为开放数据云中的一部分,那么将极大地增强平台的知识价值和吸引力。Drupal的关联数据发布模块已经比较成熟,难点是如何将实例对象属性自动化连接到外部相关知识单元,此外,语义互操作中的本体融合和配准也是需要解决的问题。
6.3 开发具有大数据分析和处理功能的模块
随着时间的积累,读者生成内容、科研数据、读者使用内容的数据量将变得非常庞大,达到PB级,此时需要成熟的大数据分析和处理框架来处理这些数据,从而提供数据推荐、海量数据挖掘(含分类和聚类)、协作网络识别、影响力评估等个性化信息服务。但目前Drupal还没有相关的模块发布,可以考虑用第三方工具如Solr、ZooKeeper、Hadoop框架等来开发。Solr是开放源码的企业搜索服务器软件,在全文检索、分布式搜索和缓存方面表现良好;Apache ZooKeeper为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册;Hadoop是一个由Apache基金会所开发的分布式系统基础架构,包含一个开源的MapReduce框架,可以将PB级数据划分到由多台计算机构成的集群上并行处理,提高处理速度。
7 总 结
随着互联网上读者交流意愿的提升,各种网络社区的活跃和进一步发展,图书馆读者迫切需要一个平台提供对科研数据、读者生成内容、读者使用内容的管理和服务,同时读者需要利用这个平台,以平台中的读者提供资源为基础进行知识交流和共享活动。
本文从图书馆员和读者两个角度对知识交流共享平台进行需求分析,并以此为基础设计了系统的功能结构和体系结构。以图书馆知识交流共享平台的构建为例,介绍了使用Drupal来开发知识交流共享平台的方法,重点介绍了各种功能模块的特点及其配置和使用方法。科研数据是知识交流共享平台中最重要的知识资产,为了保证科研数据的完整性、可用性和准确性,图书馆需要提供针对科研数据的监管服务,包括制定元数据描述标准,提供数据描述接口,将科研数据集成到开放数据云。为了保证科研数据的可靠性和完整性,本文设计了一套推荐性科研数据监管元数据描述规范,包括针对学科数据内容的描述性元数据和针对数据监管的管理性元数据两个部分,介绍了该描述规范在科研数据监管、语义描述、科研数据语义关联中的具体应用。最后,本文针对知识交流共享平台的未来发展提供一系列的对策和建议,包括加强数据的搜集和整理工作,提高数据质量监管水平、加强和开放数据云的关联和集成、开发具有大数据分析和处理功能的模块。
[1]杨鹤林.数据监护:美国高校图书馆的新探索[J].中国图书馆学报,2011(2):18-21,41.
[2]Radovan Vrana.Supporting e-Science:Scientific Research Data Curation[J].Future of Information Sciences Infuture,2011:407-416.
[3]赵宇翔,范哲,朱庆华.用户生成内容(UGC)概念解析及研究进展[J].中国图书馆学报,2012,(5):68-81.
[4]Chris Anderson.长尾巴理论[M].北京:中信出版社,2006,12.
[5]王大珩,于光远.论科学精神[M].北京:中央编译出版社,2001:31-37.
[6]沈小玲.论图书馆的经济学属性——公共物品[J].中国图书馆学报,2001,(1):80-82.
[7]曾群.泛在网络环境下高校知识共享平台资源建设研究[J].情报理论与实践,2013,(9):83-87,77.
[8]吴云珊.泛在图书馆知识共享空间(KC)研究[J].图书情报知识,2013,(1):114-121.
[9]Drupal[EB/OL].https:∥en.wikipedia.org/wiki/Drupal,2015-11-09.
[10]熊回香,王学东,许颖颖.基于Web3.0的虚拟团队知识共享平台建设研究[J].情报科学,2009,(12):1770-1775.
[11]张曾昱,于秀芬.基于掌上虚拟社区的高校教师隐性知识交流平台实践研究[J].图书馆学研究,2015,(9):19-25.
[12]刘会婷,魏青山,李丹.泛在图书馆知识共享空间(KC)研究[J].图书情报知识,2013,(1):114-121.
[14]李丹,闫晓第,魏青山.Drupal的混搭技术在图书馆的应用[J].现代图书情报技术,2013,(10):79-84.
[15]夏翠娟,刘炜,赵亮,等.关联数据发布技术及其实现——以Drupal为例[J].中国图书馆学报,2012,(1):49-57.
[16]任瑞娟,濮德敏,王剑宏,等.基于Drupal实现多类型学术资源的语义化组织与关联化聚合[J].情报科学,2015,(5):63-67.
[17]Van Horik,Rene.Data curation.A Driver’s Guide to European Repositories.Amsterdam:Amsterdam University press,2008:131-152.
[18]Huda Khan,Brian Caruso,Jon Corson-Rikert etc.DataStaR:Using the Semantic Web approach for Data Curation[A].6th International Digital Curation Conference[C].Cornell University,December,2010:1-12.
[19]Antony J.Williams,Sean Ekins.A quality alert and call for improved curation of public chemistry databases[J].Drug Discovery Today,2011,16(17-18):747-750.
[20]Van Horik,Rene.Data curation,A Driver’s Guide to European Repositories.Amsterdam:Amsterdam University press,2008:131-152.
[21]State of the LOD Cloud 2014[EB/OL].http:∥linkeddatacatalog.dws.informatik.uni-mannheim.de/state/,2015-09-10.
(本文责任编辑:郭沫含)
The Construction of Drupal Based Library Knowledge Exchange and Sharing Platform
Zhou Yu1,2Wei Tailiang3Liao Siqin2
(1.School of Information Management,Nanjing University,Nanjing 210023,China;2.Library,Southwest University of Science and Technology,Mianyang 621010,China;3.Library,Sichuan Party School,Chengdu 610071,China)
Domestic Library Knowledge Exchange and Sharing Platform rarely providing services of storage and curation for readers’ uploaded data such as research data,used data and created data,which is not integrated with open data cloud too.In order to providing services of academic information communication and reader uploaded data management,this paper mainly studied the method of building the Library knowledge exchange and sharing platform by using Drupal,which is an open source content management system.The research process included:(1)Analyzing the requirements of the library and readers for the platform;(2)Designing the function and architecture of the platform;(3)Introducing the method of building the platform with Drupal.(4)Discussing the method of research data curation,semantic prescription and its semantic linking to other dataset.Finally,this paper put forward a series of suggestions on future development of Library knowledge exchange and sharing platform in large data and open data cloud environment.
Drupal;knowledge sharing;knowledge service;information system development
2015-12-20
本文的研究受西南科技大学图书馆基金项目“科大机构知识库构建研究”资助。
周 宇(1982-),男,博士研究生,助理研究员,研究方向:语义网与数字图书馆。
10.3969/j.issn.1008-0821.2016.03.009
G250.73
A
1008-0821(2016)03-0053-08
猜你喜欢
科教新报(2022年12期)2022-05-23 06:34:16
今日农业(2021年14期)2021-10-14 08:35:28
海峡姐妹(2020年8期)2020-08-25 09:30:18
开放教育研究(2020年2期)2020-03-31 01:54:14
小太阳画报(2018年1期)2018-05-14 17:19:25
少年博览·小学低年级(2016年10期)2016-11-24 06:48:23
现代语文(2016年21期)2016-05-25 13:13:44
大连民族大学学报(2015年2期)2015-02-27 08:28:11
小天使·一年级语数英综合(2014年8期)2014-06-26 14:42:04
外语学刊(2011年1期)2011-01-22 03:38:33
